Einen 3-färbbaren Graphen kann man in Zeit \(O(|V| + |E|)\) mit \(O({{c2::\sqrt{|V|} }})\) Farben färben.
Note 1: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
r%m#I)x.lS
Previous
Note did not exist
New Note
Front
Back
Einen 3-färbbaren Graphen kann man in Zeit \(O(|V| + |E|)\) mit \(O({{c2::\sqrt{|V|} }})\) Farben färben.

Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Einen 3-färbbaren Graphen kann man in Zeit \(O({{c1::|V| + |E|}})\) mit \(O({{c2::\sqrt{|V|} }})\) Farben färben. | |
| Extra | <img src="paste-45aa473f33c22168fe4a58fed3ec3d7b0c084bd0.jpg"> |
Note 2: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
z=Bcbr%mzt
Previous
Note did not exist
New Note
Front
Es ist kein polynomieller Algorithmus bekannt, um zu entscheiden, ob zwei Graphen isomorph sind.
Back
Es ist kein polynomieller Algorithmus bekannt, um zu entscheiden, ob zwei Graphen isomorph sind.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Es ist kein polynomieller Algorithmus bekannt, um zu entscheiden, ob zwei Graphen {{c1::isomorph}} sind. |
Note 3: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
fr%yq&f{dL
Before
Front
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ such that } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Back
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ such that } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Genauso kann die Folge auch gegen *minus unendlich* divergieren
After
Front
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ such that } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Back
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ such that } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Genauso kann die Folge auch gegen \(-\infty\) divergieren.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Extra | Genauso kann die Folge auch gegen |
Genauso kann die Folge auch gegen \(-\infty\) divergieren. |
Note 4: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
f{:q{$_BIe
Before
Front
\(A \in \mathbb{R}\) ist ein Häufungspunkt einer Folge genau dann, wenn {{c1::eine konvergente Teilfolge \(({a_n}_k)_{k \in \mathbb{N_0}}\) existiert mit \[ \lim_{k \rightarrow \infty} {a_n}_k = A \]}}
Back
\(A \in \mathbb{R}\) ist ein Häufungspunkt einer Folge genau dann, wenn {{c1::eine konvergente Teilfolge \(({a_n}_k)_{k \in \mathbb{N_0}}\) existiert mit \[ \lim_{k \rightarrow \infty} {a_n}_k = A \]}}
After
Front
\(A \in \mathbb{R}\) ist ein Häufungspunkt einer Folge genau dann, wenn {{c1::eine konvergente Teilfolge \(({a_n}_k)_{k \in \mathbb{N_0} }\) existiert mit \[ \lim_{k \rightarrow \infty} {a_n}_k = A \]}}
Back
\(A \in \mathbb{R}\) ist ein Häufungspunkt einer Folge genau dann, wenn {{c1::eine konvergente Teilfolge \(({a_n}_k)_{k \in \mathbb{N_0} }\) existiert mit \[ \lim_{k \rightarrow \infty} {a_n}_k = A \]}}
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | \(A \in \mathbb{R}\) ist ein Häufungspunkt einer Folge genau dann, wenn {{c1::eine konvergente Teilfolge \(({a_n}_k)_{k \in \mathbb{N_0}}\) existiert mit \[ \lim_{k \rightarrow \infty} {a_n}_k = A \]}} | \(A \in \mathbb{R}\) ist ein Häufungspunkt einer Folge genau dann, wenn {{c1::eine konvergente Teilfolge \(({a_n}_k)_{k \in \mathbb{N_0} }\) existiert mit \[ \lim_{k \rightarrow \infty} {a_n}_k = A \]}} |
Note 5: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
CXJAZafgMw
Previous
Note did not exist
New Note
Front
Gustafson's law:
\(W = {{c1::P(1-f)T_{wall} + fT_{wall} }}\)
\(W = {{c1::P(1-f)T_{wall} + fT_{wall} }}\)
Back
Gustafson's law:
\(W = {{c1::P(1-f)T_{wall} + fT_{wall} }}\)
\(W = {{c1::P(1-f)T_{wall} + fT_{wall} }}\)
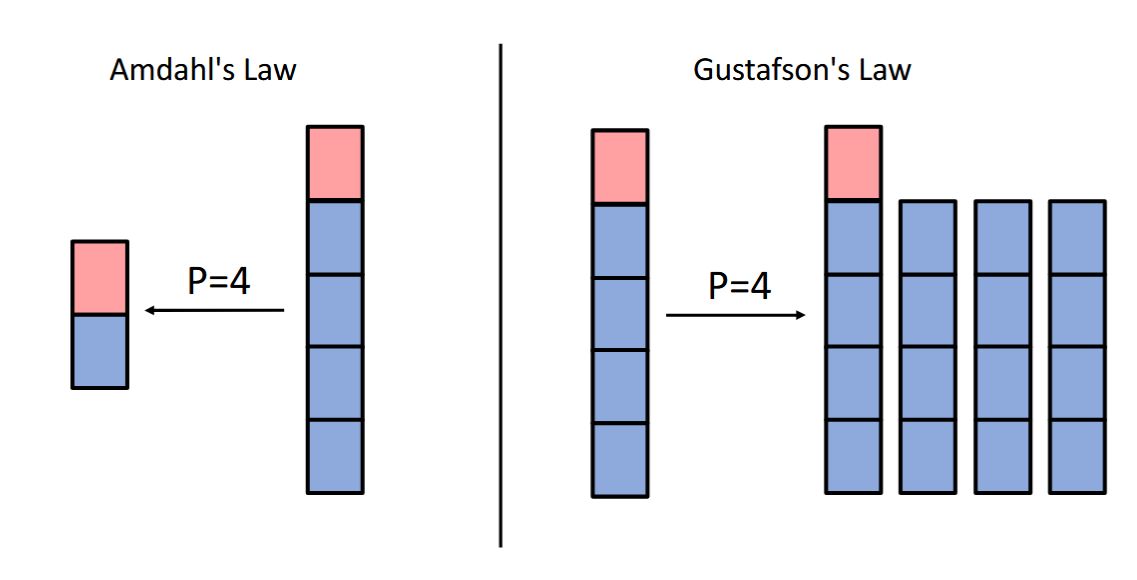
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Gustafson's law:<br><br>\(W = {{c1::P(1-f)T_{wall} + fT_{wall} }}\) | |
| Extra | <img src="paste-aa6938364b9d7ad1e183831ea200b9a4b751156d.jpg"> |
Note 6: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID:
added
Note Type: Horvath Classic
GUID:
E%^haXk=N
Previous
Note did not exist
New Note
Front
Parallel program:

What is \(T_8\)? What is the speedup \(S_8\)?
- Sequential part: 20%
- Parallel part: 80% (assume it scales linearly)
- \(T_1 = 10\)
Back
Parallel program:
What is \(T_8\)? What is the speedup \(S_8\)?
- Sequential part: 20%
- Parallel part: 80% (assume it scales linearly)
- \(T_1 = 10\)
\(T_8 = 0.2 \cdot 10 + \frac{0.8 \cdot 10}{8} = 2 + 1 = 3\)
\(S_8 = T_1/T_8 = 10/3 = 3.33\)
\(S_8 = T_1/T_8 = 10/3 = 3.33\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | Parallel program:<br><ul><li>Sequential part: 20%</li><li>Parallel part: 80% (assume it scales linearly)</li><li>\(T_1 = 10\)<br></li></ul><div><img src="paste-9bf43ab2ea793b111975a884c33e99efb31c285a.jpg"><br></div>What is \(T_8\)? What is the speedup \(S_8\)?<br> | |
| Back | \(T_8 = 0.2 \cdot 10 + \frac{0.8 \cdot 10}{8} = 2 + 1 = 3\)<br> \(S_8 = T_1/T_8 = 10/3 = 3.33\) |
Note 7: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
GzZXD@`eLY
Previous
Note did not exist
New Note
Front
"...the effort expended on achieving high parallel processing rates is wasted unless it is accompanied by achievements in sequential processing rates of very nearly the same magnitude."
— Gene Amdahl
— Gene Amdahl
Back
"...the effort expended on achieving high parallel processing rates is wasted unless it is accompanied by achievements in sequential processing rates of very nearly the same magnitude."
— Gene Amdahl
— Gene Amdahl
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <i>"...the effort expended on achieving high parallel processing rates is wasted unless {{c1::it is accompanied by achievements in sequential processing rates of very nearly the same magnitude}}."<br></i><br>— Gene Amdahl |
Note 8: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
LGNN%IJg[[
Previous
Note did not exist
New Note
Front
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Back
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
How much time is spent on synchronization, locking, context switching?
Frequent context switches introduce delays that degrade parallel performance.
High contention for shared resources or excessive synchronization barriers create bottlenecks that limit parallel efficiency.

Frequent context switches introduce delays that degrade parallel performance.
High contention for shared resources or excessive synchronization barriers create bottlenecks that limit parallel efficiency.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | What factors limit scalability?<br><ol><li>Sequential part of the program (Amdahl's law)</li><li>Data structures and algorithms</li><li>Work distribution strategy</li><li>Work scheduling strategy</li><li>{{c1::Overhead and synchronization barriers}}</li><li>Memory access and caches</li></ol> | |
| Extra | How much time is spent on synchronization, locking, context switching?<br><br>Frequent context switches introduce delays that degrade parallel performance.<br><br>High contention for shared resources or excessive synchronization barriers create bottlenecks that limit parallel efficiency.<br><br><img src="paste-52659711f8baf2991c46e3e12c42daca04c04ea3.jpg"> |
Note 9: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
MWCC+]Z]qd
Previous
Note did not exist
New Note
Front
Amdahl's law:
\(S_p \leq {{c1::\dfrac{W_{ser} + W_{par} }{W_{ser} + \dfrac{W_{par} }{P} } }}\)
\(S_p \leq {{c1::\dfrac{W_{ser} + W_{par} }{W_{ser} + \dfrac{W_{par} }{P} } }}\)
Back
Amdahl's law:
\(S_p \leq {{c1::\dfrac{W_{ser} + W_{par} }{W_{ser} + \dfrac{W_{par} }{P} } }}\)
\(S_p \leq {{c1::\dfrac{W_{ser} + W_{par} }{W_{ser} + \dfrac{W_{par} }{P} } }}\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Amdahl's law:<br><br>\(S_p \leq {{c1::\dfrac{W_{ser} + W_{par} }{W_{ser} + \dfrac{W_{par} }{P} } }}\) |
Note 10: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
P[r-`=cABI
Previous
Note did not exist
New Note
Front
The exeuctor service is not suitable for recursive problems where deep structures require waiting for partial results.
Back
The exeuctor service is not suitable for recursive problems where deep structures require waiting for partial results.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The exeuctor service is not suitable for {{c1::recursive problems where deep structures require waiting for partial results}}. |
Note 11: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
b&FE48/HWB
Previous
Note did not exist
New Note
Front
If \(f\) is the non-parallelizable serial fraction of the total work, this gives:
\(S_p \leq {{c1::\dfrac{1}{f + \dfrac{1-f}{P} } }}\)
\(S_p \leq {{c1::\dfrac{1}{f + \dfrac{1-f}{P} } }}\)
Back
If \(f\) is the non-parallelizable serial fraction of the total work, this gives:
\(S_p \leq {{c1::\dfrac{1}{f + \dfrac{1-f}{P} } }}\)
\(S_p \leq {{c1::\dfrac{1}{f + \dfrac{1-f}{P} } }}\)
Note that the following equalities hold:
\(W_{ser} = fT_1\)
\(W_{par} = (1-f)T_1\)
\(W_{ser} = fT_1\)
\(W_{par} = (1-f)T_1\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | If \(f\) is the non-parallelizable serial fraction of the total work, this gives:<br><br>\(S_p \leq {{c1::\dfrac{1}{f + \dfrac{1-f}{P} } }}\) | |
| Extra | Note that the following equalities hold:<br><br>\(W_{ser} = fT_1\)<br>\(W_{par} = (1-f)T_1\) |
Note 12: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
c*rU+
Previous
Note did not exist
New Note
Front
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Back
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
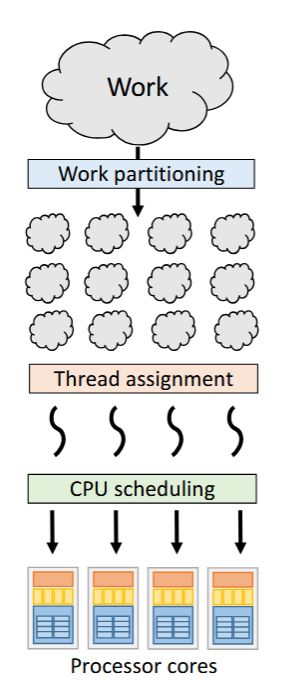 Goal: full utilization (no processor is idle)
Goal: full utilization (no processor is idle)How should work units be assigned to threads?
Efficiency of user-level scheduling: How quickly can tasks be assigned and reassigned to threads?
Overhead from task creation and
management can offset gains.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | What factors limit scalability?<br><ol><li>Sequential part of the program (Amdahl's law)</li><li>Data structures and algorithms</li><li>Work distribution strategy</li><li>{{c1::Work scheduling strategy}}</li><li>Overhead and synchronization barriers</li><li>Memory access and caches</li></ol> | |
| Extra | <img src="paste-a6a195f001fa90004c2fb713683c875872b67fbb.jpg" style="float: right;">Goal: <b>full utilization</b> (no processor is idle)<br><br>How should work units be assigned to threads?<br><br>Efficiency of user-level scheduling: How quickly can tasks be assigned and reassigned to threads?<br><br>Overhead from task creation and<br>management can offset gains.<br> |
Note 13: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
d#q[!,Jl;E
Previous
Note did not exist
New Note
Front
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Back
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Can tasks be executed independently or do they rely on one another?
Even with ideal parallelization, some problems have inherent dependencies that limit speedup.
Even if 99% of the program is parallelized, the remaining 1% sequential part dominates at high core counts.
Even with ideal parallelization, some problems have inherent dependencies that limit speedup.
Even if 99% of the program is parallelized, the remaining 1% sequential part dominates at high core counts.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | What factors limit scalability?<br><ol><li>{{c1::Sequential part of the program (Amdahl's law)}}</li><li>Data structures and algorithms</li><li>Work distribution strategy</li><li>Work scheduling strategy</li><li>Overhead and synchronization barriers</li><li>Memory access and caches</li></ol> | |
| Extra | Can tasks be executed independently or do they rely on one another?<br>Even with ideal parallelization, some problems have inherent dependencies that limit speedup.<br><br><b>Even if 99% of the program is parallelized, the remaining 1% sequential part dominates at high core counts.</b> |
Note 14: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
dCz!O8dc.S
Previous
Note did not exist
New Note
Front
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Back
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Some data structures require sequential access.
Some algorithms naturally expose more parallelism than others.
Algorithms can be restructured to improve parallelism.
Parallel efficiency starts with the right data structures and algorithms.
Some algorithms naturally expose more parallelism than others.
Algorithms can be restructured to improve parallelism.
Parallel efficiency starts with the right data structures and algorithms.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | What factors limit scalability?<br><ol><li>Sequential part of the program (Amdahl's law)</li><li>{{c1::Data structures and algorithms}}</li><li>Work distribution strategy</li><li>Work scheduling strategy</li><li>Overhead and synchronization barriers</li><li>Memory access and caches</li></ol> | |
| Extra | Some data structures require sequential access.<br><img src="paste-a5b966c62876b7312f9a71df81762f263917add0.jpg"><br>Some algorithms naturally expose more parallelism than others.<br>Algorithms can be restructured to improve parallelism.<br><br><b>Parallel efficiency starts with the right data structures and algorithms.</b> |
Note 15: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
fb-e^m:3OM
Previous
Note did not exist
New Note
Front
The Fork/Join Framework is well-suited for recursive problems where deep structures require waiting for partial results.
Back
The Fork/Join Framework is well-suited for recursive problems where deep structures require waiting for partial results.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The Fork/Join Framework is well-suited for {{c1::recursive problems where deep structures require waiting for partial results}}. |
Note 16: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
g
Previous
Note did not exist
New Note
Front
The executor service is well-suited for flat structures or tasks that can run independently in parallel (e.g., transactions).
Back
The executor service is well-suited for flat structures or tasks that can run independently in parallel (e.g., transactions).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The executor service is well-suited for {{c1::flat structures or tasks that can run independently in parallel (e.g., transactions)}}. |
Note 17: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
jxx{VYsKxH
Before
Front
Divide and conquer style parallelism (also called recursive splitting) means: solve a problem by recursively solving smaller sub-problems and combining their results. Solve the sub-problems in separate threads to gain a speedup.
Back
Divide and conquer style parallelism (also called recursive splitting) means: solve a problem by recursively solving smaller sub-problems and combining their results. Solve the sub-problems in separate threads to gain a speedup.
After
Front
Divide and conquer style parallelism (also called recursive splitting) means: solve a problem by recursively solving smaller sub-problems and combining their results.
Back
Divide and conquer style parallelism (also called recursive splitting) means: solve a problem by recursively solving smaller sub-problems and combining their results.
Solve the sub-problems in separate threads to gain a speedup.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Divide and conquer style parallelism |
{{c1::Divide and conquer style parallelism (also called recursive splitting)}} means: solve a problem by {{c2::recursively solving smaller sub-problems and combining their results}}. |
| Extra | Solve the sub-problems in separate threads to gain a speedup. |
Note 18: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
qW*_B8<}hp
Previous
Note did not exist
New Note
Front
Gustafson's law:
\(S_p = f + P(1-f) = P - f(P-1)\)
\(S_p = f + P(1-f) = P - f(P-1)\)
Back
Gustafson's law:
\(S_p = f + P(1-f) = P - f(P-1)\)
\(S_p = f + P(1-f) = P - f(P-1)\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Gustafson's law:<br><br>\(S_p = {{c1::f + P(1-f) = P - f(P-1)}}\) | |
| Extra | <img src="paste-aa6938364b9d7ad1e183831ea200b9a4b751156d.jpg"> |
Note 19: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
quC;@cmWD7
Previous
Note did not exist
New Note
Front
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Back
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
How evenly can work be distributed among cores?
Some workloads create imbalances, causing some cores to remain idle while others are overloaded.
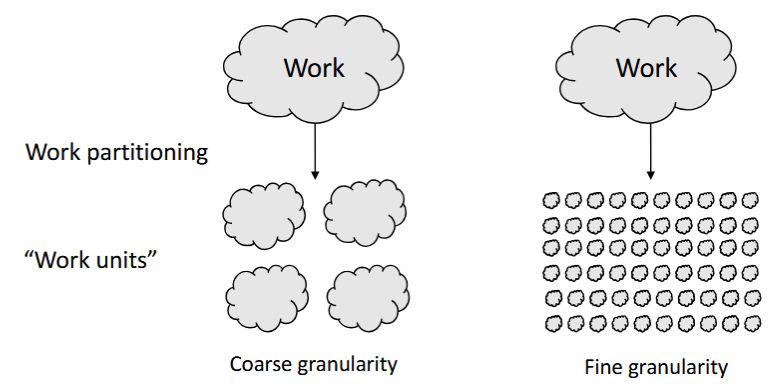
Some workloads create imbalances, causing some cores to remain idle while others are overloaded.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | What factors limit scalability?<br><ol><li>Sequential part of the program (Amdahl's law)</li><li>Data structures and algorithms</li><li>{{c1::Work distribution strategy}}</li><li>Work scheduling strategy</li><li>Overhead and synchronization barriers</li><li>Memory access and caches</li></ol> | |
| Extra | How evenly can work be distributed among cores?<br><br>Some workloads create imbalances, causing some cores to remain idle while others are overloaded.<br><img src="paste-e2881da9332c1b196a69f6460b49e9de2d515c20.jpg"> |
Note 20: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
u54P4-YG?G
Before
Front
The ForkJoin framework automatically assigns tasks to Java threads and may execute multiple tasks in one thread to avoid thread context switching overhead.
Back
The ForkJoin framework automatically assigns tasks to Java threads and may execute multiple tasks in one thread to avoid thread context switching overhead.
After
Front
The ForkJoin framework automatically assigns tasks to Java threads and may execute multiple tasks in one thread to avoid thread context switching overhead.
Back
The ForkJoin framework automatically assigns tasks to Java threads and may execute multiple tasks in one thread to avoid thread context switching overhead.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The ForkJoin framework automatically assigns tasks to Java threads and may execute |
The ForkJoin framework automatically {{c1::assigns tasks to Java threads and may execute multiple tasks in one thread}} to avoid {{c2::thread context switching overhead}}. |
Note 21: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
ug9GHCY%(J
Previous
Note did not exist
New Note
Front
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Back
What factors limit scalability?
- Sequential part of the program (Amdahl's law)
- Data structures and algorithms
- Work distribution strategy
- Work scheduling strategy
- Overhead and synchronization barriers
- Memory access and caches
Memory access contention: If all cores access shared memory, memory bandwidth becomes a bottleneck.
More cores may lead to increased cache misses if data is not well-partitioned.
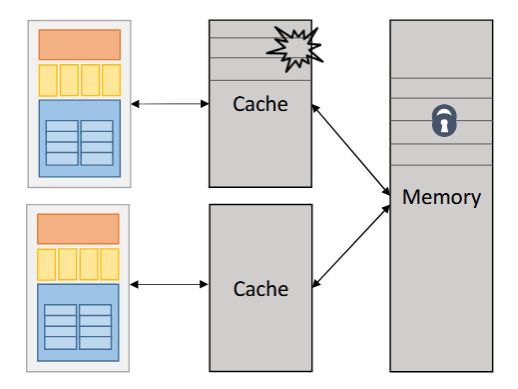
More cores may lead to increased cache misses if data is not well-partitioned.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | What factors limit scalability?<br><ol><li>Sequential part of the program (Amdahl's law)</li><li>Data structures and algorithms</li><li>Work distribution strategy</li><li>Work scheduling strategy</li><li>Overhead and synchronization barriers</li><li>{{c1::Memory access and caches}}</li></ol> | |
| Extra | Memory access contention: If all cores access shared memory, memory bandwidth becomes a bottleneck.<br><br>More cores may lead to increased cache misses if data is not well-partitioned.<br><br><img src="paste-286d4c806c5f57d89365c6d6c0f7e9ceff7485f6.jpg"> |
Note 22: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
unYLoX/LFH
Before
Front
The ForkJoin framework embraces divide and conquer parallelism. Tasks can be spawned (forked) and joined by the framework.
Back
The ForkJoin framework embraces divide and conquer parallelism. Tasks can be spawned (forked) and joined by the framework.
After
Front
The ForkJoin framework embraces divide and conquer parallelism.
Back
The ForkJoin framework embraces divide and conquer parallelism.
Tasks can be spawned (forked) and joined by the framework.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The ForkJoin framework embraces {{c1::divide and conquer parallelism}}. |
The ForkJoin framework embraces {{c1::divide and conquer parallelism}}. |
| Extra | Tasks can be spawned (forked) and joined by the framework. |
Note 23: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
upj89j/}W/
Previous
Note did not exist
New Note
Front
(Parallel) speedup:
\(S_p=T_1/T_p\)
\(S_p=T_1/T_p\)
Back
(Parallel) speedup:
\(S_p=T_1/T_p\)
\(S_p=T_1/T_p\)
- \(S_p = p\) → linear speedup (perfection)
- \(S_p < p\) → sub-linear speedup (performance loss)
- \(S_p > p\) → super-linear speedup (sorcery!)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | (Parallel) speedup:<br><br>\(S_p={{c1::T_1/T_p}}\) | |
| Extra | <div><ul><li>\(S_p = p\) → linear speedup (perfection)</li><li>\(S_p < p\) → sub-linear speedup (performance loss)</li><li>\(S_p > p\) → super-linear speedup (sorcery!)</li></ul><b>Efficiency: </b>\(S_p / p\)<br></div> |
Note 24: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
w6B3a^|y`X
Previous
Note did not exist
New Note
Front
Bound on speedup per Amdahl's law:
\(T_p \geq {{c1::W_{ser} + \dfrac{W_{par} }{P} }}\)
Back
Bound on speedup per Amdahl's law:
\(T_p \geq {{c1::W_{ser} + \dfrac{W_{par} }{P} }}\)
\(W\) denotes serial/parallel work respectively
\(P \) denotes the number of workers available
\(P \) denotes the number of workers available
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Bound on speedup per Amdahl's law:<br><pre><code>\(T_p \geq {{c1::W_{ser} + \dfrac{W_{par} }{P} }}\) </code></pre> | |
| Extra | \(W\) denotes serial/parallel work respectively<br>\(P \) denotes the number of workers available |
Note 25: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
zRL[#VyH!Q
Previous
Note did not exist
New Note
Front
Parallel execution time:
\(T_p=T_1/p\)
\(T_p=T_1/p\)
Back
Parallel execution time:
\(T_p=T_1/p\)
\(T_p=T_1/p\)
(Equality, doesn't necessarily hold, usually we have \(>\) due to some performance loss.)
\(T_1\) denotes sequential execution time.
\(T_1\) denotes sequential execution time.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Parallel execution time:<br><br>\(T_p={{c1::T_1/p}}\) | |
| Extra | (Equality, doesn't necessarily hold, usually we have \(>\) due to some performance loss.)<br><br>\(T_1\) denotes sequential execution time. |