Note 1: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: (kY&h#;hg+
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Reduktion Hamiltonkreis \(\to\) Long-Path
Falls Long-Path für Graphen mit \(n\) Knoten in \(t(n)\) Zeit entscheidbar ist, dann lässt sich in \(t(2n - 2) + O(n^2)\) Zeit entscheiden, ob ein Graph mit \(n\) Knoten einen Hamiltonkreis hat.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Reduktion Hamiltonkreis \(\to\) Long-Path
Falls Long-Path für Graphen mit \(n\) Knoten in \(t(n)\) Zeit entscheidbar ist, dann lässt sich in \(t(2n - 2) + O(n^2)\) Zeit entscheiden, ob ein Graph mit \(n\) Knoten einen Hamiltonkreis hat.
Konsequenz: Long-Path ist mindestens so schwer wie Hamiltonkreis, also ebenfalls NP-schwer.
Idee: Konstruiere in \(O(n^2)\) Zeit einen Graphen \(G'\) mit \(n' \leq 2n - 2\) Knoten, sodass \(G\) einen Hamiltonkreis hat \(\Leftrightarrow\) \(G'\) einen Pfad der Länge \(n\) hat.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Reduktion Hamiltonkreis \(\to\) Long-Path</b><br>Falls Long-Path für Graphen mit \(n\) Knoten in \(t(n)\) Zeit entscheidbar ist, dann lässt sich in {{c1::\(t(2n - 2) + O(n^2)\)}} Zeit entscheiden, ob ein Graph mit \(n\) Knoten einen Hamiltonkreis hat. |
| Extra |
|
Konsequenz: Long-Path ist mindestens so schwer wie Hamiltonkreis, also ebenfalls NP-schwer.<br>Idee: Konstruiere in \(O(n^2)\) Zeit einen Graphen \(G'\) mit \(n' \leq 2n - 2\) Knoten, sodass \(G\) einen Hamiltonkreis hat \(\Leftrightarrow\) \(G'\) einen Pfad der Länge \(n\) hat. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 2: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: +N@/D$lVm_
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Selektionsproblem: Bestimme in einer Folge \((A[1], \ldots, A[n])\) paarweise verschiedener Zahlen den
\(k\)-kleinsten Wert.
Naiver Ansatz: Sortieren + Index, Laufzeit
\(O(n \log n)\).
Schneller geht es mit
QuickSelect (erwartet \(O(
n)\)):
QuickSelect(A, ℓ, r, k):
p ← Uniform({ℓ, ℓ+1, ..., r})
t ← Partition(A, ℓ, r, p)
if t = ℓ + k - 1: return A[t] # gefunden
else if t > ℓ + k - 1:
return QuickSelect(A, ℓ, t-1, k) # links
else:
return QuickSelect(A, t+1, r, k - t) # rechts
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Selektionsproblem: Bestimme in einer Folge \((A[1], \ldots, A[n])\) paarweise verschiedener Zahlen den
\(k\)-kleinsten Wert.
Naiver Ansatz: Sortieren + Index, Laufzeit
\(O(n \log n)\).
Schneller geht es mit
QuickSelect (erwartet \(O(
n)\)):
QuickSelect(A, ℓ, r, k):
p ← Uniform({ℓ, ℓ+1, ..., r})
t ← Partition(A, ℓ, r, p)
if t = ℓ + k - 1: return A[t] # gefunden
else if t > ℓ + k - 1:
return QuickSelect(A, ℓ, t-1, k) # links
else:
return QuickSelect(A, t+1, r, k - t) # rechts
Im Gegensatz zu QuickSort rekursiert QuickSelect nur in eine der beiden Hälften (oder gibt direkt zurück, falls Pivot bereits an der gesuchten Position liegt). Das macht den Unterschied zwischen \(O(n \log n)\) und \(O(n)\) erwartet.
Bei einem Aufruf von QuickSelect ist die Anzahl Vergleiche \(T = \sum_{i=1}^{N} (r_i - \ell_i)\), wobei \(N\) die Anzahl Partition-Aufrufe ist.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Selektionsproblem: Bestimme in einer Folge \((A[1], \ldots, A[n])\) paarweise verschiedener Zahlen den
\(k\)-kleinsten Wert.
Naiver Ansatz: Sortieren + Index, Laufzeit \(O(
n \log n)\).
Schneller geht es mit
QuickSelect (erwartet \(O(
n)\)):
QuickSelect(A, ℓ, r, k):
p ← Uniform({ℓ, ℓ+1, ..., r})
t ← Partition(A, ℓ, r, p)
if t = ℓ + k - 1: return A[t] # gefunden
else if t > ℓ + k - 1:
return QuickSelect(A, ℓ, t-1, k) # links
else:
return QuickSelect(A, t+1, r, k - t) # rechts
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Selektionsproblem: Bestimme in einer Folge \((A[1], \ldots, A[n])\) paarweise verschiedener Zahlen den
\(k\)-kleinsten Wert.
Naiver Ansatz: Sortieren + Index, Laufzeit \(O(
n \log n)\).
Schneller geht es mit
QuickSelect (erwartet \(O(
n)\)):
QuickSelect(A, ℓ, r, k):
p ← Uniform({ℓ, ℓ+1, ..., r})
t ← Partition(A, ℓ, r, p)
if t = ℓ + k - 1: return A[t] # gefunden
else if t > ℓ + k - 1:
return QuickSelect(A, ℓ, t-1, k) # links
else:
return QuickSelect(A, t+1, r, k - t) # rechts
Im Gegensatz zu QuickSort rekursiert QuickSelect nur in eine der beiden Hälften (oder gibt direkt zurück, falls Pivot bereits an der gesuchten Position liegt). Das macht den Unterschied zwischen \(O(n \log n)\) und \(O(n)\) erwartet.
Bei einem Aufruf von QuickSelect ist die Anzahl Vergleiche \(T = \sum_{i=1}^{N} (r_i - \ell_i)\), wobei \(N\) die Anzahl Partition-Aufrufe ist.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Selektionsproblem:</b> Bestimme in einer Folge \((A[1], \ldots, A[n])\) paarweise verschiedener Zahlen den {{c1::\(k\)-kleinsten Wert}}.<br><br>Naiver Ansatz: Sortieren + Index, Laufzeit {{c2::\(O(n \log n)\)}}.<br><br>Schneller geht es mit <b>QuickSelect</b> (erwartet \(O({{c3::n}})\)):<pre>QuickSelect(A, ℓ, r, k):
p ← Uniform({ℓ, ℓ+1, ..., r})
t ← Partition(A, ℓ, r, p)
if t = ℓ + k - 1: return A[t] # gefunden
else if t > ℓ + k - 1:
return QuickSelect(A, ℓ, t-1, k) # links
else:
return QuickSelect(A, t+1, r, k - t) # rechts</pre> |
<b>Selektionsproblem:</b> Bestimme in einer Folge \((A[1], \ldots, A[n])\) paarweise verschiedener Zahlen den {{c1::\(k\)-kleinsten Wert}}.<br><br>Naiver Ansatz: Sortieren + Index, Laufzeit \(O({{c2::n \log n}})\).<br><br>Schneller geht es mit <b>QuickSelect</b> (erwartet \(O({{c3::n}})\)):<pre>QuickSelect(A, ℓ, r, k):
p ← Uniform({ℓ, ℓ+1, ..., r})
t ← Partition(A, ℓ, r, p)
if t = ℓ + k - 1: return A[t] # gefunden
else if t > ℓ + k - 1:
return QuickSelect(A, ℓ, t-1, k) # links
else:
return QuickSelect(A, t+1, r, k - t) # rechts</pre> |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Note 3: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: :EvvAz%/Gq
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt Färbung).
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt Färbung).
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Achtung: Die Färbung muss hier nicht zulässig im üblichen Sinn sein, also benachbarte Knoten dürfen dieselbe Farbe haben. Wichtig ist nur, dass entlang eines bunten Pfades keine Farbe doppelt vorkommt.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt {{c1::Färbung}}).<br>Ein Pfad heisst {{c2::bunt}}, wenn {{c2::alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben}}. |
| Extra |
|
Achtung: Die Färbung muss hier <b>nicht</b> zulässig im üblichen Sinn sein, also benachbarte Knoten dürfen dieselbe Farbe haben. Wichtig ist nur, dass entlang eines bunten Pfades keine Farbe doppelt vorkommt. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 4: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: Ao9Fa-:N2(
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Algorithmus \(\textsc{Bunt}(G, i)\)
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Algorithmus \(\textsc{Bunt}(G, i)\)
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
BUNT(G, i):
for all v in V:
P_i(v) := empty set
for all x in N(v):
for all R in P_{i-1}(x) with γ(v) ∉ R:
P_i(v) := P_i(v) ∪ { R ∪ {γ(v)} }Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\).
Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
<b>Algorithmus \(\textsc{Bunt}(G, i)\)</b><br>Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)? |
| Back |
|
<pre>BUNT(G, i):
for all v in V:
P_i(v) := empty set
for all x in N(v):
for all R in P_{i-1}(x) with γ(v) ∉ R:
P_i(v) := P_i(v) ∪ { R ∪ {γ(v)} }</pre>Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\).<br>Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 5: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: EK)Cz[ep(U
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Reduktion Hamiltonkreis \(\to\) Long-Path: Konstruktion
Wie konstruiert man aus \(G = (V, E)\) den Graphen \(G'\), sodass \(G\) genau dann einen Hamiltonkreis hat, wenn \(G'\) einen Pfad der Länge \(n\) besitzt?
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Reduktion Hamiltonkreis \(\to\) Long-Path: Konstruktion
Wie konstruiert man aus \(G = (V, E)\) den Graphen \(G'\), sodass \(G\) genau dann einen Hamiltonkreis hat, wenn \(G'\) einen Pfad der Länge \(n\) besitzt?
Sei \(v^* \in V\) ein beliebig gewählter Knoten.
Konstruiere \(G'\) wie folgt:
- Ersetze \(v^*\) durch zwei Kopien \(v_1^*\) und \(v_2^*\); jede Kopie erhält dieselben Nachbarn wie \(v^*\) in \(G\).
- Hänge an \(v_1^*\) und \(v_2^*\) je einen neuen Knoten \(w_1\) bzw. \(w_2\) an (jeweils Grad 1).
Dann hat \(G'\) genau \(|V| + 1 = n + 1 \leq 2n - 2\) Knoten (für \(n \geq 3\)) und kann in \(O(n^2)\) Zeit gebaut werden.
\(\Rightarrow\): Aus einem Hamiltonkreis in \(G\) erhält man durch Aufschneiden bei \(v^*\) und Anhängen von \(w_1, w_2\) einen Pfad \(w_1 \to v_1^* \to \dots \to v_2^* \to w_2\) der Länge \(n\) in \(G'\).
\(\Leftarrow\): Ein Pfad der Länge \(n\) in \(G'\) muss bei \(w_1\) starten und bei \(w_2\) enden (oder umgekehrt) und liefert nach Verschmelzen von \(v_1^*, v_2^*\) einen Hamiltonkreis in \(G\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
<b>Reduktion Hamiltonkreis \(\to\) Long-Path: Konstruktion</b><br>Wie konstruiert man aus \(G = (V, E)\) den Graphen \(G'\), sodass \(G\) genau dann einen Hamiltonkreis hat, wenn \(G'\) einen Pfad der Länge \(n\) besitzt? |
| Back |
|
Sei \(v^* \in V\) ein beliebig gewählter Knoten.<br>Konstruiere \(G'\) wie folgt:<ol><li>Ersetze \(v^*\) durch zwei Kopien \(v_1^*\) und \(v_2^*\); jede Kopie erhält dieselben Nachbarn wie \(v^*\) in \(G\).</li><li>Hänge an \(v_1^*\) und \(v_2^*\) je einen neuen Knoten \(w_1\) bzw. \(w_2\) an (jeweils Grad 1).</li></ol>Dann hat \(G'\) genau \(|V| + 1 = n + 1 \leq 2n - 2\) Knoten (für \(n \geq 3\)) und kann in \(O(n^2)\) Zeit gebaut werden.<br><br><b>\(\Rightarrow\):</b> Aus einem Hamiltonkreis in \(G\) erhält man durch Aufschneiden bei \(v^*\) und Anhängen von \(w_1, w_2\) einen Pfad \(w_1 \to v_1^* \to \dots \to v_2^* \to w_2\) der Länge \(n\) in \(G'\).<br><b>\(\Leftarrow\):</b> Ein Pfad der Länge \(n\) in \(G'\) muss bei \(w_1\) starten und bei \(w_2\) enden (oder umgekehrt) und liefert nach Verschmelzen von \(v_1^*, v_2^*\) einen Hamiltonkreis in \(G\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 6: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: R/^@L,DJMy
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Long-Path Problem
Gegeben ein Graph \(G = (V, E)\) und ein \(B \in \mathbb{N}_0\), stelle fest, ob es einen Pfad der Länge \(B\) in \(G\) gibt.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Long-Path Problem
Gegeben ein Graph \(G = (V, E)\) und ein \(B \in \mathbb{N}_0\), stelle fest, ob es einen Pfad der Länge \(B\) in \(G\) gibt.
Achtung: \(B\) ist die Anzahl Kanten, also hat ein Pfad der Länge \(B\) genau \(B+1\) Knoten.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Long-Path Problem</b><br>Gegeben ein Graph \(G = (V, E)\) und ein \(B \in \mathbb{N}_0\), {{c1::stelle fest, ob es einen Pfad der Länge \(B\) in \(G\) gibt}}. |
| Extra |
|
Achtung: \(B\) ist die <b>Anzahl Kanten</b>, also hat ein Pfad der Länge \(B\) genau \(B+1\) Knoten. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 7: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: R?={ZwzI%F
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Monte-Carlo Algorithmus für Long-Path: Analyse
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.
(1) Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Monte-Carlo Algorithmus für Long-Path: Analyse
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.
(1) Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Faktor \((2e)^k\) statt \(e^k\): einmalige bunte Färbung kostet \(O(2^k \cdot k \cdot m)\) (Mengen \(S \subseteq [k]\) im DP), und es werden \(\Theta(\varepsilon \cdot e^k)\) Versuche gemacht.
Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Monte-Carlo Algorithmus für Long-Path: Analyse</b><br>Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.<br>(1) Laufzeit: \(O\!\big({{c1::\varepsilon \cdot (2e)^k \cdot k \cdot m}}\big)\), wobei \(m = |E|\).<br>(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: {{c2::einseitiger Fehler}}).<br>(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}. |
| Extra |
|
Faktor \((2e)^k\) statt \(e^k\): einmalige bunte Färbung kostet \(O(2^k \cdot k \cdot m)\) (Mengen \(S \subseteq [k]\) im DP), und es werden \(\Theta(\varepsilon \cdot e^k)\) Versuche gemacht.<br>Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 8: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: U_elCD$&ev
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\]
\(P_i(v)\) sammelt also alle möglichen Farbmengen, die ein bunter Pfad der Länge \(i\) ausschöpfen kann, wenn er bei \(v\) endet.
Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.
Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei<br>\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\] |
| Extra |
|
\(P_i(v)\) sammelt also alle möglichen <b>Farbmengen</b>, die ein bunter Pfad der Länge \(i\) ausschöpfen kann, wenn er bei \(v\) endet.<br>Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.<br>Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 9: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: XE[{x!N{Fm
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Satz (Zufallsfärbungen)
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq e^{-k}\).
(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq e^{k}\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Satz (Zufallsfärbungen)
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq e^{-k}\).
(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq e^{k}\).
Beweis von (1): \(\Pr[P \text{ wird bunt}] = \tfrac{k!}{k^k} \geq e^{-k}\) per Stirling.
Beweis von (2): geometrisch verteilte Wartezeit mit Erfolgswahrscheinlichkeit \(p\), Erwartungswert \(1/p\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Satz (Zufallsfärbungen)</b><br>Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).<br>(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq {{c1::e^{-k}}}\).<br>(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq {{c2::e^{k}}}\). |
| Extra |
|
Beweis von (1): \(\Pr[P \text{ wird bunt}] = \tfrac{k!}{k^k} \geq e^{-k}\) per Stirling.<br>Beweis von (2): geometrisch verteilte Wartezeit mit Erfolgswahrscheinlichkeit \(p\), Erwartungswert \(1/p\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 10: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: grern^;M[D
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Durchprobieren aller möglichen Pfade liefert für das Long-Path Problem eine Laufzeit von {{c1::\(O(n^{B+2})\)}}.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Durchprobieren aller möglichen Pfade liefert für das Long-Path Problem eine Laufzeit von {{c1::\(O(n^{B+2})\)}}.
Das ist polynomiell in \(n\), aber exponentiell in \(B\): unbrauchbar, sobald \(B\) mit \(n\) wächst.
Ziel der nachfolgenden Konstruktion (Color-Coding): Laufzeit \(O(c^B)\) für eine Konstante \(c\), also unabhängig von \(n\) im Exponenten.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Durchprobieren aller möglichen Pfade liefert für das Long-Path Problem eine Laufzeit von {{c1::\(O(n^{B+2})\)}}. |
| Extra |
|
Das ist polynomiell in \(n\), aber exponentiell in \(B\): unbrauchbar, sobald \(B\) mit \(n\) wächst.<br>Ziel der nachfolgenden Konstruktion (Color-Coding): Laufzeit \(O(c^B)\) für eine Konstante \(c\), also unabhängig von \(n\) im Exponenten. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 11: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: t6+;HK:U,l
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Rekursionsformel für \(P_i(v)\)
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Rekursionsformel für \(P_i(v)\)
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\]
Idee: Ein bunter Pfad der Länge \(i\), der in \(v\) endet, entsteht aus einem bunten Pfad der Länge \(i-1\), der in einem Nachbarn \(x\) von \(v\) endet, dessen Farbmenge \(\gamma(v)\) noch nicht enthält.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Rekursionsformel für \(P_i(v)\)</b><br>Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).<br>Für \(i \geq 1\):<br>\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\] |
| Extra |
|
Idee: Ein bunter Pfad der Länge \(i\), der in \(v\) endet, entsteht aus einem bunten Pfad der Länge \(i-1\), der in einem Nachbarn \(x\) von \(v\) endet, dessen Farbmenge \(\gamma(v)\) noch nicht enthält. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 12: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: tSHEc:NhB:
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Sei \(P\) ein Pfad der Länge \(k-1\) (also mit \(k\) Knoten).
Anzahl der Färbungen von \(P\) mit \(k\) Farben: \(k^k\).
Anzahl der Färbungen, in denen \(P\) bunt ist: \(k!\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Sei \(P\) ein Pfad der Länge \(k-1\) (also mit \(k\) Knoten).
Anzahl der Färbungen von \(P\) mit \(k\) Farben: \(k^k\).
Anzahl der Färbungen, in denen \(P\) bunt ist: \(k!\).
Daraus folgt: Bei einer zufälligen Färbung mit \(k\) Farben ist die Wahrscheinlichkeit, dass \(P\) bunt wird, \[ p = \frac{k!}{k^k} \geq e^{-k} \] (per Stirling: \(k! \geq (k/e)^k\)).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Sei \(P\) ein Pfad der Länge \(k-1\) (also mit \(k\) Knoten).<br>Anzahl der Färbungen von \(P\) mit \(k\) Farben: {{c1::\(k^k\)}}.<br>Anzahl der Färbungen, in denen \(P\) bunt ist: {{c2::\(k!\)}}. |
| Extra |
|
Daraus folgt: Bei einer zufälligen Färbung mit \(k\) Farben ist die Wahrscheinlichkeit, dass \(P\) bunt wird, \[ p = \frac{k!}{k^k} \geq e^{-k} \] (per Stirling: \(k! \geq (k/e)^k\)). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::8._Lange_Pfade_und_Color-Coding
Note 13: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: y@-]+Mp!&j
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
Ein Problem \(\Pi\) aus NP heißt NP-vollständig, falls gilt:
\(\Pi \in P \Rightarrow P = NP\)
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
Ein Problem \(\Pi\) aus NP heißt NP-vollständig, falls gilt:
\(\Pi \in P \Rightarrow P = NP\)
Es gibt sehr viele NP-vollständige Probleme:
- Hamiltonkreis
- Rucksackproblem
- Clique: Gibt es in einem Graphen \(k\) paarweise benachbarte Knoten?
- Nullstelle mod \(n\): Hat ein Polynom mod \(n\) eine Nullstelle?
- Satisfiability: Hat eine logische Formel eine Lösung?
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
Ein Problem \(\Pi\) aus NP heißt NP-vollständig, falls gilt:
\[\Pi \in P \Rightarrow P = NP\]
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
Ein Problem \(\Pi\) aus NP heißt NP-vollständig, falls gilt:
\[\Pi \in P \Rightarrow P = NP\]
Es gibt sehr viele NP-vollständige Probleme:
- Hamiltonkreis
- Rucksackproblem
- Clique: Gibt es in einem Graphen \(k\) paarweise benachbarte Knoten?
- Nullstelle mod \(n\): Hat ein Polynom mod \(n\) eine Nullstelle?
- Satisfiability: Hat eine logische Formel eine Lösung?
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<div>Ein Problem \(\Pi\) aus NP heißt NP-vollständig, falls gilt:</div><div>\({{c1::\Pi \in P \Rightarrow P = NP}}\)</div> |
<div>Ein Problem \(\Pi\) aus NP heißt NP-vollständig, falls gilt:</div><div>\[{{c1::\Pi \in P \Rightarrow P = NP}}\]</div> |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
Note 14: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: 3:g]mJgPq,
modified
Before
Front
ETH::2._Semester::Analysis::5._Differentialrechnung::2._Differenzierbarkeit
Ist \(f\) an der Stelle \(x_0\) differenzierbar, so ist \(f\) an dieser Stelle insbesondere stetig.
Back
ETH::2._Semester::Analysis::5._Differentialrechnung::2._Differenzierbarkeit
Ist \(f\) an der Stelle \(x_0\) differenzierbar, so ist \(f\) an dieser Stelle insbesondere stetig.
Die Umkehrung gilt nicht: stetige Funktionen müssen nicht differenzierbar sein (z.B. \(|x|\) bei \(x_0 = 0\)). Proof Included
After
Front
ETH::2._Semester::Analysis::5._Differentialrechnung::2._Differenzierbarkeit
Ist \(f\) an der Stelle \(x_0\) differenzierbar, so ist \(f\) an dieser Stelle insbesondere stetig.
Back
ETH::2._Semester::Analysis::5._Differentialrechnung::2._Differenzierbarkeit
Ist \(f\) an der Stelle \(x_0\) differenzierbar, so ist \(f\) an dieser Stelle insbesondere stetig.
Die Umkehrung gilt nicht: stetige Funktionen müssen nicht differenzierbar sein (z.B. \(|x|\) bei \(x_0 = 0\)).
Field-by-field Comparison
| Field |
Before |
After |
| Extra |
Die Umkehrung gilt nicht: stetige Funktionen müssen nicht differenzierbar sein (z.B. \(|x|\) bei \(x_0 = 0\)). Proof Included |
Die Umkehrung gilt nicht: stetige Funktionen müssen nicht differenzierbar sein (z.B. \(|x|\) bei \(x_0 = 0\)). |
Tags:
ETH::2._Semester::Analysis::5._Differentialrechnung::2._Differenzierbarkeit
Note 15: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: (kY&h#
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
A reader/writer lock has three states: not held, held for writing by exactly one thread, and held for reading by one or more threads. The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c4::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. writers and readers exclude each other.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
A reader/writer lock has three states: not held, held for writing by exactly one thread, and held for reading by one or more threads. The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c4::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. writers and readers exclude each other.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
A reader/writer lock has three states: {{c1::<em>not held</em>}}, {{c2::<em>held for writing</em> by exactly one thread}}, and {{c3::<em>held for reading</em> by one or more threads}}. The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c4::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. {{c4::writers and readers exclude each other}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 16: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: )Wj64y)bWf
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Peterson's lock (for two processes \(P\) and \(Q\)) uses two shared variables:
flag[1..2] ("I am interested") and
victim ("who yields if both want in"). The pre-protocol for thread
id is
flag[id] = true;
victim = id;
while(flag[1-id] && victim == id);
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Peterson's lock (for two processes \(P\) and \(Q\)) uses two shared variables:
flag[1..2] ("I am interested") and
victim ("who yields if both want in"). The pre-protocol for thread
id is
flag[id] = true;
victim = id;
while(flag[1-id] && victim == id);
Intuition: a thread can enter as soon as either the other thread has dropped its flag (no contention) or the other thread has overwritten victim (so it became the new victim). Far simpler than Dekker, and provably ME + starvation-free.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Peterson's lock (for two processes \(P\) and \(Q\)) uses two shared variables: flag[1..2] ("I am interested") and victim ("who yields if both want in").
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Peterson's lock (for two processes \(P\) and \(Q\)) uses two shared variables: flag[1..2] ("I am interested") and victim ("who yields if both want in").
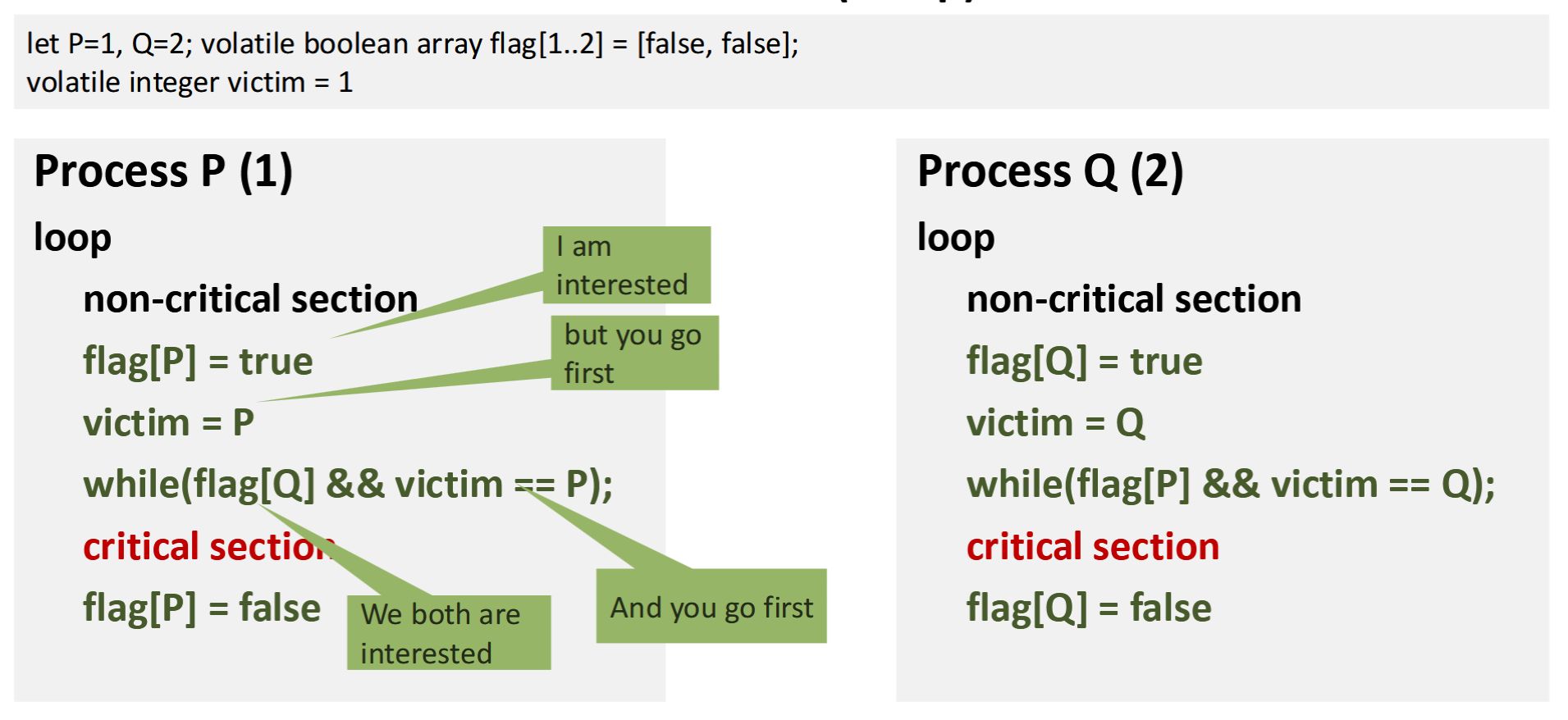
Intuition: a thread can enter as soon as either the other thread has dropped its flag (no contention) or the other thread has overwritten
victim (so it became the new victim). Far simpler than Dekker, and provably ME + starvation-free.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
{{c1::Peterson's lock}} (for two processes \(P\) and \(Q\)) uses two shared variables: {{c2::<code>flag[1..2]</code> ("I am interested")}} and {{c3::<code>victim</code> ("who yields if both want in")}}. The pre-protocol for thread <code>id</code> is <pre>flag[id] = true;
victim = id;
while(flag[1-id] && victim == id);</pre> |
{{c1::Peterson's lock}} (for two processes \(P\) and \(Q\)) uses two shared variables: {{c2::<code>flag[1..2]</code> ("I am interested")}} and {{c3::<code>victim</code> ("who yields if both want in")}}. |
| Extra |
Intuition: a thread can enter as soon as either the other thread has dropped its flag (no contention) or the other thread has overwritten <code>victim</code> (so it became the new victim). Far simpler than Dekker, and provably ME + starvation-free. |
<img src="paste-ea194ecdb7e600acdd487758e9b3e75e21e43c4a.jpg"><br><br>Intuition: a thread can enter as soon as either the other thread has dropped its flag (no contention) or the other thread has overwritten <code>victim</code> (so it became the new victim). Far simpler than Dekker, and provably ME + starvation-free. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Note 17: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: +IMbq_64hM
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Correctness argument for optimistic remove(c): given that b and c are both locked, b is still reachable from head, and c is still b's successor, neither node can currently be in the process of being deleted, so removing c is safe. For a non-existing c with neighbours b, d the same invariants additionally guarantee that no thread can insert a new node between b and d while we hold the locks, so returning false is correct.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Correctness argument for optimistic remove(c): given that b and c are both locked, b is still reachable from head, and c is still b's successor, neither node can currently be in the process of being deleted, so removing c is safe. For a non-existing c with neighbours b, d the same invariants additionally guarantee that no thread can insert a new node between b and d while we hold the locks, so returning false is correct.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Correctness argument for optimistic <code>remove(c)</code>: given that {{c1::<code>b</code> and <code>c</code> are both locked}}, {{c2::<code>b</code> is still reachable from <code>head</code>}}, and {{c3::<code>c</code> is still <code>b</code>'s successor}}, {{c4::neither node can currently be in the process of being deleted}}, so removing <code>c</code> is safe. For a non-existing <code>c</code> with neighbours <code>b, d</code> the same invariants additionally guarantee that {{c5::no thread can insert a new node between <code>b</code> and <code>d</code> while we hold the locks}}, so returning <code>false</code> is correct. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Note 18: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: +[g?P8,OBL
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Hand-over-hand locking (also lock coupling) on a linked list: a thread always holds locks on two consecutive nodes pred and curr and only releases pred after the lock on the next node has been acquired. This way it walks through the list step by step without any concurrent thread being able to redirect a pointer underneath it.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Hand-over-hand locking (also lock coupling) on a linked list: a thread always holds locks on two consecutive nodes pred and curr and only releases pred after the lock on the next node has been acquired. This way it walks through the list step by step without any concurrent thread being able to redirect a pointer underneath it.
Skeleton of
remove:
head.lock();
pred = head;
curr = pred.next;
curr.lock();
while (curr.key < key) {
pred.unlock();
pred = curr; // pred stays locked
curr = curr.next;
curr.lock(); // hand over hand
}
if (curr.key == key) { pred.next = curr.next; return true; }
return false;Sentinel nodes at head and tail prevent
curr from ever being
null on entry or at the end of the list.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Hand-over-hand locking (also <em>lock coupling</em>) on a linked list: a thread always holds {{c1::locks on two consecutive nodes <code>pred</code> and <code>curr</code>}} and only releases {{c2::<code>pred</code> after the lock on the next node has been acquired}}. This way it walks through the list step by step without {{c3::any concurrent thread being able to redirect a pointer underneath it}}. |
| Extra |
|
Skeleton of <code>remove</code>: <pre>head.lock();
pred = head;
curr = pred.next;
curr.lock();
while (curr.key < key) {
pred.unlock();
pred = curr; // pred stays locked
curr = curr.next;
curr.lock(); // hand over hand
}
if (curr.key == key) { pred.next = curr.next; return true; }
return false;</pre>Sentinel nodes at head and tail prevent <code>curr</code> from ever being <code>null</code> on entry or at the end of the list. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Note 19: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: 4vgT{Q5@#k
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
After locking, validate(pred, curr) in optimistic synchronisation must check two properties: pred is still reachable from head (otherwise pred has been deleted in the meantime), and pred.next == curr (otherwise some node has been inserted between pred and curr). If either check fails, the operation must be restarted.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
After locking, validate(pred, curr) in optimistic synchronisation must check two properties: pred is still reachable from head (otherwise pred has been deleted in the meantime), and pred.next == curr (otherwise some node has been inserted between pred and curr). If either check fails, the operation must be restarted.
Code skeleton:
private boolean validate(Node pred, Node curr) {
Node node = head;
while (node.key <= pred.key) {
if (node == pred) return pred.next == curr;
node = node.next;
}
return false;
}
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
After locking, <code>validate(pred, curr)</code> in optimistic synchronisation must check two properties: {{c1::<code>pred</code> is still reachable from <code>head</code>}} (otherwise <code>pred</code> has been deleted in the meantime), and {{c2::<code>pred.next == curr</code>}} (otherwise some node has been inserted between <code>pred</code> and <code>curr</code>). If either check fails, the operation must be {{c3::restarted}}. |
| Extra |
|
Code skeleton: <pre>private boolean validate(Node pred, Node curr) {
Node node = head;
while (node.key <= pred.key) {
if (node == pred) return pred.next == curr;
node = node.next;
}
return false;
}</pre> |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Note 20: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: 5ofcejWG|B
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Optimistic synchronisation on a list: traverse the list without any locks to find pred and curr, then lock both nodes, and validate that the world has not changed underneath you during the traversal. If validation fails, the whole attempt is retried.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Optimistic synchronisation on a list: traverse the list without any locks to find pred and curr, then lock both nodes, and validate that the world has not changed underneath you during the traversal. If validation fails, the whole attempt is retried.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Optimistic synchronisation on a list: {{c1::traverse the list <em>without</em> any locks to find <code>pred</code> and <code>curr</code>}}, {{c2::then lock both nodes}}, and {{c3::validate that the world has not changed underneath you during the traversal}}. If validation fails, {{c4::the whole attempt is retried}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Note 21: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: 7gI{,sQ;#o
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
The 3rd-try mutex (strict alternation)
p2: while(turn != 1);
p3: critical section
p4: turn = 2
satisfies mutual exclusion but allows
starvation, because
a process stuck in its non-CS never resets turn, so the other process is forced to wait forever.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
The 3rd-try mutex (strict alternation)
p2: while(turn != 1);
p3: critical section
p4: turn = 2
satisfies mutual exclusion but allows
starvation, because
a process stuck in its non-CS never resets turn, so the other process is forced to wait forever.
This is exactly why we make no assumption about progress outside the CS: a correct mutex must not rely on the other thread continuing to take turns.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers

This satisfies mutual exclusion but allows
starvation, because
a process stuck in its non-CS never resets turn, so the other process is forced to wait forever.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
This satisfies mutual exclusion but allows
starvation, because
a process stuck in its non-CS never resets turn, so the other process is forced to wait forever.
This is exactly why we make no assumption about progress outside the CS: a correct mutex must not rely on the other thread continuing to take turns.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
The 3rd-try mutex (strict alternation) <pre>p2: while(turn != 1);
p3: critical section
p4: turn = 2</pre> satisfies mutual exclusion but allows {{c1::starvation}}, because {{c2::a process stuck in its non-CS never resets <code>turn</code>, so the other process is forced to wait forever}}. |
<img src="paste-e60da3ffeafc4a6ea4399f57f24e12d83ba28c22.jpg"><br>This satisfies mutual exclusion but allows {{c1::starvation}}, because {{c1::a process stuck in its non-CS never resets <code>turn</code>, so the other process is forced to wait forever}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Note 22: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: ;EvvAz%:Gq
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
FIFO fairness for reader/writer locks: when a writer leaves the CS, the \(k\) readers currently waiting are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives. An arriving writer then has to wait until the readers currently in the CS finish.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
FIFO fairness for reader/writer locks: when a writer leaves the CS, the \(k\) readers currently waiting are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives. An arriving writer then has to wait until the readers currently in the CS finish.
Idea: readers that arrive after a waiting writer must not overtake that writer (analogous to the usual writer priority of common library implementations), but with an explicit quota \(k\) instead of absolute writer precedence.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
FIFO fairness for reader/writer locks: {{c1::when a writer leaves the CS, the \(k\) readers <em>currently waiting</em> are allowed in}}; {{c2::once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives}}. An arriving writer then {{c3::has to wait until the readers currently in the CS finish}}. |
| Extra |
|
Idea: readers that arrive <em>after</em> a waiting writer must not overtake that writer (analogous to the usual writer priority of common library implementations), but with an explicit quota \(k\) instead of absolute writer precedence. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 23: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: ?O|=^.G.3G
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::3._Lazy_Synchronisation
Lazy synchronisation improves the optimistic list in two respects: the list is traversed only once (instead of twice for the validation pass), and contains() never acquires any locks. The trick is to give every node a deleted flag (marker) with the semantics every unmarked node is reachable from head; nodes are first marked and only afterwards "lazily" unlinked from the list.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::3._Lazy_Synchronisation
Lazy synchronisation improves the optimistic list in two respects: the list is traversed only once (instead of twice for the validation pass), and contains() never acquires any locks. The trick is to give every node a deleted flag (marker) with the semantics every unmarked node is reachable from head; nodes are first marked and only afterwards "lazily" unlinked from the list.
The marker replaces the validation step: a thread that locks a node and observes marked == false knows without rescanning that this node is still reachable and valid.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Lazy synchronisation improves the optimistic list in two respects: {{c1::the list is traversed only once}} (instead of twice for the validation pass), and {{c2::<code>contains()</code> never acquires any locks}}. The trick is to give every node a {{c3::<em>deleted</em> flag (marker)}} with the semantics {{c4::every unmarked node is reachable from <code>head</code>}}; nodes are first marked and {{c5::only afterwards "lazily" unlinked from the list}}. |
| Extra |
|
The marker replaces the validation step: a thread that locks a node and observes <code>marked == false</code> knows without rescanning that this node is still reachable and valid. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::3._Lazy_Synchronisation
Note 24: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: Ao9Fa-;N2(
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Practical reader/writer lock implementations usually give priority to writers: once a writer blocks, readers arriving later no longer get the lock before that writer. Otherwise an insert could starve under a steady stream of readers.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Practical reader/writer lock implementations usually give priority to writers: once a writer blocks, readers arriving later no longer get the lock before that writer. Otherwise an insert could starve under a steady stream of readers.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Practical reader/writer lock implementations usually give priority to {{c1::writers}}: once a writer blocks, {{c2::readers arriving later}} no longer get the lock {{c3::before that writer}}. Otherwise an <code>insert</code> could {{c4::starve}} under a steady stream of readers. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 25: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: EK)Cz]ep(U
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Reader/writer lock API. new creates the lock in state not held. acquire_write: block if currently held for reading or held for writing; otherwise transition to held for writing. release_write: make not held. acquire_read: block if currently held for writing; otherwise transition to / stay in held for reading and increment the readers count. release_read: decrement the readers count; if it reaches \(0\), make not held.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Reader/writer lock API. new creates the lock in state not held. acquire_write: block if currently held for reading or held for writing; otherwise transition to held for writing. release_write: make not held. acquire_read: block if currently held for writing; otherwise transition to / stay in held for reading and increment the readers count. release_read: decrement the readers count; if it reaches \(0\), make not held.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Reader/writer lock API. <code>new</code> creates the lock in state <em>not held</em>. {{c1::<code>acquire_write</code>}}: {{c2::block if currently <em>held for reading</em> or <em>held for writing</em>; otherwise transition to <em>held for writing</em>}}. {{c3::<code>release_write</code>}}: {{c4::make <em>not held</em>}}. {{c5::<code>acquire_read</code>}}: {{c6::block if currently <em>held for writing</em>; otherwise transition to / stay in <em>held for reading</em> and increment the readers count}}. {{c7::<code>release_read</code>}}: {{c8::decrement the readers count; if it reaches \(0\), make <em>not held</em>}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 26: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: IY>:8)JAgD
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Why is locking only the node to be deleted not sufficient for remove on a fine-grained linked list?
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Why is locking only the node to be deleted not sufficient for remove on a fine-grained linked list?
A delete has to redirect pred.next, so the predecessor's next field is mutated as well. If thread A locks only node c for remove(c) while thread B in parallel locks only node b for remove(b), they can both proceed: B sets a.next = c, A sets b.next = d, and as a result c remains reachable from a and is not deleted. Fix: lock the predecessor and the node together (hand-over-hand locking).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Why is locking only the node to be deleted <em>not</em> sufficient for <code>remove</code> on a fine-grained linked list? |
| Back |
|
A delete has to redirect <code>pred.next</code>, so the predecessor's <code>next</code> field is mutated as well. If thread A locks only node <code>c</code> for <code>remove(c)</code> while thread B in parallel locks only node <code>b</code> for <code>remove(b)</code>, they can both proceed: B sets <code>a.next = c</code>, A sets <code>b.next = d</code>, and as a result <code>c</code> remains reachable from <code>a</code> and is <em>not</em> deleted. Fix: lock the predecessor and the node together (hand-over-hand locking). |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Note 27: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: OFOX5ohUY9
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
The FIFO-fair RW lock keeps five counters: writers: number of writers in the CS (\(\leq 1\)); readers: number of readers in the CS; writersWaiting: number of writers trying to enter the CS; readersWaiting: number of readers trying to enter the CS; writersWait: number of readers the writers still have to wait for (the remaining quota \(k\)).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
The FIFO-fair RW lock keeps five counters: writers: number of writers in the CS (\(\leq 1\)); readers: number of readers in the CS; writersWaiting: number of writers trying to enter the CS; readersWaiting: number of readers trying to enter the CS; writersWait: number of readers the writers still have to wait for (the remaining quota \(k\)).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
The FIFO-fair RW lock keeps five counters: {{c1::<code>writers</code>}}: {{c2::number of writers in the CS (\(\leq 1\))}}; {{c1::<code>readers</code>}}: {{c2::number of readers in the CS}}; {{c3::<code>writersWaiting</code>}}: {{c4::number of writers trying to enter the CS}}; {{c3::<code>readersWaiting</code>}}: {{c4::number of readers trying to enter the CS}}; {{c5::<code>writersWait</code>}}: {{c6::number of readers the writers still have to wait for (the remaining quota \(k\))}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 28: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: R:_[L,DJMy
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Plain mutual exclusion is unnecessarily conservative when reads dominate: concurrent read/read on the same memory is harmless but still gets serialised. Real conflicts only arise on write/write or read/write. A reader/writer lock therefore allows multiple concurrent readers, but at most one writer and no readers in parallel with that writer.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Plain mutual exclusion is unnecessarily conservative when reads dominate: concurrent read/read on the same memory is harmless but still gets serialised. Real conflicts only arise on write/write or read/write. A reader/writer lock therefore allows multiple concurrent readers, but at most one writer and no readers in parallel with that writer.
Example: a hashtable that almost only sees lookup and rarely insert (Wikipedia: ~0.12% write rate) wastes essentially all parallelism under a coarse-grained mutex. Crucially, lookup must really be read-only (no move-to-front or similar mutation).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Plain mutual exclusion is unnecessarily conservative when reads dominate: {{c1::concurrent <em>read/read</em> on the same memory is harmless}} but still gets serialised. Real conflicts only arise on {{c2::write/write or read/write}}. A <em>reader/writer lock</em> therefore allows {{c3::multiple concurrent readers, but at most one writer and no readers in parallel with that writer}}. |
| Extra |
|
Example: a hashtable that almost only sees <code>lookup</code> and rarely <code>insert</code> (Wikipedia: ~0.12% write rate) wastes essentially all parallelism under a coarse-grained mutex. Crucially, <code>lookup</code> must really be read-only (no <em>move-to-front</em> or similar mutation). |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 29: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: R@>|ZwzI%F
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity
Five granularity levels for synchronisation, from coarse to fine: coarse-grained locking, fine-grained locking, optimistic synchronisation (locking), lazy synchronisation (locking), and finally lock-free synchronisation.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity
Five granularity levels for synchronisation, from coarse to fine: coarse-grained locking, fine-grained locking, optimistic synchronisation (locking), lazy synchronisation (locking), and finally lock-free synchronisation.
Running example throughout the lecture: a Set<T> implemented as a sorted linked list with sentinel nodes at head and tail and operations add, remove, contains.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Five granularity levels for synchronisation, from coarse to fine: {{c1::coarse-grained locking}}, {{c2::fine-grained locking}}, {{c3::optimistic synchronisation (locking)}}, {{c4::lazy synchronisation (locking)}}, and finally {{c5::lock-free synchronisation}}. |
| Extra |
|
Running example throughout the lecture: a <code>Set<T></code> implemented as a sorted linked list with sentinel nodes at head and tail and operations <code>add</code>, <code>remove</code>, <code>contains</code>. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity
Note 30: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: T]qE9q6bY9
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Fine-grained locking: the object is split into pieces with one lock per piece, so that operations on disjoint pieces no longer exclude each other. On a linked list this means one lock per node. In practice it tends to be more intricate than it looks and requires careful handling of special cases.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Fine-grained locking: the object is split into pieces with one lock per piece, so that operations on disjoint pieces no longer exclude each other. On a linked list this means one lock per node. In practice it tends to be more intricate than it looks and requires careful handling of special cases.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Fine-grained locking: {{c1::the object is split into pieces with one lock per piece}}, so that {{c2::operations on disjoint pieces no longer exclude each other}}. On a linked list this means one lock per node. In practice it tends to be {{c3::more intricate than it looks and requires careful handling of special cases}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Note 31: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: XE]|x!N|Fm
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Four rules for using condition waits: always have a condition predicate; test that predicate both before calling wait and after returning from it; always call wait in a while loop, never in an if; ensure the state involved is protected by the lock associated with the condition.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Four rules for using condition waits: always have a condition predicate; test that predicate both before calling wait and after returning from it; always call wait in a while loop, never in an if; ensure the state involved is protected by the lock associated with the condition.
Spurious wakeups, signal-and-continue semantics, and competing signallers all force every woken thread to re-check the predicate itself.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Four rules for using condition waits: {{c1::always have a condition predicate}}; {{c2::test that predicate both <em>before</em> calling <code>wait</code> and <em>after</em> returning from it}}; {{c3::always call <code>wait</code> in a <code>while</code> loop, never in an <code>if</code>}}; {{c4::ensure the state involved is protected by the lock associated with the condition}}. |
| Extra |
|
Spurious wakeups, signal-and-continue semantics, and competing signallers all force every woken thread to re-check the predicate itself. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 32: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: Y5M`wl3>De
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via synchronized methods. Pro: simple and obviously correct. Con: a single bottleneck for all threads, no parallelism even between disjoint operations.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via synchronized methods. Pro: simple and obviously correct. Con: a single bottleneck for all threads, no parallelism even between disjoint operations.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via <code>synchronized</code> methods. Pro: {{c1::simple and obviously correct}}. Con: {{c2::a single bottleneck for all threads, no parallelism even between disjoint operations}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Note 33: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: gU`BMd!40?
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Trade-offs of the optimistic list. Good: no contention during traversal, traversals are wait-free, fewer lock acquisitions than hand-over-hand. Bad: the list has to be traversed twice (search + validation), contains() still has to acquire locks, and the algorithm is not starvation-free (an operation may have to retry arbitrarily often under unfavourable concurrency).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Trade-offs of the optimistic list. Good: no contention during traversal, traversals are wait-free, fewer lock acquisitions than hand-over-hand. Bad: the list has to be traversed twice (search + validation), contains() still has to acquire locks, and the algorithm is not starvation-free (an operation may have to retry arbitrarily often under unfavourable concurrency).
Wait-free: every call finishes in a finite number of steps regardless of what other threads do (in particular it never waits for other threads).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Trade-offs of the optimistic list. <em>Good</em>: {{c1::no contention during traversal}}, {{c2::traversals are wait-free}}, {{c3::fewer lock acquisitions than hand-over-hand}}. <em>Bad</em>: {{c4::the list has to be traversed twice (search + validation)}}, {{c5::<code>contains()</code> still has to acquire locks}}, and {{c6::the algorithm is not starvation-free (an operation may have to retry arbitrarily often under unfavourable concurrency)}}. |
| Extra |
|
<em>Wait-free</em>: every call finishes in a finite number of steps regardless of what other threads do (in particular it <em>never</em> waits for other threads). |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::2._Optimistic_Synchronisation
Note 34: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: grern_
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Simple monitor implementation of a reader/writer lock:
class RWLock {
int writers = 0, readers = 0;
synchronized void acquire_read() {
while (writers > 0) wait();
readers++;
}
synchronized void release_read() { readers--; notifyAll(); }
synchronized void acquire_write() {
while (writers > 0 || readers > 0) wait();
writers++;
}
synchronized void release_write() { writers--; notifyAll(); }
}This naive variant
gives priority to readers:
while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can
starve.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Simple monitor implementation of a reader/writer lock:
class RWLock {
int writers = 0, readers = 0;
synchronized void acquire_read() {
while (writers > 0) wait();
readers++;
}
synchronized void release_read() { readers--; notifyAll(); }
synchronized void acquire_write() {
while (writers > 0 || readers > 0) wait();
writers++;
}
synchronized void release_write() { writers--; notifyAll(); }
}This naive variant
gives priority to readers:
while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can
starve.
Correctness: acquire_write waits until neither writer nor reader is in the CS; acquire_read only waits on writers.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Simple monitor implementation of a reader/writer lock: <pre>class RWLock {
int writers = 0, readers = 0;
synchronized void acquire_read() {
while (writers > 0) wait();
readers++;
}
synchronized void release_read() { readers--; notifyAll(); }
synchronized void acquire_write() {
while (writers > 0 || readers > 0) wait();
writers++;
}
synchronized void release_write() { writers--; notifyAll(); }
}</pre>This naive variant {{c1::gives priority to readers}}: {{c2::while a reader is active, further readers may enter and the writer stays blocked}}, so under a constant stream of readers a writer can {{c3::starve}}. |
| Extra |
|
Correctness: <code>acquire_write</code> waits until neither writer nor reader is in the CS; <code>acquire_read</code> only waits on writers. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 35: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: t6+
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Core logic of the FIFO-fair RW lock. release_write sets writersWait = readersWaiting, i.e. exactly the readers waiting now are allowed through before the next writer. acquire_read blocks while writers > 0 or (writersWaiting > 0 and writersWait <= 0), and on entry decrements writersWait. acquire_write blocks while writers > 0 or readers > 0 or writersWait > 0.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Core logic of the FIFO-fair RW lock. release_write sets writersWait = readersWaiting, i.e. exactly the readers waiting now are allowed through before the next writer. acquire_read blocks while writers > 0 or (writersWaiting > 0 and writersWait <= 0), and on entry decrements writersWait. acquire_write blocks while writers > 0 or readers > 0 or writersWait > 0.
The clause writersWait <= 0 reads as: "the quota of preferred readers is used up, newly arriving readers must wait". When the next writer finishes, the quota is freshly set from the readers that happen to be waiting then.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Core logic of the FIFO-fair RW lock. {{c1::<code>release_write</code>}} sets {{c2::<code>writersWait = readersWaiting</code>}}, i.e. {{c2::exactly the readers waiting <em>now</em> are allowed through before the next writer}}. {{c3::<code>acquire_read</code>}} blocks while {{c4::<code>writers > 0</code> or (<code>writersWaiting > 0</code> and <code>writersWait <= 0</code>)}}, and on entry decrements {{c5::<code>writersWait</code>}}. {{c6::<code>acquire_write</code>}} blocks while {{c7::<code>writers > 0</code> or <code>readers > 0</code> or <code>writersWait > 0</code>}}. |
| Extra |
|
The clause <code>writersWait <= 0</code> reads as: "the quota of preferred readers is used up, newly arriving readers must wait". When the next writer finishes, the quota is freshly set from the readers that happen to be waiting then. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 36: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: tSHEc;NhB;
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Java's synchronized statement does not support reader/writer semantics. The library provides java.util.concurrent.locks.ReentrantReadWriteLock instead. Its methods readLock() and writeLock() each return a lock object with its own lock()/unlock() methods. This implementation has neither writer priority nor reader-to-writer upgrading.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Java's synchronized statement does not support reader/writer semantics. The library provides java.util.concurrent.locks.ReentrantReadWriteLock instead. Its methods readLock() and writeLock() each return a lock object with its own lock()/unlock() methods. This implementation has neither writer priority nor reader-to-writer upgrading.
Re-entrancy is orthogonal to the reader/writer distinction; some libraries do support upgrading a held read lock to a write lock in the same thread.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Java's <code>synchronized</code> statement does not support reader/writer semantics. The library provides {{c1::<code>java.util.concurrent.locks.ReentrantReadWriteLock</code>}} instead. Its methods {{c2::<code>readLock()</code> and <code>writeLock()</code>}} each return {{c3::a lock object with its own <code>lock()</code>/<code>unlock()</code> methods}}. This implementation has {{c4::neither writer priority nor reader-to-writer upgrading}}. |
| Extra |
|
Re-entrancy is orthogonal to the reader/writer distinction; some libraries do support upgrading a held read lock to a write lock in the same thread. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::13._Reader-Writer_Locks
Note 37: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: vPyQ73A=X$
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Disadvantages of hand-over-hand locking on a list: potentially long sequence of acquire/release before the actual operation can take place; a single slow thread holding "early" nodes blocks every other thread that wants to reach "later" nodes (no overtaking).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Disadvantages of hand-over-hand locking on a list: potentially long sequence of acquire/release before the actual operation can take place; a single slow thread holding "early" nodes blocks every other thread that wants to reach "later" nodes (no overtaking).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Disadvantages of hand-over-hand locking on a list: {{c1::potentially long sequence of acquire/release before the actual operation can take place}}; {{c2::a single slow thread holding "early" nodes blocks every other thread that wants to reach "later" nodes (no overtaking)}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::14._Lock_Granularity::1._Coarse_and_Fine_Grained
Note 38: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: w(*5>B[{%<
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
In the 2nd-try mutex
p2: wantp = true;
p3: while(wantq);
p4: critical section
the order "first set my flag, then wait" satisfies mutual exclusion but
deadlocks, because {{c2::both threads can set their flags before either reads the other's, leaving both stuck spinning at state \((p3, q3, \text{true}, \text{true})\)}}.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
In the 2nd-try mutex
p2: wantp = true;
p3: while(wantq);
p4: critical section
the order "first set my flag, then wait" satisfies mutual exclusion but
deadlocks, because {{c2::both threads can set their flags before either reads the other's, leaving both stuck spinning at state \((p3, q3, \text{true}, \text{true})\)}}.
Trade-off compared with the 1st try: ME is now ensured (the flag is set before the check), but the symmetric race produces a stable bad state. No process is making progress, yet none is starving in the technical sense - it is a true deadlock.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers

Here the order "first set my flag, then wait" satisfies mutual exclusion but
deadlocks, because {{c1::both threads can set their flags before either reads the other's, leaving both stuck spinning at state \((p3, q3, \text{true}, \text{true})\)}}.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Here the order "first set my flag, then wait" satisfies mutual exclusion but
deadlocks, because {{c1::both threads can set their flags before either reads the other's, leaving both stuck spinning at state \((p3, q3, \text{true}, \text{true})\)}}.
Trade-off compared with the 1st try: ME is now ensured (the flag is set before the check), but the symmetric race produces a stable bad state. No process is making progress, yet none is starving in the technical sense - it is a true deadlock.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
In the 2nd-try mutex <pre>p2: wantp = true;
p3: while(wantq);
p4: critical section</pre> the order "first set my flag, then wait" satisfies mutual exclusion but {{c1::deadlocks}}, because {{c2::both threads can set their flags before either reads the other's, leaving both stuck spinning at state \((p3, q3, \text{true}, \text{true})\)}}. |
<img src="paste-d5afea784fd8b8f11424f219bcbea70640999891.jpg"><br>Here the order "first set my flag, then wait" satisfies mutual exclusion but {{c1::deadlocks}}, because {{c1::both threads can set their flags before either reads the other's, leaving both stuck spinning at state \((p3, q3, \text{true}, \text{true})\)}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers