Note 1: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: I(y+n3Ez0R
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Seien \(A_1, \ldots, A_n\) paarweise disjunkte Ereignisse und sei \(B \subseteq A_1 \cup \cdots \cup A_n\).
Dann gilt: \[\Pr[B] = {{c1::\sum_{i=1}^{n} \Pr[B|A_i] \cdot \Pr[A_i]}}.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Seien \(A_1, \ldots, A_n\) paarweise disjunkte Ereignisse und sei \(B \subseteq A_1 \cup \cdots \cup A_n\).
Dann gilt: \[\Pr[B] = {{c1::\sum_{i=1}^{n} \Pr[B|A_i] \cdot \Pr[A_i]}}.\]
Satz von der totalen Wahrscheinlichkeit
Beispiel: Ziegenproblem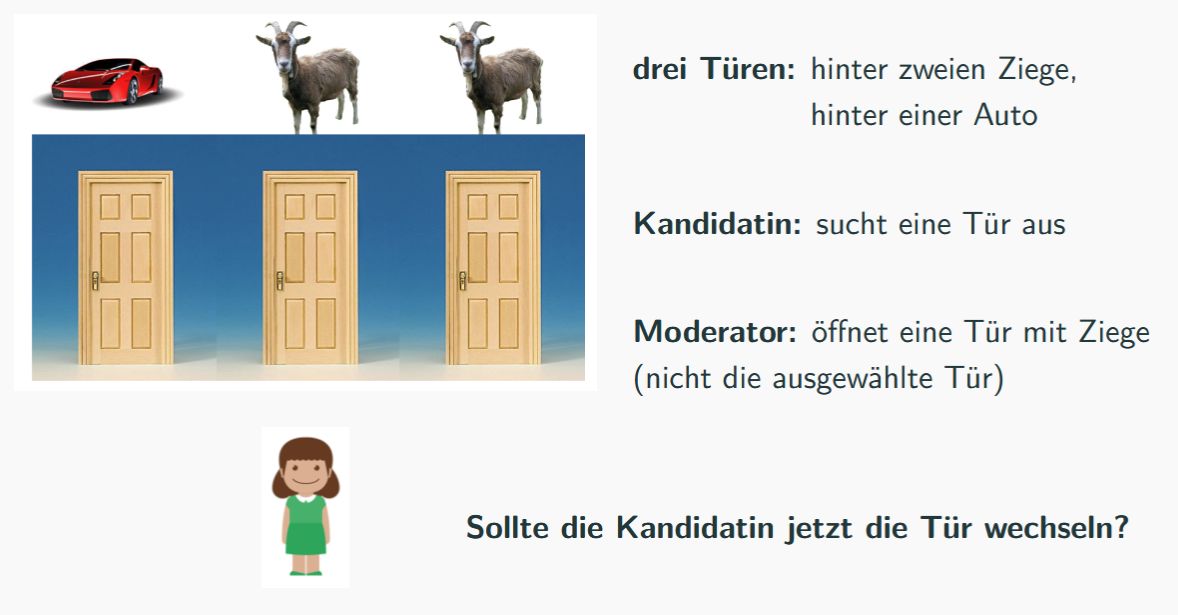
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Seien \(A_1, \ldots, A_n\) paarweise disjunkte Ereignisse und sei \(B \subseteq A_1 \cup \cdots \cup A_n\).
Dann gilt: \[\Pr[B] = {{c1::\sum_{i=1}^{n} \Pr[B\mid A_i] \cdot \Pr[A_i]}}.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Seien \(A_1, \ldots, A_n\) paarweise disjunkte Ereignisse und sei \(B \subseteq A_1 \cup \cdots \cup A_n\).
Dann gilt: \[\Pr[B] = {{c1::\sum_{i=1}^{n} \Pr[B\mid A_i] \cdot \Pr[A_i]}}.\]
Satz von der totalen Wahrscheinlichkeit
Beispiel: Ziegenproblem
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Seien \(A_1, \ldots, A_n\) paarweise disjunkte Ereignisse und sei \(B \subseteq A_1 \cup \cdots \cup A_n\).
<br><br>
Dann gilt: \[\Pr[B] = {{c1::\sum_{i=1}^{n} \Pr[B|A_i] \cdot \Pr[A_i]}}.\] |
Seien \(A_1, \ldots, A_n\) paarweise disjunkte Ereignisse und sei \(B \subseteq A_1 \cup \cdots \cup A_n\).
<br><br>
Dann gilt: \[\Pr[B] = {{c1::\sum_{i=1}^{n} \Pr[B\mid A_i] \cdot \Pr[A_i]}}.\] |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Note 2: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_06f8d72e
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
The density function (Dichtefunktion) of a random variable \(X\) is:
\[ {{c1:: f_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X=x]}}. \]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
The density function (Dichtefunktion) of a random variable \(X\) is:
\[ {{c1:: f_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X=x]}}. \]
It is zero outside \(W_X\). The density function uniquely determines the random variable's distribution.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
Die Dichtefunktion einer Zufallsvariablen \(X\) ist:
\[ {{c1:: f_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X=x]}}. \]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
Die Dichtefunktion einer Zufallsvariablen \(X\) ist:
\[ {{c1:: f_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X=x]}}. \]
Sie ist null ausserhalb von \(W_X\). Die Dichtefunktion bestimmt die Verteilung der Zufallsvariablen eindeutig.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
The <strong>density function</strong> (Dichtefunktion) of a random variable \(X\) is:<br>\[ {{c1:: f_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X=x]}}. \] |
Die <strong>Dichtefunktion</strong> einer Zufallsvariablen \(X\) ist:<br>\[ {{c1:: f_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X=x]}}. \] |
| Extra |
It is zero outside \(W_X\). The density function uniquely determines the random variable's distribution. |
Sie ist null ausserhalb von \(W_X\). Die Dichtefunktion bestimmt die Verteilung der Zufallsvariablen eindeutig. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
Note 3: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: sc_0aab872f
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Warum muss für Unabhängigkeit die Produktregel für alle Teilmengen gelten, und nicht nur für die paarweisen oder den vollen Schnitt?
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Warum muss für Unabhängigkeit die Produktregel für alle Teilmengen gelten, und nicht nur für die paarweisen oder den vollen Schnitt?
Paarweise \(\not \implies\) vollen Schnitt: Zwei faire Münzen, \(A=\)„\(M_1\) Kopf", \(B=\)„\(M_2\) Kopf", \(C=\)„Ergebnisse verschieden": je zwei Ereignisse sind unabhängig, aber \(\Pr[A\cap B\cap C]=0\neq\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\).
Voller Schnitt \(\not \implies\) paarweise: Zufallszahl in \(\{1,\ldots,8\}\), \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\): \(\Pr[A\cap B\cap C]=\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\), aber \(\Pr[A\cap B]=\tfrac{1}{8}\neq\tfrac{1}{4}=\Pr[A]\Pr[B]\).
Beide Bedingungen zusammen sind nötig — daher fordert Unabhängigkeit die Produktregel für alle nichtleeren Teilmengen.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Warum muss für Unabhängigkeit die Produktregel für alle Teilmengen gelten, und nicht nur für die paarweisen oder den vollen Schnitt?
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Warum muss für Unabhängigkeit die Produktregel für alle Teilmengen gelten, und nicht nur für die paarweisen oder den vollen Schnitt?
Beide Bedingungen zusammen sind nötig - daher fordert Unabhängigkeit die Produktregel für alle nichtleeren Teilmengen.
Paarweise \(\not \implies\) vollen Schnitt: Zwei faire Münzen, \(A=\)„\(M_1\) Kopf", \(B=\)„\(M_2\) Kopf", \(C=\)„Ergebnisse verschieden": je zwei Ereignisse sind unabhängig, aber \(\Pr[A\cap B\cap C]=0\neq\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\).
Voller Schnitt \(\not \implies\) paarweise: Zufallszahl in \(\{1,\ldots,8\}\), \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\): \(\Pr[A\cap B\cap C]=\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\), aber \(\Pr[A\cap B]=\tfrac{1}{8}\neq\tfrac{1}{4}=\Pr[A]\Pr[B]\).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
<strong>Paarweise \(\not \implies\) vollen Schnitt:</strong> Zwei faire Münzen, \(A=\)„\(M_1\) Kopf", \(B=\)„\(M_2\) Kopf", \(C=\)„Ergebnisse verschieden": je zwei Ereignisse sind unabhängig, aber \(\Pr[A\cap B\cap C]=0\neq\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\).<br><br><strong>Voller Schnitt \(\not \implies\) paarweise:</strong> Zufallszahl in \(\{1,\ldots,8\}\), \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\): \(\Pr[A\cap B\cap C]=\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\), aber \(\Pr[A\cap B]=\tfrac{1}{8}\neq\tfrac{1}{4}=\Pr[A]\Pr[B]\).<br><br>Beide Bedingungen zusammen sind nötig — daher fordert Unabhängigkeit die Produktregel für <strong>alle</strong> nichtleeren Teilmengen. |
Beide Bedingungen <b>zusammen </b>sind nötig - daher fordert Unabhängigkeit die Produktregel für <b>alle</b> nichtleeren Teilmengen.<br><br><b>Paarweise </b>\(\not \implies\)<b> vollen Schnitt:</b> Zwei faire Münzen, \(A=\)„\(M_1\) Kopf", \(B=\)„\(M_2\) Kopf", \(C=\)„Ergebnisse verschieden": je zwei Ereignisse sind unabhängig, aber \(\Pr[A\cap B\cap C]=0\neq\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\).<br><br><b>Voller Schnitt </b>\(\not \implies\)<b> paarweise:</b> Zufallszahl in \(\{1,\ldots,8\}\), \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\): \(\Pr[A\cap B\cap C]=\tfrac{1}{8}=\Pr[A]\Pr[B]\Pr[C]\), aber \(\Pr[A\cap B]=\tfrac{1}{8}\neq\tfrac{1}{4}=\Pr[A]\Pr[B]\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Note 4: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_1de913c2
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Linearität) For \(X=a_1X_1+\cdots+a_nX_n+b\):
\[ \mathbb{E}[X] = {{c1::a_1\mathbb{E}[X_1]+\cdots+a_n\mathbb{E}[X_n]+b}}\]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Linearität) For \(X=a_1X_1+\cdots+a_nX_n+b\):
\[ \mathbb{E}[X] = {{c1::a_1\mathbb{E}[X_1]+\cdots+a_n\mathbb{E}[X_n]+b}}\]
Proof Included
Holds even if \(X_1,\ldots,X_n\) are not independent.
Proof:
Using Lemma 2.29 (\(\mathbb{E}[X]=\sum_\omega X(\omega)\Pr[\omega]\)):
\[ \mathbb{E}[X]=\sum_\omega(a_1X_1(\omega)+\cdots+a_nX_n(\omega)+b)\Pr[\omega] =a_1\underbrace{\sum_\omega X_1(\omega)\Pr[\omega]}_{=\mathbb{E}[X_1]}+\cdots+b\underbrace{\sum_\omega\Pr[\omega]}_{=1}.\quad\square \]
The key is that the outer sum \(\sum_\omega\) distributes over the linear combination.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Für \(X=a_1X_1+\cdots+a_nX_n+b\):
\[ \mathbb{E}[X] = {{c1::a_1\mathbb{E}[X_1]+\cdots+a_n\mathbb{E}[X_n]+b}}\]Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Für \(X=a_1X_1+\cdots+a_nX_n+b\):
\[ \mathbb{E}[X] = {{c1::a_1\mathbb{E}[X_1]+\cdots+a_n\mathbb{E}[X_n]+b}}\]Proof Included
(Linearität)
Gilt auch wenn \(X_1,\ldots,X_n\) nicht unabhängig sind.
Proof:
Mit Lemma 2.29 (\(\mathbb{E}[X]=\sum_\omega X(\omega)\Pr[\omega]\)):
\[ \mathbb{E}[X]=\sum_\omega(a_1X_1(\omega)+\cdots+a_nX_n(\omega)+b)\Pr[\omega] =a_1\underbrace{\sum_\omega X_1(\omega)\Pr[\omega]}_{=\mathbb{E}[X_1]}+\cdots+b\underbrace{\sum_\omega\Pr[\omega]}_{=1}.\quad\square \]
Der Schlüssel ist, dass die äussere Summe \(\sum_\omega\) sich über die Linearkombination verteilt.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
(<b>Linearität</b>) For \(X=a_1X_1+\cdots+a_nX_n+b\):<br>\[ \mathbb{E}[X] = {{c1::a_1\mathbb{E}[X_1]+\cdots+a_n\mathbb{E}[X_n]+b}}\]<br> <em>Proof Included</em> |
Für \(X=a_1X_1+\cdots+a_nX_n+b\):<br>\[ \mathbb{E}[X] = {{c1::a_1\mathbb{E}[X_1]+\cdots+a_n\mathbb{E}[X_n]+b}}\]<em>Proof Included</em> |
| Extra |
Holds even if \(X_1,\ldots,X_n\) are <strong>not independent</strong>.<strong><br><br>Proof:</strong><br>Using Lemma 2.29 (\(\mathbb{E}[X]=\sum_\omega X(\omega)\Pr[\omega]\)):<br>\[ \mathbb{E}[X]=\sum_\omega(a_1X_1(\omega)+\cdots+a_nX_n(\omega)+b)\Pr[\omega] =a_1\underbrace{\sum_\omega X_1(\omega)\Pr[\omega]}_{=\mathbb{E}[X_1]}+\cdots+b\underbrace{\sum_\omega\Pr[\omega]}_{=1}.\quad\square \]<br>The key is that the outer sum \(\sum_\omega\) distributes over the linear combination. |
(Linearität)<br><br>Gilt auch wenn \(X_1,\ldots,X_n\) <b>nicht unabhängig</b> sind.<br><br><b>Proof:</b><br>Mit Lemma 2.29 (\(\mathbb{E}[X]=\sum_\omega X(\omega)\Pr[\omega]\)):<br>\[ \mathbb{E}[X]=\sum_\omega(a_1X_1(\omega)+\cdots+a_nX_n(\omega)+b)\Pr[\omega] =a_1\underbrace{\sum_\omega X_1(\omega)\Pr[\omega]}_{=\mathbb{E}[X_1]}+\cdots+b\underbrace{\sum_\omega\Pr[\omega]}_{=1}.\quad\square \]<br>Der Schlüssel ist, dass die äussere Summe \(\sum_\omega\) sich über die Linearkombination verteilt. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Note 5: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_1eb62870
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Gesetz der totalen Erwartung, not script) Let \(A_1,\ldots,A_n\) partition \(\Omega\) with all \(\Pr[A_i]>0\). Then:
\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{n}\mathbb{E}[X|A_i]\cdot\Pr[A_i]}}. \]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Gesetz der totalen Erwartung, not script) Let \(A_1,\ldots,A_n\) partition \(\Omega\) with all \(\Pr[A_i]>0\). Then:
\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{n}\mathbb{E}[X|A_i]\cdot\Pr[A_i]}}. \]
Proof Included
Proof:
\[\begin{align} \mathbb{E}[X] &=\sum_{x}x\cdot\Pr[X=x] \\ &\overset{\text{total prob}}{=}\sum_x x\sum_i\Pr[X=x|A_i]\Pr[A_i] \\ &=\sum_i\Pr[A_i]\underbrace{\sum_x x\Pr[X=x|A_i]}_{=\mathbb{E}[X|A_i]} \end{align}\]
(Uses the law of total probability to expand \(\Pr[X=x]\), then swaps summation order.)
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Sei \(A_1,\ldots,A_n\) eine Partition von \(\Omega\) mit \(\Pr[A_i]>0\) für alle \(i\).
Dann:\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{n}\mathbb{E}[X\mid A_i]\cdot\Pr[A_i]}}. \]Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Sei \(A_1,\ldots,A_n\) eine Partition von \(\Omega\) mit \(\Pr[A_i]>0\) für alle \(i\).
Dann:\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{n}\mathbb{E}[X\mid A_i]\cdot\Pr[A_i]}}. \]Proof Included
(Gesetz der totalen Erwartung, nicht im Skript!)
Proof:
\[\begin{align} \mathbb{E}[X] &=\sum_{x}x\cdot\Pr[X=x] \\ &\overset{\text{totale W'keit}}{=}\sum_x x\sum_i\Pr[X=x|A_i]\Pr[A_i] \\ &=\sum_i\Pr[A_i]\underbrace{\sum_x x\Pr[X=x|A_i]}_{=\mathbb{E}[X|A_i]} \end{align}\]
(Verwendet das Gesetz der totalen Wahrscheinlichkeit um \(\Pr[X=x]\) zu expandieren, dann wird die Summationsreihenfolge vertauscht.)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>(Gesetz der totalen Erwartung, not script)</b> Let \(A_1,\ldots,A_n\) partition \(\Omega\) with all \(\Pr[A_i]>0\). Then:<br>\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{n}\mathbb{E}[X|A_i]\cdot\Pr[A_i]}}. \]<br><em>Proof Included</em> |
Sei \(A_1,\ldots,A_n\) eine Partition von \(\Omega\) mit \(\Pr[A_i]>0\) für alle \(i\). <br>Dann:\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{n}\mathbb{E}[X\mid A_i]\cdot\Pr[A_i]}}. \]<em>Proof Included</em> |
| Extra |
<strong>Proof:</strong><br>\[\begin{align} \mathbb{E}[X] &=\sum_{x}x\cdot\Pr[X=x] \\ &\overset{\text{total prob}}{=}\sum_x x\sum_i\Pr[X=x|A_i]\Pr[A_i] \\ &=\sum_i\Pr[A_i]\underbrace{\sum_x x\Pr[X=x|A_i]}_{=\mathbb{E}[X|A_i]} \end{align}\]<br>(Uses the law of total probability to expand \(\Pr[X=x]\), then swaps summation order.) |
(Gesetz der totalen Erwartung, nicht im Skript!) <br><br><b>Proof:</b><br>\[\begin{align} \mathbb{E}[X] &=\sum_{x}x\cdot\Pr[X=x] \\ &\overset{\text{totale W'keit}}{=}\sum_x x\sum_i\Pr[X=x|A_i]\Pr[A_i] \\ &=\sum_i\Pr[A_i]\underbrace{\sum_x x\Pr[X=x|A_i]}_{=\mathbb{E}[X|A_i]} \end{align}\]<br>(Verwendet das Gesetz der totalen Wahrscheinlichkeit um \(\Pr[X=x]\) zu expandieren, dann wird die Summationsreihenfolge vertauscht.) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Note 6: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_3121875f
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
(Definition 2.22) Events \(A_1,\ldots,A_n\) are called independent (unabhängig) if {{c1::for all subsets
\(I\subseteq\{1,\ldots,n\}\) with \(I=\{i_1,\ldots,i_k\} \)}}:
\[ \Pr\!\left[A_{i_1}\cap\cdots\cap A_{i_k}\right] = {{c1::\Pr[A_{i_1}]\cdots\Pr[A_{i_k}]}}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
(Definition 2.22) Events \(A_1,\ldots,A_n\) are called independent (unabhängig) if {{c1::for all subsets
\(I\subseteq\{1,\ldots,n\}\) with \(I=\{i_1,\ldots,i_k\} \)}}:
\[ \Pr\!\left[A_{i_1}\cap\cdots\cap A_{i_k}\right] = {{c1::\Pr[A_{i_1}]\cdots\Pr[A_{i_k}]}}\]
The definition requires the product rule for
every non-empty sub-intersection — not just pairwise intersections, and not just the full \(n\)-fold intersection. Both conditions alone are insufficient:
- Pairwise \(\not \implies\) full intersection: two fair coins, \(A=\)"\(M_1\) heads", \(B=\)"\(M_2\) heads", \(C=\)"results differ" are pairwise independent but \(\Pr[A\cap B\cap C]=0\neq\Pr[A]\Pr[B]\Pr[C]\).
- Full intersection \(\not \implies\) pairwise: \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\) in \(\{1,\ldots,8\}\): \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) but \(A,B\) are not independent.
The total number of conditions to check for \(n\) events is \(2^n-1\) (all non-empty subsets of \(\{1,\ldots,n\}\)).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Ereignisse \(A_1,\ldots,A_n\) heissen unabhängig, falls für {{c1::alle Teilmengen \(I\subseteq\{1,\ldots,n\}\) mit \(I=\{i_1,\ldots,i_k\} \)}} gilt:
\[ \Pr\!\left[A_{i_1}\cap\cdots\cap A_{i_k}\right] = {{c2::\Pr[A_{i_1}]\cdots\Pr[A_{i_k}]}}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Ereignisse \(A_1,\ldots,A_n\) heissen unabhängig, falls für {{c1::alle Teilmengen \(I\subseteq\{1,\ldots,n\}\) mit \(I=\{i_1,\ldots,i_k\} \)}} gilt:
\[ \Pr\!\left[A_{i_1}\cap\cdots\cap A_{i_k}\right] = {{c2::\Pr[A_{i_1}]\cdots\Pr[A_{i_k}]}}\]
(Definition 2.22)
Die Definition verlangt die Produktregel für
jede nicht-leere Teil-Durchschnittsmenge - nicht nur paarweise Durchschnitte und nicht nur den vollen \(n\)-fachen Durchschnitt. Beide Bedingungen allein sind unzureichend:
- Paarweise \(\not \implies\) voller Durchschnitt: zwei faire Münzen, \(A=\)"\(M_1\) Kopf", \(B=\)"\(M_2\) Kopf", \(C=\)"Ergebnisse unterscheiden sich" sind paarweise unabhängig, aber \(\Pr[A\cap B\cap C]=0\neq\Pr[A]\Pr[B]\Pr[C]\).
- Voller Durchschnitt \(\not \implies\) paarweise: \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\) in \(\{1,\ldots,8\}\): \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\), aber \(A,B\) sind nicht unabhängig.
Die Gesamtzahl der zu prüfenden Bedingungen für \(n\) Ereignisse ist \(2^n-1\) (alle nicht-leeren Teilmengen von \(\{1,\ldots,n\}\)).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
(Definition 2.22) Events \(A_1,\ldots,A_n\) are called <strong>independent</strong> (unabhängig) if {{c1::for <strong>all</strong> subsets<br>\(I\subseteq\{1,\ldots,n\}\) with \(I=\{i_1,\ldots,i_k\} \)}}:<br>\[ \Pr\!\left[A_{i_1}\cap\cdots\cap A_{i_k}\right] = {{c1::\Pr[A_{i_1}]\cdots\Pr[A_{i_k}]}}\] |
Ereignisse \(A_1,\ldots,A_n\) heissen <strong>unabhängig,</strong> falls für {{c1::<strong>alle</strong> Teilmengen \(I\subseteq\{1,\ldots,n\}\) mit \(I=\{i_1,\ldots,i_k\} \)}} gilt:<br>\[ \Pr\!\left[A_{i_1}\cap\cdots\cap A_{i_k}\right] = {{c2::\Pr[A_{i_1}]\cdots\Pr[A_{i_k}]}}\] |
| Extra |
The definition requires the product rule for <strong>every</strong> non-empty sub-intersection — not just pairwise intersections, and not just the full \(n\)-fold intersection. Both conditions alone are insufficient:<br><br><ul><li>Pairwise \(\not \implies\) full intersection: two fair coins, \(A=\)"\(M_1\) heads", \(B=\)"\(M_2\) heads", \(C=\)"results differ" are pairwise independent but \(\Pr[A\cap B\cap C]=0\neq\Pr[A]\Pr[B]\Pr[C]\).</li><li>Full intersection \(\not \implies\) pairwise: \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\) in \(\{1,\ldots,8\}\): \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) but \(A,B\) are not independent.</li></ul><br>The total number of conditions to check for \(n\) events is \(2^n-1\) (all non-empty subsets of \(\{1,\ldots,n\}\)).<br> |
(Definition 2.22) <br><br>Die Definition verlangt die Produktregel für <strong>jede</strong> nicht-leere Teil-Durchschnittsmenge - nicht nur paarweise Durchschnitte und nicht nur den vollen \(n\)-fachen Durchschnitt. Beide Bedingungen allein sind unzureichend:<br><br><ul><li>Paarweise \(\not \implies\) voller Durchschnitt: zwei faire Münzen, \(A=\)"\(M_1\) Kopf", \(B=\)"\(M_2\) Kopf", \(C=\)"Ergebnisse unterscheiden sich" sind paarweise unabhängig, aber \(\Pr[A\cap B\cap C]=0\neq\Pr[A]\Pr[B]\Pr[C]\).</li><li>Voller Durchschnitt \(\not \implies\) paarweise: \(A=\{1,2,3,4\}\), \(B=\{1,5,6,7\}\), \(C=B\) in \(\{1,\ldots,8\}\): \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\), aber \(A,B\) sind nicht unabhängig.</li></ul><br>Die Gesamtzahl der zu prüfenden Bedingungen für \(n\) Ereignisse ist \(2^n-1\) (alle nicht-leeren Teilmengen von \(\{1,\ldots,n\}\)).<br> |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Note 7: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_32a73428
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
(Satz von Bayes) Let \(A_1,\ldots,A_n\) be pairwise disjoint, \(B\subseteq\bigcup A_i\), \(\Pr[B]>0\). Then for any \(i\):
\[ \Pr[A_i|B] = {{c1::\frac{\Pr[B|A_i]\cdot\Pr[A_i]}{\sum_{j=1}^{n}\Pr[B|A_j]\cdot\Pr[A_j]} }}. \]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
(Satz von Bayes) Let \(A_1,\ldots,A_n\) be pairwise disjoint, \(B\subseteq\bigcup A_i\), \(\Pr[B]>0\). Then for any \(i\):
\[ \Pr[A_i|B] = {{c1::\frac{\Pr[B|A_i]\cdot\Pr[A_i]}{\sum_{j=1}^{n}\Pr[B|A_j]\cdot\Pr[A_j]} }}. \]
Proof Included
Proof: By definition \(\Pr[A_i|B]=\Pr[A_i\cap B]/\Pr[B]\). Numerator: \(\Pr[A_i\cap B]=\Pr[B|A_i]\cdot\Pr[A_i]\). Denominator: \(\Pr[B]=\sum_j\Pr[B|A_j]\Pr[A_j]\) (total probability). \(\square\)
Key use: "Invert" the direction of conditioning — from \(\Pr[B|A_i]\) (easy to measure) to \(\Pr[A_i|B]\) (what we want to know).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Seien \(A_1,\ldots,A_n\) paarweise disjunkt, \(B\subseteq\bigcup A_i\), \(\Pr[B]>0\).
Dann gilt für jedes \(i\):
\[ \Pr[A_i|B] = {{c1::\frac{\Pr[B|A_i]\cdot\Pr[A_i]}{\sum_{j=1}^{n}\Pr[B|A_j]\cdot\Pr[A_j]} }}. \]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Seien \(A_1,\ldots,A_n\) paarweise disjunkt, \(B\subseteq\bigcup A_i\), \(\Pr[B]>0\).
Dann gilt für jedes \(i\):
\[ \Pr[A_i|B] = {{c1::\frac{\Pr[B|A_i]\cdot\Pr[A_i]}{\sum_{j=1}^{n}\Pr[B|A_j]\cdot\Pr[A_j]} }}. \]
Proof Included
(Satz von Bayes)
Proof:
Nach Definition gilt \(\Pr[A_i|B]=\Pr[A_i\cap B]/\Pr[B]\).
Zähler: \(\Pr[A_i\cap B]=\Pr[B|A_i]\cdot\Pr[A_i]\).
Nenner: \(\Pr[B]=\sum_j\Pr[B|A_j]\Pr[A_j]\) (totale Wahrscheinlichkeit). \(\square\)
Zentrale Anwendung:
Die Konditionierungsrichtung "umkehren" - von \(\Pr[B|A_i]\) (leicht zu messen) zu \(\Pr[A_i|B]\) (was wir wissen wollen).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
(Satz von <b>Bayes</b>) Let \(A_1,\ldots,A_n\) be pairwise disjoint, \(B\subseteq\bigcup A_i\), \(\Pr[B]>0\). Then for any \(i\):<br>\[ \Pr[A_i|B] = {{c1::\frac{\Pr[B|A_i]\cdot\Pr[A_i]}{\sum_{j=1}^{n}\Pr[B|A_j]\cdot\Pr[A_j]} }}. \]<br><em>Proof Included</em> |
Seien \(A_1,\ldots,A_n\) paarweise disjunkt, \(B\subseteq\bigcup A_i\), \(\Pr[B]>0\). <br>Dann gilt für jedes \(i\):<br>\[ \Pr[A_i|B] = {{c1::\frac{\Pr[B|A_i]\cdot\Pr[A_i]}{\sum_{j=1}^{n}\Pr[B|A_j]\cdot\Pr[A_j]} }}. \]<br><em>Proof Included</em> |
| Extra |
<strong>Proof:</strong> By definition \(\Pr[A_i|B]=\Pr[A_i\cap B]/\Pr[B]\). Numerator: \(\Pr[A_i\cap B]=\Pr[B|A_i]\cdot\Pr[A_i]\). Denominator: \(\Pr[B]=\sum_j\Pr[B|A_j]\Pr[A_j]\) (total probability). \(\square\)<br><br><strong>Key use:</strong> "Invert" the direction of conditioning — from \(\Pr[B|A_i]\) (easy to measure) to \(\Pr[A_i|B]\) (what we want to know). |
(Satz von Bayes)<strong><br><br>Proof:</strong> <br>Nach Definition gilt \(\Pr[A_i|B]=\Pr[A_i\cap B]/\Pr[B]\). <br>Zähler: \(\Pr[A_i\cap B]=\Pr[B|A_i]\cdot\Pr[A_i]\). <br>Nenner: \(\Pr[B]=\sum_j\Pr[B|A_j]\Pr[A_j]\) (totale Wahrscheinlichkeit). \(\square\)<br><br><strong>Zentrale Anwendung:</strong> <br>Die Konditionierungsrichtung "umkehren" - von \(\Pr[B|A_i]\) (leicht zu messen) zu \(\Pr[A_i|B]\) (was wir wissen wollen). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Note 8: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_35dcd411
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Expected Value as Sum) For any random variable \(X\):
\[ \mathbb{E}[X] = {{c1::\sum_{\omega\in\Omega} X(\omega)\cdot\Pr[\omega]::weighted sum definition}} \]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Expected Value as Sum) For any random variable \(X\):
\[ \mathbb{E}[X] = {{c1::\sum_{\omega\in\Omega} X(\omega)\cdot\Pr[\omega]::weighted sum definition}} \]
Proof Included
Proof:
\[\begin{align} \mathbb{E}[X] &= \sum_{x\in W_X}x\cdot\Pr[X=x] \\ &=\sum_{x\in W_X}x\cdot\sum_{\omega: X(\omega)=x}\Pr[\omega] \\&=\sum_{\omega\in\Omega}X(\omega)\cdot\Pr[\omega].\quad \end{align}\]
(Switch the order of summation: group by \(\omega\) instead of by value \(x\).)
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Für jede Zufallsvariable \(X\):
\[ \mathbb{E}[X] = {{c1::\sum_{\omega\in\Omega} X(\omega)\cdot\Pr[\omega]::\text{gewichtete Summe} }} \]Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Für jede Zufallsvariable \(X\):
\[ \mathbb{E}[X] = {{c1::\sum_{\omega\in\Omega} X(\omega)\cdot\Pr[\omega]::\text{gewichtete Summe} }} \]Proof Included
(Erwartungswert als Summe)
Proof:
\[\begin{align} \mathbb{E}[X] &= \sum_{x\in W_X}x\cdot\Pr[X=x] \\ &=\sum_{x\in W_X}x\cdot\sum_{\omega: X(\omega)=x}\Pr[\omega] \\&=\sum_{\omega\in\Omega}X(\omega)\cdot\Pr[\omega].\quad \end{align}\]
(Summationsreihenfolge vertauschen: nach \(\omega\) gruppieren statt nach Wert \(x\).)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
(<b>Expected Value as Sum</b>) For any random variable \(X\):<br>\[ \mathbb{E}[X] = {{c1::\sum_{\omega\in\Omega} X(\omega)\cdot\Pr[\omega]::weighted sum definition}} \]<br><em>Proof Included</em> |
Für jede Zufallsvariable \(X\):<br>\[ \mathbb{E}[X] = {{c1::\sum_{\omega\in\Omega} X(\omega)\cdot\Pr[\omega]::\text{gewichtete Summe} }} \]<em>Proof Included</em> |
| Extra |
<strong>Proof:</strong><br>\[\begin{align} \mathbb{E}[X] &= \sum_{x\in W_X}x\cdot\Pr[X=x] \\ &=\sum_{x\in W_X}x\cdot\sum_{\omega: X(\omega)=x}\Pr[\omega] \\&=\sum_{\omega\in\Omega}X(\omega)\cdot\Pr[\omega].\quad \end{align}\]<br>(Switch the order of summation: group by \(\omega\) instead of by value \(x\).) |
(Erwartungswert als Summe)<br><br><b>Proof:</b><br>\[\begin{align} \mathbb{E}[X] &= \sum_{x\in W_X}x\cdot\Pr[X=x] \\ &=\sum_{x\in W_X}x\cdot\sum_{\omega: X(\omega)=x}\Pr[\omega] \\&=\sum_{\omega\in\Omega}X(\omega)\cdot\Pr[\omega].\quad \end{align}\]<br>(Summationsreihenfolge vertauschen: nach \(\omega\) gruppieren statt nach Wert \(x\).) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Note 9: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: sc_38d18cae
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
(Geburtstagsproblem) In a group of \(m\) people (with \(n=365\) days), what is the probability that all birthdays are distinct? Derive the formula. Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
(Geburtstagsproblem) In a group of \(m\) people (with \(n=365\) days), what is the probability that all birthdays are distinct? Derive the formula. Proof Included
Model: throw \(m\) balls into \(n\) bins uniformly. Let \(A_j\) = "ball \(j\) lands in an empty bin."
By the Multiplikationssatz:
\[ \Pr\!\left[\bigcap_{j=1}^m A_j\right] = \prod_{j=2}^{m} \frac{n-(j-1)}{n} = \prod_{j=2}^{m}\!\left(1-\frac{j-1}{n}\right). \]
Upper bound using \(1-x \le e^{-x}\):
\[ \Pr[\text{all distinct}] \le \prod_{j=2}^{m} e^{-(j-1)/n} = e^{-m(m-1)/(2n)}. \]
So the probability of at least one collision is \(\ge 1 - e^{-m(m-1)/(2n)}\). \(\square\)
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
In einer Gruppe von \(m\) Personen (mit \(n=365\) Tagen), wie gross ist die Wahrscheinlichkeit, dass alle Geburtstage verschieden sind? Leite die Formel her.
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
In einer Gruppe von \(m\) Personen (mit \(n=365\) Tagen), wie gross ist die Wahrscheinlichkeit, dass alle Geburtstage verschieden sind? Leite die Formel her.
Proof Included
(Geburtstagsproblem)
Modell:
Werfe \(m\) Bälle gleichverteilt in \(n\) Urnen.
Sei \(A_j\) = "Ball \(j\) landet in einer leeren Urne."
Mit dem Multiplikationssatz:\[ \Pr\!\left[\bigcap_{j=1}^m A_j\right] = \prod_{j=2}^{m} \frac{n-(j-1)}{n} = \prod_{j=2}^{m}\!\left(1-\frac{j-1}{n}\right). \]Obere Schranke mit \(1-x \le e^{-x}\):\[ \Pr[\text{alle verschieden}] \le \prod_{j=2}^{m} e^{-(j-1)/n} = e^{-m(m-1)/(2n)}. \]Also ist die Wahrscheinlichkeit für mindestens eine Kollision \(\ge 1 - e^{-m(m-1)/(2n)}\). \(\square\)
Field-by-field Comparison
| Field |
Before |
After |
| Front |
(Geburtstagsproblem) In a group of \(m\) people (with \(n=365\) days), what is the probability that <strong>all birthdays are distinct</strong>? Derive the formula. <em>Proof Included</em> |
In einer Gruppe von \(m\) Personen (mit \(n=365\) Tagen), wie gross ist die Wahrscheinlichkeit, dass <strong>alle Geburtstage verschieden</strong> sind? Leite die Formel her.<br><br><em>Proof Included</em> |
| Back |
Model: throw \(m\) balls into \(n\) bins uniformly. Let \(A_j\) = "ball \(j\) lands in an empty bin."<br><br>By the Multiplikationssatz:<br>\[ \Pr\!\left[\bigcap_{j=1}^m A_j\right] = \prod_{j=2}^{m} \frac{n-(j-1)}{n} = \prod_{j=2}^{m}\!\left(1-\frac{j-1}{n}\right). \]<br><br>Upper bound using \(1-x \le e^{-x}\):<br>\[ \Pr[\text{all distinct}] \le \prod_{j=2}^{m} e^{-(j-1)/n} = e^{-m(m-1)/(2n)}. \]<br><br>So the probability of <strong>at least one collision</strong> is \(\ge 1 - e^{-m(m-1)/(2n)}\). \(\square\) |
(Geburtstagsproblem) <br><br><b>Modell:</b> <br>Werfe \(m\) Bälle gleichverteilt in \(n\) Urnen. <br>Sei \(A_j\) = "Ball \(j\) landet in einer leeren Urne."<br><br>Mit dem Multiplikationssatz:\[ \Pr\!\left[\bigcap_{j=1}^m A_j\right] = \prod_{j=2}^{m} \frac{n-(j-1)}{n} = \prod_{j=2}^{m}\!\left(1-\frac{j-1}{n}\right). \]Obere Schranke mit \(1-x \le e^{-x}\):\[ \Pr[\text{alle verschieden}] \le \prod_{j=2}^{m} e^{-(j-1)/n} = e^{-m(m-1)/(2n)}. \]Also ist die Wahrscheinlichkeit für <strong>mindestens eine Kollision</strong> \(\ge 1 - e^{-m(m-1)/(2n)}\). \(\square\) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Note 10: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_38dbfe49
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Expected Value) For a random variable \(X\) with \(W_X\subseteq\mathbb{N}_0\):
\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{\infty}\Pr[X\ge i] :: bound form}} \]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
(Expected Value) For a random variable \(X\) with \(W_X\subseteq\mathbb{N}_0\):
\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{\infty}\Pr[X\ge i] :: bound form}} \]
Proof Included
Proof:
\[ \mathbb{E}[X]=\sum_{i=0}^{\infty}i\cdot\Pr[X=i]=\sum_{i=0}^{\infty}\sum_{j=1}^{i}\Pr[X=i]=\sum_{j=1}^{\infty}\sum_{i=j}^{\infty}\Pr[X=i]=\sum_{j=1}^{\infty}\Pr[X\ge j].\quad\square \]
(The key step is swapping the order of summation: instead of summing over \(i\) and counting 1 for each \(j\le i\), sum over \(j\) and count all \(i\ge j\).)
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Für eine Zufallsvariable \(X\) mit \(W_X\subseteq\mathbb{N}_0\):\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{\infty}\Pr[X\ge i] :: \text{Schrankenform} }} \]Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Für eine Zufallsvariable \(X\) mit \(W_X\subseteq\mathbb{N}_0\):\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{\infty}\Pr[X\ge i] :: \text{Schrankenform} }} \]Proof Included
(Erwartungswert)
Proof:\[ \mathbb{E}[X]=\sum_{i=0}^{\infty}i\cdot\Pr[X=i]=\sum_{i=0}^{\infty}\sum_{j=1}^{i}\Pr[X=i]=\sum_{j=1}^{\infty}\sum_{i=j}^{\infty}\Pr[X=i]=\sum_{j=1}^{\infty}\Pr[X\ge j].\quad\square \](Der Schlüsselschritt ist das Vertauschen der Summationsreihenfolge: Statt über \(i\) zu summieren und für jedes \(j\le i\) eine 1 zu zählen, wird über \(j\) summiert und alle \(i\ge j\) gezählt.)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>(Expected Value)</b> For a random variable \(X\) with \(W_X\subseteq\mathbb{N}_0\):<br>\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{\infty}\Pr[X\ge i] :: bound form}} \]<br><em>Proof Included</em> |
Für eine Zufallsvariable \(X\) mit \(W_X\subseteq\mathbb{N}_0\):\[ \mathbb{E}[X] = {{c1::\sum_{i=1}^{\infty}\Pr[X\ge i] :: \text{Schrankenform} }} \]<em>Proof Included</em> |
| Extra |
<strong>Proof:</strong><br>\[ \mathbb{E}[X]=\sum_{i=0}^{\infty}i\cdot\Pr[X=i]=\sum_{i=0}^{\infty}\sum_{j=1}^{i}\Pr[X=i]=\sum_{j=1}^{\infty}\sum_{i=j}^{\infty}\Pr[X=i]=\sum_{j=1}^{\infty}\Pr[X\ge j].\quad\square \]<br>(The key step is swapping the order of summation: instead of summing over \(i\) and counting 1 for each \(j\le i\), sum over \(j\) and count all \(i\ge j\).) |
(Erwartungswert)<br><br><b>Proof:</b>\[ \mathbb{E}[X]=\sum_{i=0}^{\infty}i\cdot\Pr[X=i]=\sum_{i=0}^{\infty}\sum_{j=1}^{i}\Pr[X=i]=\sum_{j=1}^{\infty}\sum_{i=j}^{\infty}\Pr[X=i]=\sum_{j=1}^{\infty}\Pr[X\ge j].\quad\square \](Der Schlüsselschritt ist das Vertauschen der Summationsreihenfolge: Statt über \(i\) zu summieren und für jedes \(j\le i\) eine 1 zu zählen, wird über \(j\) summiert und alle \(i\ge j\) gezählt.) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Erwartungswert
Note 11: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_3ed1db5d
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen
(Lemma 2.2) Für jedes Ereignis \(A\) gilt:
\[\Pr[\bar{A}] = 1 - \Pr[A].\]
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen
(Lemma 2.2) Für jedes Ereignis \(A\) gilt:
\[\Pr[\bar{A}] = 1 - \Pr[A].\]
Proof Included
Beweis: \(\Omega = A \cup \bar{A}\) ist eine disjunkte Zerlegung, also \(\Pr[\Omega]=\Pr[A]+\Pr[\bar{A}]\). Mit \(\Pr[\Omega]=1\) folgt \(\Pr[\bar{A}]=1-\Pr[A]\). \(\square\)
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen
Für jedes Ereignis \(A\) gilt:
\[\Pr[\overline{A}] = 1 - \Pr[A].\]Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen
Für jedes Ereignis \(A\) gilt:
\[\Pr[\overline{A}] = 1 - \Pr[A].\]Proof Included
(Lemma 2.2)
Beweis:
\(\Omega = A \cup \bar{A}\) ist eine disjunkte Zerlegung, also \(\Pr[\Omega]=\Pr[A]+\Pr[\bar{A}]\).
Mit \(\Pr[\Omega]=1\) folgt \(\Pr[\bar{A}]=1-\Pr[A]\). \(\square\)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
(Lemma 2.2) Für jedes Ereignis \(A\) gilt:<br>\[\Pr[\bar{A}] = {{c1::1 - \Pr[A]}}.\]<br><em>Proof Included</em> |
Für jedes Ereignis \(A\) gilt:<br>\[\Pr[\overline{A}] = {{c1::1 - \Pr[A]}}.\]<em>Proof Included</em> |
| Extra |
<strong>Beweis:</strong> \(\Omega = A \cup \bar{A}\) ist eine disjunkte Zerlegung, also \(\Pr[\Omega]=\Pr[A]+\Pr[\bar{A}]\). Mit \(\Pr[\Omega]=1\) folgt \(\Pr[\bar{A}]=1-\Pr[A]\). \(\square\) |
(Lemma 2.2)<strong><br><br>Beweis:</strong> <br>\(\Omega = A \cup \bar{A}\) ist eine disjunkte Zerlegung, also \(\Pr[\Omega]=\Pr[A]+\Pr[\bar{A}]\). <br>Mit \(\Pr[\Omega]=1\) folgt \(\Pr[\bar{A}]=1-\Pr[A]\). \(\square\) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen
Note 12: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: sc_3fceba79
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Give an example where \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) holds but the three events are not mutually independent.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Give an example where \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) holds but the three events are not mutually independent.
Choose a random number in \(\{1,\ldots,8\}\). Let:
\(A = \{1,2,3,4\}\), so \(\Pr[A]=1/2\)
\(B = \{1,5,6,7\}\), so \(\Pr[B]=1/2\)
\(C = B\) (same event)
Then \(\Pr[A\cap B\cap C]=\Pr[A\cap B]=1/8=\Pr[A]\Pr[B]\Pr[C]\) ✓
But \(\Pr[A\cap B]=1/8 \neq 1/4 = \Pr[A]\Pr[B]\) ✗ — so \(A\) and \(B\) are not independent.
Lesson: The product condition for the full intersection is not sufficient; all sub-intersections must satisfy the product rule.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Gib ein Beispiel, bei dem \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) gilt, die drei Ereignisse aber nicht (gegenseitig) unabhängig sind.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Gib ein Beispiel, bei dem \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) gilt, die drei Ereignisse aber nicht (gegenseitig) unabhängig sind.
Wähle eine Zahl gleichverteilt aus \(\{1,\ldots,8\}\). Sei:
\(A = \{1,2,3,4\}\), also \(\Pr[A]=1/2\)
\(B = \{1,5,6,7\}\), also \(\Pr[B]=1/2\)
\(C = B\) (gleiches Ereignis)
Dann gilt \(\Pr[A\cap B\cap C]=\Pr[A\cap B]=1/8=\Pr[A]\Pr[B]\Pr[C]\) ✓
Aber \(\Pr[A\cap B]=1/8 \neq 1/4 = \Pr[A]\Pr[B]\) ✗ - also sind \(A\) und \(B\) nicht unabhängig.
Lektion:
Die Produktbedingung für den vollen Durchschnitt allein reicht nicht aus; alle Teil-Durchschnitte müssen die Produktregel erfüllen.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Give an example where \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) holds but the three events are <strong>not</strong> mutually independent. |
Gib ein Beispiel, bei dem \(\Pr[A\cap B\cap C]=\Pr[A]\Pr[B]\Pr[C]\) gilt, die drei Ereignisse aber <strong>nicht</strong> (gegenseitig) unabhängig sind. |
| Back |
Choose a random number in \(\{1,\ldots,8\}\). Let:<br>\(A = \{1,2,3,4\}\), so \(\Pr[A]=1/2\)<br>\(B = \{1,5,6,7\}\), so \(\Pr[B]=1/2\)<br>\(C = B\) (same event)<br><br>Then \(\Pr[A\cap B\cap C]=\Pr[A\cap B]=1/8=\Pr[A]\Pr[B]\Pr[C]\) ✓<br><br>But \(\Pr[A\cap B]=1/8 \neq 1/4 = \Pr[A]\Pr[B]\) ✗ — so \(A\) and \(B\) are not independent.<br><br><strong>Lesson:</strong> The product condition for the full intersection is not sufficient; <em>all</em> sub-intersections must satisfy the product rule. |
Wähle eine Zahl gleichverteilt aus \(\{1,\ldots,8\}\). Sei:<br>\(A = \{1,2,3,4\}\), also \(\Pr[A]=1/2\)<br>\(B = \{1,5,6,7\}\), also \(\Pr[B]=1/2\)<br>\(C = B\) (gleiches Ereignis)<br><br>Dann gilt \(\Pr[A\cap B\cap C]=\Pr[A\cap B]=1/8=\Pr[A]\Pr[B]\Pr[C]\) ✓<br><br>Aber \(\Pr[A\cap B]=1/8 \neq 1/4 = \Pr[A]\Pr[B]\) ✗ - also sind \(A\) und \(B\) nicht unabhängig.<br><br><strong>Lektion:</strong> <br>Die Produktbedingung für den vollen Durchschnitt allein reicht nicht aus; <em>alle</em> Teil-Durchschnitte müssen die Produktregel erfüllen. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Note 13: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_4064b971
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Independence Events \(A_1,\ldots,A_n\) are mutually independent iff for all \((s_1,\ldots,s_n)\in\{0,1\}^n\):
\[ {{c1:: \Pr\!\left[A_1^{s_1}\cap\cdots\cap A_n^{s_n}\right] = \Pr[A_1^{s_1}]\cdots\Pr[A_n^{s_n}]}} \]
where \(A_i^1 = A_i\) and \(A_i^0 = \bar{A}_i\). Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Independence Events \(A_1,\ldots,A_n\) are mutually independent iff for all \((s_1,\ldots,s_n)\in\{0,1\}^n\):
\[ {{c1:: \Pr\!\left[A_1^{s_1}\cap\cdots\cap A_n^{s_n}\right] = \Pr[A_1^{s_1}]\cdots\Pr[A_n^{s_n}]}} \]
where \(A_i^1 = A_i\) and \(A_i^0 = \bar{A}_i\). Proof Included
Proof sketch (⇒): Induction on the number of zeros in \((s_1,\ldots,s_n)\).
Base case (\(s_i=1\) for all \(i\)): direct from definition.
Inductive step (say \(s_1=0\)):
\(\Pr[\bar{A}_1\cap A_2^{s_2}\cap\cdots] = \Pr[A_2^{s_2}\cap\cdots]-\Pr[A_1\cap A_2^{s_2}\cap\cdots]\)
\(= \Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]-\Pr[A_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\)
\(= (1-\Pr[A_1])\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}] = \Pr[\bar{A}_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\). \(\square\)
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
\(A_1,\ldots,A_n\) sind gegenseitig unabhängig gdw. für alle \((s_1,\ldots,s_n)\in\{0,1\}^n\):\[ {{c1:: \Pr\!\left[A_1^{s_1}\cap\cdots\cap A_n^{s_n}\right] = \Pr[A_1^{s_1}]\cdots\Pr[A_n^{s_n}]}} \]wobei \(A_i^1 = A_i\) und \(A_i^0 = \bar{A}_i\).
Proof Included
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
\(A_1,\ldots,A_n\) sind gegenseitig unabhängig gdw. für alle \((s_1,\ldots,s_n)\in\{0,1\}^n\):\[ {{c1:: \Pr\!\left[A_1^{s_1}\cap\cdots\cap A_n^{s_n}\right] = \Pr[A_1^{s_1}]\cdots\Pr[A_n^{s_n}]}} \]wobei \(A_i^1 = A_i\) und \(A_i^0 = \bar{A}_i\).
Proof Included
Beweisskizze (⇒):
Induktion über die Anzahl Nullen in \((s_1,\ldots,s_n)\).
Basisfall (\(s_i=1\) für alle \(i\)): direkt aus der Definition.
Induktionsschritt (z.B. \(s_1=0\)):
\(\Pr[\bar{A}_1\cap A_2^{s_2}\cap\cdots] = \Pr[A_2^{s_2}\cap\cdots]-\Pr[A_1\cap A_2^{s_2}\cap\cdots]\)
\(= \Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]-\Pr[A_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\)
\(= (1-\Pr[A_1])\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}] = \Pr[\bar{A}_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\). \(\square\)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Independence</b> Events \(A_1,\ldots,A_n\) are <b>mutually</b> independent iff for <b>all</b> \((s_1,\ldots,s_n)\in\{0,1\}^n\):<br>\[ {{c1:: \Pr\!\left[A_1^{s_1}\cap\cdots\cap A_n^{s_n}\right] = \Pr[A_1^{s_1}]\cdots\Pr[A_n^{s_n}]}} \]<br>where \(A_i^1 = A_i\) and \(A_i^0 = \bar{A}_i\). <em>Proof Included</em> |
\(A_1,\ldots,A_n\) sind <b>gegenseitig</b> unabhängig gdw. für <b>alle</b> \((s_1,\ldots,s_n)\in\{0,1\}^n\):\[ {{c1:: \Pr\!\left[A_1^{s_1}\cap\cdots\cap A_n^{s_n}\right] = \Pr[A_1^{s_1}]\cdots\Pr[A_n^{s_n}]}} \]wobei \(A_i^1 = A_i\) und \(A_i^0 = \bar{A}_i\). <br><em><br>Proof Included</em> |
| Extra |
<strong>Proof sketch (⇒):</strong> Induction on the number of zeros in \((s_1,\ldots,s_n)\).<br>Base case (\(s_i=1\) for all \(i\)): direct from definition.<br>Inductive step (say \(s_1=0\)):<br>\(\Pr[\bar{A}_1\cap A_2^{s_2}\cap\cdots] = \Pr[A_2^{s_2}\cap\cdots]-\Pr[A_1\cap A_2^{s_2}\cap\cdots]\)<br>\(= \Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]-\Pr[A_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\)<br>\(= (1-\Pr[A_1])\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}] = \Pr[\bar{A}_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\). \(\square\) |
<strong>Beweisskizze (⇒):</strong> <br>Induktion über die Anzahl Nullen in \((s_1,\ldots,s_n)\).<br>Basisfall (\(s_i=1\) für alle \(i\)): direkt aus der Definition.<br>Induktionsschritt (z.B. \(s_1=0\)):<br>\(\Pr[\bar{A}_1\cap A_2^{s_2}\cap\cdots] = \Pr[A_2^{s_2}\cap\cdots]-\Pr[A_1\cap A_2^{s_2}\cap\cdots]\)<br>\(= \Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]-\Pr[A_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\)<br>\(= (1-\Pr[A_1])\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}] = \Pr[\bar{A}_1]\Pr[A_2^{s_2}]\cdots\Pr[A_n^{s_n}]\). \(\square\) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
Note 14: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: sc_4701cdf5
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Give an intuitive description of what conditioning on event \(B\) (events \(\Pr[\cdot | B]\)) does to the probability space.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Give an intuitive description of what conditioning on event \(B\) (events \(\Pr[\cdot | B]\)) does to the probability space.
Conditioning on \(B\):
Zeros out all elementary events \(\omega\notin B\) (they are ruled out).
Rescales the remaining probabilities by \(1/\Pr[B]\) so they sum to 1.
Think of it as "zooming in" on the sub-universe \(B\): inside \(B\), relative probabilities remain unchanged; everything outside \(B\) is discarded.
Consequence: All probability rules hold within the conditional space (complement, disjoint union, Bayes, etc.).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Gib eine intuitive Beschreibung, was das Konditionieren auf ein Ereignis \(B\) (d.h. \(\Pr[\cdot | B]\)) mit dem Wahrscheinlichkeitsraum macht.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Gib eine intuitive Beschreibung, was das Konditionieren auf ein Ereignis \(B\) (d.h. \(\Pr[\cdot | B]\)) mit dem Wahrscheinlichkeitsraum macht.
Man "zoomt" in den Wahrscheinlichkeitsraum hinein und beschränkt sich auf die Ergebnisse in \(B\).
Alle Ergebnisse ausserhalb von \(B\) erhalten Wahrscheinlichkeit 0, und die verbleibenden Wahrscheinlichkeiten werden mit \(1/\Pr[B]\) reskaliert, damit sie sich wieder zu 1 summieren.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Give an intuitive description of what conditioning on event \(B\) (events \(\Pr[\cdot | B]\)) does to the probability space. |
Gib eine intuitive Beschreibung, was das Konditionieren auf ein Ereignis \(B\) (d.h. \(\Pr[\cdot | B]\)) mit dem Wahrscheinlichkeitsraum macht. |
| Back |
Conditioning on \(B\):<br><strong>Zeros out</strong> all elementary events \(\omega\notin B\) (they are ruled out).<br><strong>Rescales</strong> the remaining probabilities by \(1/\Pr[B]\) so they sum to 1.<br><br>Think of it as "zooming in" on the sub-universe \(B\): inside \(B\), relative probabilities remain unchanged; everything outside \(B\) is discarded.<br><br><strong>Consequence:</strong> All probability rules hold within the conditional space (complement, disjoint union, Bayes, etc.). |
Man "zoomt" in den Wahrscheinlichkeitsraum hinein und beschränkt sich auf die Ergebnisse in \(B\). <br><br>Alle Ergebnisse ausserhalb von \(B\) erhalten Wahrscheinlichkeit 0, und die verbleibenden Wahrscheinlichkeiten werden mit \(1/\Pr[B]\) reskaliert, damit sie sich wieder zu 1 summieren. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
Note 15: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: sc_55f36256
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
The distribution function (Verteilungsfunktion) of \(X\) is:
\[ {{c1:: F_X : \mathbb{R}\to[0,1], x\mapsto \Pr[X\le x]}} = {{c2::\sum_{\substack{x'\in W_X\\x'\le x} } \Pr[X=x'] }}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
The distribution function (Verteilungsfunktion) of \(X\) is:
\[ {{c1:: F_X : \mathbb{R}\to[0,1], x\mapsto \Pr[X\le x]}} = {{c2::\sum_{\substack{x'\in W_X\\x'\le x} } \Pr[X=x'] }}\]
It is non-decreasing, right-continuous, with \(F_X\to 0\) as \(x\to-\infty\) and \(F_X\to 1\) as \(x\to+\infty\).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
Die Verteilungsfunktion von \(X\) ist:
\[ {{c1:: F_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X\le x]}} = {{c2::\sum_{\substack{x'\in W_X\\x'\le x} } \Pr[X=x'] }}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
Die Verteilungsfunktion von \(X\) ist:
\[ {{c1:: F_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X\le x]}} = {{c2::\sum_{\substack{x'\in W_X\\x'\le x} } \Pr[X=x'] }}\]
Sie ist monoton wachsend, rechtsstetig, mit \(F_X\to 0\) für \(x\to-\infty\) und \(F_X\to 1\) für \(x\to+\infty\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
The <strong>distribution function</strong> (Verteilungsfunktion) of \(X\) is:<br>\[ {{c1:: F_X : \mathbb{R}\to[0,1], x\mapsto \Pr[X\le x]}} = {{c2::\sum_{\substack{x'\in W_X\\x'\le x} } \Pr[X=x'] }}\] |
Die <strong>Verteilungsfunktion</strong> von \(X\) ist:<br>\[ {{c1:: F_X : \mathbb{R}\to[0,1], \quad x\mapsto \Pr[X\le x]}} = {{c2::\sum_{\substack{x'\in W_X\\x'\le x} } \Pr[X=x'] }}\] |
| Extra |
It is non-decreasing, right-continuous, with \(F_X\to 0\) as \(x\to-\infty\) and \(F_X\to 1\) as \(x\to+\infty\). |
Sie ist monoton wachsend, rechtsstetig, mit \(F_X\to 0\) für \(x\to-\infty\) und \(F_X\to 1\) für \(x\to+\infty\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Definitionen
Note 16: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: +!U{GV-1:X
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe \(\sum_{k=1}^\infty a_k\) ist definiert als die Folge der Partialsummen \(S_n\), wobei: \[S_n = {{c2::\sum_{k=1}^n a_k = a_1 + a_2 + \cdots + a_n}}\]
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe \(\sum_{k=1}^\infty a_k\) ist definiert als die Folge der Partialsummen \(S_n\), wobei: \[S_n = {{c2::\sum_{k=1}^n a_k = a_1 + a_2 + \cdots + a_n}}\]
Eine Reihe ist ein Symbol für \(\lim_{n\to\infty} S_n\) — keine gewöhnliche Summe.
After
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe \(\sum_{k=1}^\infty a_k\) ist definiert als die Folge der Partialsummen \(S_n\), wobei: \[S_n = {{c2::\sum_{k=1}^n a_k = a_1 + a_2 + \cdots + a_n}}\]
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe \(\sum_{k=1}^\infty a_k\) ist definiert als die Folge der Partialsummen \(S_n\), wobei: \[S_n = {{c2::\sum_{k=1}^n a_k = a_1 + a_2 + \cdots + a_n}}\]
Eine Reihe ist ein Symbol für \(\lim_{n\to\infty} S_n\) - keine gewöhnliche Summe.
Field-by-field Comparison
| Field |
Before |
After |
| Extra |
Eine Reihe ist ein <b>Symbol</b> für \(\lim_{n\to\infty} S_n\) — keine gewöhnliche Summe. |
Eine Reihe ist ein <b>Symbol</b> für \(\lim_{n\to\infty} S_n\) - keine gewöhnliche Summe. |
Tags:
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Note 17: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Classic
GUID: +w)j=/t,NA
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Was gilt auf dem Rand des Konvergenzkreises \(|x - a| = R\) einer Potenzreihe?
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Was gilt auf dem Rand des Konvergenzkreises \(|x - a| = R\) einer Potenzreihe?
Keine allgemeine Aussage — kommt auf den Einzelfall an:
- \(\sum \frac{x^n}{n}\): divergiert für \(x = 1\), konvergiert für \(x = -1\) (Leibniz)
- \(\sum \frac{x^n}{n^2}\): konvergiert für alle \(|x| = 1\) (absolut)
- \(\sum x^n\): divergiert für alle \(|x| = 1\)
After
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Was gilt auf dem Rand des Konvergenzkreises \(|x - a| = R\) einer Potenzreihe?
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Was gilt auf dem Rand des Konvergenzkreises \(|x - a| = R\) einer Potenzreihe?
Keine allgemeine Aussage - kommt auf den Einzelfall an:
- \(\sum \frac{x^n}{n}\): divergiert für \(x = 1\), konvergiert für \(x = -1\) (Leibniz)
- \(\sum \frac{x^n}{n^2}\): konvergiert für alle \(|x| = 1\) (absolut)
- \(\sum x^n\): divergiert für alle \(|x| = 1\)
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Keine allgemeine Aussage — kommt auf den Einzelfall an:<br><ul><li>\(\sum \frac{x^n}{n}\): divergiert für \(x = 1\), konvergiert für \(x = -1\) (Leibniz)</li><li>\(\sum \frac{x^n}{n^2}\): konvergiert für alle \(|x| = 1\) (absolut)</li><li>\(\sum x^n\): divergiert für alle \(|x| = 1\)</li></ul> |
Keine allgemeine Aussage - kommt auf den Einzelfall an:<br><ul><li>\(\sum \frac{x^n}{n}\): divergiert für \(x = 1\), konvergiert für \(x = -1\) (Leibniz)</li><li>\(\sum \frac{x^n}{n^2}\): konvergiert für alle \(|x| = 1\) (absolut)</li><li>\(\sum x^n\): divergiert für alle \(|x| = 1\)</li></ul> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Note 18: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: ,$5trcvO/g
modified
Before
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::2._Properties
| Form |
Umformung |
Methode |
| {{c1::\(\dfrac{0}{0}\)}} |
— |
L'Hôpital, kürzen, Taylor |
| {{c2::\(\dfrac{\infty}{\infty}\)}} |
— |
L'Hôpital, führende Terme |
| \(0 \cdot \infty\) |
{{c3::\(\dfrac{0}{1/\infty} = \dfrac{0}{0}\) oder \(\dfrac{\infty}{1/0} = \dfrac{\infty}{\infty}\)}} |
Umschreiben → L'Hôpital |
| \(\infty - \infty\) |
gemeinsamer Nenner, Konjugat, ausklammern |
{{c4::→ \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}} |
| \(0^0\) |
{{c5::\(e^{0 \cdot \ln 0} = e^{0 \cdot (-\infty)}\)}} |
Logarithmieren → \(0 \cdot \infty\) |
| \(\infty^0\) |
{{c6::\(e^{0 \cdot \ln \infty} = e^{0 \cdot \infty}\)}} |
Logarithmieren → \(0 \cdot \infty\) |
| \(1^\infty\) |
{{c7::\(e^{\infty \cdot \ln 1} = e^{\infty \cdot 0}\)}} |
Logarithmieren → \(0 \cdot \infty\) |
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::2._Properties
| Form |
Umformung |
Methode |
| {{c1::\(\dfrac{0}{0}\)}} |
— |
L'Hôpital, kürzen, Taylor |
| {{c2::\(\dfrac{\infty}{\infty}\)}} |
— |
L'Hôpital, führende Terme |
| \(0 \cdot \infty\) |
{{c3::\(\dfrac{0}{1/\infty} = \dfrac{0}{0}\) oder \(\dfrac{\infty}{1/0} = \dfrac{\infty}{\infty}\)}} |
Umschreiben → L'Hôpital |
| \(\infty - \infty\) |
gemeinsamer Nenner, Konjugat, ausklammern |
{{c4::→ \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}} |
| \(0^0\) |
{{c5::\(e^{0 \cdot \ln 0} = e^{0 \cdot (-\infty)}\)}} |
Logarithmieren → \(0 \cdot \infty\) |
| \(\infty^0\) |
{{c6::\(e^{0 \cdot \ln \infty} = e^{0 \cdot \infty}\)}} |
Logarithmieren → \(0 \cdot \infty\) |
| \(1^\infty\) |
{{c7::\(e^{\infty \cdot \ln 1} = e^{\infty \cdot 0}\)}} |
Logarithmieren → \(0 \cdot \infty\) |
(\(0\) und \(\infty\) sind hier Kurzschreibweisen für das Verhalten im Grenzwert: \(0\) steht für „geht gegen \(0\)" und \(\infty\) für „geht gegen \(\infty\)".)
After
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::2._Properties
| Form |
Strategie |
| \(\dfrac{0}{0}\) |
L'Hôpital, kürzen, Taylor |
| \(\dfrac{\infty}{\infty}\) |
L'Hôpital, führende Terme, Taylor |
| \(0 \cdot \infty\) |
{{c3::Als Bruch schreiben → \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}} |
| \(\infty - \infty\) |
{{c4::Gemeinsamer Nenner, Konjugat oder Ausklammern → \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}} |
| \(0^0,\; \infty^0,\; 1^\infty\) |
{{c5::\(f^g = e^{g \ln f}\) → wird zu \(0 \cdot \infty\)}} |
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::2._Properties
| Form |
Strategie |
| \(\dfrac{0}{0}\) |
L'Hôpital, kürzen, Taylor |
| \(\dfrac{\infty}{\infty}\) |
L'Hôpital, führende Terme, Taylor |
| \(0 \cdot \infty\) |
{{c3::Als Bruch schreiben → \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}} |
| \(\infty - \infty\) |
{{c4::Gemeinsamer Nenner, Konjugat oder Ausklammern → \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}} |
| \(0^0,\; \infty^0,\; 1^\infty\) |
{{c5::\(f^g = e^{g \ln f}\) → wird zu \(0 \cdot \infty\)}} |
(\(0\) und \(\infty\) sind hier Kurzschreibweisen für das Verhalten im Grenzwert: \(0\) steht für „geht gegen \(0\)" und \(\infty\) für „geht gegen \(\infty\)".)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<table style="border-collapse:collapse;width:100%;font-size:0.95em;">
<thead>
<tr>
<th style="padding:8px 12px;border:1px solid #555;">Form</th>
<th style="padding:8px 12px;border:1px solid #555;">Umformung</th>
<th style="padding:8px 12px;border:1px solid #555;">Methode</th>
</tr>
</thead>
<tbody>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c1::\(\dfrac{0}{0}\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c1:: —}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c1::L'Hôpital, kürzen, Taylor}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c2::\(\dfrac{\infty}{\infty}\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c2::—}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c2::L'Hôpital, führende Terme}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c3::\(0 \cdot \infty\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c3::\(\dfrac{0}{1/\infty} = \dfrac{0}{0}\) oder \(\dfrac{\infty}{1/0} = \dfrac{\infty}{\infty}\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c3::Umschreiben → L'Hôpital}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c4::\(\infty - \infty\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c4::gemeinsamer Nenner, Konjugat, ausklammern}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c4::→ \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c5::\(0^0\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c5::\(e^{0 \cdot \ln 0} = e^{0 \cdot (-\infty)}\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c5::Logarithmieren → \(0 \cdot \infty\)}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c6::\(\infty^0\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c6::\(e^{0 \cdot \ln \infty} = e^{0 \cdot \infty}\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c6::Logarithmieren → \(0 \cdot \infty\)}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">{{c7::\(1^\infty\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c7::\(e^{\infty \cdot \ln 1} = e^{\infty \cdot 0}\)}}</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c7::Logarithmieren → \(0 \cdot \infty\)}}</td>
</tr>
</tbody>
</table> |
<table style="border-collapse:collapse;width:100%;font-size:0.95em;">
<thead>
<tr>
<th style="padding:8px 12px;border:1px solid #555;">Form</th>
<th style="padding:8px 12px;border:1px solid #555;">Strategie</th>
</tr>
</thead>
<tbody><tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">\(\dfrac{0}{0}\)</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c1::L'Hôpital, kürzen, Taylor}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">\(\dfrac{\infty}{\infty}\)</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c2::L'Hôpital, führende Terme, Taylor}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">\(0 \cdot \infty\)</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c3::Als Bruch schreiben → \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">\(\infty - \infty\)</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c4::Gemeinsamer Nenner, Konjugat oder Ausklammern → \(\dfrac{0}{0}\) oder \(\dfrac{\infty}{\infty}\)}}</td>
</tr>
<tr>
<td style="padding:8px 12px;border:1px solid #555;text-align:center;">\(0^0,\; \infty^0,\; 1^\infty\)</td>
<td style="padding:8px 12px;border:1px solid #555;">{{c5::\(f^g = e^{g \ln f}\) → wird zu \(0 \cdot \infty\)}}</td>
</tr>
</tbody>
</table> |
Tags:
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::2._Properties
Note 19: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Classic
GUID: 2cxt#6?hKc
modified
Before
Front
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::1._Ordnung
Cauchy-Schwarz Ungleichung (Euklidischer Raum)
Back
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::1._Ordnung
Cauchy-Schwarz Ungleichung (Euklidischer Raum)
Für alle \(x, y \in \mathbb{R}^n\) gilt:\[|x \cdot y| \leq \|x\| \cdot \|y\|\]
After
Front
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::1._Ordnung
Wie lautet die Cauchy-Schwarz Ungleichung im euklidischen Raum?
Back
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::1._Ordnung
Wie lautet die Cauchy-Schwarz Ungleichung im euklidischen Raum?
Für alle \(x, y \in \mathbb{R}^n\) gilt:\[|x \cdot y| \leq \|x\| \cdot \|y\|\]
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Cauchy-Schwarz Ungleichung (Euklidischer Raum) |
Wie lautet die Cauchy-Schwarz Ungleichung im euklidischen Raum? |
Tags:
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::1._Ordnung
Note 20: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Classic
GUID: 9r2wQ@.hKx
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Unterschied Wurzel- vs. Quotientenkriterium?
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Unterschied Wurzel- vs. Quotientenkriterium?
Das Wurzelkriterium ist stärker: Liefert der Quotient ein Ergebnis, so auch die Wurzel - aber nicht umgekehrt.
In der Praxis ist das Quotientenkriterium oft bequemer, besonders bei \(n!\) oder Potenzen.
Beide versagen bei \(\rho = 1\), z.B. bei \(p\)-Reihen.
After
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Welches Konvergenzkriterium ist stärker: das Wurzel- oder das Quotientenkriterium?
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Welches Konvergenzkriterium ist stärker: das Wurzel- oder das Quotientenkriterium?
Das Wurzelkriterium. Liefert der Quotient ein Ergebnis, so auch die Wurzel - aber nicht umgekehrt.
In der Praxis ist das Quotientenkriterium oft bequemer, besonders bei \(n!\) oder Potenzen.
Beide versagen bei \(\rho = 1\), z.B. bei \(p\)-Reihen.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Unterschied Wurzel- vs. Quotientenkriterium? |
Welches Konvergenzkriterium ist stärker: das Wurzel- oder das Quotientenkriterium? |
| Back |
Das <b>Wurzelkriterium ist stärker</b>: Liefert der Quotient ein Ergebnis, so auch die Wurzel - aber nicht umgekehrt.
<br><br>In der Praxis ist das <b>Quotientenkriterium</b> oft bequemer, besonders bei \(n!\) oder Potenzen.
<br><br>Beide versagen bei \(\rho = 1\), z.B. bei \(p\)-Reihen. |
Das <b>Wurzelkriterium.</b> Liefert der Quotient ein Ergebnis, so auch die Wurzel - aber nicht umgekehrt.
<br><br>In der Praxis ist das <b>Quotientenkriterium</b> oft bequemer, besonders bei \(n!\) oder Potenzen.
<br><br>Beide versagen bei \(\rho = 1\), z.B. bei \(p\)-Reihen. |
Tags:
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Note 21: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: ==Fn-80|4a
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Wurzelkriterium: Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\). Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Wurzelkriterium: Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\). Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber
nicht umgekehrt.
Proof:
- Convergence \(L < 1\)
-
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).
- Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)
- So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).
- Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)
-
Divergence \(L > 1\)
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).
- Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)
- So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence
After
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\).
Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\).
Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
(Wurzelkriterium)
Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber
nicht umgekehrt.
Proof:
- Convergence \(L < 1\)
-
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).
- Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)
- So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).
- Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)
-
Divergence \(L > 1\)
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).
- Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)
- So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Wurzelkriterium: Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\). Dann:<br><ul><li>\(\rho {{c1::< 1}}\) \(\implies\) \(\sum a_n\) konvergiert <b>absolut</b></li><li>\(\rho {{c2::> 1}}\) \(\implies\) \(\sum a_n\) divergiert</li><li>\(\rho {{c3::= 1}}\) \(\implies\) <b>keine Aussage</b> möglich<br><br></li></ul><i>Proof Included</i> |
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\). <br>Dann:<br><ul><li>\(\rho < 1\) \(\implies\) {{c1::\(\sum a_n\) konvergiert <b>absolut</b>}}</li><li>\(\rho > 1\) \(\implies\) {{c1::\(\sum a_n\) divergiert}}</li><li>\(\rho = 1\) \(\implies\) {{c1::<b>keine Aussage</b> möglich}}<br></li></ul><i>Proof Included</i> |
| Extra |
Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber <b>nicht umgekehrt</b>.<br><div><div><br></div></div><div><div><strong>Proof:</strong> </div><ol>
<li>Convergence \(L < 1\)</li><li>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).</li>
<li>Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)</li>
<li>So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).</li>
<li>Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)</li>
</ol>
</li>
<li>
<div>Divergence \(L > 1\)</div>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).</li>
<li>Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)</li>
<li>So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence </li></ol></li></ol></div> |
(Wurzelkriterium)<br><br>Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber <b>nicht umgekehrt</b>.<br><div><div><br></div></div><div><div><strong>Proof:</strong> </div><ol>
<li>Convergence \(L < 1\)</li><li>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).</li>
<li>Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)</li>
<li>So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).</li>
<li>Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)</li>
</ol>
</li>
<li>
<div>Divergence \(L > 1\)</div>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).</li>
<li>Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)</li>
<li>So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence </li></ol></li></ol></div> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Note 22: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Classic
GUID: AO&PBz(QiL
modified
Before
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz
Eine Folge \((a_n)_{n \in \mathbb{N_0}}\) konvergiert, falls:
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz
Eine Folge \((a_n)_{n \in \mathbb{N_0}}\) konvergiert, falls:
\[\forall \varepsilon > 0 \; \exists N > 0 \text{ so dass } \forall n > N : |a_n - L| < \varepsilon\]
After
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz
Wann konvergiert eine Folge \((a_n)_{n \in \mathbb{N_0}}\)?
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz
Wann konvergiert eine Folge \((a_n)_{n \in \mathbb{N_0}}\)?
\[\text{Wenn }\forall \varepsilon > 0 \; \exists N > 0 \text{, so dass } \forall n > N : |a_n - L| < \varepsilon\]
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Eine Folge \((a_n)_{n \in \mathbb{N_0}}\) konvergiert, falls: |
Wann konvergiert eine Folge \((a_n)_{n \in \mathbb{N_0}}\)? |
| Back |
\[\forall \varepsilon > 0 \; \exists N > 0 \text{ so dass } \forall n > N : |a_n - L| < \varepsilon\]<br> |
\[\text{Wenn }\forall \varepsilon > 0 \; \exists N > 0 \text{, so dass } \forall n > N : |a_n - L| < \varepsilon\] |
Tags:
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz
Note 23: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: BYMIpKIF1M
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Eine Funktion \(f : \mathbb{R} \rightarrow \mathbb{R}\) ist ungerade falls gilt {{c2::\(\forall x \in \mathbb{R} \ \ f(-x) = -f(x)\) }}
Back
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Eine Funktion \(f : \mathbb{R} \rightarrow \mathbb{R}\) ist ungerade falls gilt {{c2::\(\forall x \in \mathbb{R} \ \ f(-x) = -f(x)\) }}
\(x^3\) (ungerade Potenzen) sind zum Beispiel ungerade, oder \(\sin(x)\)
After
Front
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Eine Funktion \(f : \mathbb{R} \rightarrow \mathbb{R}\) ist ungerade, falls gilt {{c2::\(\forall x \in \mathbb{R} \ \ f(-x) = -f(x)\).}}
Back
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Eine Funktion \(f : \mathbb{R} \rightarrow \mathbb{R}\) ist ungerade, falls gilt {{c2::\(\forall x \in \mathbb{R} \ \ f(-x) = -f(x)\).}}
\(x^3\) (ungerade Potenzen) sind zum Beispiel ungerade, oder \(\sin(x)\)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eine Funktion \(f : \mathbb{R} \rightarrow \mathbb{R}\) ist {{c1::ungerade}} falls gilt {{c2::\(\forall x \in \mathbb{R} \ \ f(-x) = -f(x)\) }} |
Eine Funktion \(f : \mathbb{R} \rightarrow \mathbb{R}\) ist {{c1::ungerade}}, falls gilt {{c2::\(\forall x \in \mathbb{R} \ \ f(-x) = -f(x)\).}} |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Note 24: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: EWO(x#WDV|
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\), es sei \(x_0 \in \mathbb{R}\) und es gelte \[{{c1::\mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \neq \emptyset \quad \forall \delta > 0}}\]Dann ist \(L \in \mathbb{R}\) der Grenzwert/Limes von \(f(x)\) an der Stelle \(x_0\), falls gilt \[{{c2::\forall \varepsilon > 0 \;\exists \delta > 0 \quad \text{ so dass} \quad x \in \mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \;\Rightarrow\; |f(x) - L| < \varepsilon}}\]
Back
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\), es sei \(x_0 \in \mathbb{R}\) und es gelte \[{{c1::\mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \neq \emptyset \quad \forall \delta > 0}}\]Dann ist \(L \in \mathbb{R}\) der Grenzwert/Limes von \(f(x)\) an der Stelle \(x_0\), falls gilt \[{{c2::\forall \varepsilon > 0 \;\exists \delta > 0 \quad \text{ so dass} \quad x \in \mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \;\Rightarrow\; |f(x) - L| < \varepsilon}}\]
Beachte, dass die Funktion nicht unbedingt an der Stelle \(x_0\) des Grenzwerts definiert sein muss (siehe Sprungstelle, Definitionslücke).
After
Front
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\), es sei \(x_0 \in \mathbb{R}\) und es gelte \[{{c1::\mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \neq \emptyset \quad \forall \delta > 0}}\]Dann ist \(L \in \mathbb{R}\) der Grenzwert/Limes von \(f(x)\) an der Stelle \(x_0\), falls gilt \[{{c2::\begin{gathered}\forall \varepsilon > 0 \;\exists \delta > 0 \text{ so dass} \\ x \in \mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \;\Rightarrow\; |f(x) - L| < \varepsilon\end{gathered} }}\]
Back
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\), es sei \(x_0 \in \mathbb{R}\) und es gelte \[{{c1::\mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \neq \emptyset \quad \forall \delta > 0}}\]Dann ist \(L \in \mathbb{R}\) der Grenzwert/Limes von \(f(x)\) an der Stelle \(x_0\), falls gilt \[{{c2::\begin{gathered}\forall \varepsilon > 0 \;\exists \delta > 0 \text{ so dass} \\ x \in \mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \;\Rightarrow\; |f(x) - L| < \varepsilon\end{gathered} }}\]
Beachte, dass die Funktion nicht unbedingt an der Stelle \(x_0\) des Grenzwerts definiert sein muss (siehe Sprungstelle, Definitionslücke).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\), es sei \(x_0 \in \mathbb{R}\) und es gelte \[{{c1::\mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \neq \emptyset \quad \forall \delta > 0}}\]Dann ist \(L \in \mathbb{R}\) der Grenzwert/Limes von \(f(x)\) an der Stelle \(x_0\), falls gilt \[{{c2::\forall \varepsilon > 0 \;\exists \delta > 0 \quad \text{ so dass} \quad x \in \mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \;\Rightarrow\; |f(x) - L| < \varepsilon}}\] |
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\), es sei \(x_0 \in \mathbb{R}\) und es gelte \[{{c1::\mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \neq \emptyset \quad \forall \delta > 0}}\]Dann ist \(L \in \mathbb{R}\) der Grenzwert/Limes von \(f(x)\) an der Stelle \(x_0\), falls gilt \[{{c2::\begin{gathered}\forall \varepsilon > 0 \;\exists \delta > 0 \text{ so dass} \\ x \in \mathbb{D}(f) \cap (x_0 - \delta,\, x_0 + \delta) \;\Rightarrow\; |f(x) - L| < \varepsilon\end{gathered} }}\] |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Note 25: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: Hr{NV+|lFT
modified
Before
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::3._Kriterien
Für eine {{c1:: monotone Folge reeller Zahlen \((a_n)_{n \in \mathbb{N}_0}\)}} gilt: sie konvergiert genau dann, wenn sie beschränkt ist.
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::3._Kriterien
Für eine {{c1:: monotone Folge reeller Zahlen \((a_n)_{n \in \mathbb{N}_0}\)}} gilt: sie konvergiert genau dann, wenn sie beschränkt ist.
(Weierstrass)
Falls die Folge monoton wachsend ist, gilt: \[ \lim_{n \rightarrow \infty} a_n = \sup \{a_n \mid n \in \mathbb{N}_0\} \]Falls die Folge monoton fallend ist, gilt:\[\lim_{n \rightarrow \infty} a_n = \inf \{ a_n \mid n \in \mathbb{N}_0\}\]
After
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::3._Kriterien
Für eine {{c1:: monotone Folge reeller Zahlen \((a_n)_{n \in \mathbb{N}_0}\)}} gilt:
Sie konvergiert genau dann, wenn sie beschränkt ist.
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::3._Kriterien
Für eine {{c1:: monotone Folge reeller Zahlen \((a_n)_{n \in \mathbb{N}_0}\)}} gilt:
Sie konvergiert genau dann, wenn sie beschränkt ist.
(Weierstrass)
Falls die Folge monoton wachsend ist, gilt: \[ \lim_{n \rightarrow \infty} a_n = \sup \{a_n \mid n \in \mathbb{N}_0\} \]Falls die Folge monoton fallend ist, gilt:\[\lim_{n \rightarrow \infty} a_n = \inf \{ a_n \mid n \in \mathbb{N}_0\}\]
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Für eine {{c1:: monotone Folge reeller Zahlen \((a_n)_{n \in \mathbb{N}_0}\)}} gilt: sie {{c2::konvergiert}} genau dann, wenn {{c2::sie beschränkt ist}}. |
Für eine {{c1:: monotone Folge reeller Zahlen \((a_n)_{n \in \mathbb{N}_0}\)}} gilt: <br>Sie konvergiert genau dann, wenn {{c2::sie beschränkt ist}}. |
Tags:
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::3._Kriterien
Note 26: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: H~>w5z&KSZ
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Sei \(f: X \rightarrow Y\) und \(g: Y \rightarrow Z\). \[ g \circ f : X \rightarrow Z \text{ mit } (g \circ f)(x) = g(f(x)) \]
Back
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Sei \(f: X \rightarrow Y\) und \(g: Y \rightarrow Z\). \[ g \circ f : X \rightarrow Z \text{ mit } (g \circ f)(x) = g(f(x)) \]
\(f\) ist die innere und \(g\) die äußere Funktion.
After
Front
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Sei \(f: X \rightarrow Y\) und \(g: Y \rightarrow Z\). \[ g \circ f : X \rightarrow Z \text{ mit } (g \circ f)(x) = g(f(x)) \]
Back
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Sei \(f: X \rightarrow Y\) und \(g: Y \rightarrow Z\). \[ g \circ f : X \rightarrow Z \text{ mit } (g \circ f)(x) = g(f(x)) \]
\(f\) ist die innere und \(g\) die äussere Funktion.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Sei \(f: X \rightarrow Y\) und \(g: Y \rightarrow Z\). \[ g \circ f : X \rightarrow Z \text{ mit } (g \circ f)(x) = {{c1::g(f(x)) }}\] |
Sei \(f: X \rightarrow Y\) und \(g: Y \rightarrow Z\). \[ g \circ f : X \rightarrow Z \text{ mit } (g \circ f)(x) = {{c1::g(f(x)) }}\] |
| Extra |
\(f\) ist die innere und \(g\) die äußere Funktion. |
\(f\) ist die innere und \(g\) die äussere Funktion. |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Note 27: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: IWY(~?%X0)
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\). Dann gilt \[ \lim_{x \to x_o} f(x) = L \] genau dann, wenn {{c1::für jede konvergente Folge \((x_n)_{n \in \mathbb{N}_0}\) welche gegen \(x_0\) konvergiert gilt \[ \lim_{n \to \infty} f(x_n) = L \]}}
Back
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\). Dann gilt \[ \lim_{x \to x_o} f(x) = L \] genau dann, wenn {{c1::für jede konvergente Folge \((x_n)_{n \in \mathbb{N}_0}\) welche gegen \(x_0\) konvergiert gilt \[ \lim_{n \to \infty} f(x_n) = L \]}}
After
Front
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\). Dann gilt:\[ \lim_{x \to x_o} f(x) = L \] genau dann, wenn {{c1::für jede konvergente Folge \((x_n)_{n \in \mathbb{N}_0}\), welche gegen \(x_0\) konvergiert, gilt: \[ \lim_{n \to \infty} f(x_n) = L \]}}
Back
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\). Dann gilt:\[ \lim_{x \to x_o} f(x) = L \] genau dann, wenn {{c1::für jede konvergente Folge \((x_n)_{n \in \mathbb{N}_0}\), welche gegen \(x_0\) konvergiert, gilt: \[ \lim_{n \to \infty} f(x_n) = L \]}}
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\). Dann gilt \[ \lim_{x \to x_o} f(x) = L \] genau dann, wenn {{c1::für jede konvergente Folge \((x_n)_{n \in \mathbb{N}_0}\) welche gegen \(x_0\) konvergiert gilt \[ \lim_{n \to \infty} f(x_n) = L \]}} |
Es sei \(f : \mathbb{D}(f) \to \mathbb{R}\). Dann gilt:\[ \lim_{x \to x_o} f(x) = L \] genau dann, wenn {{c1::für jede konvergente Folge \((x_n)_{n \in \mathbb{N}_0}\), welche gegen \(x_0\) konvergiert, gilt: \[ \lim_{n \to \infty} f(x_n) = L \]}} |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::3._Grenzwerte
Note 28: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: IZ]eCute5j
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Es sei \(f: \mathcal{D}(f) \rightarrow \mathcal{R}\) mit \(\mathcal{D}(f) \neq \emptyset\). Dann heißt \(f\) nach oben beschränkt, falls \(M \in \mathbb{R}\) existiert mit {{c1::\(f(x) \le M\) \(\forall x \in \mathbb{D}(f)\)}}.
Back
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Es sei \(f: \mathcal{D}(f) \rightarrow \mathcal{R}\) mit \(\mathcal{D}(f) \neq \emptyset\). Dann heißt \(f\) nach oben beschränkt, falls \(M \in \mathbb{R}\) existiert mit {{c1::\(f(x) \le M\) \(\forall x \in \mathbb{D}(f)\)}}.
After
Front
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Es sei \(f: \mathcal{D}(f) \rightarrow \mathcal{R}\) mit \(\mathcal{D}(f) \neq \emptyset\).
Dann heisst \(f\) nach oben beschränkt, falls \(M \in \mathbb{R}\) existiert mit {{c1::\(f(x) \le M\) \(\forall x \in \mathbb{D}(f)\)}}.
Back
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Es sei \(f: \mathcal{D}(f) \rightarrow \mathcal{R}\) mit \(\mathcal{D}(f) \neq \emptyset\).
Dann heisst \(f\) nach oben beschränkt, falls \(M \in \mathbb{R}\) existiert mit {{c1::\(f(x) \le M\) \(\forall x \in \mathbb{D}(f)\)}}.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Es sei \(f: \mathcal{D}(f) \rightarrow \mathcal{R}\) mit \(\mathcal{D}(f) \neq \emptyset\). Dann heißt \(f\) nach oben beschränkt, falls \(M \in \mathbb{R}\) existiert mit {{c1::\(f(x) \le M\) \(\forall x \in \mathbb{D}(f)\)}}. |
Es sei \(f: \mathcal{D}(f) \rightarrow \mathcal{R}\) mit \(\mathcal{D}(f) \neq \emptyset\). <br><br>Dann heisst \(f\) nach oben beschränkt, falls \(M \in \mathbb{R}\) existiert mit {{c1::\(f(x) \le M\) \(\forall x \in \mathbb{D}(f)\)}}. |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::1._Grundlagen
Note 29: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Classic
GUID: U9#5Fg5CA.
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::5._Cauchy_Produkt
Unter welcher Bedingung darf man bei einer Doppelreihe \((a_{ij})\) die Summationsreihenfolge vertauschen?
Back
ETH::2._Semester::Analysis::3._Reihen::5._Cauchy_Produkt
Unter welcher Bedingung darf man bei einer Doppelreihe \((a_{ij})\) die Summationsreihenfolge vertauschen?
Wenn \(\exists B \geq 0\) so dass für alle \(m \in \mathbb{N}\) gilt:
\[\sum_{i=0}^m \sum_{j=0}^m |a_{ij}| \leq B\]Dann konvergieren Spalten- und Reihensummen absolut und sind gleich:
\[\sum_i S_i = \sum_j U_j = S\]Auch jede linear geordnete Summe konvergiert absolut gegen \(S\).
After
Front
ETH::2._Semester::Analysis::3._Reihen::5._Cauchy_Produkt
Unter welcher Bedingung darf man bei einer Doppelreihe \((a_{ij})\) die Summationsreihenfolge vertauschen?
Back
ETH::2._Semester::Analysis::3._Reihen::5._Cauchy_Produkt
Unter welcher Bedingung darf man bei einer Doppelreihe \((a_{ij})\) die Summationsreihenfolge vertauschen?
Wenn \(\exists B \geq 0\) so dass für alle \(m \in \mathbb{N}\) gilt:
\[\sum_{i=0}^m \sum_{j=0}^m |a_{ij}| \leq B\]dann konvergieren Zeilen- und Spaltensummen absolut und sind gleich:
\[\sum_i S_i = \sum_j U_j = S\]Auch jede linear geordnete Summe konvergiert absolut gegen \(S\).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wenn \(\exists B \geq 0\) so dass für alle \(m \in \mathbb{N}\) gilt:<br>\[\sum_{i=0}^m \sum_{j=0}^m |a_{ij}| \leq B\]Dann konvergieren Spalten- und Reihensummen absolut und sind gleich:<br>\[\sum_i S_i = \sum_j U_j = S\]Auch jede linear geordnete Summe konvergiert absolut gegen \(S\). |
Wenn \(\exists B \geq 0\) so dass für alle \(m \in \mathbb{N}\) gilt:<br>\[\sum_{i=0}^m \sum_{j=0}^m |a_{ij}| \leq B\]dann konvergieren Zeilen- und Spaltensummen absolut und sind gleich:<br>\[\sum_i S_i = \sum_j U_j = S\]Auch jede linear geordnete Summe konvergiert absolut gegen \(S\). |
Tags:
ETH::2._Semester::Analysis::3._Reihen::5._Cauchy_Produkt
Note 30: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: ^XO)+qiLKO
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Eine
Potenzreihe hat die Form \({{c5:: \displaystyle\sum_{k=0}^\infty c_k (x - a)^k }}\), wobei:
- \(a\) heisst Entwicklungspunkt (Zentrum)
- \(c_0, c_1, \ldots\) heissen Koeffizienten
- \(x\) heisst Argument
- \((a - R,\, a + R)\) heisst Konvergenzintervall
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Eine
Potenzreihe hat die Form \({{c5:: \displaystyle\sum_{k=0}^\infty c_k (x - a)^k }}\), wobei:
- \(a\) heisst Entwicklungspunkt (Zentrum)
- \(c_0, c_1, \ldots\) heissen Koeffizienten
- \(x\) heisst Argument
- \((a - R,\, a + R)\) heisst Konvergenzintervall
Spezialfall \(a = 0\):
\(\sum c_k x^k\) - Entwicklungspunkt im Ursprung.
After
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Eine
Potenzreihe hat die Form \({{c5:: \displaystyle\sum_{k=0}^\infty c_k (x - a)^k }}\), wobei:
- \(a\) ist der Entwicklungspunkt (Zentrum)
- \(c_0, c_1, \ldots\) sind die Koeffizienten
- \(x\) ist das Argument
- \((a - R,\, a + R)\) ist das Konvergenzintervall
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Eine
Potenzreihe hat die Form \({{c5:: \displaystyle\sum_{k=0}^\infty c_k (x - a)^k }}\), wobei:
- \(a\) ist der Entwicklungspunkt (Zentrum)
- \(c_0, c_1, \ldots\) sind die Koeffizienten
- \(x\) ist das Argument
- \((a - R,\, a + R)\) ist das Konvergenzintervall
Spezialfall \(a = 0\):
\(\sum c_k x^k\) - Entwicklungspunkt im Ursprung.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eine <b>Potenzreihe</b> hat die Form \({{c5:: \displaystyle\sum_{k=0}^\infty c_k (x - a)^k }}\), wobei:<br><ul><li>\(a\) heisst {{c1::Entwicklungspunkt (Zentrum)}}</li><li>\(c_0, c_1, \ldots\) heissen {{c2::Koeffizienten}}</li><li>\(x\) heisst {{c3::Argument}}</li><li>\((a - R,\, a + R)\) heisst {{c4::Konvergenzintervall}}</li></ul> |
Eine <b>Potenzreihe</b> hat die Form \({{c5:: \displaystyle\sum_{k=0}^\infty c_k (x - a)^k }}\), wobei:<br><ul><li>\(a\) ist {{c1::der Entwicklungspunkt (Zentrum)}}</li><li>\(c_0, c_1, \ldots\) sind {{c2::die Koeffizienten}}</li><li>\(x\) ist {{c3::das Argument}}</li><li>\((a - R,\, a + R)\) ist {{c4::das Konvergenzintervall}}</li></ul> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen::1._Potenzreihe
Note 31: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: fr%yq&f{dL
modified
Before
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::1._Definitionen
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ sodass } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::1._Definitionen
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ sodass } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Genauso kann die Folge auch gegen \(-\infty\) divergieren.
After
Front
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::1._Definitionen
Falls für eine Folge gilt:
\[{{c1:: \forall M > 0 \ \exists N > 0 \text{ sodass } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Back
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::1._Definitionen
Falls für eine Folge gilt:
\[{{c1:: \forall M > 0 \ \exists N > 0 \text{ sodass } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge gegen unendlich divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\).
Genauso kann die Folge auch gegen \(-\infty\) divergieren.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Falls für eine Folge gilt \[{{c1:: \forall M > 0 \ \exists N > 0 \text{ sodass } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge <i>gegen unendlich</i> divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\). |
Falls für eine Folge gilt:<br>\[{{c1:: \forall M > 0 \ \exists N > 0 \text{ sodass } \forall n > N \ : \ a_n > M }}\] sagen wir, dass die Folge <i>gegen unendlich</i> divergiert und schreiben \(\lim_{n \rightarrow \infty} a_n = \infty\). |
Tags:
ETH::2._Semester::Analysis::2._Folgen::2._Konvergenz::1._Definitionen
Note 32: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: f|yr~E%TB^
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Die Reihe \(\sum_{k=1}^\infty a_k\), \(a_k = b_k - b_{k-1}\) konvergiert gdw. {{c1::\(\lim_{n\to\infty} b_n\) existiert}}.
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Die Reihe \(\sum_{k=1}^\infty a_k\), \(a_k = b_k - b_{k-1}\) konvergiert gdw. {{c1::\(\lim_{n\to\infty} b_n\) existiert}}.
After
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Eine Teleskopreihe \(\sum_{k=1}^\infty (b_k - b_{k-1})\) konvergiert genau dann, wenn {{c1::\(\lim_{n\to\infty} b_n\) existiert}}.
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Eine Teleskopreihe \(\sum_{k=1}^\infty (b_k - b_{k-1})\) konvergiert genau dann, wenn {{c1::\(\lim_{n\to\infty} b_n\) existiert}}.
In diesem Fall gilt \(\sum_{k=1}^\infty (b_k - b_{k-1}) = \lim_{n\to\infty} b_n - b_0\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Die Reihe \(\sum_{k=1}^\infty a_k\), \(a_k = b_k - b_{k-1}\) konvergiert gdw. {{c1::\(\lim_{n\to\infty} b_n\) existiert}}. |
Eine <b>Teleskopreihe</b> \(\sum_{k=1}^\infty (b_k - b_{k-1})\) konvergiert genau dann, wenn {{c1::\(\lim_{n\to\infty} b_n\) existiert}}. |
| Extra |
|
In diesem Fall gilt \(\sum_{k=1}^\infty (b_k - b_{k-1}) = \lim_{n\to\infty} b_n - b_0\). |
Tags:
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Note 33: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: j1*KfG}T{:
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heißt bedingt konvergent, wenn sie konvergiert, aber nicht absolut konvergiert.
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heißt bedingt konvergent, wenn sie konvergiert, aber nicht absolut konvergiert.
Beispiel:
\(\sum \frac{(-1)^n}{n}\) ist bedingt konvergent.
After
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heisst bedingt konvergent, wenn sie konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert.
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heisst bedingt konvergent, wenn sie konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert.
(D.h. nicht absolut konvergiert..)
Beispiel:
\(\sum \frac{(-1)^n}{n}\) ist bedingt konvergent.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eine Reihe heißt <b>bedingt konvergent</b>, wenn sie {{c1::konvergiert, aber nicht absolut konvergiert}}. |
Eine Reihe heisst <b>bedingt konvergent</b>, wenn sie {{c1::konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert}}. |
| Extra |
<b>Beispiel:</b> <br>\(\sum \frac{(-1)^n}{n}\) ist bedingt konvergent. |
(D.h. nicht absolut konvergiert..)<br><br><b>Beispiel:</b> <br>\(\sum \frac{(-1)^n}{n}\) ist bedingt konvergent. |
Tags:
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Note 34: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: k!m:Bg$t#^
modified
Before
Front
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::4._Komplexe_Zahlen::3._Eulersche_Formel
Eulersche Formel:\[ \sin(t) = {{c1:: \frac{e^{it} - e^{-it} }{2i} :: Exponentialform }}\]
Back
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::4._Komplexe_Zahlen::3._Eulersche_Formel
Eulersche Formel:\[ \sin(t) = {{c1:: \frac{e^{it} - e^{-it} }{2i} :: Exponentialform }}\]
After
Front
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::4._Komplexe_Zahlen::3._Eulersche_Formel
Eulersche Formel:\[ \sin(t) = {{c1:: \frac{e^{it} - e^{-it} }{2i} ::\text{Exponentialform} }}\]
Back
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::4._Komplexe_Zahlen::3._Eulersche_Formel
Eulersche Formel:\[ \sin(t) = {{c1:: \frac{e^{it} - e^{-it} }{2i} ::\text{Exponentialform} }}\]
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eulersche Formel:\[ \sin(t) = {{c1:: \frac{e^{it} - e^{-it} }{2i} :: Exponentialform }}\] |
Eulersche Formel:\[ \sin(t) = {{c1:: \frac{e^{it} - e^{-it} }{2i} ::\text{Exponentialform} }}\] |
Tags:
ETH::2._Semester::Analysis::1._Logik,_Mengen,_Zahlen::3._Zahlen::4._Komplexe_Zahlen::3._Eulersche_Formel
Note 35: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: s_=B4I[Nwv
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Sei \(a_n \geq 0\) für alle \(n\). Dann ist \(S_n\) monoton wachsend.
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Sei \(a_n \geq 0\) für alle \(n\). Dann ist \(S_n\) monoton wachsend.
Für \(a_n \geq 0\) gibt es nur zwei Fälle: konvergiert oder divergiert gegen \(+\infty\)
After
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Sei \(a_n \geq 0\) für alle \(n\). Dann ist \(S_n\) monoton wachsend.
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Sei \(a_n \geq 0\) für alle \(n\). Dann ist \(S_n\) monoton wachsend.
Für \(a_n \geq 0\) gibt es nur zwei Fälle: konvergiert oder divergiert gegen \(+\infty\)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Sei \(a_n \geq 0\) für alle \(n\). Dann ist \(S_n\) {{c1::monoton wachsend}}. |
Sei \(a_n \geq 0\) für alle \(n\). Dann ist \(S_n\) {{c1::monoton wachsend::Wachstumsverhalten}}. |
Tags:
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Note 36: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: ssLcC6IoOk
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Das Majoranten-/Minorantenkriterium gilt nur, wenn beide Folgen nicht-negativ sind: \(0 \leq a_n \leq b_n\).
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Das Majoranten-/Minorantenkriterium gilt nur, wenn beide Folgen nicht-negativ sind: \(0 \leq a_n \leq b_n\).
Für alternierende Reihen ist es nicht direkt anwendbar, erst Absolutkonvergenz mit \(\sum |a_n|\) zeigen, dann folgt Konvergenz.
Häufiger Fehler: Vergleich von \((-1)^n/n\) mit \(1/n\) über Majorante. Das scheitert, da \((-1)^n/n \not\geq 0\).
After
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Das Majoranten-/Minorantenkriterium gilt nur für Reihen mit nicht-negativen Gliedern (ab einem Index \(N\)): \(0 \leq a_n \leq b_n\) für alle \(n \geq N\).
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Das Majoranten-/Minorantenkriterium gilt nur für Reihen mit nicht-negativen Gliedern (ab einem Index \(N\)): \(0 \leq a_n \leq b_n\) für alle \(n \geq N\).
Für alternierende Reihen ist es nicht direkt anwendbar, erst Absolutkonvergenz mit \(\sum |a_n|\) zeigen, dann folgt Konvergenz.
Häufiger Fehler: Vergleich von \((-1)^n/n\) mit \(1/n\) über Majorante. Das scheitert, da \((-1)^n/n \not\geq 0\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Das Majoranten-/Minorantenkriterium gilt nur, wenn {{c1::beide Folgen nicht-negativ sind: \(0 \leq a_n \leq b_n\)}}. |
Das Majoranten-/Minorantenkriterium gilt nur für {{c1::Reihen mit nicht-negativen Gliedern (ab einem Index \(N\)): \(0 \leq a_n \leq b_n\) für alle \(n \geq N\)}}. |
Tags:
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Note 37: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: z!sAYo_L3D
modified
Before
Front
ETH::2._Semester::Analysis::2._Folgen::1._Folgen::1._Properties
Für alle Polynome \(P(n)\) mit \(P(n) > 0\), gilt für große \(n\): \[ \lim_{n \rightarrow \infty} \sqrt[n]{P(n)} = 1 \]
Back
ETH::2._Semester::Analysis::2._Folgen::1._Folgen::1._Properties
Für alle Polynome \(P(n)\) mit \(P(n) > 0\), gilt für große \(n\): \[ \lim_{n \rightarrow \infty} \sqrt[n]{P(n)} = 1 \]
(Die Wurzel dämpft diese vollständig ab.)
After
Front
ETH::2._Semester::Analysis::2._Folgen::1._Folgen::1._Properties
Für alle Polynome \(P(n)\) mit \(P(n) > 0\), gilt für grosse \(n\): \[ \lim_{n \rightarrow \infty} \sqrt[n]{P(n)} = 1 \]
Back
ETH::2._Semester::Analysis::2._Folgen::1._Folgen::1._Properties
Für alle Polynome \(P(n)\) mit \(P(n) > 0\), gilt für grosse \(n\): \[ \lim_{n \rightarrow \infty} \sqrt[n]{P(n)} = 1 \]
(Die Wurzel dämpft diese vollständig ab.)
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Für alle Polynome \(P(n)\) mit \(P(n) > 0\), gilt für große \(n\): \[ \lim_{n \rightarrow \infty} \sqrt[n]{P(n)} = {{c1:: 1}} \] |
Für alle Polynome \(P(n)\) mit \(P(n) > 0\), gilt für grosse \(n\): \[ \lim_{n \rightarrow \infty} \sqrt[n]{P(n)} = {{c1:: 1}} \] |
Tags:
ETH::2._Semester::Analysis::2._Folgen::1._Folgen::1._Properties
Note 38: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: }3LSktDYts
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Die Riemansche-Zeta Funktion Reihe \(\displaystyle\zeta(s) = {{c1:: \sum_{n=1}^\infty \frac{1}{n^s} }}\) konvergiert für s > 1 und divergiert für s \(\leq 1\).
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Die Riemansche-Zeta Funktion Reihe \(\displaystyle\zeta(s) = {{c1:: \sum_{n=1}^\infty \frac{1}{n^s} }}\) konvergiert für s > 1 und divergiert für s \(\leq 1\).
Oft als Referenzreihe im Vergleichssatz nützlich (wenn Wurzel/Quotient versagen).
After
Front
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Die Riemansche-Zeta Funktion Reihe \(\displaystyle\zeta(s) = {{c1:: \sum_{n=1}^\infty \frac{1}{n^s} }}\) konvergiert für \(s > 1\) und divergiert für \(s\leq1\).
Back
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Die Riemansche-Zeta Funktion Reihe \(\displaystyle\zeta(s) = {{c1:: \sum_{n=1}^\infty \frac{1}{n^s} }}\) konvergiert für \(s > 1\) und divergiert für \(s\leq1\).
Oft als Referenzreihe im Vergleichssatz nützlich (wenn Wurzel/Quotient versagen).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Die Riemansche-Zeta Funktion Reihe \(\displaystyle\zeta(s) = {{c1:: \sum_{n=1}^\infty \frac{1}{n^s} }}\) konvergiert für {{c2::s > 1}} und divergiert für {{c2::s \(\leq 1\)}}. |
Die Riemansche-Zeta Funktion Reihe \(\displaystyle\zeta(s) = {{c1:: \sum_{n=1}^\infty \frac{1}{n^s} }}\) konvergiert für {{c2::\(s > 1\)}} und divergiert für {{c2::\(s\leq1\)}}. |
Tags:
ETH::2._Semester::Analysis::3._Reihen::2._Standard_Reihen
Note 39: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: }3V6.(tcBx
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
- Die Konvergenz einer Reihe hängt nicht von den ersten \(N\) Termen ab.
- Der Wert der Reihe hängt jedoch schon davon ab.
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
- Die Konvergenz einer Reihe hängt nicht von den ersten \(N\) Termen ab.
- Der Wert der Reihe hängt jedoch schon davon ab.
\(\displaystyle\sum_{n=0}^\infty a_n = \sum_{n=0}^{N-1} a_n + \sum_{n=N}^\infty a_n\)
After
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Die Konvergenz einer Reihe ist unabhängig von endlich vielen Anfangsgliedern.
Der Wert einer Reihe ist jedoch abhängig von den Anfangsgliedern.
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Die Konvergenz einer Reihe ist unabhängig von endlich vielen Anfangsgliedern.
Der Wert einer Reihe ist jedoch abhängig von den Anfangsgliedern.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<ul><li>Die {{c1::<b>Konvergenz</b>}} einer Reihe {{c2::hängt nicht von den ersten \(N\) Termen ab}}.</li><li>Der {{c1::<b>Wert</b>}} der Reihe {{c2::hängt jedoch schon davon ab}}.</li></ul> |
Die {{c1::<b>Konvergenz</b>}} einer Reihe ist {{c2::unabhängig}} von endlich vielen Anfangsgliedern.<br><br>Der {{c1::<b>Wert</b>}} einer Reihe ist {{c2::jedoch abhängig}} von den Anfangsgliedern. |
| Extra |
\(\displaystyle\sum_{n=0}^\infty a_n = \sum_{n=0}^{N-1} a_n + \sum_{n=N}^\infty a_n\) |
|
Tags:
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Note 40: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: 3fV+]~d+w}
modified
Before
Front
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
What are the work and span of parallel merge sort, and what limits its parallelism?
Back
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
What are the work and span of parallel merge sort, and what limits its parallelism?
- Work: \(O(n \log n)\) - same as sequential
- Span: \(O(\log^2 n)\) - recursive calls parallelized (O(log n) depth) but merge step takes O(log n) span via parallel merge
- Parallelism: \(O(n/\log n)\)
Bottleneck: The merge step.
A sequential merge gives \(O(n)\) span, limiting parallelism to \(O(\log n)\).
After
Front
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
What are the work and span of parallel merge sort, and what limits its parallelism?
Back
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
What are the work and span of parallel merge sort, and what limits its parallelism?
- Work: \(O(n \log n)\) - same as sequential
- Span: \(O(\log^2 n)\) - recursive calls parallelized (\(O(\log n)\) depth) but merge step takes \(O(\log n)\) span via parallel merge
- Parallelism: \(O(n/\log n)\)
Bottleneck: The merge step.
A sequential merge gives \(O(n)\) span, limiting parallelism to \(O(\log n)\).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
<ul><li><b>Work</b>: \(O(n \log n)\) - same as sequential</li><li><b>Span</b>: \(O(\log^2 n)\) - recursive calls parallelized (O(log n) depth) but merge step takes O(log n) span via parallel merge</li><li><b>Parallelism</b>: \(O(n/\log n)\)</li></ul>Bottleneck: The merge step. <br>A sequential merge gives \(O(n)\) span, limiting parallelism to \(O(\log n)\). |
<ul><li><b>Work</b>: \(O(n \log n)\) - same as sequential</li><li><b>Span</b>: \(O(\log^2 n)\) - recursive calls parallelized (\(O(\log n)\) depth) but merge step takes \(O(\log n)\) span via parallel merge</li><li><b>Parallelism</b>: \(O(n/\log n)\)</li></ul>Bottleneck: The merge step. <br>A sequential merge gives \(O(n)\) span, limiting parallelism to \(O(\log n)\). |
Tags:
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
Note 41: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: EdVyAbz-qv
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
AtomicInteger provides atomic compound operations such as getAndIncrement() and compareAndSet(expected, update) without requiring synchronized.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
AtomicInteger provides atomic compound operations such as getAndIncrement() and compareAndSet(expected, update) without requiring synchronized.
Faster than synchronized for simple counters.
Implemented via hardware CAS (compare-and-swap).
Part of java.util.concurrent.atomic.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
AtomicInteger provides atomic compound operations such as getAndIncrement() and compareAndSet(expected, update) without requiring synchronized.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
AtomicInteger provides atomic compound operations such as getAndIncrement() and compareAndSet(expected, update) without requiring synchronized.
Faster than synchronized for simple counters.
Implemented via hardware CAS (compare-and-swap).
Part of java.util.concurrent.atomic.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<code>{{c1::AtomicInteger}}</code> provides {{c2::atomic compound operations}} such as <code>getAndIncrement()</code> and <code>compareAndSet(expected, update)</code> without requiring <code>synchronized</code>. |
<code>{{c1::AtomicInteger}}</code> provides {{c2::atomic compound operations such as <code>getAndIncrement()</code> and <code>compareAndSet(expected, update)}}</code> without requiring <code>synchronized</code>. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
Note 42: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: GH&YPQRsTh
modified
Before
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Lead-in and lead-out reduce effective throughput below the theoretical bound for a finite number of elements N.
Their impact is largest when N is small (short pipelines).
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Lead-in and lead-out reduce effective throughput below the theoretical bound for a finite number of elements N.
Their impact is largest when N is small (short pipelines).
Example:
For a finite run, effective throughput was 0.7 while the infinite-stream bound was 1. As N → ∞, effective throughput approaches 1/max(stage_time).
After
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Lead-in and lead-out reduce effective throughput below the theoretical bound for a finite number of elements \(N\).
Their impact is largest when \(N\) is small (short pipelines).
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Lead-in and lead-out reduce effective throughput below the theoretical bound for a finite number of elements \(N\).
Their impact is largest when \(N\) is small (short pipelines).
Example:
For a finite run, effective throughput was 0.7 while the infinite-stream bound was 1. As N → ∞, effective throughput approaches 1/max(stage_time).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Lead-in and lead-out reduce {{c1::effective throughput below the theoretical bound}} for {{c2::a finite number of elements N}}. <br><br>Their impact is largest when {{c3::N is small (short pipelines)}}. |
Lead-in and lead-out reduce {{c1::effective throughput below the theoretical bound}} for {{c2::a finite number of elements \(N\)}}. <br><br>Their impact is largest when {{c3::\(N\) is small (short pipelines)}}. |
Tags:
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Note 43: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: KD1&||&6xW
modified
Before
Front
ETH::2._Semester::PProg::10._Parallel_Algorithms::1._Task_graphs_and_performance_measures
Why is \(T_p \geq T_1/p\) a strict lower bound - why can no scheduler beat it?
Back
ETH::2._Semester::PProg::10._Parallel_Algorithms::1._Task_graphs_and_performance_measures
Why is \(T_p \geq T_1/p\) a strict lower bound - why can no scheduler beat it?
\(T_1\) is the total work (sum of all node costs in the DAG).
With p processors, at most p units of work can be done per time step.
Therefore the minimum time to do \(T_1\) units of work is \(T_1/p\).
This is a counting argument, independent of the scheduler's strategy.
After
Front
ETH::2._Semester::PProg::10._Parallel_Algorithms::1._Task_graphs_and_performance_measures
Why is \(T_p \geq T_1/p\) a strict lower bound - why can no scheduler beat it?
Back
ETH::2._Semester::PProg::10._Parallel_Algorithms::1._Task_graphs_and_performance_measures
Why is \(T_p \geq T_1/p\) a strict lower bound - why can no scheduler beat it?
\(T_1\) is the total work (sum of all node costs in the DAG).
With \(p\) processors, at most \(p\) units of work can be done per time step.
Therefore the minimum time to do \(T_1\) units of work is \(T_1/p\).
This is a counting argument, independent of the scheduler's strategy.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
\(T_1\) is the total work (sum of all node costs in the DAG). <br>With p processors, at most p units of work can be done per time step. <br>Therefore the minimum time to do \(T_1\) units of work is \(T_1/p\).<br><br>This is a counting argument, independent of the scheduler's strategy. |
\(T_1\) is the total work (sum of all node costs in the DAG). <br>With \(p\) processors, at most \(p\) units of work can be done per time step. <br>Therefore the minimum time to do \(T_1\) units of work is \(T_1/p\).<br><br>This is a counting argument, independent of the scheduler's strategy. |
Tags:
ETH::2._Semester::PProg::10._Parallel_Algorithms::1._Task_graphs_and_performance_measures
Note 44: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: O>b+4REo=(
modified
Before
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::2._Instruction_Level_Parallelism
Instruction-level parallelism (ILP)
- dependency analysis (execute independent instructions in parallel, reorder to keep the CPU busy)
- speculative execution (execute a branch before the condition is resolved, roll back if wrong).
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::2._Instruction_Level_Parallelism
Instruction-level parallelism (ILP)
- dependency analysis (execute independent instructions in parallel, reorder to keep the CPU busy)
- speculative execution (execute a branch before the condition is resolved, roll back if wrong).
ILP happens on a single thread — no concurrency. It is hardware-dependent (requires superscalar execution units).
After
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::2._Instruction_Level_Parallelism
Instruction-Level Parallelism (ILP) uses two techniques:
- Dependency Analysis: Execute independent instructions in parallel or reorder them to keep the CPU busy.
- Speculative Execution: Execute a branch before the condition is resolved; roll back if the prediction was wrong.
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::2._Instruction_Level_Parallelism
Instruction-Level Parallelism (ILP) uses two techniques:
- Dependency Analysis: Execute independent instructions in parallel or reorder them to keep the CPU busy.
- Speculative Execution: Execute a branch before the condition is resolved; roll back if the prediction was wrong.
ILP happens on a single thread - no concurrency. It is hardware-dependent (requires superscalar execution units).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Instruction-level parallelism (ILP)<br><ul><li>{{c1::dependency analysis (execute independent instructions in parallel, reorder to keep the CPU busy) }}</li><li>{{c2::speculative execution (execute a branch before the condition is resolved, roll back if wrong). }} </li></ul> |
<b>Instruction-Level Parallelism (ILP)</b> uses two techniques:<br><ol><li>{{c1::Dependency Analysis: Execute independent instructions in parallel or reorder them to keep the CPU busy.}}</li><li>{{c2::Speculative Execution: Execute a branch before the condition is resolved; roll back if the prediction was wrong.}}</li></ol> |
| Extra |
ILP happens on a <b>single thread</b> — no concurrency. It is hardware-dependent (requires superscalar execution units). |
ILP happens on a <b>single thread</b> - no concurrency. It is hardware-dependent (requires superscalar execution units). |
Tags:
ETH::2._Semester::PProg::06._Parallel_Architecture::2._Instruction_Level_Parallelism
Note 45: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: OG4szVeI~<
modified
Before
Front
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
Why does parallel prefix sum require two passes (up then down) rather than one?
Back
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
Why does parallel prefix sum require two passes (up then down) rather than one?
The up pass computes subtree sums — it doesn't know what came "before" each element globally. The down pass distributes accumulated sums from the root downward, so each leaf learns the total sum of all elements to its left. No single pass can do both simultaneously because each node needs both its subtree total (from children) and the prefix from its ancestors.
After
Front
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
Why does parallel prefix sum require two passes (up then down) rather than one?
Back
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
Why does parallel prefix sum require two passes (up then down) rather than one?
The up-sweep computes partial sums in a tree structure, but each node only knows the sum of its subtree - not the sum of all elements to its left.
The down-sweep propagates these missing left-side contributions back down the tree, so that every position ends up with the correct prefix sum.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
The up pass computes subtree sums — it doesn't know what came "before" each element globally. The down pass distributes accumulated sums from the root downward, so each leaf learns the total sum of all elements to its left. No single pass can do both simultaneously because each node needs both its subtree total (from children) and the prefix from its ancestors. |
The <b>up-sweep</b> computes partial sums in a tree structure, but each node only knows the sum of its subtree - not the sum of all elements to its left. <br><br>The <b>down-sweep</b> propagates these missing left-side contributions back down the tree, so that every position ends up with the correct prefix sum. |
Tags:
ETH::2._Semester::PProg::10._Parallel_Algorithms::3._Parallel_algorithms
Note 46: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: Q$hlo>kuR^
modified
Before
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Latency of the n-th element in an unbalanced pipeline \(= {{c1::\text{latency}_1 + \bigl(\max(\text{stage_time}) - \text{time}(\text{stage}_1)\bigr) \cdot (n-1)}}\)
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Latency of the n-th element in an unbalanced pipeline \(= {{c1::\text{latency}_1 + \bigl(\max(\text{stage_time}) - \text{time}(\text{stage}_1)\bigr) \cdot (n-1)}}\)
Latency grows linearly with n when the pipeline is unbalanced — elements pile up at the bottleneck. If balanced, this simplifies to latency₁ (constant).
After
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Latency of the n-th element in an unbalanced pipeline:
\[{{c1:: L(n) = L(1) + (n-1) \cdot \max_i(\text{stage time}_i) }}\]
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Latency of the n-th element in an unbalanced pipeline:
\[{{c1:: L(n) = L(1) + (n-1) \cdot \max_i(\text{stage time}_i) }}\]
The first element pays the full pipeline latency \(L(1) = \sum_i \text{stage time}_i\). Each subsequent element is delayed by the slowest stage (bottleneck).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Latency of the <b>n-th</b> element in an unbalanced pipeline \(= {{c1::\text{latency}_1 + \bigl(\max(\text{stage_time}) - \text{time}(\text{stage}_1)\bigr) \cdot (n-1)}}\) |
Latency of the <b>n-th</b> element in an <b>unbalanced</b> pipeline:<br>\[{{c1:: L(n) = L(1) + (n-1) \cdot \max_i(\text{stage time}_i) }}\] |
| Extra |
Latency grows linearly with n when the pipeline is unbalanced — elements pile up at the bottleneck. If balanced, this simplifies to latency₁ (constant). |
The first element pays the full pipeline latency \(L(1) = \sum_i \text{stage time}_i\). Each subsequent element is delayed by the <b>slowest stage</b> (bottleneck). |
Tags:
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Note 47: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: Q({*qU*f^i
modified
Before
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What are the lead-in and lead-out phases of a pipeline?
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What are the lead-in and lead-out phases of a pipeline?
Lead-in (warm-up): the pipeline is filling — earlier stages have started but later stages are still idle. Not all stages are doing useful work yet.
Lead-out (cool-down): the pipeline is draining — earlier stages have finished but later stages are still processing. Earlier stages become idle.
After
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What are the lead-in and lead-out phases of a pipeline?
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What are the lead-in and lead-out phases of a pipeline?
Lead-in: The initial phase where the pipeline is filling up - not all stages are busy yet.
Lead-out: The final phase where the pipeline is draining - no new elements enter, and stages finish one by one.
Only during the steady state between them is the pipeline fully utilized.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
<b>Lead-in</b> (warm-up): the pipeline is filling — earlier stages have started but later stages are still idle. Not all stages are doing useful work yet.<br><b>Lead-out</b> (cool-down): the pipeline is draining — earlier stages have finished but later stages are still processing. Earlier stages become idle. |
<b>Lead-in:</b> The initial phase where the pipeline is filling up - not all stages are busy yet.<br><br><b>Lead-out:</b> The final phase where the pipeline is draining - no new elements enter, and stages finish one by one.<br><br>Only during the <b>steady state</b> between them is the pipeline fully utilized. |
Tags:
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Note 48: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: RJC9+1Wgmi
modified
Before
Front
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
exec.shutdown() stops accepting new tasks but lets already-submitted tasks finish.exec.shutdownNow() attempts to interrupt all running tasks and returns the list of unstarted tasks.
Back
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
exec.shutdown() stops accepting new tasks but lets already-submitted tasks finish.exec.shutdownNow() attempts to interrupt all running tasks and returns the list of unstarted tasks.
Use awaitTermination(timeout, unit) after shutdown() to block until all tasks complete or the timeout expires.
After
Front
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
Shutting down an ExecutorService:shutdown(): No new tasks accepted, but already-submitted tasks run to completion.shutdownNow(): Interrupts running tasks and returns a list of unstarted tasks.
Back
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
Shutting down an ExecutorService:shutdown(): No new tasks accepted, but already-submitted tasks run to completion.shutdownNow(): Interrupts running tasks and returns a list of unstarted tasks.
Use awaitTermination(timeout, unit) after shutdown() to block until all tasks complete or the timeout expires.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<ul><li><code>exec.shutdown()</code> {{c1::stops accepting new tasks but lets already-submitted tasks finish}}.</li><li><code>exec.shutdownNow()</code> {{c2::attempts to interrupt all running tasks and returns the list of unstarted tasks}}.</li></ul> |
<b>Shutting down an ExecutorService:</b><br><ul><li><code>shutdown()</code>: {{c1::No new tasks accepted, but already-submitted tasks run to completion.}}</li><li><code>shutdownNow()</code>: {{c1::Interrupts running tasks and returns a list of unstarted tasks.}}</li></ul> |
Tags:
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
Note 49: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: TAzr]%>^o%
modified
Before
Front
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
Name the four standard
ExecutorService pool types and their key characteristics.
newFixedThreadPool(n) fixed n threads; queues excess tasksnewSingleThreadExecutor() exactly 1 thread; tasks execute sequentiallynewCachedThreadPool() elastic; creates threads on demand, reuses idle onesnewScheduledThreadPool(n) supports delayed and periodic tasks
Back
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
Name the four standard
ExecutorService pool types and their key characteristics.
newFixedThreadPool(n) fixed n threads; queues excess tasksnewSingleThreadExecutor() exactly 1 thread; tasks execute sequentiallynewCachedThreadPool() elastic; creates threads on demand, reuses idle onesnewScheduledThreadPool(n) supports delayed and periodic tasks
After
Front
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
The four standard
ExecutorService pool types:
newFixedThreadPool(n) - Fixed n threads; excess tasks are queued.newSingleThreadExecutor() - Exactly 1 thread; tasks execute sequentially.newCachedThreadPool() - Elastic; creates threads on demand, reuses idle ones.newScheduledThreadPool(n) - Supports delayed and periodic task execution.
Back
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
The four standard
ExecutorService pool types:
newFixedThreadPool(n) - Fixed n threads; excess tasks are queued.newSingleThreadExecutor() - Exactly 1 thread; tasks execute sequentially.newCachedThreadPool() - Elastic; creates threads on demand, reuses idle ones.newScheduledThreadPool(n) - Supports delayed and periodic task execution.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Name the four standard <code>ExecutorService</code> pool types and their key characteristics.<br><ul><li><code>{{c1::newFixedThreadPool(n)}}</code> fixed n threads; queues excess tasks</li><li><code>{{c2::newSingleThreadExecutor()}}</code> exactly 1 thread; tasks execute sequentially</li><li><code>{{c3::newCachedThreadPool()}}</code> elastic; creates threads on demand, reuses idle ones</li><li><code>{{c4::newScheduledThreadPool(n)}}</code> supports delayed and periodic tasks</li></ul> |
The four standard <code>ExecutorService</code> pool types:<br><ol><li><code>newFixedThreadPool(n)</code> - {{c1::Fixed <code>n</code> threads; excess tasks are queued.}}</li><li><code>newSingleThreadExecutor()</code> - {{c2::Exactly 1 thread; tasks execute sequentially.}}</li><li><code>newCachedThreadPool()</code> - {{c3::Elastic; creates threads on demand, reuses idle ones.}}</li><li><code>newScheduledThreadPool(n)</code> - {{c4::Supports delayed and periodic task execution.}}</li></ol> |
Tags:
ETH::2._Semester::PProg::09._Divide_and_conquer::3._Executor_Service
Note 50: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: Tc|J+GdHu-
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
The Java volatile keyword guarantees visibility, every read of a volatile field sees the most recent write by any thread — but does not guarantee atomicity of compound operations (e.g. i++).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
The Java volatile keyword guarantees visibility, every read of a volatile field sees the most recent write by any thread — but does not guarantee atomicity of compound operations (e.g. i++).
Use volatile for simple flags (e.g. volatile boolean running). For compound operations, use synchronized or AtomicInteger.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
The Java volatile keyword guarantees visibility, every read of a volatile field sees the most recent write by any thread, but does not guarantee atomicity of compound operations (e.g. i++).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
The Java volatile keyword guarantees visibility, every read of a volatile field sees the most recent write by any thread, but does not guarantee atomicity of compound operations (e.g. i++).
Use volatile for simple flags (e.g. volatile boolean running). For compound operations, use synchronized or AtomicInteger.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
The Java <code>volatile</code> keyword guarantees {{c1::visibility, every read of a volatile field sees}} the {{c2::most recent write by any thread}} — but does <b>not</b> guarantee {{c2::atomicity of compound operations (e.g. i++)}}. |
The Java <code>volatile</code> keyword guarantees {{c1::visibility, every read of a volatile field sees the most recent write by any thread}}, but does <b>not</b> guarantee {{c2::atomicity of compound operations (e.g. i++)}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency
Note 51: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: U/}jSkoobw
modified
Before
Front
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Is it possible for \(T_p < T_1/p\)? What does this mean and what causes it?
Back
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Is it possible for \(T_p < T_1/p\)? What does this mean and what causes it?
Yes, this is
super-linear speedup (\(S_p > p\)). Causes:
- (1) Cache effects — smaller per-thread working sets fit in L1/L2 cache, making memory access faster than in the sequential run which had cache misses.
- (2) Algorithmic differences — the parallel version may explore the problem space differently. Not considered 'magic' — it has a real explanation.
After
Front
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Can we achieve superlinear speedup, i.e. \(S(p) > p\)? What causes it?
Back
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Can we achieve superlinear speedup, i.e. \(S(p) > p\)? What causes it?
Yes, it can happen in practice. Common causes:
- Cache effects: With more processors, each works on a smaller portion of data that fits into cache, reducing memory access time.
- Search/pruning: Parallel threads may explore different branches and find a solution (or prune the search space) earlier than a single thread would.
It does not violate Amdahl's law, which assumes a fixed algorithm - superlinear speedup arises when parallelism changes the effective amount of work.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Is it possible for \(T_p < T_1/p\)? What does this mean and what causes it? |
Can we achieve <b>superlinear speedup</b>, i.e. \(S(p) > p\)? What causes it? |
| Back |
Yes, this is <b>super-linear speedup</b> (\(S_p > p\)). Causes: <br><ul><li>(1) <b>Cache effects</b> — smaller per-thread working sets fit in L1/L2 cache, making memory access faster than in the sequential run which had cache misses.</li><li>(2) <b>Algorithmic differences</b> — the parallel version may explore the problem space differently. Not considered 'magic' — it has a real explanation.</li></ul> |
Yes, it can happen in practice. Common causes:<br><ul><li><b>Cache effects:</b> With more processors, each works on a smaller portion of data that fits into cache, reducing memory access time.</li><li><b>Search/pruning:</b> Parallel threads may explore different branches and find a solution (or prune the search space) earlier than a single thread would.</li></ul>It does not violate Amdahl's law, which assumes a fixed algorithm - superlinear speedup arises when parallelism changes the effective amount of work. |
Tags:
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Note 52: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: VOg3W+qe2?
modified
Before
Front
ETH::2._Semester::PProg::05._Java_Threads::2._synchronized
If an exception is thrown inside a synchronized block, the lock is automatically released when the exception propagates out of the block .
Back
ETH::2._Semester::PProg::05._Java_Threads::2._synchronized
If an exception is thrown inside a synchronized block, the lock is automatically released when the exception propagates out of the block .
This is because synchronized is structured (unlike ReentrantLock which requires explicit finally). The JVM guarantees lock release on any exit from the block, including exceptions.
After
Front
ETH::2._Semester::PProg::05._Java_Threads::2._synchronized
If an exception is thrown inside a synchronized block, the lock is automatically released when the exception propagates out of the block.
Back
ETH::2._Semester::PProg::05._Java_Threads::2._synchronized
If an exception is thrown inside a synchronized block, the lock is automatically released when the exception propagates out of the block.
This is because synchronized is structured (unlike ReentrantLock which requires explicit finally). The JVM guarantees lock release on any exit from the block, including exceptions.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
If an exception is thrown inside a <code>synchronized</code> block, {{c1::the lock is automatically released when the exception propagates out of the block}} . |
If an exception is thrown inside a <code>synchronized</code> block, the lock is {{c1::automatically released when the exception propagates out of the block}}. |
Tags:
ETH::2._Semester::PProg::05._Java_Threads::2._synchronized
Note 53: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID: WSSC!D36#|
modified
Before
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What is a pipeline (in CPU instruction execution)?
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What is a pipeline (in CPU instruction execution)?
A pipeline breaks instruction execution into multiple stages (e.g. fetch, decode, execute, write-back) that are overlapped: while stage k processes instruction n+1, stage k+1 processes instruction n. Multiple instructions are in-flight simultaneously — like a factory assembly line.
After
Front
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What is a pipeline in CPU instruction execution?
Back
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
What is a pipeline in CPU instruction execution?
A technique that splits instruction execution into independent stages (e.g. fetch, decode, execute, write-back).
Multiple instructions overlap in different stages simultaneously - like an assembly line.
This increases throughput (instructions per cycle) without reducing the latency of a single instruction.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
What is a pipeline (in CPU instruction execution)? |
What is a <b>pipeline</b> in CPU instruction execution? |
| Back |
A pipeline breaks instruction execution into multiple stages (e.g. fetch, decode, execute, write-back) that are overlapped: while stage k processes instruction n+1, stage k+1 processes instruction n. Multiple instructions are in-flight simultaneously — like a factory assembly line. |
A technique that splits instruction execution into <b>independent stages</b> (e.g. fetch, decode, execute, write-back). <br><br>Multiple instructions overlap in different stages simultaneously - like an assembly line. <br>This increases <b>throughput</b> (instructions per cycle) without reducing the <b>latency</b> of a single instruction. |
Tags:
ETH::2._Semester::PProg::06._Parallel_Architecture::3._Pipelining
Note 54: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: XKz4m$d8-k
modified
Before
Front
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Under Gustafson's Law, \(\lim_{P \to \infty} S_P = \infty\), because \(S_P = P - f(P-1)\) grows linearly with P (assuming f < 1).
Back
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Under Gustafson's Law, \(\lim_{P \to \infty} S_P = \infty\), because \(S_P = P - f(P-1)\) grows linearly with P (assuming f < 1).
This does not contradict Amdahl — Gustafson scales the problem size with P (fixed wall time), so the serial fraction f is a fixed fraction of the larger workload, not a fixed amount of work.
After
Front
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Under Gustafson's Law, \(\lim_{P \to \infty} S_P = \infty\), because \(S_P = P - f(P-1)\) grows linearly with \(P\) (assuming \(f < 1\)).
Back
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Under Gustafson's Law, \(\lim_{P \to \infty} S_P = \infty\), because \(S_P = P - f(P-1)\) grows linearly with \(P\) (assuming \(f < 1\)).
This does not contradict Amdahl - Gustafson scales the problem size with \(P\) (fixed wall time), so the serial fraction \(f\) is a fixed fraction of the larger workload, not a fixed amount of work.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Under Gustafson's Law, \(\lim_{P \to \infty} S_P = {{c1::\infty}}\), because {{c2::\(S_P = P - f(P-1)\) grows linearly with P (assuming f < 1)}}. |
Under Gustafson's Law, \(\lim_{P \to \infty} S_P = {{c1::\infty}}\), because {{c2::\(S_P = P - f(P-1)\) grows linearly with \(P\) (assuming \(f < 1\))}}. |
| Extra |
This does not contradict Amdahl — Gustafson scales the <b>problem size</b> with P (fixed wall time), so the serial fraction f is a fixed fraction of the larger workload, not a fixed amount of work. |
This does not contradict Amdahl - Gustafson scales the <b>problem size</b> with \(P\) (fixed wall time), so the serial fraction \(f\) is a fixed fraction of the larger workload, not a fixed amount of work. |
Tags:
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Note 55: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: zRL[#VyH!Q
modified
Before
Front
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Parallel execution time:
\(T_p=T_1/p\)
Back
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Parallel execution time:
\(T_p=T_1/p\)
(Equality, doesn't necessarily hold, usually we have \(>\) due to some performance loss.)
\(T_1\) denotes sequential execution time.
After
Front
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Parallel execution time:\[T_p=T_1/p\]
Back
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance
Parallel execution time:\[T_p=T_1/p\]
(Equality, doesn't necessarily hold, usually we have \(>\) due to some performance loss.)
\(T_1\) denotes sequential execution time.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Parallel execution time:<br><br>\(T_p={{c1::T_1/p}}\) |
Parallel execution time:\[T_p={{c1::T_1/p}}\] |
Tags:
ETH::2._Semester::PProg::07._Concepts::2._Parallel_performance