2-3 Tree: Runtime of: Search, Inserting, Deleting: \(O(\log n)\)
Note 1: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Bz)mOB:[n-
Before
Front
Back
2-3 Tree: Runtime of: Search, Inserting, Deleting: \(O(\log n)\)
This is because the tree is now forced to be balanced and \(h \leq \log_2 n\).
After
Front
2-3 Tree: The runtime of search, insertion and deletion is \(O(\log n)\).
Back
2-3 Tree: The runtime of search, insertion and deletion is \(O(\log n)\).
This is because the tree is now forced to be balanced and \(h \leq \log_2 n\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>2-3 Tree</b>: |
<b>2-3 Tree</b>: The runtime of search, insertion and deletion is{{c1:: \(O(\log n)\)}}. |
Note 2: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
F^&OZQURkx
Before
Front
The ADT queue can be efficiently implemented using a singly linked list with a pointer to the end:
- push: \(O(1)\) insert at the end, with pointer to the end
- pop: \(O(1)\) remove the first element like in a stack
Back
The ADT queue can be efficiently implemented using a singly linked list with a pointer to the end:
- push: \(O(1)\) insert at the end, with pointer to the end
- pop: \(O(1)\) remove the first element like in a stack
After
Front
The ADT queue can be efficiently implemented using a singly linked list with a pointer to the end:
- push: \(O(1)\) insert at the end, with pointer to the end
- pop: \(O(1)\) remove the first element like in a stack
Back
The ADT queue can be efficiently implemented using a singly linked list with a pointer to the end:
- push: \(O(1)\) insert at the end, with pointer to the end
- pop: \(O(1)\) remove the first element like in a stack
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The ADT <b>queue</b> can be efficiently implemented using a {{c1:: |
The ADT <b>queue</b> can be efficiently implemented using a {{c1::<b>singly linked list with a pointer to the end</b>}}:<br><ul><li><b>push</b>: {{c2:: \(O(1)\) insert at the end, with pointer to the end}}<br></li><li><b>pop</b>: {{c3:: \(O(1)\) remove the first element like in a stack}}</li></ul> |
Note 3: ETH::A&D
Deck: ETH::A&D
Note Type: Image Occlusion-73a2c
GUID:
modified
Note Type: Image Occlusion-73a2c
GUID:
GKG~Tp?e4l
Before
Front
Note that the key parameter of insertAfter and delete in lists refers to the actual node, not it's value.
Back
Note that the key parameter of insertAfter and delete in lists refers to the actual node, not it's value.
After
Front
Note that the key parameter of insertAfter and delete in lists refers to the actual node, not it's value.
Back
Note that the key parameter of insertAfter and delete in lists refers to the actual node, not it's value.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Occlusion | {{c1::image-occlusion:rect:left=.43 |
{{c1::image-occlusion:rect:left=.4368:top=.3055:width=.0903:height=.1154:oi=1}}<br>{{c12::image-occlusion:rect:left=.444:top=.6997:width=.0794:height=.0947:oi=1}}<br>{{c11::image-occlusion:rect:left=.4404:top=.5635:width=.0939:height=.1018:oi=1}}<br>{{c6::image-occlusion:rect:left=.7906:top=.4413:width=.083:height=.1086:oi=1}}<br>{{c8::image-occlusion:rect:left=.7834:top=.6972:width=.0975:height=.0972:oi=1}}<br>{{c10::image-occlusion:rect:left=.5848:top=.5703:width=.0866:height=.0976:oi=1}}<br>{{c4::image-occlusion:rect:left=.4368:top=.4481:width=.0903:height=.0951:oi=1}}<br>{{c9::image-occlusion:rect:left=.5921:top=.6993:width=.0758:height=.091:oi=1}}<br>{{c3::image-occlusion:rect:left=.7906:top=.3123:width=.0866:height=.1086:oi=1}}<br>{{c7::image-occlusion:rect:left=.7906:top=.5771:width=.0866:height=.0883:oi=1}}<br>{{c2::image-occlusion:rect:left=.5884:top=.3055:width=.083:height=.1018:oi=1}}<br>{{c5::image-occlusion:rect:left=.5921:top=.4413:width=.0794:height=.0951:oi=1}}<br> |
Note 4: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
H0^#YREe-o
Before
Front
A 2-3 Tree is an external search-tree.
Back
A 2-3 Tree is an external search-tree.
This means that the values are stored in the leaves only. The nodes are for "navigation".
After
Front
The 2-3 Trees we are covering in this course are external search-trees.
Back
The 2-3 Trees we are covering in this course are external search-trees.
This means that the values are stored in the leaves only. The nodes are for "navigation".
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The <b>2-3 Trees </b>we are covering in this course are {{c1::external}} search-trees. |
Note 5: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
H?Cs9sT6&{
Before
Front
2-3 Tree: Inserting Steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Insert the new key value as a separator
- Rebalance (if necessary, i.e. more than 3 keys)
- split node into two nodes (each gets 2 children and 1 seps)
- the middle sep is pushed to the parent level (and propagate)
Back
2-3 Tree: Inserting Steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Insert the new key value as a separator
- Rebalance (if necessary, i.e. more than 3 keys)
- split node into two nodes (each gets 2 children and 1 seps)
- the middle sep is pushed to the parent level (and propagate)
The rebalancing being recursively pushed to the parent limits the operations at the height \(h\) thus we get \(O(\log n)\).
After
Front
2-3 Tree: Insertion steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Insert the new key value as a separator
- Rebalance (if necessary, i.e. more than 3 keys)
- split node into two nodes (each gets 2 children and 1 seps)
- the middle sep is pushed to the parent level (and propagate)
Back
2-3 Tree: Insertion steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Insert the new key value as a separator
- Rebalance (if necessary, i.e. more than 3 keys)
- split node into two nodes (each gets 2 children and 1 seps)
- the middle sep is pushed to the parent level (and propagate)
The rebalancing being recursively pushed to the parent limits the operations at the height \(h\) thus we get \(O(\log n)\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>2-3 Tree</b>: Inserti |
<b>2-3 Tree</b>: Insertion steps:<br><ol><li>{{c1::Search for the correct node under which the key is inserted: \(O(\log_2 n)\)}}</li><li>{{c2::Insert the new key value as a <b>separator</b>}}</li><li>{{c3::<b>Rebalance</b> (if necessary, i.e. more than 3 keys)<br></li></ol><ul><li>split node into two nodes (each gets 2 children and 1 seps)</li><li>the middle sep is pushed to the parent level (and propagate)}}</li></ul> |
Note 6: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Jp{gN:I7yh
Before
Front
{{c1:: \(\sum_{i = 1}^{n} \log(i)\)}} \(=\) \(\log(n!)\) (Sum)
Back
{{c1:: \(\sum_{i = 1}^{n} \log(i)\)}} \(=\) \(\log(n!)\) (Sum)
After
Front
{{c1:: \(\sum_{i = 1}^{n} \log(i)\)::Sum}} \(=\) \(\log(n!)\)
Back
{{c1:: \(\sum_{i = 1}^{n} \log(i)\)::Sum}} \(=\) \(\log(n!)\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1:: \(\sum_{i = 1}^{n} \log(i)\)}} \(=\) {{c2::\(\log(n!)\) |
{{c1:: \(\sum_{i = 1}^{n} \log(i)\)::Sum}} \(=\) {{c2::\(\log(n!)\)}} |
Note 7: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
L4[cTT%fZ]
Before
Front
Give the outline of an induction proof:
Back
Give the outline of an induction proof:
We want to prove that ... for \(n \geq 5\)
Base Case: Let \(n = 5\) .... So the property holds for \(n = 5\).
Induction Hypothesis: We assume the property is true for some \(k \geq 5\)
Induction Step: We must show that the property holds for \(k + 1\).
By the principle of mathematical induction ... is true for all \(n \geq 5\).
Base Case: Let \(n = 5\) .... So the property holds for \(n = 5\).
Induction Hypothesis: We assume the property is true for some \(k \geq 5\)
Induction Step: We must show that the property holds for \(k + 1\).
By the principle of mathematical induction ... is true for all \(n \geq 5\).
After
Front
Provide the outline of an induction proof.
Back
Provide the outline of an induction proof.
We want to prove that ... for \(n \geq 5\)
Base Case: Let \(n = 5\) .... So the property holds for \(n = 5\).
Induction Hypothesis: We assume the property is true for some \(k \geq 5\)
Induction Step: We must show that the property holds for \(k + 1\).
By the principle of mathematical induction ... is true for all \(n \geq 5\).
Base Case: Let \(n = 5\) .... So the property holds for \(n = 5\).
Induction Hypothesis: We assume the property is true for some \(k \geq 5\)
Induction Step: We must show that the property holds for \(k + 1\).
By the principle of mathematical induction ... is true for all \(n \geq 5\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | Provide the outline of an induction proof. |
Note 8: ETH::A&D
Deck: ETH::A&D
Note Type: Algorithms
GUID:
modified
Note Type: Algorithms
GUID:
LqP`8lU$&o
Before
Front
Runtime of Insertion Sort?
Back
Runtime of Insertion Sort?
Best Case: \(O(n)\)
Worst Case: \(O(n^2)\)
This insertion is not constant time! We have to swap it with each previous element!
After
Front
Runtime of Insertion Sort?
Back
Runtime of Insertion Sort?
Best Case: \(O(n)\)
Worst Case: \(O(n^2)\)
This insertion is not in constant time! We have to swap with each previous element!
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Extra Info | <i>This insertion is not constant time! We have to swap |
<i>This insertion is not in constant time! We have to swap with each previous element!</i> |
Note 9: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
OY@2Ay+>4p
Before
Front
2-3 Tree: Deleting Steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Remove the leaf with the value and one separator
- Rebalance (if necessary, i.e. now 1 key)
Back
2-3 Tree: Deleting Steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Remove the leaf with the value and one separator
- Rebalance (if necessary, i.e. now 1 key)
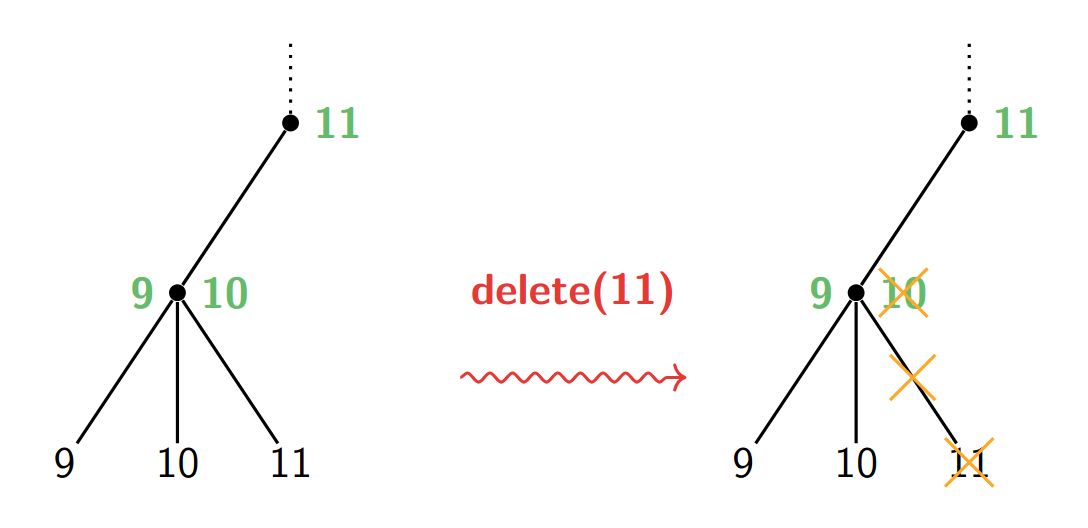
After
Front
2-3 Tree: Deletion steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Remove the leaf with the value and one separator
- Rebalance (if necessary, i.e. now 1 key)
Back
2-3 Tree: Deletion steps:
- Search for the correct node under which the key is inserted: \(O(\log_2 n)\)
- Remove the leaf with the value and one separator
- Rebalance (if necessary, i.e. now 1 key)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>2-3 Tree</b>: Deleti |
<b>2-3 Tree</b>: Deletion steps:<br><ol><li>{{c1::Search for the correct node under which the key is inserted: \(O(\log_2 n)\)}}</li><li>{{c2::Remove the leaf with the value and one separator}}</li><li>{{c3::<b>Rebalance</b> (if necessary, i.e. now 1 key)}}</li></ol> |
Note 10: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
Q}a3<1,J]C
Before
Front
2-3 Tree: Deleting Steps if neighbour has 2 keys:
Back
2-3 Tree: Deleting Steps if neighbour has 2 keys:
- the nodes \(u\) and \(v\) are merged to form one new node with 3 children.
- The separator from the parent node is pulled down to be the new \(s_2\).
If root has 1 child -> root replaced by child.
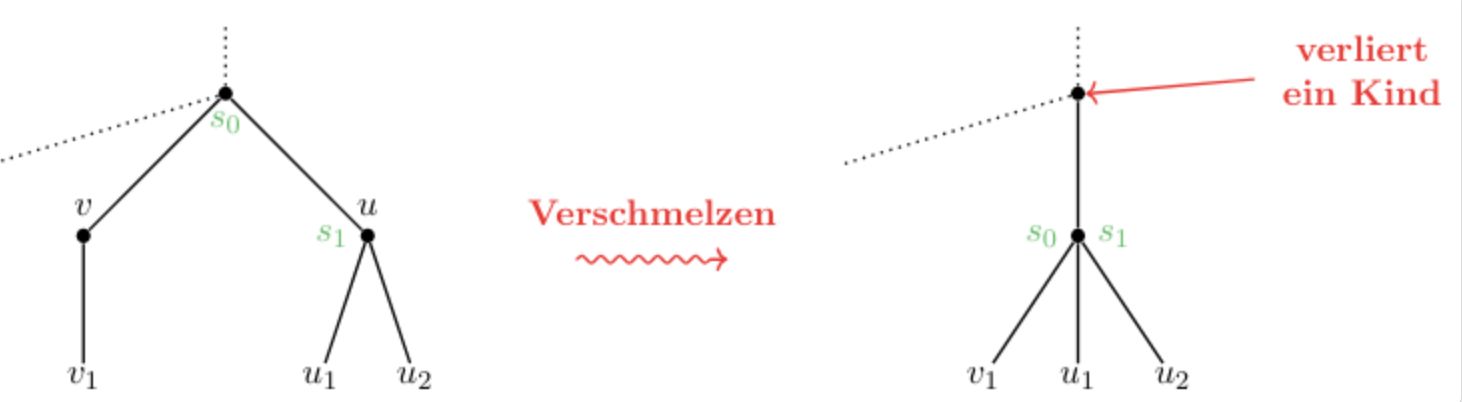
After
Front
2-3 Tree: We deleted a node and now it's sibling is an only child. What happens if it's neighbor has 2 keys?
Back
2-3 Tree: We deleted a node and now it's sibling is an only child. What happens if it's neighbor has 2 keys?
- The nodes \(u\) and \(v\) are merged to form one new node with 3 children.
- The separator from the parent node is pulled down to be the new \(s_2\).
If root has 1 child -> root replaced by child.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | 2-3 Tree: |
2-3 Tree: We deleted a node and now it's sibling is an only child. What happens if it's neighbor has 2 keys? |
| Back | <ol><li> |
<ol><li>The nodes \(u\) and \(v\) are <b>merged</b> to form one new node with <b>3 children</b>.</li><li>The separator from the parent node is pulled down to be the new \(s_2\).</li></ol>Parent may lose child -> rebalance there (can go up to the root).<br>If root has 1 child -> root replaced by child.<br><img src="paste-fcffee6f619138677fc86eb74beebfaa266c8cfe.jpg"> |
Note 11: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
m3`Qbb~x?c
Before
Front
2-3 Tree: Deleting Steps if neighbour has 3 keys:
Back
2-3 Tree: Deleting Steps if neighbour has 3 keys:
Our current node adopts one of the children. The separators have to be updated by “rotating them”. The parent sep moves with the adopted and the left sep becomes the new parent).
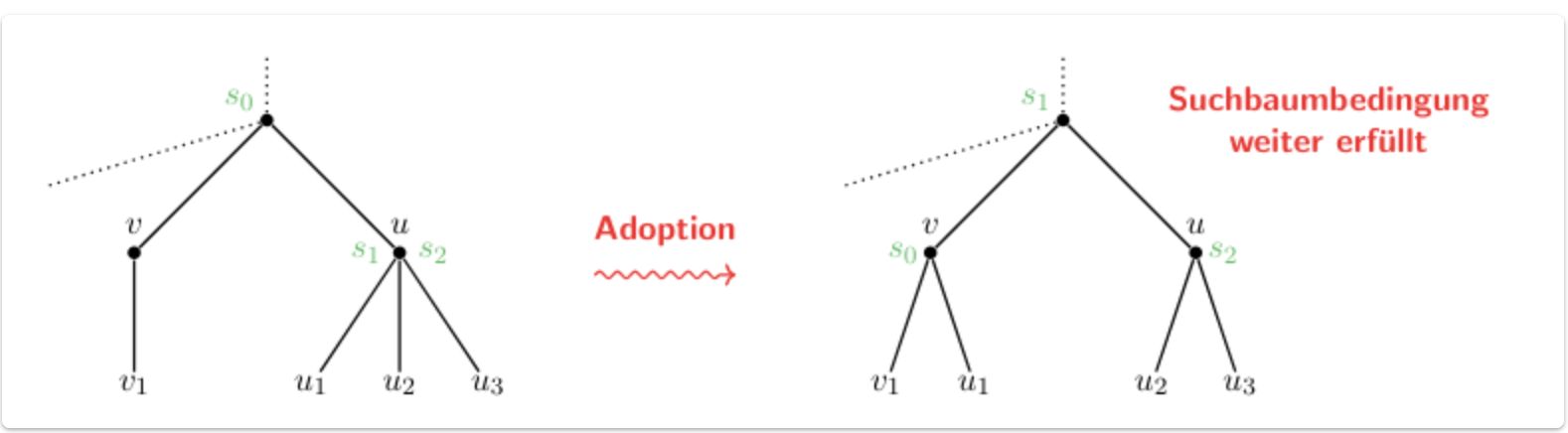
After
Front
2-3 Tree: We deleted a node and now it's sibling is an only child. What happens if it's neighbor has 3 keys?
Back
2-3 Tree: We deleted a node and now it's sibling is an only child. What happens if it's neighbor has 3 keys?
Our current node adopts one of the children. The separators have to be updated by “rotating them”. The parent sep moves with the adopted and the left sep becomes the new parent).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | <b>2-3 Tree</b>: |
<b>2-3 Tree</b>: We deleted a node and now it's sibling is an only child. What happens if it's neighbor has 3 keys? |
Note 12: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
nK{)v6I%zc
Before
Front
The ADT stack can be efficiently implemented using a singly linked list:
- push: \(\Theta(1)\)
- pop: \(\Theta(1)\) as this removes the first element. This means we just copy the pointer next from the first element to be the first pointer of the list.
Back
The ADT stack can be efficiently implemented using a singly linked list:
- push: \(\Theta(1)\)
- pop: \(\Theta(1)\) as this removes the first element. This means we just copy the pointer next from the first element to be the first pointer of the list.
After
Front
The ADT stack can be efficiently implemented using a singly linked list:
- push: \(\Theta(1)\)
- pop: \(\Theta(1)\) as this removes the first element. This means we just copy the pointer next from the first element to be the first pointer of the list.
Back
The ADT stack can be efficiently implemented using a singly linked list:
- push: \(\Theta(1)\)
- pop: \(\Theta(1)\) as this removes the first element. This means we just copy the pointer next from the first element to be the first pointer of the list.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The ADT <b>stack</b> can be efficiently implemented using a {{c1:: |
The ADT <b>stack</b> can be efficiently implemented using a {{c1::<b>singly linked list</b>}}:<br><ul><li><b>push</b>: {{c2:: \(\Theta(1)\)}}<br></li><li><b>pop</b>: {{c3:: \(\Theta(1)\) as this removes the first element. This means we just copy the pointer next from the first element to be the first pointer of the list.}}<br></li></ul> |
Note 13: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
rp1#iPsvnq
Before
Front
In a linked list, the keys don't appear in order in memory. They each contain a pointer to the start of the next element in the list instead.
We also have an extra pointer to the end in practice.
We also have an extra pointer to the end in practice.
Back
In a linked list, the keys don't appear in order in memory. They each contain a pointer to the start of the next element in the list instead.
We also have an extra pointer to the end in practice.
We also have an extra pointer to the end in practice.
The last pointer of the list is a null pointer to indicate the end.
After
Front
In a linked list, the keys don't appear in order in memory. They each contain a pointer to the next element in the list instead.
We also have an extra pointer to the end.
We also have an extra pointer to the end.
Back
In a linked list, the keys don't appear in order in memory. They each contain a pointer to the next element in the list instead.
We also have an extra pointer to the end.
We also have an extra pointer to the end.
The last pointer of the list is a null pointer to indicate the end.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | In a <b>linked list</b>, the keys {{c1::don't appear in order in memory}}. They each contain {{c2::a pointer to the |
In a <b>linked list</b>, the keys {{c1::don't appear in order in memory}}. They each contain {{c2::a pointer to the next element in the list instead}}.<br><br>We also have {{c3::an extra pointer to the end}}. |
Note 14: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
uHC]1fZd$=
Before
Front
Tree Condition: for 2-3 Trees implementing dictionary.
Back
Tree Condition: for 2-3 Trees implementing dictionary.
Each node has 2 or 3 children but that all leafs are on the same level
After
Front
What is the tree condition for 2-3 Trees implementing a dictionary?
Back
What is the tree condition for 2-3 Trees implementing a dictionary?
Each node has 2 or 3 children and all leaves are on the same level.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | <b> |
<b>What is the tree condition</b> for <b>2-3 Trees</b> implementing a dictionary? |
| Back | Each node has <b>2 or 3 children</b> |
Each node has <b>2 or 3 children</b> and all leaves are <b>on the same level.</b> |
Note 15: ETH::A&D
Deck: ETH::A&D
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
wbdb9#fK:J
Before
Front
Height of a 2-3 Tree for \(n\) keys is \(\leq \log_2(n)\) thus \(h=\)\(O(\log(n)\) (O-notation).
Back
Height of a 2-3 Tree for \(n\) keys is \(\leq \log_2(n)\) thus \(h=\)\(O(\log(n)\) (O-notation).
Note that for the case \(n = 1\) the root has one leaf with the key.
After
Front
The height of a 2-3 Tree for \(n\) keys is \(\leq \log_2(n)\) thus \(h={{c2::O(\log(n)::\textbf{O-notation} }}\).
Back
The height of a 2-3 Tree for \(n\) keys is \(\leq \log_2(n)\) thus \(h={{c2::O(\log(n)::\textbf{O-notation} }}\).
Note that for the case \(n = 1\) the root has one leaf with the key.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The height of a <b>2-3 Tree</b> for \(n\) keys is {{c1::\(\leq \log_2(n)\)}} thus \(h={{c2::O(\log(n)::\textbf{O-notation} }}\). |
Note 16: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Ey9Sz2Kp7Q
Before
Front
If \(F \vdash_K G\) in a calculus \(K\), one could extend the calculus by the new derivation \(\emptyset \vdash F \rightarrow G\).
Back
If \(F \vdash_K G\) in a calculus \(K\), one could extend the calculus by the new derivation \(\emptyset \vdash F \rightarrow G\).
After
Front
If \(F \vdash_K G\) in a calculus \(K\), one could extend the calculus by the new derivation \(F \rightarrow G\).
Back
If \(F \vdash_K G\) in a calculus \(K\), one could extend the calculus by the new derivation \(F \rightarrow G\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | If \(F \vdash_K G\) in a calculus \(K\), one could {{c1::<i>extend the calculus</i> by the new derivation \( |
If \(F \vdash_K G\) in a calculus \(K\), one could {{c1::<i>extend the calculus</i> by the new derivation \(F \rightarrow G\)}}. |
Note 17: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Fl3HSpM`6f
Before
Front
When proving \(H\) is a subgroup, we have to prove the closure of \(H\).
Back
When proving \(H\) is a subgroup, we have to prove the closure of \(H\).
After
Front
When proving \(H\) is a subgroup, we have to prove the closure of \(H\).
Back
When proving \(H\) is a subgroup, we have to prove the closure of \(H\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | When proving \(H\) is {{c2:: a subgroup}}, we have to prove the {{c1:: |
When proving \(H\) is {{c2:: a subgroup}}, we have to prove the {{c1::<b>closure</b> of \(H\)}}. |
Note 18: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
LM9=
Before
Front
DHKE selects two public values:
- a large prime \(p\)
- basis \(g\) which is then exponentiated
Back
DHKE selects two public values:
- a large prime \(p\)
- basis \(g\) which is then exponentiated
After
Front
The Diffie-Hellman Key-Agreement selects two public values:
- a large prime \(p\)
- basis \(g\) which is then exponentiated
Back
The Diffie-Hellman Key-Agreement selects two public values:
- a large prime \(p\)
- basis \(g\) which is then exponentiated
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The Diffie-Hellman Key-Agreement selects two public values:<br><ol><li>{{c1:: a large prime \(p\)}}</li><li>{{c2:: basis \(g\) which is then exponentiated}}</li></ol> |
Note 19: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
N9}Teh]+={
Before
Front
For \(H\) to be a subgroup, it must have {{c1::closure under inverses:
\(\widehat{a} \in H\) for all \(a \in H\)}}.
\(\widehat{a} \in H\) for all \(a \in H\)}}.
Back
For \(H\) to be a subgroup, it must have {{c1::closure under inverses:
\(\widehat{a} \in H\) for all \(a \in H\)}}.
\(\widehat{a} \in H\) for all \(a \in H\)}}.
After
Front
For \(H\) to be a subgroup, it must have closure under {{c1::inverses:
\(\widehat{a} \in H\) for all \(a \in H\)}}.
\(\widehat{a} \in H\) for all \(a \in H\)}}.
Back
For \(H\) to be a subgroup, it must have closure under {{c1::inverses:
\(\widehat{a} \in H\) for all \(a \in H\)}}.
\(\widehat{a} \in H\) for all \(a \in H\)}}.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | For \(H\) to be a subgroup, it must have |
For \(H\) to be a subgroup, it must have closure under {{c1::inverses: <br><br>\(\widehat{a} \in H\) for all \(a \in H\)}}. |
Note 20: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
O?~Mb}~!3:
Before
Front
Proof method: "Modus Ponens"
1. Find a suitable statement \(R\)
1. Find a suitable statement \(R\)
2. Prove \(R\)
3. Prove \(R \implies S\)
Back
Proof method: "Modus Ponens"
1. Find a suitable statement \(R\)
1. Find a suitable statement \(R\)
2. Prove \(R\)
3. Prove \(R \implies S\)
After
Front
Proof method: "Modus Ponens"
1. Find a suitable statement \(R\).
1. Find a suitable statement \(R\).
2. Prove \(R\).
3. Prove \(R \implies S\).
Back
Proof method: "Modus Ponens"
1. Find a suitable statement \(R\).
1. Find a suitable statement \(R\).
2. Prove \(R\).
3. Prove \(R \implies S\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Proof method: "Modus Ponens"<br><br>1. {{c1:: Find a suitable statement \(R\)}}<div>2. {{c2:: Prove \(R\)}}</div><div>3. {{c3:: Prove \(R \implies S\)}}</div> | Proof method: "Modus Ponens"<br><br>1. {{c1:: Find a suitable statement \(R\).}}<div>2. {{c2:: Prove \(R\).}}</div><div>3. {{c3:: Prove \(R \implies S\).}}</div> |
Note 21: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
bzpi*}NRv1
Before
Front
Does every homomorphism have to be injective? (Example)
Back
Does every homomorphism have to be injective? (Example)
No, homomorphisms do not need to be injective.
Example: We could map all elements of \(G\) to the neutral element \(e'\) in \(H\). This satisfies the homomorphism property: \[\psi(a * b) = e' = e' \star e' = \psi(a) \star \psi(b)\] but it clearly is not injective.
After
Front
Does every homomorphism have to be injective?
Back
Does every homomorphism have to be injective?
No, homomorphisms do not need to be injective.
Example: We could map all elements of \(G\) to the neutral element \(e'\) in \(H\). This satisfies the homomorphism property: \[\psi(a * b) = e' = e' \star e' = \psi(a) \star \psi(b)\] but it clearly is not injective.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | <p>Does every homomorphism have to be injective? |
<p>Does every homomorphism have to be injective?</p> |
Note 22: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
cV1b,==V*(
Before
Front
Give an example of an element with infinite order.
Back
Give an example of an element with infinite order.
In the group \(\langle \mathbb{Z}; + \rangle\), any integer \(a \neq 0\) has infinite order.
Explanation: The carrier \(\mathbb{Z}\) is infinite, and we never "loop around" to reach \(0\) by repeatedly adding a non-zero integer. For any \(n \geq 1\), we have \(na \neq 0\) if \(a \neq 0\).
After
Front
Provide an example of an element with infinite order.
Back
Provide an example of an element with infinite order.
In the group \(\langle \mathbb{Z}; + \rangle\), any integer \(a \neq 0\) has infinite order.
Explanation: The carrier \(\mathbb{Z}\) is infinite, and we never "loop around" to reach \(0\) by repeatedly adding a non-zero integer. For any \(n \geq 1\), we have \(na \neq 0\) if \(a \neq 0\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | <p> |
<p>Provide an example of an element with infinite order.</p> |
Note 23: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
hAzQO,E_+E
Before
Front
What is the order of elements in finite groups.
Back
What is the order of elements in finite groups.
Lemma 5.6: In a finite group \(G\), every element has a finite order.
(This doesn't hold for infinite groups - elements can have infinite order.)
After
Front
What property does the order of elements in finite groups have?
Back
What property does the order of elements in finite groups have?
Lemma 5.6: In a finite group \(G\), every element has a finite order.
(This doesn't hold for infinite groups - elements can have infinite order.)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | <p>What |
<p>What property does the order of elements in finite groups have?</p> |
Note 24: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
vD12#kM5/-
Before
Front
Number of Subgroups of \(\langle \mathbb{Z}_a \times \mathbb{Z}_b \rangle\)
Back
Number of Subgroups of \(\langle \mathbb{Z}_a \times \mathbb{Z}_b \rangle\)
\(\sum_{a|m \land b|n} \gcd(a, b)\)
After
Front
Number of subgroups of \(\langle \mathbb{Z}_m \times \mathbb{Z}_n \rangle\)
Back
Number of subgroups of \(\langle \mathbb{Z}_m \times \mathbb{Z}_n \rangle\)
\(\sum_{a \mid m \land b \mid n} \gcd(a, b)\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | Number of |
Number of subgroups of \(\langle \mathbb{Z}_m \times \mathbb{Z}_n \rangle\) |
| Back | \(\sum_{a |
\(\sum_{a \mid m \land b \mid n} \gcd(a, b)\) |
Note 25: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
vpgCC{U)O3
Before
Front
A cyclic group of order \(n\) {{c1::is isomorphic to \(\langle \mathbb{Z}_n,\oplus)\), and hence commutative::has which useful property?}}.
Back
A cyclic group of order \(n\) {{c1::is isomorphic to \(\langle \mathbb{Z}_n,\oplus)\), and hence commutative::has which useful property?}}.
After
Front
A cyclic group of order \(n\) {{c1::is isomorphic to \(\langle \mathbb{Z}_n,\oplus)\), and hence commutative.::has which useful property?}}
Back
A cyclic group of order \(n\) {{c1::is isomorphic to \(\langle \mathbb{Z}_n,\oplus)\), and hence commutative.::has which useful property?}}
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A cyclic group of order \(n\) {{c1::is isomorphic to \(\langle \mathbb{Z}_n,\oplus)\), and hence commutative::has which useful property?}} |
A cyclic group of order \(n\) {{c1::is isomorphic to \(\langle \mathbb{Z}_n,\oplus)\), and hence commutative.::has which useful property?}} |
Note 26: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
xDDC{82KOB
Before
Front
Proof method: Proof by Contradiction
1. Find a suitable statement \( T\)
1. Find a suitable statement \( T\)
2. Prove that \( T \) is false
3. Assume that \( S \) is false and prove that \( T \) is true (-> contradiction)
Back
Proof method: Proof by Contradiction
1. Find a suitable statement \( T\)
1. Find a suitable statement \( T\)
2. Prove that \( T \) is false
3. Assume that \( S \) is false and prove that \( T \) is true (-> contradiction)
After
Front
Proof method: Proof by Contradiction
1. Find a suitable statement \( T\).
1. Find a suitable statement \( T\).
2. Prove that \( T \) is false.
3. Assume that \( S \) is false and prove that \( T \) is true (-> contradiction).
Back
Proof method: Proof by Contradiction
1. Find a suitable statement \( T\).
1. Find a suitable statement \( T\).
2. Prove that \( T \) is false.
3. Assume that \( S \) is false and prove that \( T \) is true (-> contradiction).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Proof method: Proof by Contradiction<br><br>1. {{c1:: Find a suitable statement \( T\)}}<div>2. {{c2:: Prove that \( T \) is false}}</div><div>3. {{c3:: Assume that \( S \) is false and prove that \( T \) is true (-> contradiction)}}</div> | Proof method: Proof by Contradiction<br><br>1. {{c1:: Find a suitable statement \( T\).}}<div>2. {{c2:: Prove that \( T \) is false.}}</div><div>3. {{c3:: Assume that \( S \) is false and prove that \( T \) is true (-> contradiction).}}</div> |
Note 27: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
y)
Before
Front
Proof method: "Direct Proof of an Implication"
Back
Proof method: "Direct Proof of an Implication"
Direct proof of \( S \implies T \): assume S and prove T under that assumption
After
Front
Proof method: "Direct Proof of an Implication"
Back
Proof method: "Direct Proof of an Implication"
Assume \(S\) and prove \(T\) under that assumption.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Back | Assume \(S\) and prove \(T\) under that assumption. |
Note 28: ETH::LinAlg
Deck: ETH::LinAlg
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
eUCQYkiYf@
Before
Front
What is a property that always hold for linear transformations?
Back
What is a property that always hold for linear transformations?
for a linear transformation \(T(X)\): \(T(0) = 0\)
After
Front
What is a property that always hold for linear transformations?
Back
What is a property that always hold for linear transformations?
\(T(0) = 0\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Back | \(T(0) = 0\) |
Note 29: ETH::LinAlg
Deck: ETH::LinAlg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
w7_|F6Nt!U
Before
Front
The triangle inequality \(||v|| + ||w|| \geq ||v+w||\) holds exactly if \(\exists \lambda \) s.t. \(w = \lambda v\) (i.e. they are scalar multiples)
Back
The triangle inequality \(||v|| + ||w|| \geq ||v+w||\) holds exactly if \(\exists \lambda \) s.t. \(w = \lambda v\) (i.e. they are scalar multiples)
After
Front
The triangle inequality \(||v|| + ||w|| \geq ||v+w||\) holds exactly if \(w = \lambda v\) for some \(\lambda\geq0\) (i.e., they point in the same direction).
Back
The triangle inequality \(||v|| + ||w|| \geq ||v+w||\) holds exactly if \(w = \lambda v\) for some \(\lambda\geq0\) (i.e., they point in the same direction).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The triangle inequality \(||v|| + ||w|| \geq ||v+w||\) holds exactly if {{c1::\( |
The triangle inequality \(||v|| + ||w|| \geq ||v+w||\) holds exactly if {{c1::\(w = \lambda v\) for some \(\lambda\geq0\) (i.e., they point in the same direction)}}. |
Note 30: ETH::DiskMat
Deck: ETH::DiskMat
Note Type: Horvath Classic
GUID:
deleted
Note Type: Horvath Classic
GUID:
nGeB*S%`!e
Deleted Note
Front
What is really important for the prenex form due to the binding of quantifiers?
Back
What is really important for the prenex form due to the binding of quantifiers?
We need to wrap the entire expression in parentheses \(\forall \exists (...)\) otherwise, it's not prenex!
Current
Note has been deleted
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | ||
| Back |