Das Maximum Bipartite Matching Problem kann durch Anwendung von Ford-Fulkerson auf \(N_G\) in Zeit \(O(nm)\) gelöst werden.
Note 1: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
5olJMm:+Jn
Previous
Note did not exist
New Note
Front
Back
Das Maximum Bipartite Matching Problem kann durch Anwendung von Ford-Fulkerson auf \(N_G\) in Zeit \(O(nm)\) gelöst werden.
In \(N_G\) ist \(U = 1\), also liefert Ford-Fulkerson mit Laufzeit \(O(mnU)\) hier \(O(mn)\). Besser geht es mit Hopcroft-Karp in \(O((m + n)\sqrt{n})\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Das Maximum Bipartite Matching Problem kann durch {{c1::Anwendung von Ford-Fulkerson auf \(N_G\)}} in Zeit \(O({{c2::nm}})\) gelöst werden. | |
| Extra | In \(N_G\) ist \(U = 1\), also liefert Ford-Fulkerson mit Laufzeit \(O(mnU)\) hier \(O(mn)\). Besser geht es mit Hopcroft-Karp in \(O((m + n)\sqrt{n})\). |
Note 2: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
9qhFW_UE&x
Previous
Note did not exist
New Note
Front
Konstruktion \(G \mapsto N_G^{*}\) (kantendisjunkte Pfade). Sei \(G = (V, E)\) mit \(u, v \in V\). Definiere \(N_G^{*} = (V, A, c, u, v)\) mit:
- \(A := {{c1::\{(x, y), (y, x) \mid \{x, y\} \in E\} }}\) (jede ungerichtete Kante wird zu zwei gerichteten Kanten),
- \(c \equiv 1\),
- Quelle \(u\), Senke \(v\).
Back
Konstruktion \(G \mapsto N_G^{*}\) (kantendisjunkte Pfade). Sei \(G = (V, E)\) mit \(u, v \in V\). Definiere \(N_G^{*} = (V, A, c, u, v)\) mit:
- \(A := {{c1::\{(x, y), (y, x) \mid \{x, y\} \in E\} }}\) (jede ungerichtete Kante wird zu zwei gerichteten Kanten),
- \(c \equiv 1\),
- Quelle \(u\), Senke \(v\).
Achtung: Im Unterschied zum Matching-Netzwerk hat \(N_G^{*}\) jetzt entgegen gerichtete Kanten (für jede Originalkante eine in jede Richtung).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Konstruktion \(G \mapsto N_G^{*}\) (kantendisjunkte Pfade).</b> Sei \(G = (V, E)\) mit \(u, v \in V\). Definiere \(N_G^{*} = (V, A, c, u, v)\) mit:<ul><li>\(A := {{c1::\{(x, y), (y, x) \mid \{x, y\} \in E\} }}\) (jede ungerichtete Kante wird zu zwei gerichteten Kanten),</li><li>{{c2::\(c \equiv 1\)}},</li><li>Quelle \(u\), Senke \(v\).</li></ul> | |
| Extra | <b>Achtung:</b> Im Unterschied zum Matching-Netzwerk hat \(N_G^{*}\) jetzt <i>entgegen gerichtete Kanten</i> (für jede Originalkante eine in jede Richtung). |
Note 3: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
:EvvAz%/Gq
Before
Front
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt Färbung).
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Back
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt Färbung).
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Achtung: Die Färbung muss hier nicht zulässig im üblichen Sinn sein, also benachbarte Knoten dürfen dieselbe Farbe haben. Wichtig ist nur, dass entlang eines bunten Pfades keine Farbe doppelt vorkommt.
After
Front
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt Färbung).
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Back
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt Färbung).
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Ein Pfad heisst bunt, wenn alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben.
Achtung: Die Färbung muss hier nicht zulässig im üblichen Sinn sein, also benachbarte Knoten dürfen dieselbe Farbe haben. Wichtig ist nur, dass entlang eines bunten Pfades keine Farbe doppelt vorkommt.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt {{c1::Färbung}}).<br>Ein Pfad heisst |
Sei \(G = (V, E)\) ein Graph mit einer Abbildung \(\gamma : V \to [k]\) (genannt {{c1::Färbung}}).<br><br>Ein Pfad heisst bunt, wenn {{c2::alle seine Knoten paarweise verschiedene Farben \(\gamma(v)\) haben}}. |
Note 4: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
Ao9Fa-:N2(
Before
Front
Algorithmus \(\textsc{Bunt}(G, i)\)
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Back
Algorithmus \(\textsc{Bunt}(G, i)\)
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
BUNT(G, i):
for all v in V:
P_i(v) := empty set
for all x in N(v):
for all R in P_{i-1}(x) with γ(v) ∉ R:
P_i(v) := P_i(v) ∪ { R ∪ {γ(v)} }Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\).Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
After
Front
Algorithmus \(\text{Bunt}(G, i)\)
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Back
Algorithmus \(\text{Bunt}(G, i)\)
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
BUNT(G, i):
for all v in V:
P_i(v) := empty set
for all x in N(v):
for all R in P_{i-1}(x) with γ(v) ∉ R:
P_i(v) := P_i(v) ∪ { R ∪ {γ(v)} }Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\).Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Front | <b>Algorithmus \(\text |
<b>Algorithmus \(\text{Bunt}(G, i)\)</b><br>Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)? |
Note 5: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
BU;!Ls68$O
Previous
Note did not exist
New Note
Front
Schlüsselidentität Bildsegmentierung. Sei \((S, T)\) ein \(s\)-\(t\)-Schnitt im Segmentierungs-Netzwerk \(N\) und \(A := S \setminus \{s\}\), \(B := T \setminus \{t\}\). Dann gilt\[\operatorname{cap}(S, T) = {{c1::q'(A, B) = \sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}.\]Folgerung: Die optimale Partition \((A, B)\) lässt sich mit Hilfe von MaxFlow für den minimalen \(s\)-\(t\)-Schnitt in \(N\) berechnen.
Back
Schlüsselidentität Bildsegmentierung. Sei \((S, T)\) ein \(s\)-\(t\)-Schnitt im Segmentierungs-Netzwerk \(N\) und \(A := S \setminus \{s\}\), \(B := T \setminus \{t\}\). Dann gilt\[\operatorname{cap}(S, T) = {{c1::q'(A, B) = \sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}.\]Folgerung: Die optimale Partition \((A, B)\) lässt sich mit Hilfe von MaxFlow für den minimalen \(s\)-\(t\)-Schnitt in \(N\) berechnen.
Beitrag zum Schnitt:
- Kanten \((s, p)\) mit \(p \in B\): Beitrag \(\sum_{p \in B} \alpha_p\).
- Kanten \((p, t)\) mit \(p \in A\): Beitrag \(\sum_{p \in A} \beta_p\).
- Bildkanten \((p, p')\) mit \(p \in A, p' \in B\): Beitrag \(\sum_{\ldots} \gamma_{(p, p')}\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Schlüsselidentität Bildsegmentierung.</b> Sei \((S, T)\) ein \(s\)-\(t\)-Schnitt im Segmentierungs-Netzwerk \(N\) und \(A := S \setminus \{s\}\), \(B := T \setminus \{t\}\). Dann gilt\[\operatorname{cap}(S, T) = {{c1::q'(A, B) = \sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}.\]Folgerung: Die optimale Partition \((A, B)\) lässt sich mit Hilfe von {{c2::MaxFlow für den minimalen \(s\)-\(t\)-Schnitt}} in \(N\) berechnen. | |
| Extra | Beitrag zum Schnitt: <ul><li>Kanten \((s, p)\) mit \(p \in B\): Beitrag \(\sum_{p \in B} \alpha_p\).</li><li>Kanten \((p, t)\) mit \(p \in A\): Beitrag \(\sum_{p \in A} \beta_p\).</li><li>Bildkanten \((p, p')\) mit \(p \in A, p' \in B\): Beitrag \(\sum_{\ldots} \gamma_{(p, p')}\).</li></ul>Dieser Lösungsansatz wird in der Praxis verwendet, auch für höherdimensionale Bilder (Voxel), z.B. Computertomographie. |
Note 6: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
Ett.Ls>TFD
Previous
Note did not exist
New Note
Front
Fluss \(\to\) kantendisjunkte Pfade. Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):
- Beginnend bei \(u\), laufe entlang gerichteter, ungebrauchter Kanten mit Fluss 1 bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.
- Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\) Mal}}.
- Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach Entfernen von Kreisen).
Back
Fluss \(\to\) kantendisjunkte Pfade. Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):
- Beginnend bei \(u\), laufe entlang gerichteter, ungebrauchter Kanten mit Fluss 1 bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.
- Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\) Mal}}.
- Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach Entfernen von Kreisen).
Kreise können entstehen, wenn der Fluss interne Zyklen mit Fluss 1 enthält; diese sind für die Pfade irrelevant und werden weggelassen.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Fluss \(\to\) kantendisjunkte Pfade.</b> Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):<ol><li>Beginnend bei \(u\), laufe entlang gerichteter, {{c1::ungebrauchter Kanten mit Fluss 1}} bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.</li><li>Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\) Mal}}.</li><li>Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach {{c3::Entfernen von Kreisen}}).</li></ol> | |
| Extra | Kreise können entstehen, wenn der Fluss interne Zyklen mit Fluss 1 enthält; diese sind für die Pfade irrelevant und werden weggelassen. |
Note 7: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
JYDWO_<3y.
Previous
Note did not exist
New Note
Front
Sei \(f\) ein ganzzahliger maximaler Fluss in \(N_G^{*}\). Dann gilt:
- Flusswerte: {{c1::\(f(e) \in \{0, 1\}\)}} für alle Kanten \(e\).
- Für jeden Knoten \(w \notin \{u, v\}\): {{c2::\(\operatorname{indeg}_f(w) = \operatorname{outdeg}_f(w)\)}} (Flusserhaltung in inneren Knoten).
- \(\operatorname{val}(f) = {{c3::\operatorname{outdeg}_f(u) - \operatorname{indeg}_f(u) = \operatorname{indeg}_f(v) - \operatorname{outdeg}_f(v)}}\).
Back
Sei \(f\) ein ganzzahliger maximaler Fluss in \(N_G^{*}\). Dann gilt:
- Flusswerte: {{c1::\(f(e) \in \{0, 1\}\)}} für alle Kanten \(e\).
- Für jeden Knoten \(w \notin \{u, v\}\): {{c2::\(\operatorname{indeg}_f(w) = \operatorname{outdeg}_f(w)\)}} (Flusserhaltung in inneren Knoten).
- \(\operatorname{val}(f) = {{c3::\operatorname{outdeg}_f(u) - \operatorname{indeg}_f(u) = \operatorname{indeg}_f(v) - \operatorname{outdeg}_f(v)}}\).
\(\operatorname{indeg}_f(w)\) und \(\operatorname{outdeg}_f(w)\) bezeichnen die Ein- bzw. Ausgrade bezüglich der Kanten mit Fluss 1.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Sei \(f\) ein ganzzahliger maximaler Fluss in \(N_G^{*}\). Dann gilt:<ul><li>Flusswerte: {{c1::\(f(e) \in \{0, 1\}\)}} für alle Kanten \(e\).</li><li>Für jeden Knoten \(w \notin \{u, v\}\): {{c2::\(\operatorname{indeg}_f(w) = \operatorname{outdeg}_f(w)\)}} (Flusserhaltung in inneren Knoten).</li><li>\(\operatorname{val}(f) = {{c3::\operatorname{outdeg}_f(u) - \operatorname{indeg}_f(u) = \operatorname{indeg}_f(v) - \operatorname{outdeg}_f(v)}}\).</li></ul> | |
| Extra | \(\operatorname{indeg}_f(w)\) und \(\operatorname{outdeg}_f(w)\) bezeichnen die Ein- bzw. Ausgrade bezüglich der Kanten mit Fluss 1. |
Note 8: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
R8)5Btb:o[
Previous
Note did not exist
New Note
Front
Umformung der Bildsegmentierung. Mit \(S := \sum_{p \in P}(\alpha_p + \beta_p)\) gilt\[q(A, B) = S - \Big({{c1::\sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}\Big).\]Maximierung von \(q(A, B)\) ist also äquivalent zur Minimierung von\[q'(A, B) := \sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e.\]
Back
Umformung der Bildsegmentierung. Mit \(S := \sum_{p \in P}(\alpha_p + \beta_p)\) gilt\[q(A, B) = S - \Big({{c1::\sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}\Big).\]Maximierung von \(q(A, B)\) ist also äquivalent zur Minimierung von\[q'(A, B) := \sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e.\]
\(S\) ist eine Konstante, die nur von den Daten abhängt, nicht von der Partition.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Umformung der Bildsegmentierung.</b> Mit \(S := \sum_{p \in P}(\alpha_p + \beta_p)\) gilt\[q(A, B) = S - \Big({{c1::\sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}\Big).\]Maximierung von \(q(A, B)\) ist also äquivalent zur {{c2::Minimierung}} von\[q'(A, B) := \sum_{p \in A} \beta_p + \sum_{p \in B} \alpha_p + \sum_{e \in E,\, |e \cap A| = 1} \gamma_e.\] | |
| Extra | \(S\) ist eine Konstante, die nur von den Daten abhängt, nicht von der Partition. |
Note 9: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
R?={ZwzI%F
Before
Front
Monte-Carlo Algorithmus für Long-Path: Analyse
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.
(1) Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.
(1) Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Back
Monte-Carlo Algorithmus für Long-Path: Analyse
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.
(1) Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\textsc{Bunt}\) ausführen.
(1) Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
(2) Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
(3) Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Faktor \((2e)^k\) statt \(e^k\): einmalige bunte Färbung kostet \(O(2^k \cdot k \cdot m)\) (Mengen \(S \subseteq [k]\) im DP), und es werden \(\Theta(\varepsilon \cdot e^k)\) Versuche gemacht.
Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995).
Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995).
After
Front
Monte-Carlo Algorithmus für Long-Path: Analyse
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\text{Bunt}\) ausführen.
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\text{Bunt}\) ausführen.
- Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
- Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
- Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Back
Monte-Carlo Algorithmus für Long-Path: Analyse
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\text{Bunt}\) ausführen.
Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\text{Bunt}\) ausführen.
- Laufzeit: \(O\!\big(\varepsilon \cdot (2e)^k \cdot k \cdot m\big)\), wobei \(m = |E|\).
- Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: einseitiger Fehler).
- Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.
Faktor \((2e)^k\) statt \(e^k\): einmalige bunte Färbung kostet \(O(2^k \cdot k \cdot m)\) (Mengen \(S \subseteq [k]\) im DP), und es werden \(\Theta(\varepsilon \cdot e^k)\) Versuche gemacht.
Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995).
Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Monte-Carlo Algorithmus für Long-Path: Analyse</b><br>Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\text |
<b>Monte-Carlo Algorithmus für Long-Path: Analyse</b><br>Wiederhole \(\lceil \varepsilon \cdot e^k \rceil\) Mal: zufällig färben, dann \(\text{Bunt}\) ausführen.<br><ol><li>Laufzeit: \(O\!\big({{c1::\varepsilon \cdot (2e)^k \cdot k \cdot m}}\big)\), wobei \(m = |E|\).</li><li>Antwortet der Algorithmus mit JA, dann hat \(G\) einen Pfad der Länge \(k-1\) (kein false positive: {{c2::einseitiger Fehler}}).</li><li>Hat \(G\) einen Pfad der Länge \(k-1\), dann ist die Wahrscheinlichkeit, dass der Algorithmus mit NEIN antwortet, höchstens {{c3::\(e^{-\varepsilon}\)}}.</li></ol> |
| Extra | Faktor \((2e)^k\) statt \(e^k\): einmalige bunte Färbung kostet \(O(2^k \cdot k \cdot m)\) (Mengen \(S \subseteq [k]\) im DP), und es werden \(\Theta(\varepsilon \cdot e^k)\) Versuche gemacht.<br>Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995). | Faktor \((2e)^k\) statt \(e^k\): einmalige bunte Färbung kostet \(O(2^k \cdot k \cdot m)\) (Mengen \(S \subseteq [k]\) im DP), und es werden \(\Theta(\varepsilon \cdot e^k)\) Versuche gemacht.<br><br>Bemerkung: \((2e)^k\) ist konstant in \(n\). Damit wird Long-Path für festes \(k\) in Polynomialzeit lösbar (FPT-Resultat von Alon, Yuster, Zwick 1995). |
Note 10: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
U_elCD$&ev
Before
Front
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\]
\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\]
Back
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\]
\[P_i(v) := \Big\{ S \subseteq [k] \,:\, {{c1::|S| = i+1 \text{ und } \exists \text{ in } v \text{ endender, genau mit } S \text{ gefärbter bunter Pfad}}} \Big\}.\]
\(P_i(v)\) sammelt also alle möglichen Farbmengen, die ein bunter Pfad der Länge \(i\) ausschöpfen kann, wenn er bei \(v\) endet.
Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.
Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\).
Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.
Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\).
After
Front
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\).
Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \left\{ S \subseteq [k] \,:\, {{c1::\begin{gathered} |S| = i+1 \text{ und } \exists \text{ in } v \text{ endender,} \\ \text{genau mit } S \text{ gefärbter bunter Pfad} \end{gathered} }} \right\}.\]
Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \left\{ S \subseteq [k] \,:\, {{c1::\begin{gathered} |S| = i+1 \text{ und } \exists \text{ in } v \text{ endender,} \\ \text{genau mit } S \text{ gefärbter bunter Pfad} \end{gathered} }} \right\}.\]
Back
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\).
Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \left\{ S \subseteq [k] \,:\, {{c1::\begin{gathered} |S| = i+1 \text{ und } \exists \text{ in } v \text{ endender,} \\ \text{genau mit } S \text{ gefärbter bunter Pfad} \end{gathered} }} \right\}.\]
Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei
\[P_i(v) := \left\{ S \subseteq [k] \,:\, {{c1::\begin{gathered} |S| = i+1 \text{ und } \exists \text{ in } v \text{ endender,} \\ \text{genau mit } S \text{ gefärbter bunter Pfad} \end{gathered} }} \right\}.\]
\(P_i(v)\) sammelt also alle möglichen Farbmengen, die ein bunter Pfad der Länge \(i\) ausschöpfen kann, wenn er bei \(v\) endet.
Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.
Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\).
Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.
Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei<br>\[P_i(v) := \ |
Sei \(G = (V, E)\) mit Färbung \(\gamma : V \to [k]\). <br>Für \(v \in V\) und \(i \in \{0, \dots, k-1\}\) sei<br>\[P_i(v) := \left\{ S \subseteq [k] \,:\, {{c1::\begin{gathered} |S| = i+1 \text{ und } \exists \text{ in } v \text{ endender,} \\ \text{genau mit } S \text{ gefärbter bunter Pfad} \end{gathered} }} \right\}.\] |
| Extra | \(P_i(v)\) sammelt also alle möglichen <b>Farbmengen</b>, die ein bunter Pfad der Länge \(i\) ausschöpfen kann, wenn er bei \(v\) endet.<br>Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.<br>Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\). | \(P_i(v)\) sammelt also alle möglichen <b>Farbmengen</b>, die ein bunter Pfad der Länge \(i\) ausschöpfen kann, wenn er bei \(v\) endet.<br><br>Ziel des Algorithmus: Berechne \(P_i(v)\) für alle \(v \in V\) und alle \(i \in \{0, 1, \dots, k-1\}\) per dynamischer Programmierung.<br><br>Es existiert ein bunter Pfad der Länge \(k-1\) genau dann, wenn \(P_{k-1}(v) \neq \emptyset\) für ein \(v \in V\). |
Note 11: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
Vvjtjjj#?h
Previous
Note did not exist
New Note
Front
Qualitätsfunktion für eine Partition \((A, B)\) von \(P\):\[q(A, B) := {{c1::\sum_{p \in A} \alpha_p \;+\; \sum_{p \in B} \beta_p \;-\; \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}.\]Bildsegmentierung sucht eine Partition, die \(q(A, B)\) maximiert.
Back
Qualitätsfunktion für eine Partition \((A, B)\) von \(P\):\[q(A, B) := {{c1::\sum_{p \in A} \alpha_p \;+\; \sum_{p \in B} \beta_p \;-\; \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}.\]Bildsegmentierung sucht eine Partition, die \(q(A, B)\) maximiert.
Erste zwei Summen belohnen Pixel, die zur 'richtigen' Seite zugeordnet sind. Der Strafterm bestraft Nachbarschafts-Kanten, die zwischen den beiden Teilen verlaufen (d.h. Kanten mit genau einem Endpunkt in \(A\)).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Qualitätsfunktion für eine Partition \((A, B)\) von \(P\):</b>\[q(A, B) := {{c1::\sum_{p \in A} \alpha_p \;+\; \sum_{p \in B} \beta_p \;-\; \sum_{e \in E,\, |e \cap A| = 1} \gamma_e}}.\]Bildsegmentierung sucht eine Partition, die {{c2::\(q(A, B)\) maximiert}}. | |
| Extra | Erste zwei Summen belohnen Pixel, die zur 'richtigen' Seite zugeordnet sind. Der Strafterm bestraft Nachbarschafts-Kanten, die zwischen den beiden Teilen verlaufen (d.h. Kanten mit genau einem Endpunkt in \(A\)). |
Note 12: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
XE[{x!N{Fm
Before
Front
Satz (Zufallsfärbungen)
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq e^{-k}\).
(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq e^{k}\).
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq e^{-k}\).
(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq e^{k}\).
Back
Satz (Zufallsfärbungen)
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq e^{-k}\).
(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq e^{k}\).
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
(1) Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq e^{-k}\).
(2) Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq e^{k}\).
Beweis von (1): \(\Pr[P \text{ wird bunt}] = \tfrac{k!}{k^k} \geq e^{-k}\) per Stirling.
Beweis von (2): geometrisch verteilte Wartezeit mit Erfolgswahrscheinlichkeit \(p\), Erwartungswert \(1/p\).
Beweis von (2): geometrisch verteilte Wartezeit mit Erfolgswahrscheinlichkeit \(p\), Erwartungswert \(1/p\).
After
Front
Satz (Zufallsfärbungen)
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
- Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq {{c1::e^{-k} }}\).
- Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq {{c2::e^{k} }}\).
Back
Satz (Zufallsfärbungen)
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).
- Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq {{c1::e^{-k} }}\).
- Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq {{c2::e^{k} }}\).
Beweis von (1): \(\Pr[P \text{ wird bunt}] = \tfrac{k!}{k^k} \geq e^{-k}\) per Stirling.
Beweis von (2): geometrisch verteilte Wartezeit mit Erfolgswahrscheinlichkeit \(p\), Erwartungswert \(1/p\).
Beweis von (2): geometrisch verteilte Wartezeit mit Erfolgswahrscheinlichkeit \(p\), Erwartungswert \(1/p\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Satz (Zufallsfärbungen)</b><br>Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).<br> |
<b>Satz (Zufallsfärbungen)</b><br>Sei \(G\) ein Graph mit einem Pfad \(P\) der Länge \(k-1\).<br><ol><li>Eine zufällige Färbung mit \(k\) Farben erzeugt einen bunten Pfad der Länge \(k-1\) mit Wahrscheinlichkeit \(p \geq {{c1::e^{-k} }}\).</li><li>Bei wiederholten Färbungen mit \(k\) Farben ist der Erwartungswert der Anzahl der Versuche, bis man einen bunten Pfad der Länge \(k-1\) erhält, \(\tfrac{1}{p} \leq {{c2::e^{k} }}\).</li></ol> |
Note 13: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
Xw^:rS7Fv+
Previous
Note did not exist
New Note
Front
Konstruktion \(G \mapsto N_G\) (bipartites Matching). Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:
- \(s \neq t\) sind zwei neue Knoten (Quelle und Senke).
- \(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)
- \(c \equiv 1\) (alle Kapazitäten gleich 1).
Back
Konstruktion \(G \mapsto N_G\) (bipartites Matching). Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:
- \(s \neq t\) sind zwei neue Knoten (Quelle und Senke).
- \(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)
- \(c \equiv 1\) (alle Kapazitäten gleich 1).
Idee: Die mittleren Kanten zeigen von \(U\) nach \(W\), also nur in eine Richtung; die Einheitskapazitäten erzwingen, dass jeder Knoten höchstens eine Match-Kante bekommt.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Konstruktion \(G \mapsto N_G\) (bipartites Matching).</b> Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:<ul><li>{{c1::\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).}}</li><li>\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)</li><li>{{c3::\(c \equiv 1\)}} (alle Kapazitäten gleich 1).</li></ul> | |
| Extra | <b>Idee:</b> Die mittleren Kanten zeigen <i>von \(U\) nach \(W\)</i>, also nur in eine Richtung; die Einheitskapazitäten erzwingen, dass jeder Knoten höchstens eine Match-Kante bekommt. |
Note 14: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
[(Ow>HP}-W
Previous
Note did not exist
New Note
Front
Ein bipartiter Graph ist ein Graph \(G = (U \uplus W, E)\), bei dem die Knotenmenge in zwei disjunkte Mengen \(U\) und \(W\) partitioniert ist und die Kanten nur zwischen den beiden Mengen verlaufen, d.h.\[\forall e \in E : |e \cap U| = |e \cap W| = 1.\]
Back
Ein bipartiter Graph ist ein Graph \(G = (U \uplus W, E)\), bei dem die Knotenmenge in zwei disjunkte Mengen \(U\) und \(W\) partitioniert ist und die Kanten nur zwischen den beiden Mengen verlaufen, d.h.\[\forall e \in E : |e \cap U| = |e \cap W| = 1.\]
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Ein <b>bipartiter Graph</b> ist ein Graph \(G = (U \uplus W, E)\), bei dem {{c1::die Knotenmenge in zwei disjunkte Mengen \(U\) und \(W\) partitioniert ist}} und {{c2::die Kanten nur zwischen den beiden Mengen verlaufen}}, d.h.\[\forall e \in E : |e \cap U| = |e \cap W| = 1.\] |
Note 15: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
[u#wQ+Y.*n
Before
Front
Floyd's Cycle Finding (Aufgabenstellung)
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
- Laufzeit \(O(n)\)
- Das Array \(a\) darf nicht verändert werden (Zugriffe \(a[i]\) sind beliebig oft erlaubt)
- Nur \(O(1)\) zusätzliche Speicherzellen
Back
Floyd's Cycle Finding (Aufgabenstellung)
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
- Laufzeit \(O(n)\)
- Das Array \(a\) darf nicht verändert werden (Zugriffe \(a[i]\) sind beliebig oft erlaubt)
- Nur \(O(1)\) zusätzliche Speicherzellen
Ein Duplikat existiert sicher, denn \(a\) hat \(n\) Einträge mit Werten aus einer Menge der Grösse \(n-1\) (Schubfachprinzip).
Diese Variante hat keine direkte praktische Bedeutung, zeigt aber, was mit guter algorithmischer Herangehensweise möglich ist.
Diese Variante hat keine direkte praktische Bedeutung, zeigt aber, was mit guter algorithmischer Herangehensweise möglich ist.
After
Front
Floyd's Cycle Finding (Aufgabenstellung)
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
- Laufzeit \(O(n)\)
- Das Array \(a\) darf nicht verändert werden (Zugriffe \(a[i]\) sind beliebig oft erlaubt)
- Nur \(O(1)\) zusätzliche Speicherzellen
Back
Floyd's Cycle Finding (Aufgabenstellung)
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:
- Laufzeit \(O(n)\)
- Das Array \(a\) darf nicht verändert werden (Zugriffe \(a[i]\) sind beliebig oft erlaubt)
- Nur \(O(1)\) zusätzliche Speicherzellen
Ein Duplikat existiert sicher, denn \(a\) hat \(n\) Einträge mit Werten aus einer Menge der Grösse \(n-1\) (Schubfachprinzip).
Diese Variante hat keine direkte praktische Bedeutung, zeigt aber, was mit guter algorithmischer Herangehensweise möglich ist.
Diese Variante hat keine direkte praktische Bedeutung, zeigt aber, was mit guter algorithmischer Herangehensweise möglich ist.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Floyd's Cycle Finding (Aufgabenstellung)</b><br>Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:<ul><li>Laufzeit {{c1:: |
<b>Floyd's Cycle Finding (Aufgabenstellung)</b><br>Gegeben ein Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\). Finde zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\), unter folgenden Einschränkungen:<ul><li>Laufzeit \(O({{c1::n}})\)</li><li>{{c2::Das Array \(a\) darf nicht verändert werden (Zugriffe \(a[i]\) sind beliebig oft erlaubt)}}</li><li>Nur \(O({{c3::1}})\) zusätzliche Speicherzellen</li></ul> |
Note 16: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
bwfv>Ig~IE
Previous
Note did not exist
New Note
Front
Korrespondenz Matching \(\leftrightarrow\) Fluss in \(N_G\). Für einen bipartiten Graphen \(G\) gilt:
- Jedem Matching \(M\) in \(G\) entspricht ein ganzzahliger Fluss \(f_M\) in \(N_G\) mit {{c1::\(\operatorname{val}(f_M) = |M|\)}}.
- Jedem ganzzahligen Fluss \(f\) in \(N_G\) entspricht ein Matching \(M\) in \(G\) mit {{c1::\(|M| = \operatorname{val}(f)\)}}.
Back
Korrespondenz Matching \(\leftrightarrow\) Fluss in \(N_G\). Für einen bipartiten Graphen \(G\) gilt:
- Jedem Matching \(M\) in \(G\) entspricht ein ganzzahliger Fluss \(f_M\) in \(N_G\) mit {{c1::\(\operatorname{val}(f_M) = |M|\)}}.
- Jedem ganzzahligen Fluss \(f\) in \(N_G\) entspricht ein Matching \(M\) in \(G\) mit {{c1::\(|M| = \operatorname{val}(f)\)}}.
Die letzte Gleichheit nutzt Ford-Fulkerson (ganzzahlig): bei ganzzahligen Kapazitäten existiert immer ein ganzzahliger Maxflow.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Korrespondenz Matching \(\leftrightarrow\) Fluss in \(N_G\).</b> Für einen bipartiten Graphen \(G\) gilt:<ul><li>Jedem Matching \(M\) in \(G\) entspricht ein ganzzahliger Fluss \(f_M\) in \(N_G\) mit {{c1::\(\operatorname{val}(f_M) = |M|\)}}.</li><li>Jedem ganzzahligen Fluss \(f\) in \(N_G\) entspricht ein Matching \(M\) in \(G\) mit {{c1::\(|M| = \operatorname{val}(f)\)}}.</li></ul>Damit folgt:\[\max_{M \text{ Matching in } G}|M| \;=\; {{c2::\max_{f \text{ ganzz. Fluss in } N_G}\operatorname{val}(f) \;=\; \max_{f \text{ Fluss in } N_G}\operatorname{val}(f)}}.\] | |
| Extra | Die letzte Gleichheit nutzt Ford-Fulkerson (ganzzahlig): bei ganzzahligen Kapazitäten existiert immer ein ganzzahliger Maxflow. |
Note 17: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
g0V)&ygKw?
Before
Front
Kollision
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Back
Kollision
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Echte Duplikate (\(s_i = s_j\)) erzeugen automatisch übereinstimmende Hashes; das ist erwünscht. Kollisionen sind die zusätzlichen, unerwünschten Übereinstimmungen, die durch die Komprimierung \(|U| \to [m]\) entstehen.
After
Front
Kollision
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Back
Kollision
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Eine Kollision ist ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\).
Anschaulich: Kollisionen sind die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind.
Echte Duplikate (\(s_i = s_j\)) erzeugen automatisch übereinstimmende Hashes; das ist erwünscht. Kollisionen sind die zusätzlichen, unerwünschten Übereinstimmungen, die durch die Komprimierung \(|U| \to [m]\) entstehen.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Kollision</b><br>Eine <b>Kollision</b> ist {{c1::ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\)}}.<br>Anschaulich: Kollisionen sind {{c2::die neuen (unerwünschten) Duplikate in der Hashmap |
<b>Kollision</b><br><br>Eine <b>Kollision</b> ist {{c1::ein Paar \((i, j)\) mit \(1 \leq i < j \leq n\), \(s_i \neq s_j\) und \(h(s_i) = h(s_j)\)}}.<br><br>Anschaulich: Kollisionen sind {{c2::die neuen (unerwünschten) Duplikate in der Hashmap, also Hashmap-Duplikate, die im Original keine sind}}. |
Note 18: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
hN,uV~s)@n
Before
Front
Erwartete Anzahl Kollisionen
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m}}}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m}}}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Back
Erwartete Anzahl Kollisionen
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m}}}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m}}}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Beweisidee: Für jedes feste Paar \((i, j)\) mit \(s_i \neq s_j\) gilt \(\Pr[h(s_i) = h(s_j)] = \tfrac{1}{m}\) (wegen Unabhängigkeit / Zufallsfunktion). Es gibt höchstens \(\binom{n}{2}\) solche Paare, und Linearität des Erwartungswerts liefert die Schranke.
After
Front
Erwartete Anzahl Kollisionen
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m} }}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m} }}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Back
Erwartete Anzahl Kollisionen
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m} }}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m} }}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] < 1\).
Beweisidee: Für jedes feste Paar \((i, j)\) mit \(s_i \neq s_j\) gilt \(\Pr[h(s_i) = h(s_j)] = \tfrac{1}{m}\) (wegen Unabhängigkeit / Zufallsfunktion). Es gibt höchstens \(\binom{n}{2}\) solche Paare, und Linearität des Erwartungswerts liefert die Schranke.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Erwartete Anzahl Kollisionen</b><br>Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m}}}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] {{c2::< 1}}\). | <b>Erwartete Anzahl Kollisionen</b><br>Für eine Hashfunktion \(h : U \to [m]\) mit \(\Pr[h(u) = i] = \tfrac{1}{m}\) gilt:\[\mathbb{E}[\#\text{Kollisionen}] \leq {{c1::\binom{n}{2} \cdot \tfrac{1}{m} }}.\]Insbesondere folgt mit der Wahl \(m = n^2\): \(\mathbb{E}[\#\text{Kollisionen}] {{c2::< 1}}\). |
Note 19: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
lp-/}/,C:}
Previous
Note did not exist
New Note
Front
Maximum Bipartite Matching. Für das Problem, in einem bipartiten Graphen ein kardinalitätsmaximales Matching zu finden, gilt:
- Greedy funktioniert nicht (liefert nur ein inklusionsmaximales Matching).
- Lösungsansatz: Reduktion auf Maxflow.
Back
Maximum Bipartite Matching. Für das Problem, in einem bipartiten Graphen ein kardinalitätsmaximales Matching zu finden, gilt:
- Greedy funktioniert nicht (liefert nur ein inklusionsmaximales Matching).
- Lösungsansatz: Reduktion auf Maxflow.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Maximum Bipartite Matching.</b> Für das Problem, in einem bipartiten Graphen ein kardinalitätsmaximales Matching zu finden, gilt:<ul><li>{{c1::Greedy funktioniert nicht}} (liefert nur ein inklusionsmaximales Matching).</li><li>Lösungsansatz: {{c2::Reduktion auf Maxflow}}.</li></ul> |
Note 20: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
o;8w9oS4V{
Previous
Note did not exist
New Note
Front
Bildsegmentierung. Gegeben ein Bild (aus Pixeln mit Farbwerten), trenne Vordergrund von Hintergrund. Formal: ein Bild ist eine Menge \(P\) von Pixeln mit Farben \(\chi : P \to \text{Farben}\) und einer Nachbarschaftsrelation \(E\), die sagt, welche Pixel nebeneinander liegen.
Back
Bildsegmentierung. Gegeben ein Bild (aus Pixeln mit Farbwerten), trenne Vordergrund von Hintergrund. Formal: ein Bild ist eine Menge \(P\) von Pixeln mit Farben \(\chi : P \to \text{Farben}\) und einer Nachbarschaftsrelation \(E\), die sagt, welche Pixel nebeneinander liegen.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Bildsegmentierung.</b> Gegeben ein Bild (aus Pixeln mit Farbwerten), {{c1::trenne Vordergrund von Hintergrund}}. Formal: ein Bild ist eine Menge \(P\) von Pixeln mit Farben \(\chi : P \to \text{Farben}\) und einer {{c2::Nachbarschaftsrelation \(E\)}}, die sagt, welche Pixel nebeneinander liegen. |
Note 21: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
o~85^tBatc
Before
Front
Eine Zufallsquelle liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:
- Physikalische Zufallsgeneratoren: Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente.
- Deterministische (Pseudo-)Zufallsgeneratoren: liefern, basierend auf einem Startwert (seed) \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht Reproduzierbarkeit, wenn man sich den Startwert merkt.
Back
Eine Zufallsquelle liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:
- Physikalische Zufallsgeneratoren: Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente.
- Deterministische (Pseudo-)Zufallsgeneratoren: liefern, basierend auf einem Startwert (seed) \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht Reproduzierbarkeit, wenn man sich den Startwert merkt.
In der Analyse geht man von idealen Zufallsgeneratoren aus. Bei der Anwendung muss man aber berücksichtigen, dass Pseudo-Zufallsgeneratoren das nur näherungsweise leisten.
After
Front
Eine Zufallsquelle liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:
- Physikalische Zufallsgeneratoren: Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente.
- Deterministische (Pseudo-)Zufallsgeneratoren: liefern, basierend auf einem Startwert (seed) \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht Reproduzierbarkeit, wenn man sich den .
Back
Eine Zufallsquelle liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:
- Physikalische Zufallsgeneratoren: Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente.
- Deterministische (Pseudo-)Zufallsgeneratoren: liefern, basierend auf einem Startwert (seed) \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht Reproduzierbarkeit, wenn man sich den .
In der Analyse geht man von idealen Zufallsgeneratoren aus. Bei der Anwendung muss man aber berücksichtigen, dass Pseudo-Zufallsgeneratoren das nur näherungsweise leisten.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Eine <b>Zufallsquelle</b> liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:<ul><li><b>Physikalische Zufallsgeneratoren</b>: {{c1::Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente::Beispiele?}}.</li><li><b>Deterministische (Pseudo-)Zufallsgeneratoren</b>: liefern, basierend auf einem {{c2::Startwert (seed)}} \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht {{c3::Reproduzierbarkeit, wenn man sich den Startwert merkt}}.</li></ul> | Eine <b>Zufallsquelle</b> liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:<ul><li><b>Physikalische Zufallsgeneratoren</b>: {{c1::Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente::Beispiele?}}.</li><li><b>Deterministische (Pseudo-)Zufallsgeneratoren</b>: liefern, basierend auf einem {{c2::Startwert (seed)}} \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht {{c3::Reproduzierbarkeit, wenn man sich den {{c2::Startwert}} merkt}}.</li></ul> |
Note 22: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
t6+;HK:U,l
Before
Front
Rekursionsformel für \(P_i(v)\)
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\]
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\]
Back
Rekursionsformel für \(P_i(v)\)
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\]
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\]
Idee: Ein bunter Pfad der Länge \(i\), der in \(v\) endet, entsteht aus einem bunten Pfad der Länge \(i-1\), der in einem Nachbarn \(x\) von \(v\) endet, dessen Farbmenge \(\gamma(v)\) noch nicht enthält.
After
Front
Rekursionsformel für \(P_i(v)\)
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \} }}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\} }}.\]
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \} }}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\} }}.\]
Back
Rekursionsformel für \(P_i(v)\)
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \} }}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\} }}.\]
Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \} }}\).
Für \(i \geq 1\):
\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\} }}.\]
Idee: Ein bunter Pfad der Länge \(i\), der in \(v\) endet, entsteht aus einem bunten Pfad der Länge \(i-1\), der in einem Nachbarn \(x\) von \(v\) endet, dessen Farbmenge \(\gamma(v)\) noch nicht enthält.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Rekursionsformel für \(P_i(v)\)</b><br>Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \}}}\).<br>Für \(i \geq 1\):<br>\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\}}}.\] | <b>Rekursionsformel für \(P_i(v)\)</b><br>Basisfall: \(P_0(v) = {{c1::\{ \{\gamma(v)\} \} }}\).<br>Für \(i \geq 1\):<br>\[P_i(v) = {{c2::\bigcup_{x \in N(v)} \big\{ R \cup \{\gamma(v)\} \,:\, R \in P_{i-1}(x) \text{ und } \gamma(v) \notin R \big\} }}.\] |
Note 23: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
unEExu6hiJ
Before
Front
Floyd's Cycle Finding (Resultat)
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
- Laufzeit \(O(n)\)
- Zusätzlicher Speicher: nur vier Variablen (igel, hase, i, j)
Back
Floyd's Cycle Finding (Resultat)
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
- Laufzeit \(O(n)\)
- Zusätzlicher Speicher: nur vier Variablen (igel, hase, i, j)
Bemerkenswert: Die offensichtliche Hashmap-Lösung benötigt \(\Theta(n \log n)\) Zusatzspeicher; Floyd's Algorithmus kommt mit \(O(1)\) Zusatzspeicher aus, ohne die Laufzeitschranke zu opfern.
Der Algorithmus ist deterministisch und (anders als Hashmap/Bloomfilter) nicht randomisiert: er steht hier als Kontrast und Highlight, nicht als randomisierter Algorithmus.
Der Algorithmus ist deterministisch und (anders als Hashmap/Bloomfilter) nicht randomisiert: er steht hier als Kontrast und Highlight, nicht als randomisierter Algorithmus.
After
Front
Floyd's Cycle Finding (Resultat)
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
- Laufzeit \(O(n)\)
- Zusätzlicher Speicher: nur vier Variablen (igel, hase, i, j)
Back
Floyd's Cycle Finding (Resultat)
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:
- Laufzeit \(O(n)\)
- Zusätzlicher Speicher: nur vier Variablen (igel, hase, i, j)
Bemerkenswert: Die offensichtliche Hashmap-Lösung benötigt \(\Theta(n \log n)\) Zusatzspeicher; Floyd's Algorithmus kommt mit \(O(1)\) Zusatzspeicher aus, ohne die Laufzeitschranke zu opfern.
Der Algorithmus ist deterministisch und (anders als Hashmap/Bloomfilter) nicht randomisiert.
Der Algorithmus ist deterministisch und (anders als Hashmap/Bloomfilter) nicht randomisiert.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Floyd's Cycle Finding (Resultat)</b><br>Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:<ul><li>Laufzeit {{c1:: |
<b>Floyd's Cycle Finding (Resultat)</b><br>Auf einem Array \(a[1, \ldots, n]\) mit \(a[i] \in \{1, \ldots, n-1\}\) findet der Hase-und-Igel-Algorithmus zwei Indizes \(i \neq j\) mit \(a[i] = a[j]\) in:<ul><li>Laufzeit \(O({{c1::n}})\)</li><li>Zusätzlicher Speicher: {{c2::nur vier Variablen (igel, hase, i, j)}}</li></ul>Das Array \(a\) wird dabei {{c3::nicht verändert}}. |
| Extra | Bemerkenswert: Die offensichtliche Hashmap-Lösung benötigt \(\Theta(n \log n)\) Zusatzspeicher; Floyd's Algorithmus kommt mit \(O(1)\) Zusatzspeicher aus, ohne die Laufzeitschranke zu opfern.<br><br>Der Algorithmus ist deterministisch und (anders als Hashmap/Bloomfilter) <b>nicht</b> randomisiert |
Bemerkenswert: Die offensichtliche Hashmap-Lösung benötigt \(\Theta(n \log n)\) Zusatzspeicher; Floyd's Algorithmus kommt mit \(O(1)\) Zusatzspeicher aus, ohne die Laufzeitschranke zu opfern.<br><br>Der Algorithmus ist deterministisch und (anders als Hashmap/Bloomfilter) <b>nicht</b> randomisiert. |
Note 24: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
xR}HnW(yI&
Previous
Note did not exist
New Note
Front
Modellierung Bildsegmentierung. Aus den Farben werden drei Einschätzungen extrahiert:
- \(\alpha : P \to \mathbb{R}_0^{+}\): \(\alpha_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Vordergrund.
- \(\beta : P \to \mathbb{R}_0^{+}\): \(\beta_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Hintergrund.
- \(\gamma : E \to \mathbb{R}_0^{+}\): \(\gamma_e\) grösser \(\Rightarrow\) benachbarte Pixel eher im gleichen Teil.
Back
Modellierung Bildsegmentierung. Aus den Farben werden drei Einschätzungen extrahiert:
- \(\alpha : P \to \mathbb{R}_0^{+}\): \(\alpha_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Vordergrund.
- \(\beta : P \to \mathbb{R}_0^{+}\): \(\beta_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Hintergrund.
- \(\gamma : E \to \mathbb{R}_0^{+}\): \(\gamma_e\) grösser \(\Rightarrow\) benachbarte Pixel eher im gleichen Teil.
Naiver Ansatz \(A := \{p : \alpha_p > \beta_p\}\), \(B := P \setminus A\) wird in vielen Fällen zu feinkörnig: deshalb braucht es die dritte Einschätzung \(\gamma\), die Nachbarschaft berücksichtigt.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Modellierung Bildsegmentierung.</b> Aus den Farben werden drei Einschätzungen extrahiert:<ul><li>\(\alpha : P \to \mathbb{R}_0^{+}\): {{c1::\(\alpha_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Vordergrund}}.</li><li>\(\beta : P \to \mathbb{R}_0^{+}\): {{c2::\(\beta_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Hintergrund}}.</li><li>\(\gamma : E \to \mathbb{R}_0^{+}\): {{c3::\(\gamma_e\) grösser \(\Rightarrow\) benachbarte Pixel eher im gleichen Teil}}.</li></ul> | |
| Extra | Naiver Ansatz \(A := \{p : \alpha_p > \beta_p\}\), \(B := P \setminus A\) wird in vielen Fällen zu feinkörnig: deshalb braucht es die dritte Einschätzung \(\gamma\), die Nachbarschaft berücksichtigt. |
Note 25: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
{&I>#VmXE3
Previous
Note did not exist
New Note
Front
Problem der kantendisjunkten Pfade. Gegeben ein Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\), bestimme eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade.
Back
Problem der kantendisjunkten Pfade. Gegeben ein Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\), bestimme eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade.
Graph ist ungerichtet und ungewichtet.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Problem der kantendisjunkten Pfade.</b> Gegeben ein {{c1::Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\)}}, bestimme {{c2::eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade}}. | |
| Extra | Graph ist ungerichtet und ungewichtet. |
Note 26: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
|(%V*=bZ6e
Before
Front
Floyd's Cycle Finding (Graph-Reformulierung)
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
- Jeder Knoten hat genau eine ausgehende Kante
- Knoten \(n\) hat keine eingehende Kante (weil \(a[i] \neq n\) für alle \(i\))
- Der von Knoten \(n\) ausgehende Subgraph (immer der ausgehenden Kante folgen) besteht aus einem Pfad gefolgt von einem Kreis (\(\rho\)-Form)
Back
Floyd's Cycle Finding (Graph-Reformulierung)
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
- Jeder Knoten hat genau eine ausgehende Kante
- Knoten \(n\) hat keine eingehende Kante (weil \(a[i] \neq n\) für alle \(i\))
- Der von Knoten \(n\) ausgehende Subgraph (immer der ausgehenden Kante folgen) besteht aus einem Pfad gefolgt von einem Kreis (\(\rho\)-Form)
Notation: Pfad hat \(k \geq 1\) Kanten, Kreis hat \(\ell \geq 3\) Kanten, mit \(k + \ell \leq n\).
After
Front
Floyd's Cycle Finding (Graph-Reformulierung)
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
- Jeder Knoten hat genau eine ausgehende Kante
- Knoten \(n\) hat keine eingehende Kante (weil \(a[i] \neq n\) für alle \(i\))
- Der von Knoten \(n\) ausgehende Subgraph (immer der ausgehenden Kante folgen) besteht aus einem Pfad gefolgt von einem Kreis (\(\rho\)-Form)
Back
Floyd's Cycle Finding (Graph-Reformulierung)
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
Definiere den gerichteten Graphen \(D = (V, A)\) mit \(V = [n]\) und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.
Eigenschaften:
- Jeder Knoten hat genau eine ausgehende Kante
- Knoten \(n\) hat keine eingehende Kante (weil \(a[i] \neq n\) für alle \(i\))
- Der von Knoten \(n\) ausgehende Subgraph (immer der ausgehenden Kante folgen) besteht aus einem Pfad gefolgt von einem Kreis (\(\rho\)-Form)
Notation: Pfad hat \(k \geq 1\) Kanten, Kreis hat \(\ell \geq 3\) Kanten, mit \(k + \ell \leq n\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Floyd's Cycle Finding (Graph-Reformulierung)</b><br>Definiere den gerichteten Graphen \(D = (V, A)\) mit {{c1::\(V = [n]\)}} und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.<br>Eigenschaften:<ul><li>Jeder Knoten hat genau {{c3::eine ausgehende Kante}}</li><li>Knoten \(n\) hat {{c4::keine eingehende Kante |
<b>Floyd's Cycle Finding (Graph-Reformulierung)</b><br>Definiere den gerichteten Graphen \(D = (V, A)\) mit {{c1::\(V = [n]\)}} und {{c2::\(A = \{(i, a[i]) \mid 1 \leq i \leq n\}\)}}.<br>Eigenschaften:<ul><li>Jeder Knoten hat genau {{c3::eine ausgehende Kante}}</li><li>Knoten \(n\) hat {{c4::keine eingehende Kante (weil \(a[i] \neq n\) für alle \(i\))}}</li><li>Der von Knoten \(n\) ausgehende Subgraph (immer der ausgehenden Kante folgen) besteht aus {{c5::einem Pfad gefolgt von einem Kreis (\(\rho\)-Form)}}</li></ul> |
Note 27: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
|iDn6XexPi
Previous
Note did not exist
New Note
Front
Konstruktion Bild \(\to\) Netzwerk \(N = (P \cup \{s, t\}, \vec{E}, c, s, t)\):
- Neue Knoten \(s\) (Quelle) und \(t\) (Senke).
- Für jedes \(p \in P\): gerichtete Kante \((s, p)\) mit Kapazität \(\alpha_p\).
- Für jedes \(p \in P\): gerichtete Kante \((p, t)\) mit Kapazität \(\beta_p\).
- Für jede Bildkante \(e = \{p, p'\} \in E\): zwei gerichtete Kanten \((p, p')\) und \((p', p)\), je mit Kapazität \(\gamma_e\).
Back
Konstruktion Bild \(\to\) Netzwerk \(N = (P \cup \{s, t\}, \vec{E}, c, s, t)\):
- Neue Knoten \(s\) (Quelle) und \(t\) (Senke).
- Für jedes \(p \in P\): gerichtete Kante \((s, p)\) mit Kapazität \(\alpha_p\).
- Für jedes \(p \in P\): gerichtete Kante \((p, t)\) mit Kapazität \(\beta_p\).
- Für jede Bildkante \(e = \{p, p'\} \in E\): zwei gerichtete Kanten \((p, p')\) und \((p', p)\), je mit Kapazität \(\gamma_e\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>Konstruktion Bild \(\to\) Netzwerk \(N = (P \cup \{s, t\}, \vec{E}, c, s, t)\):</b><ul><li>Neue Knoten \(s\) (Quelle) und \(t\) (Senke).</li><li>Für jedes \(p \in P\): gerichtete Kante \((s, p)\) mit Kapazität {{c1::\(\alpha_p\)}}.</li><li>Für jedes \(p \in P\): gerichtete Kante \((p, t)\) mit Kapazität {{c2::\(\beta_p\)}}.</li><li>Für jede Bildkante \(e = \{p, p'\} \in E\): {{c3::zwei gerichtete Kanten \((p, p')\) und \((p', p)\), je mit Kapazität \(\gamma_e\)}}.</li></ul> |
Note 28: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
#uX+tPSPEz
Before
Front
Definitionen der hyperbolischen Funktionen:
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c2::\tfrac{1}{2}(e^x + e^{-x})}} \]
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c2::\tfrac{1}{2}(e^x + e^{-x})}} \]
Back
Definitionen der hyperbolischen Funktionen:
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c2::\tfrac{1}{2}(e^x + e^{-x})}} \]
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c2::\tfrac{1}{2}(e^x + e^{-x})}} \]
Es gilt die Identität \(\cosh^2(x) - \sinh^2(x) = 1\).
After
Front
Definitionen der hyperbolischen Funktionen:
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c1::\tfrac{1}{2}(e^x + e^{-x})}} \]
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c1::\tfrac{1}{2}(e^x + e^{-x})}} \]
Back
Definitionen der hyperbolischen Funktionen:
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c1::\tfrac{1}{2}(e^x + e^{-x})}} \]
\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c1::\tfrac{1}{2}(e^x + e^{-x})}} \]
Es gilt die Identität \(\cosh^2(x) - \sinh^2(x) = 1\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Definitionen der hyperbolischen Funktionen:<br>\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c |
Definitionen der hyperbolischen Funktionen:<br>\[ \sinh(x) = {{c1::\tfrac{1}{2}(e^x - e^{-x})}}, \quad \cosh(x) = {{c1::\tfrac{1}{2}(e^x + e^{-x})}} \] |
Note 29: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
.,irs!+R~h
Before
Front
Taylorreihe des Cosinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n}}{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n}}{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
Back
Taylorreihe des Cosinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n}}{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n}}{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
Nur gerade Potenzen, weil \(\cos\) eine gerade Funktion ist. Entwicklungsstelle \(a = 0\).
After
Front
Taylorreihe des Cosinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n} }{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n} }{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
Back
Taylorreihe des Cosinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n} }{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n} }{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \]
Nur gerade Potenzen, weil \(\cos\) eine gerade Funktion ist. Entwicklungsstelle \(a = 0\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Taylorreihe des Cosinus (konvergiert für alle \(x \in \mathbb{R}\)):<br>\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n}}{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \] | Taylorreihe des Cosinus (konvergiert für alle \(x \in \mathbb{R}\)):<br>\[ \cos(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n} }{(2n)!} }} = 1 - \tfrac{1}{2!} x^2 + \tfrac{1}{4!} x^4 - \dots \] |
Note 30: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Fc+2]Q+d90
Before
Front
Eine Funktion \(f\) heisst an der Stelle \(x\) differenzierbar, falls die Ableitung \(f'(x)\) existiert.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich differenzierbar ist.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich differenzierbar ist.
Back
Eine Funktion \(f\) heisst an der Stelle \(x\) differenzierbar, falls die Ableitung \(f'(x)\) existiert.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich differenzierbar ist.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich differenzierbar ist.
After
Front
Eine Funktion \(f\) heisst an der Stelle \(x\) differenzierbar, falls die Ableitung \(f'(x)\) existiert.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich ist.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich ist.
Back
Eine Funktion \(f\) heisst an der Stelle \(x\) differenzierbar, falls die Ableitung \(f'(x)\) existiert.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich ist.
Sie heisst differenzierbar (schlechthin), falls sie für alle \(x\) im Definitionsbereich ist.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Eine Funktion \(f\) heisst {{c1::an der Stelle \(x\) differenzierbar}}, falls {{c2::die Ableitung \(f'(x)\) existiert}}.<br><br>Sie heisst <i>differenzierbar</i> (schlechthin), falls sie {{c3::für alle \(x\) im Definitionsbereich differenzierbar}} ist. | Eine Funktion \(f\) heisst {{c1::an der Stelle \(x\) differenzierbar}}, falls {{c2::die Ableitung \(f'(x)\) existiert}}.<br><br>Sie heisst {{c1::<i>differenzierbar</i>}} (schlechthin), falls sie {{c3::für alle \(x\) im Definitionsbereich {{c1::differenzierbar}} }} ist. |
Note 31: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
f]9cwHTP|(
Before
Front
Definition Absolutbetrag:
\(|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: funktion und cases }}\)
\(|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: funktion und cases }}\)
Back
Definition Absolutbetrag:
\(|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: funktion und cases }}\)
\(|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: funktion und cases }}\)
After
Front
Definition Absolutbetrag: \[|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: \text{Funktion und Cases} }}\]
Back
Definition Absolutbetrag: \[|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: \text{Funktion und Cases} }}\]
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Definition Absolutbetrag: |
Definition Absolutbetrag: \[|x| := {{c1:: \max\{x, -x\} = \begin{cases} x, & x \geq 0 \\ -x, & \text{sonst} \end{cases} :: \text{Funktion und Cases} }}\] |
Note 32: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
gj0j?GOgU5
Before
Front
Taylorreihe des Sinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1}}{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1}}{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
Back
Taylorreihe des Sinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1}}{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1}}{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
Nur ungerade Potenzen, weil \(\sin\) eine ungerade Funktion ist. Entwicklungsstelle \(a = 0\) (Maclaurin-Reihe).
After
Front
Taylorreihe des Sinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1} }{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1} }{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
Back
Taylorreihe des Sinus (konvergiert für alle \(x \in \mathbb{R}\)):
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1} }{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1} }{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \]
Nur ungerade Potenzen, weil \(\sin\) eine ungerade Funktion ist. Entwicklungsstelle \(a = 0\) (Maclaurin-Reihe).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Taylorreihe des Sinus (konvergiert für alle \(x \in \mathbb{R}\)):<br>\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1}}{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \] | Taylorreihe des Sinus (konvergiert für alle \(x \in \mathbb{R}\)):<br>\[ \sin(x) = {{c1::\sum_{n=0}^{\infty} (-1)^n \frac{x^{2n+1} }{(2n+1)!} }} = x - \tfrac{1}{3!} x^3 + \tfrac{1}{5!} x^5 - \dots \] |
Note 33: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
tvE6GF:g2Q
Before
Front
5-Schritt-Methodik zum Aufstellen einer Differentialgleichung für eine Grösse \(y(t)\):
- Schritt 1: Veränderung in einem kleinen Zeitintervall \(\Delta t\) bilanzieren: {{c1::\(y(t + \Delta t) = y(t) + \text{Zuwachs} - \text{Abnahme}\)}}
- Schritt 2: Differenz bilden: \(\Delta y = y(t + \Delta t) - y(t)\)
- Schritt 3: Proportionale Veränderung (Differenzenquotient): {{c3::\(\dfrac{\Delta y}{\Delta t} = \dfrac{y(t + \Delta t) - y(t)}{\Delta t}\)}}
- Schritt 4: Grenzwert \(\Delta t \to 0\): {{c4::\(\dfrac{dy}{dt} = \lim\limits_{\Delta t \to 0} \dfrac{\Delta y}{\Delta t}\)}}
- Schritt 5: Differentialgleichung \(y'(t) = \dots\) zusammenfassen
Back
5-Schritt-Methodik zum Aufstellen einer Differentialgleichung für eine Grösse \(y(t)\):
- Schritt 1: Veränderung in einem kleinen Zeitintervall \(\Delta t\) bilanzieren: {{c1::\(y(t + \Delta t) = y(t) + \text{Zuwachs} - \text{Abnahme}\)}}
- Schritt 2: Differenz bilden: \(\Delta y = y(t + \Delta t) - y(t)\)
- Schritt 3: Proportionale Veränderung (Differenzenquotient): {{c3::\(\dfrac{\Delta y}{\Delta t} = \dfrac{y(t + \Delta t) - y(t)}{\Delta t}\)}}
- Schritt 4: Grenzwert \(\Delta t \to 0\): {{c4::\(\dfrac{dy}{dt} = \lim\limits_{\Delta t \to 0} \dfrac{\Delta y}{\Delta t}\)}}
- Schritt 5: Differentialgleichung \(y'(t) = \dots\) zusammenfassen
After
Front
5-Schritt-Methodik zum Aufstellen einer Differentialgleichung für eine Grösse \(y(t)\):
- Veränderung in einem kleinen Zeitintervall \(\Delta t\) bilanzieren: {{c1::\(y(t + \Delta t) = y(t) + \text{Zuwachs} - \text{Abnahme}\)}}
- Differenz bilden: \(\Delta y = y(t + \Delta t) - y(t)\)
- Proportionale Veränderung (Differenzenquotient): {{c3::\(\dfrac{\Delta y}{\Delta t} = \dfrac{y(t + \Delta t) - y(t)}{\Delta t}\)}}
- Grenzwert \(\Delta t \to 0\): {{c4::\(\dfrac{dy}{dt} = \lim\limits_{\Delta t \to 0} \dfrac{\Delta y}{\Delta t}\)}}
- Differentialgleichung \(y'(t) = \dots\) zusammenfassen
Back
5-Schritt-Methodik zum Aufstellen einer Differentialgleichung für eine Grösse \(y(t)\):
- Veränderung in einem kleinen Zeitintervall \(\Delta t\) bilanzieren: {{c1::\(y(t + \Delta t) = y(t) + \text{Zuwachs} - \text{Abnahme}\)}}
- Differenz bilden: \(\Delta y = y(t + \Delta t) - y(t)\)
- Proportionale Veränderung (Differenzenquotient): {{c3::\(\dfrac{\Delta y}{\Delta t} = \dfrac{y(t + \Delta t) - y(t)}{\Delta t}\)}}
- Grenzwert \(\Delta t \to 0\): {{c4::\(\dfrac{dy}{dt} = \lim\limits_{\Delta t \to 0} \dfrac{\Delta y}{\Delta t}\)}}
- Differentialgleichung \(y'(t) = \dots\) zusammenfassen
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <b>5-Schritt-Methodik</b> zum Aufstellen einer Differentialgleichung für eine Grösse \(y(t)\):<ol><li> |
<b>5-Schritt-Methodik</b> zum Aufstellen einer Differentialgleichung für eine Grösse \(y(t)\):<ol><li>Veränderung in einem kleinen Zeitintervall \(\Delta t\) bilanzieren: {{c1::\(y(t + \Delta t) = y(t) + \text{Zuwachs} - \text{Abnahme}\)}}</li><li>Differenz bilden: {{c2::\(\Delta y = y(t + \Delta t) - y(t)\)}}</li><li>Proportionale Veränderung (Differenzenquotient): {{c3::\(\dfrac{\Delta y}{\Delta t} = \dfrac{y(t + \Delta t) - y(t)}{\Delta t}\)}}</li><li>Grenzwert \(\Delta t \to 0\): {{c4::\(\dfrac{dy}{dt} = \lim\limits_{\Delta t \to 0} \dfrac{\Delta y}{\Delta t}\)}}</li><li>{{c5::Differentialgleichung \(y'(t) = \dots\) zusammenfassen}}</li></ol> |
Note 34: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
!G*k.T_~wz
Previous
Note did not exist
New Note
Front
Six steps of
remove on the lazy skip list: find predecessors, lock the victim node, logically remove it (set the marked flag), lock its predecessors on every level and validate, physically unlink the victim on every level (top-down), then unlock everything.Back
Six steps of
remove on the lazy skip list: find predecessors, lock the victim node, logically remove it (set the marked flag), lock its predecessors on every level and validate, physically unlink the victim on every level (top-down), then unlock everything.Mark first, then unlink: once the victim is marked, any concurrent
contains will (correctly) report the value as absent, even while the physical unlinking is still in progress.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Six steps of <code>remove</code> on the lazy skip list: {{c1::find predecessors}}, {{c2::lock the victim node}}, {{c3::logically remove it (set the marked flag)}}, {{c4::lock its predecessors on every level and validate}}, {{c5::physically unlink the victim on every level (top-down)}}, then {{c6::unlock everything}}. | |
| Extra | Mark first, then unlink: once the victim is marked, any concurrent <code>contains</code> will (correctly) report the value as absent, even while the physical unlinking is still in progress. |
Note 35: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
!gF?S8.igA
Previous
Note did not exist
New Note
Front
Final Michael-Scott
dequeue: while (true) {
Node first = head.get();
Node last = tail.get();
Node next = first.next.get();
if (first == last) {
if (next == null) return null; // truly empty
else tail.compareAndSet(last, next); // help advance tail
} else {
T value = next.item;
if (head.compareAndSet(first, next))
return value;
}
} The two relevant cases when first == last: next == null means the queue is genuinely empty, return null; next != null means an enqueue is in progress and tail lags; help advance it, then retry.Back
Final Michael-Scott
dequeue: while (true) {
Node first = head.get();
Node last = tail.get();
Node next = first.next.get();
if (first == last) {
if (next == null) return null; // truly empty
else tail.compareAndSet(last, next); // help advance tail
} else {
T value = next.item;
if (head.compareAndSet(first, next))
return value;
}
} The two relevant cases when first == last: next == null means the queue is genuinely empty, return null; next != null means an enqueue is in progress and tail lags; help advance it, then retry.Reading
tail before first.next is what catches the inconsistency from the empty-queue enqueue scenario: if tail still equals first but first.next != null, the queue is in the half-enqueued state.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Final Michael-Scott <code>dequeue</code>: <pre>while (true) { Node first = head.get(); Node last = tail.get(); Node next = first.next.get(); if (first == last) { if (next == null) return null; // truly empty else tail.compareAndSet(last, next); // help advance tail } else { T value = next.item; if (head.compareAndSet(first, next)) return value; } }</pre> The two relevant cases when <code>first == last</code>: {{c1::<code>next == null</code> means the queue is genuinely empty, return <code>null</code>}}; {{c2::<code>next != null</code> means an enqueue is in progress and <code>tail</code> lags; help advance it, then retry}}. | |
| Extra | Reading <code>tail</code> before <code>first.next</code> is what catches the inconsistency from the empty-queue enqueue scenario: if <code>tail</code> still equals <code>first</code> but <code>first.next != null</code>, the queue is in the half-enqueued state. |
Note 36: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
#PL3{qyfq6
Previous
Note did not exist
New Note
Front
A lock-free stack uses a single
AtomicReference<Node> top as its only shared state. Both push and pop work by reading top, preparing the new top locally, and committing with top.compareAndSet(oldTop, newTop), retrying on failure.Back
A lock-free stack uses a single
AtomicReference<Node> top as its only shared state. Both push and pop work by reading top, preparing the new top locally, and committing with top.compareAndSet(oldTop, newTop), retrying on failure.No locks are involved, so the structure is deadlock-free by construction.
top is the only point of contention, which is also why a lock-free stack scales poorly under high concurrency unless combined with backoff or an elimination array.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A lock-free stack uses a single {{c1::<code>AtomicReference<Node> top</code>}} as its only shared state. Both <code>push</code> and <code>pop</code> work by reading <code>top</code>, preparing the new <code>top</code> locally, and committing with {{c2::<code>top.compareAndSet(oldTop, newTop)</code>}}, retrying on failure. | |
| Extra | No locks are involved, so the structure is deadlock-free by construction. <code>top</code> is the only point of contention, which is also why a lock-free stack scales poorly under high concurrency unless combined with backoff or an elimination array. |
Note 37: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
#P|j?^In$#
Before
Front
Dekker's algorithm fixes the previous mutex tries by combining the flag-based approach (try 2) with a
turn variable used only for conflict resolution (try 3): when both flags are set, the process whose turn it is not temporarily lowers its flag and waits, then tries again.Back
Dekker's algorithm fixes the previous mutex tries by combining the flag-based approach (try 2) with a
turn variable used only for conflict resolution (try 3): when both flags are set, the process whose turn it is not temporarily lowers its flag and waits, then tries again.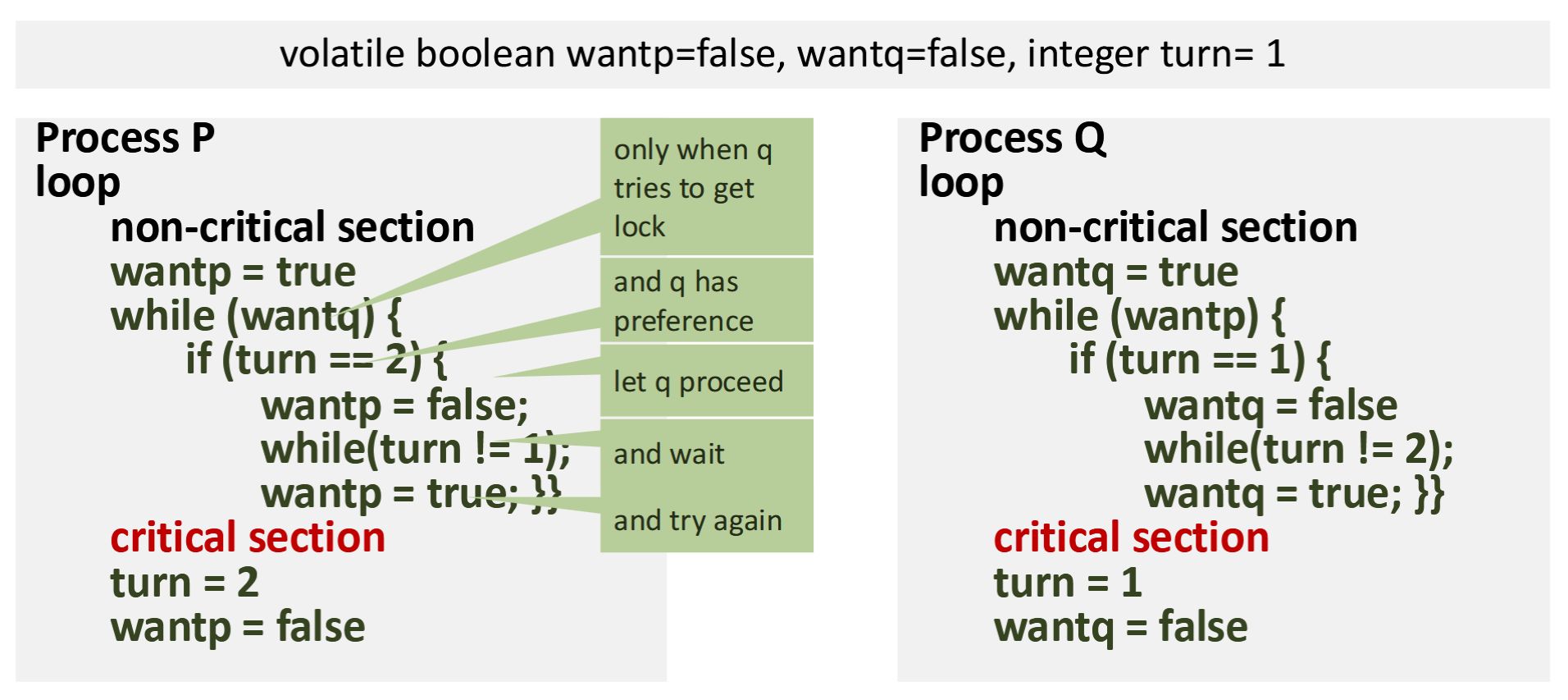
Properties: mutual exclusion, deadlock freedom, starvation freedom. But it is verbose: the code needs an inner conditional and a second wait loop. Peterson's algorithm achieves the same with a much shorter pre-protocol.
After
Front
Dekker's algorithm fixes the previous mutex tries by combining the flag-based approach (try 2) with a
turn variable used only for conflict resolution (try 3).Back
Dekker's algorithm fixes the previous mutex tries by combining the flag-based approach (try 2) with a
turn variable used only for conflict resolution (try 3).When both flags are set, the process whose turn it is not temporarily lowers its flag and waits, then tries again.
Properties: mutual exclusion, deadlock freedom, starvation freedom. But it is verbose: the code needs an inner conditional and a second wait loop. Peterson's algorithm achieves the same with a much shorter pre-protocol.
Properties: mutual exclusion, deadlock freedom, starvation freedom. But it is verbose: the code needs an inner conditional and a second wait loop. Peterson's algorithm achieves the same with a much shorter pre-protocol.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Dekker's algorithm}} fixes the previous mutex tries by combining the {{c2::flag-based approach (try 2)}} with a {{c2::<code>turn</code> variable used only for conflict resolution (try 3)}} |
{{c1::Dekker's algorithm}} fixes the previous mutex tries by combining the {{c2::flag-based approach (try 2)}} with a {{c2::<code>turn</code> variable used only for conflict resolution (try 3)}}. |
| Extra | <img src="paste-45b381800039ef5079704ec60957021441c04154.jpg"><br><br>Properties: mutual exclusion, deadlock freedom, starvation freedom. But it is verbose: the code needs an inner conditional and a second wait loop. Peterson's algorithm achieves the same with a much shorter pre-protocol. | When both flags are set, the process whose turn it is <i>not</i> temporarily lowers its flag and waits, then tries again.<br><br><img src="paste-45b381800039ef5079704ec60957021441c04154.jpg"><br><br>Properties: mutual exclusion, deadlock freedom, starvation freedom. But it is verbose: the code needs an inner conditional and a second wait loop. Peterson's algorithm achieves the same with a much shorter pre-protocol. |
Note 38: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
#XE.GywjOr
Previous
Note did not exist
New Note
Front
Lock-free list-set with
AtomicMarkableReference: the central idea is to atomically swing a next-pointer and update the deletion mark in a single CAS over the (ref, mark) pair. remove is split into two steps: first set the mark bit on the victim's next field (logical delete), then redirect the predecessor's pointer past the victim (physical delete).Back
Lock-free list-set with
AtomicMarkableReference: the central idea is to atomically swing a next-pointer and update the deletion mark in a single CAS over the (ref, mark) pair. remove is split into two steps: first set the mark bit on the victim's next field (logical delete), then redirect the predecessor's pointer past the victim (physical delete).After the first step, the victim is observably deleted (any
contains will return false) even if the second step is delayed or performed by a different thread.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free list-set with <code>AtomicMarkableReference</code>: the central idea is {{c1::to atomically swing a next-pointer <em>and</em> update the deletion mark in a single CAS over the (ref, mark) pair}}. <code>remove</code> is split into two steps: {{c2::first set the mark bit on the victim's <code>next</code> field (logical delete)}}, then {{c3::redirect the predecessor's pointer past the victim (physical delete)}}. | |
| Extra | After the first step, the victim is observably deleted (any <code>contains</code> will return <code>false</code>) even if the second step is delayed or performed by a different thread. |
Note 39: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
$$A!ueA__x
Previous
Note did not exist
New Note
Front
Initial Michael-Scott protocol. Enqueuer: read
tail into last; CAS(last.next, null, new); on success, without retry try CAS(tail, last, new). Dequeuer: read head into first, read first.next into next, read next.item, then CAS(head, first, next); on failure retry.Back
Initial Michael-Scott protocol. Enqueuer: read
tail into last; CAS(last.next, null, new); on success, without retry try CAS(tail, last, new). Dequeuer: read head into first, read first.next into next, read next.item, then CAS(head, first, next); on failure retry.The asymmetry, enqueuer retries on the first CAS but not the second, is intentional: a failed second CAS means some other thread already advanced
tail, so the enqueue's logical effect is already established.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Initial Michael-Scott protocol. <em>Enqueuer</em>: read <code>tail</code> into <code>last</code>; {{c1::<code>CAS(last.next, null, new)</code>}}; on success, <em>without retry</em> try {{c2::<code>CAS(tail, last, new)</code>}}. <em>Dequeuer</em>: read <code>head</code> into <code>first</code>, read <code>first.next</code> into <code>next</code>, read <code>next.item</code>, then {{c3::<code>CAS(head, first, next)</code>}}; on failure retry. | |
| Extra | The asymmetry, enqueuer retries on the first CAS but not the second, is intentional: a failed second CAS means <em>some other</em> thread already advanced <code>tail</code>, so the enqueue's logical effect is already established. |
Note 40: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
%fsWI2K&[)
Previous
Note did not exist
New Note
Front
Lock-free list-set
remove(item) on top of find: while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key != key) return false;
Node succ = curr.next.getReference();
snip = curr.next.attemptMark(succ, true); // step 1
if (!snip) continue; // mark failed, retry
pred.next.compareAndSet(curr, succ, false, false); // step 2, ignore result
return true;
} Two points to note: if step 1 fails, the whole operation restarts from find; if step 2 fails, the result is ignored, because some other traverser will help unlink later.Back
Lock-free list-set
remove(item) on top of find: while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key != key) return false;
Node succ = curr.next.getReference();
snip = curr.next.attemptMark(succ, true); // step 1
if (!snip) continue; // mark failed, retry
pred.next.compareAndSet(curr, succ, false, false); // step 2, ignore result
return true;
} Two points to note: if step 1 fails, the whole operation restarts from find; if step 2 fails, the result is ignored, because some other traverser will help unlink later.Step 1 is the linearisation point: a marked node is, by convention, observably absent from the set, even before step 2 has run.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free list-set <code>remove(item)</code> on top of <code>find</code>: <pre>while (true) { Window w = find(head, key); Node pred = w.pred, curr = w.curr; if (curr.key != key) return false; Node succ = curr.next.getReference(); snip = curr.next.attemptMark(succ, true); // step 1 if (!snip) continue; // mark failed, retry pred.next.compareAndSet(curr, succ, false, false); // step 2, ignore result return true; }</pre> Two points to note: if step 1 fails, {{c1::the whole operation restarts from <code>find</code>}}; if step 2 fails, {{c2::the result is ignored, because some other traverser will help unlink later}}. | |
| Extra | Step 1 is the linearisation point: a marked node is, by convention, observably absent from the set, even before step 2 has run. |
Note 41: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
(.5V#5h(R?
Previous
Note did not exist
New Note
Front
Lock-free stack
pop: public Long pop() {
Node head, next;
do {
head = top.get();
if (head == null) return null;
next = head.next;
} while (!top.compareAndSet(head, next));
return head.item;
} The CAS commits the swing of top from the observed head to head.next; on failure the loop re-reads top and retries.Back
Lock-free stack
pop: public Long pop() {
Node head, next;
do {
head = top.get();
if (head == null) return null;
next = head.next;
} while (!top.compareAndSet(head, next));
return head.item;
} The CAS commits the swing of top from the observed head to head.next; on failure the loop re-reads top and retries.Two threads racing
pop: exactly one CAS wins, the loser retries with the new top. The stack remains consistent because head.next is read locally before the CAS attempt.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free stack <code>pop</code>: <pre>public Long pop() { Node head, next; do { head = top.get(); if (head == null) return null; next = head.next; } while (!top.compareAndSet(head, next)); return head.item; }</pre> The CAS {{c1::commits the swing of <code>top</code> from the observed <code>head</code> to <code>head.next</code>}}; on failure the loop {{c2::re-reads <code>top</code> and retries}}. | |
| Extra | Two threads racing <code>pop</code>: exactly one CAS wins, the loser retries with the new top. The stack remains consistent because <code>head.next</code> is read locally before the CAS attempt. |
Note 42: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
,;%ozH3sla
Previous
Note did not exist
New Note
Front
contains(item) on the lazy list is wait-free: it walks from head following next pointers without taking any lock, then returns curr.key == key && !curr.marked. Correctness rests on the invariant that an unmarked node is reachable, even if other nodes are concurrently being marked or unlinked.Back
contains(item) on the lazy list is wait-free: it walks from head following next pointers without taking any lock, then returns curr.key == key && !curr.marked. Correctness rests on the invariant that an unmarked node is reachable, even if other nodes are concurrently being marked or unlinked.Wait-freedom here is per call: every
contains finishes in a bounded number of steps regardless of what other threads do. add and remove remain only blocking (they take locks).Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <code>contains(item)</code> on the lazy list is {{c1::wait-free}}: it walks from <code>head</code> following <code>next</code> pointers <em>without taking any lock</em>, then returns {{c2::<code>curr.key == key && !curr.marked</code>}}. Correctness rests on the invariant that {{c3::an unmarked node is reachable, even if other nodes are concurrently being marked or unlinked}}. | |
| Extra | Wait-freedom here is per call: every <code>contains</code> finishes in a bounded number of steps regardless of what other threads do. <code>add</code> and <code>remove</code> remain only blocking (they take locks). |
Note 43: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
,NDJ
Previous
Note did not exist
New Note
Front
Concrete ABA scenario on a CAS-based stack with a node pool. Thread X starts
pop, reads head = A and next = A.next, then stalls before its CAS. While X is paused: Y pops A (so A goes back into the pool); Z pushes B (now top = B → ... ); Z' pushes A again (recycled from the pool; top = A → B → ...). X now wakes up and runs top.compareAndSet(A, A.next_old). The CAS succeeds because top is again A, but it now points top at a stale successor, corrupting the stack.Back
Concrete ABA scenario on a CAS-based stack with a node pool. Thread X starts
pop, reads head = A and next = A.next, then stalls before its CAS. While X is paused: Y pops A (so A goes back into the pool); Z pushes B (now top = B → ... ); Z' pushes A again (recycled from the pool; top = A → B → ...). X now wakes up and runs top.compareAndSet(A, A.next_old). The CAS succeeds because top is again A, but it now points top at a stale successor, corrupting the stack.The corruption is observable as the symptoms in the lecture's runs: "sum of pushes and pops don't match" (lost items) or an infinite hang (lost node forms a self-cycle). Crucially, this cannot happen without reuse: a freshly allocated node has a brand-new identity, so the CAS would fail.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Concrete ABA scenario on a CAS-based stack with a node pool. Thread X starts <code>pop</code>, reads <code>head = A</code> and <code>next = A.next</code>, then stalls before its CAS. While X is paused: {{c1::Y pops A (so A goes back into the pool)}}; {{c2::Z pushes B (now top = B → ... )}}; {{c3::Z' pushes A again (recycled from the pool; top = A → B → ...)}}. X now wakes up and runs <code>top.compareAndSet(A, A.next_old)</code>. The CAS {{c4::succeeds because top is again <code>A</code>, but it now points <code>top</code> at a stale successor, corrupting the stack}}. | |
| Extra | The corruption is observable as the symptoms in the lecture's runs: "sum of pushes and pops don't match" (lost items) or an infinite hang (lost node forms a self-cycle). Crucially, this <em>cannot</em> happen without reuse: a freshly allocated node has a brand-new identity, so the CAS would fail. |
Note 44: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
.:6|d1{$n|
Previous
Note did not exist
New Note
Front
Three structural problems with plain spinlocks: no scheduling fairness / no FIFO behaviour (solved by queue locks), wasted CPU cycles, with overall throughput degraded especially under long-lived contention, and no notification mechanism (a waiter has no way to be told that some condition has become true).
Back
Three structural problems with plain spinlocks: no scheduling fairness / no FIFO behaviour (solved by queue locks), wasted CPU cycles, with overall throughput degraded especially under long-lived contention, and no notification mechanism (a waiter has no way to be told that some condition has become true).
All three motivate moving to scheduled / waiting locks, where the OS scheduler can park a waiter, wake it up on demand, and order waiters explicitly.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Three structural problems with plain spinlocks: {{c1::no scheduling fairness / no FIFO behaviour (solved by queue locks)}}, {{c2::wasted CPU cycles, with overall throughput degraded especially under long-lived contention}}, and {{c3::no notification mechanism (a waiter has no way to be told that some condition has become true)}}. | |
| Extra | All three motivate moving to scheduled / waiting locks, where the OS scheduler can park a waiter, wake it up on demand, and order waiters explicitly. |
Note 45: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
2/>$oKBf#e
Previous
Note did not exist
New Note
Front
Abstract problem behind the lock-free list: without locks, atomically establish consistency of two things at once. Here those two things are the deletion mark bit and the
next pointer of the same node. A plain CAS only handles one machine word, so a way to bind both into a single atomic update is needed.Back
Abstract problem behind the lock-free list: without locks, atomically establish consistency of two things at once. Here those two things are the deletion mark bit and the
next pointer of the same node. A plain CAS only handles one machine word, so a way to bind both into a single atomic update is needed.This is one of the canonical motivations for double-word CAS (DCAS), AtomicMarkableReference / AtomicStampedReference, or LL/SC.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Abstract problem behind the lock-free list: {{c1::without locks, atomically establish consistency of <em>two</em> things at once}}. Here those two things are {{c2::the deletion mark bit and the <code>next</code> pointer of the same node}}. A plain CAS only handles one machine word, so a way to bind both into a single atomic update is needed. | |
| Extra | This is one of the canonical motivations for double-word CAS (DCAS), AtomicMarkableReference / AtomicStampedReference, or LL/SC. |
Note 46: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
3D5,pey@8V
Previous
Note did not exist
New Note
Front
Inside the locked critical section of the lazy
remove(item), the validation check is !pred.marked && !curr.marked && pred.next == curr. If it passes and curr.key == key, the thread performs the two-step delete: curr.marked = true; (logical), then pred.next = curr.next; (physical).Back
Inside the locked critical section of the lazy
remove(item), the validation check is !pred.marked && !curr.marked && pred.next == curr. If it passes and curr.key == key, the thread performs the two-step delete: curr.marked = true; (logical), then pred.next = curr.next; (physical).Contrast with optimistic synchronisation: there the validation walked the list from
head to re-establish reachability. Here the unmarked flags imply reachability by the key invariant, so a single local check suffices.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Inside the locked critical section of the lazy <code>remove(item)</code>, the validation check is {{c1::<code>!pred.marked && !curr.marked && pred.next == curr</code>}}. If it passes and <code>curr.key == key</code>, the thread performs the two-step delete: {{c2::<code>curr.marked = true;</code>}} (logical), then {{c3::<code>pred.next = curr.next;</code>}} (physical). | |
| Extra | Contrast with optimistic synchronisation: there the validation walked the list from <code>head</code> to re-establish reachability. Here the unmarked flags <em>imply</em> reachability by the key invariant, so a single local check suffices. |
Note 47: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
3H)8)EQ;-`
Previous
Note did not exist
New Note
Front
The lazy skip-list
find(x, pre, succ) returns -1 if the value is not present, otherwise the level at which x was found. It also fills the output arrays pre: predecessor on each level and succ: successor on each level.Back
The lazy skip-list
find(x, pre, succ) returns -1 if the value is not present, otherwise the level at which x was found. It also fills the output arrays pre: predecessor on each level and succ: successor on each level.The level/pre/succ information is what
add and remove need afterwards to splice or unlink the node at every level it appears in.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The lazy skip-list <code>find(x, pre, succ)</code> returns {{c1::<code>-1</code> if the value is not present}}, otherwise {{c2::the level at which <code>x</code> was found}}. It also fills the output arrays {{c3::<code>pre</code>: predecessor on each level}} and {{c3::<code>succ</code>: successor on each level}}. | |
| Extra | The level/pre/succ information is what <code>add</code> and <code>remove</code> need afterwards to splice or unlink the node at every level it appears in. |
Note 48: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
7NAO)y6KI0
Previous
Note did not exist
New Note
Front
Lock-free stack
push: public void push(Long item) {
Node newi = new Node(item);
Node head;
do {
head = top.get();
newi.next = head;
} while (!top.compareAndSet(head, newi));
} The new node is built first, its next is wired to the currently observed top, then the CAS installs the new node as top iff top has not changed in the meantime.Back
Lock-free stack
push: public void push(Long item) {
Node newi = new Node(item);
Node head;
do {
head = top.get();
newi.next = head;
} while (!top.compareAndSet(head, newi));
} The new node is built first, its next is wired to the currently observed top, then the CAS installs the new node as top iff top has not changed in the meantime.The new node is invisible to other threads until the CAS succeeds, so there is no need to undo anything on failure.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free stack <code>push</code>: <pre>public void push(Long item) { Node newi = new Node(item); Node head; do { head = top.get(); newi.next = head; } while (!top.compareAndSet(head, newi)); }</pre> The new node is built first, its <code>next</code> is wired to the currently observed <code>top</code>, then the CAS {{c1::installs the new node as <code>top</code> iff <code>top</code> has not changed in the meantime}}. | |
| Extra | The new node is invisible to other threads until the CAS succeeds, so there is no need to undo anything on failure. |
Note 49: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
=s[j03_JHO
Previous
Note did not exist
New Note
Front
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that the lock-free version can be slower than the blocking one, because atomic operations are expensive and the CAS retry loop wastes work under contention. Adding exponential backoff to the retry loop restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Back
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that the lock-free version can be slower than the blocking one, because atomic operations are expensive and the CAS retry loop wastes work under contention. Adding exponential backoff to the retry loop restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Moral: lock-freedom is a progress property, not an automatic performance property. Contention management (backoff, elimination, combining) is still needed to make lock-free structures fast.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that {{c1::the lock-free version can be <em>slower</em> than the blocking one}}, because {{c2::atomic operations are expensive and the CAS retry loop wastes work under contention}}. Adding {{c3::exponential backoff to the retry loop}} restores good scalability and makes the lock-free + backoff variant the fastest of the three. | |
| Extra | Moral: lock-freedom is a <em>progress</em> property, not an automatic <em>performance</em> property. Contention management (backoff, elimination, combining) is still needed to make lock-free structures fast. |
Note 50: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
?]il7jjUkY
Previous
Note did not exist
New Note
Front
The ABA problem: one activity fails to recognise that a single memory location was modified temporarily by another activity, and therefore erroneously assumes the overall state has not changed. It is the fundamental limitation of plain CAS as a concurrency check, and it surfaces in lock-free algorithms whenever values (typically pointers) can be reused.
Back
The ABA problem: one activity fails to recognise that a single memory location was modified temporarily by another activity, and therefore erroneously assumes the overall state has not changed. It is the fundamental limitation of plain CAS as a concurrency check, and it surfaces in lock-free algorithms whenever values (typically pointers) can be reused.
Standard defences: (1) tag the reference with a version counter that increments on every write (e.g.
AtomicStampedReference); (2) use LL/SC instead of CAS, since the store-conditional fails on any intervening write, not just on values; (3) hazard pointers or epoch-based reclamation to ensure a freed node cannot reappear while another thread holds a reference to it.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The ABA problem: {{c1::one activity fails to recognise that a single memory location was modified <em>temporarily</em> by another activity, and therefore erroneously assumes the overall state has not changed}}. It is the fundamental limitation of plain CAS as a concurrency check, and it surfaces in lock-free algorithms whenever {{c2::values (typically pointers) can be reused}}. | |
| Extra | Standard defences: (1) tag the reference with a version counter that increments on every write (e.g. <code>AtomicStampedReference</code>); (2) use LL/SC instead of CAS, since the store-conditional fails on <em>any</em> intervening write, not just on values; (3) hazard pointers or epoch-based reclamation to ensure a freed node cannot reappear while another thread holds a reference to it. |
Note 51: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
?t1]O+nAMP
Previous
Note did not exist
New Note
Front
In an unmanaged environment (kernel, no GC), per-operation allocation is unacceptable, so dequeued nodes are returned to a node pool and later reused by enqueues. Two consequences: a node can be present in at most one in-place structure at a time (so per-instance pools are tricky, a global pool is fine), and CAS-based protocols become vulnerable to the ABA problem because the very same pointer may legitimately reappear at the same place.
Back
In an unmanaged environment (kernel, no GC), per-operation allocation is unacceptable, so dequeued nodes are returned to a node pool and later reused by enqueues. Two consequences: a node can be present in at most one in-place structure at a time (so per-instance pools are tricky, a global pool is fine), and CAS-based protocols become vulnerable to the ABA problem because the very same pointer may legitimately reappear at the same place.
The pool itself is implemented as just another lock-free stack with the same
get/put CAS loop. The hidden cost is exactly the ABA exposure that the rest of this section addresses.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | In an unmanaged environment (kernel, no GC), per-operation allocation is unacceptable, so dequeued nodes are returned to a {{c1::node pool}} and later reused by enqueues. Two consequences: {{c2::a node can be present in at most one in-place structure at a time}} (so per-instance pools are tricky, a global pool is fine), and {{c3::CAS-based protocols become vulnerable to the ABA problem because the very same pointer may legitimately reappear at the same place}}. | |
| Extra | The pool itself is implemented as just another lock-free stack with the same <code>get</code>/<code>put</code> CAS loop. The hidden cost is exactly the ABA exposure that the rest of this section addresses. |
Note 52: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
@+_^I8!US|
Previous
Note did not exist
New Note
Front
Waiting (scheduled) locks suspend a blocked thread instead of spinning. Typical building blocks: semaphores, mutexes, and monitors. A monitor has two queues: a waiting entry queue for threads trying to enter the monitor, and a waiting condition queue for threads that have called
wait inside it. These queues themselves must be protected against concurrent access, typically with a spinlock (unless implemented lock-free).Back
Waiting (scheduled) locks suspend a blocked thread instead of spinning. Typical building blocks: semaphores, mutexes, and monitors. A monitor has two queues: a waiting entry queue for threads trying to enter the monitor, and a waiting condition queue for threads that have called
wait inside it. These queues themselves must be protected against concurrent access, typically with a spinlock (unless implemented lock-free).So spinlocks do not disappear when one moves to scheduled locks: they are reused at a lower level to protect the scheduler's data structures.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Waiting (scheduled) locks suspend a blocked thread instead of spinning. Typical building blocks: {{c1::semaphores, mutexes, and monitors}}. A monitor has two queues: {{c2::a <em>waiting entry</em> queue for threads trying to enter the monitor}}, and {{c2::a <em>waiting condition</em> queue for threads that have called <code>wait</code> inside it}}. These queues themselves must be protected against concurrent access, typically {{c3::with a spinlock}} (unless implemented lock-free). | |
| Extra | So spinlocks do not disappear when one moves to scheduled locks: they are reused at a lower level to protect the scheduler's data structures. |
Note 53: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
BUqM`:KflF
Previous
Note did not exist
New Note
Front
Key invariant of the lazy list: if a node is not marked, then it is reachable from
head and it is reachable from its predecessor.Back
Key invariant of the lazy list: if a node is not marked, then it is reachable from
head and it is reachable from its predecessor.This is exactly what makes the per-node validation in lazy
remove/add work without rescanning the list: locking the two-node window and reading both marked flags is enough to certify reachability.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <em>Key invariant</em> of the lazy list: if a node is not marked, then {{c1::it is reachable from <code>head</code>}} <em>and</em> {{c1::it is reachable from its predecessor}}. | |
| Extra | This is exactly what makes the per-node validation in lazy <code>remove</code>/<code>add</code> work without rescanning the list: locking the two-node window and reading both <code>marked</code> flags is enough to certify reachability. |
Note 54: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Ctz
Before
Front
Scheduling overhead is the extra time spent by the system or the algorithm to distribute work on multiple threads/tasks.
Back
Scheduling overhead is the extra time spent by the system or the algorithm to distribute work on multiple threads/tasks.
After
Front
Scheduling overhead is the extra time spent by the system or the algorithm to distribute work on multiple threads/tasks.
Back
Scheduling overhead is the extra time spent by the system or the algorithm to distribute work on multiple threads/tasks.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Scheduling overhead}} is |
{{c1::Scheduling overhead}} is {{c2::the extra time spent by the system or the algorithm to distribute work on multiple threads/tasks}}. |
Note 55: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
D:Fv|@_<,B
Previous
Note did not exist
New Note
Front
Lock-free list-set
add(item) on top of find: while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key == key) return false;
Node node = new Node(item);
node.next = new AtomicMarkableReference(curr, false);
if (pred.next.compareAndSet(curr, node, false, false))
return true;
// else retry
} The single CAS commits both that pred still points to curr and that pred is itself still unmarked. If it fails, another thread changed pred.next or marked pred for deletion in the meantime, so the operation restarts.Back
Lock-free list-set
add(item) on top of find: while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key == key) return false;
Node node = new Node(item);
node.next = new AtomicMarkableReference(curr, false);
if (pred.next.compareAndSet(curr, node, false, false))
return true;
// else retry
} The single CAS commits both that pred still points to curr and that pred is itself still unmarked. If it fails, another thread changed pred.next or marked pred for deletion in the meantime, so the operation restarts.Because
find already snips away every marked node it encounters, by the time add tries its CAS the window (pred, curr) is "clean": any failure of this CAS is due to a concurrent operation, not stale state from a half-done remove.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free list-set <code>add(item)</code> on top of <code>find</code>: <pre>while (true) { Window w = find(head, key); Node pred = w.pred, curr = w.curr; if (curr.key == key) return false; Node node = new Node(item); node.next = new AtomicMarkableReference(curr, false); if (pred.next.compareAndSet(curr, node, false, false)) return true; // else retry }</pre> The single CAS commits both that {{c1::<code>pred</code> still points to <code>curr</code>}} and that {{c2::<code>pred</code> is itself still unmarked}}. If it fails, {{c3::another thread changed <code>pred.next</code> or marked <code>pred</code> for deletion in the meantime, so the operation restarts}}. | |
| Extra | Because <code>find</code> already snips away every marked node it encounters, by the time <code>add</code> tries its CAS the window <code>(pred, curr)</code> is "clean": any failure of this CAS is due to a concurrent operation, not stale state from a half-done remove. |
Note 56: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
F&WMvXhXR0
Previous
Note did not exist
New Note
Front
Lock-free
Window find(head, key) structure: an outer retry loop (restart from head if a snip CAS fails) surrounds an inner walk. In the inner walk, at each node the thread reads (succ, marked) from the AMR and, while marked is set, tries pred.next.CAS(curr, succ, false, false) to physically unlink curr, then advances. If the snip CAS fails, the whole traversal is restarted from head; otherwise the walk continues until curr.key >= key, which is returned as Window(pred, curr).Back
Lock-free
Window find(head, key) structure: an outer retry loop (restart from head if a snip CAS fails) surrounds an inner walk. In the inner walk, at each node the thread reads (succ, marked) from the AMR and, while marked is set, tries pred.next.CAS(curr, succ, false, false) to physically unlink curr, then advances. If the snip CAS fails, the whole traversal is restarted from head; otherwise the walk continues until curr.key >= key, which is returned as Window(pred, curr).Window is a tiny holder class with two fields pred and curr. Returning both lets add and remove avoid re-walking the list.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free <code>Window find(head, key)</code> structure: an {{c1::outer retry loop (restart from <code>head</code> if a snip CAS fails)}} surrounds an inner walk. In the inner walk, at each node the thread reads <code>(succ, marked)</code> from the AMR and, while <code>marked</code> is set, {{c2::tries <code>pred.next.CAS(curr, succ, false, false)</code> to physically unlink <code>curr</code>}}, then advances. If the snip CAS fails, {{c3::the whole traversal is restarted from <code>head</code>}}; otherwise the walk continues until <code>curr.key >= key</code>, which is returned as <code>Window(pred, curr)</code>. | |
| Extra | <code>Window</code> is a tiny holder class with two fields <code>pred</code> and <code>curr</code>. Returning both lets <code>add</code> and <code>remove</code> avoid re-walking the list. |
Note 57: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
FQh8J6s4%4
Previous
Note did not exist
New Note
Front
Naive CAS-only list: why concurrent
remove(b) and remove(c) on neighbouring nodes break correctness. Thread A executes CAS(b.next, c, d) while thread B executes CAS(a.next, b, c). Both CAS calls succeed (each operates on a different field) and the result is a -> c -> d: node c is still reachable, even though it was supposed to be removed.Back
Naive CAS-only list: why concurrent
remove(b) and remove(c) on neighbouring nodes break correctness. Thread A executes CAS(b.next, c, d) while thread B executes CAS(a.next, b, c). Both CAS calls succeed (each operates on a different field) and the result is a -> c -> d: node c is still reachable, even though it was supposed to be removed.The deeper reason: a successful CAS only certifies that the predecessor's next pointer has not changed. It says nothing about whether the node about to be deleted is itself still part of the list.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Naive CAS-only list: why concurrent <code>remove(b)</code> and <code>remove(c)</code> on neighbouring nodes break correctness. Thread A executes <code>CAS(b.next, c, d)</code> while thread B executes <code>CAS(a.next, b, c)</code>. Both CAS calls succeed (each operates on a different field) and the result is {{c1::<code>a -> c -> d</code>: node <code>c</code> is still reachable, even though it was supposed to be removed}}. | |
| Extra | The deeper reason: a successful CAS only certifies that the <em>predecessor's next pointer</em> has not changed. It says nothing about whether the node about to be deleted is itself still part of the list. |
Note 58: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
Gce$$}OD(b
Previous
Note did not exist
New Note
Front
Sublist property of a skip list: a higher-level list is always contained in every lower-level list; in particular the lowest level contains the entire list.
Back
Sublist property of a skip list: a higher-level list is always contained in every lower-level list; in particular the lowest level contains the entire list.
Equivalently: if a node has height \(h\), it appears in levels \(0, 1, \dots, h-1\). Sentinel nodes \(-\infty\) and \(+\infty\) are present at every level.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <em>Sublist property</em> of a skip list: {{c1::a higher-level list is always contained in every lower-level list}}; in particular {{c2::the lowest level contains the entire list}}. | |
| Extra | Equivalently: if a node has height \(h\), it appears in levels \(0, 1, \dots, h-1\). Sentinel nodes \(-\infty\) and \(+\infty\) are present at every level. |
Note 59: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
GkQ^u.{q`{
Before
Front
Scalability in our context means: By how much can a program be parallelized. What is the maximum speedup that can be achieved, given an infinite amount of processors.
Back
Scalability in our context means: By how much can a program be parallelized. What is the maximum speedup that can be achieved, given an infinite amount of processors.
After
Front
Scalability in our context means: By how much can a program be parallelized.
Back
Scalability in our context means: By how much can a program be parallelized.
What is the maximum speedup that can be achieved, given an infinite amount of processors.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Scalability}} in our context means: {{c2::By how much can a program be parallelized}}. |
{{c1::Scalability}} in our context means: {{c2::By how much can a program be parallelized}}. |
| Extra | What is the maximum speedup that can be achieved, given an infinite amount of processors. |
Note 60: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
IOG>^+Y+Tt
Before
Front
Lockout means needlessly preventing a thread from entering a critical section.
Back
Lockout means needlessly preventing a thread from entering a critical section.
After
Front
Lockout means needlessly preventing a thread from entering a critical section.
Back
Lockout means needlessly preventing a thread from entering a critical section.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Lockout}} means {{c2::needlessly preventing |
{{c1::Lockout}} means {{c2::needlessly preventing a thread from entering a critical section}}. |
Note 61: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Ii]YQh:cvR
Before
Front
Vectorisation uses special machine code instructions to execute a single operation (e.g. plus) on a chunk of data (e.g. an array segment).
Back
Vectorisation uses special machine code instructions to execute a single operation (e.g. plus) on a chunk of data (e.g. an array segment).
Can significantly improve performance.
After
Front
Vectorisation uses special machine code instructions to execute a single operation (e.g. plus) on a chunk of data (e.g. an array segment).
Back
Vectorisation uses special machine code instructions to execute a single operation (e.g. plus) on a chunk of data (e.g. an array segment).
Can significantly improve performance.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Vectorisation}} uses special machine code instructions to execute a |
{{c1::Vectorisation}} uses special machine code instructions to {{c2::execute a single operation (e.g. plus) on a chunk of data (e.g. an array segment)}}. |
Note 62: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
Ivkg+_~|E~
Before
Front
With fine granularity, work is split into small tasks. This can be parallelized more, but also adds more overhead.
Back
With fine granularity, work is split into small tasks. This can be parallelized more, but also adds more overhead.
After
Front
With fine granularity, work is split into small tasks.
Back
With fine granularity, work is split into small tasks.
This can be parallelized more, but also adds more overhead.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | With {{c1::fine granularity}}, work is split into {{c2::small tasks}}. |
With {{c1::fine granularity}}, work is split into {{c2::small tasks}}. |
| Extra | This can be parallelized more, but also adds more overhead. |
Note 63: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
Iwhpp6dnE)
Previous
Note did not exist
New Note
Front
Skip lists are introduced as a practical set representation under the workload assumption that
find is called much more often than add, and add more often than remove. The interface is add, remove, find over a duplicate-free collection.Back
Skip lists are introduced as a practical set representation under the workload assumption that
find is called much more often than add, and add more often than remove. The interface is add, remove, find over a duplicate-free collection.This read-dominated assumption is what makes a wait-free
contains/find the main design goal.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Skip lists are introduced as a practical set representation under the workload assumption that {{c1::<code>find</code> is called <em>much</em> more often than <code>add</code>, and <code>add</code> more often than <code>remove</code>}}. The interface is {{c2::<code>add</code>, <code>remove</code>, <code>find</code>}} over a duplicate-free collection. | |
| Extra | This read-dominated assumption is what makes a wait-free <code>contains</code>/<code>find</code> the main design goal. |
Note 64: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
KqllK[O
Previous
Note did not exist
New Note
Front
Defining property of a non-blocking algorithm: the failure or suspension of one thread cannot cause the failure or suspension of another thread. Contrast with locks/blocking, where one thread can indefinitely delay another (e.g. by dying inside the critical section).
Back
Defining property of a non-blocking algorithm: the failure or suspension of one thread cannot cause the failure or suspension of another thread. Contrast with locks/blocking, where one thread can indefinitely delay another (e.g. by dying inside the critical section).
This is precisely what makes non-blocking algorithms suitable for environments where threads may be preempted, killed, or run at very different speeds (real-time systems, interrupt handlers, GC pauses).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Defining property of a non-blocking algorithm: {{c1::the failure or suspension of one thread cannot cause the failure or suspension of another thread}}. Contrast with locks/blocking, where {{c2::one thread can indefinitely delay another (e.g. by dying inside the critical section)}}. | |
| Extra | This is precisely what makes non-blocking algorithms suitable for environments where threads may be preempted, killed, or run at very different speeds (real-time systems, interrupt handlers, GC pauses). |
Note 65: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
L#!rmjGpR]
Before
Front
\(T_p\) is the time required to perform work on {{c2::p processors}
Back
\(T_p\) is the time required to perform work on {{c2::p processors}
After
Front
\(T_p\) is the time required to perform work on \(p\) processors.
Back
\(T_p\) is the time required to perform work on \(p\) processors.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1:: \(T_p\)}} is the time required to perform work on |
{{c1:: \(T_p\)}} is the time required to perform work on \(p\) processors. |
Note 66: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
L/^V2kJI?*
Before
Front
Schedulers typically do not give guarantees about when and how often they act, who gets selected next, etc.
Back
Schedulers typically do not give guarantees about when and how often they act, who gets selected next, etc.
After
Front
Schedulers typically do not give guarantees about when and how often they act, who gets selected next, etc.
Back
Schedulers typically do not give guarantees about when and how often they act, who gets selected next, etc.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Schedulers}} typically |
{{c1::Schedulers}} typically do not {{c2::give guarantees about when and how often they act, who gets selected next, etc}}. |
Note 67: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
MX>`Kg8*SU
Before
Front
Which events can influence if a race condition happens or not? (Assuming it is already present in the code)
Back
Which events can influence if a race condition happens or not? (Assuming it is already present in the code)
scheduler interactions can cause different interleavings
variable network latency
variable network latency
After
Front
Which events can influence if a race condition happens or not? (Assuming it is already present in the code)
Back
Which events can influence if a race condition happens or not? (Assuming it is already present in the code)
The OS thread scheduler's interleaving of instructions, plus timing factors like CPU load, cache state, I/O delays, and the number of cores, determine whether the race actually manifests.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Back | scheduler inter |
<div>The OS thread scheduler's interleaving of instructions, plus timing factors like CPU load, cache state, I/O delays, and the number of cores, determine whether the race actually manifests.</div> |
Note 68: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
NAGc`DO5VT
Before
Front
Work in a task graph is denoted T_1 and equals the sum of the cost of all nodes in the graph.
Back
Work in a task graph is denoted T_1 and equals the sum of the cost of all nodes in the graph.
After
Front
Work in a task graph is denoted \(T_1\) and equals the sum of the cost of all nodes in the graph.
Back
Work in a task graph is denoted \(T_1\) and equals the sum of the cost of all nodes in the graph.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Work}} in a task graph is denoted {{c2::T_1}} and equals the {{c3::sum of the cost of all nodes}} in the graph. | {{c1::Work}} in a task graph is denoted {{c2::\(T_1\)}} and equals the {{c3::sum of the cost of all nodes}} in the graph. |
Note 69: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
O/zmK_*z%;
Previous
Note did not exist
New Note
Front
The four progress conditions, arranged by "who makes progress" \(\times\) "locks?": non-blocking + everyone progresses = wait-free; blocking + everyone progresses = starvation-free; non-blocking + someone progresses = lock-free; blocking + someone progresses = deadlock-free.
Back
The four progress conditions, arranged by "who makes progress" \(\times\) "locks?": non-blocking + everyone progresses = wait-free; blocking + everyone progresses = starvation-free; non-blocking + someone progresses = lock-free; blocking + someone progresses = deadlock-free.
The rows match: lock-free is the non-blocking counterpart of deadlock-free, wait-free is the non-blocking counterpart of starvation-free.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The four progress conditions, arranged by "who makes progress" \(\times\) "locks?": non-blocking + everyone progresses = {{c1::wait-free}}; blocking + everyone progresses = {{c2::starvation-free}}; non-blocking + someone progresses = {{c3::lock-free}}; blocking + someone progresses = {{c4::deadlock-free}}. | |
| Extra | The rows match: lock-free is the non-blocking counterpart of deadlock-free, wait-free is the non-blocking counterpart of starvation-free. |
Note 70: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
O4Kr
Previous
Note did not exist
New Note
Front
Concrete two-step lock-free
remove(c), where each node's next field is an AtomicMarkableReference: 1. try to set the mark on c.next (c.next.attemptMark(d, true)) 2. try CAS on b.next: expected: [reference=c, mark=unmarked] new: [reference=d, mark=unmarked]Both steps are "try to" because either CAS may fail if a concurrent thread has changed the relevant field in the meantime. On failure of step 1, another thread already marked or modified
c; restart the operation; on failure of step 2, b is no longer c's predecessor; the physical unlinking can be left to a later traversal that encounters the marked node.Back
Concrete two-step lock-free
remove(c), where each node's next field is an AtomicMarkableReference: 1. try to set the mark on c.next (c.next.attemptMark(d, true)) 2. try CAS on b.next: expected: [reference=c, mark=unmarked] new: [reference=d, mark=unmarked]Both steps are "try to" because either CAS may fail if a concurrent thread has changed the relevant field in the meantime. On failure of step 1, another thread already marked or modified
c; restart the operation; on failure of step 2, b is no longer c's predecessor; the physical unlinking can be left to a later traversal that encounters the marked node.This is the core lock-free pattern: each thread that walks the list and stumbles over a marked node helps unlink it ("helping"). That property is what gives the algorithm its lock-freedom guarantee.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Concrete two-step lock-free <code>remove(c)</code>, where each node's <code>next</code> field is an <code>AtomicMarkableReference</code>: <pre>1. try to set the mark on c.next (c.next.attemptMark(d, true)) 2. try CAS on b.next: expected: [reference=c, mark=unmarked] new: [reference=d, mark=unmarked]</pre> Both steps are "try to" because {{c1::either CAS may fail if a concurrent thread has changed the relevant field in the meantime}}. On failure of step 1, {{c2::another thread already marked or modified <code>c</code>; restart the operation}}; on failure of step 2, {{c3::<code>b</code> is no longer <code>c</code>'s predecessor; the physical unlinking can be left to a later traversal that encounters the marked node}}. | |
| Extra | This is the core lock-free pattern: each thread that walks the list and stumbles over a marked node helps unlink it ("helping"). That property is what gives the algorithm its lock-freedom guarantee. |
Note 71: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
PL8n[tJah;
Before
Front
In order to perform optimally, the JVM often needs warm-up time to 'learn' what kind of code is typically being executed.
Back
In order to perform optimally, the JVM often needs warm-up time to 'learn' what kind of code is typically being executed.
This applies especially to the ForkJoin framework, which needs some time to optimally distribute tasks on threads.
After
Front
In order to perform optimally, the JVM often needs warm-up time to 'learn' what kind of code is typically being executed.
Back
In order to perform optimally, the JVM often needs warm-up time to 'learn' what kind of code is typically being executed.
This applies especially to the ForkJoin framework, which needs some time to optimally distribute tasks on threads.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | In order to perform optimally, the JVM often needs {{c1::warm-up |
In order to perform optimally, the JVM often needs {{c1::warm-up time to 'learn' what kind of code is typically being executed}}. |
Note 72: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
UV4l}f1eC(
Previous
Note did not exist
New Note
Front
Concurrent
remove(c) by A and remove(b) by B on a lock-free list with AtomicMarkableReference: both threads first mark their victim's next. When B then tries the DCAS a.next.CAS([b, unmarked], [c, unmarked]), it fails, because b.next is now marked (no longer matches the expected unmarked). The outcome: c remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries.Back
Concurrent
remove(c) by A and remove(b) by B on a lock-free list with AtomicMarkableReference: both threads first mark their victim's next. When B then tries the DCAS a.next.CAS([b, unmarked], [c, unmarked]), it fails, because b.next is now marked (no longer matches the expected unmarked). The outcome: c remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries.This is the core observation: the mark bit on
b.next is what protects c from being silently "un-deleted" by a concurrent operation on the predecessor. The DCAS over (reference, mark) ties the two together.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Concurrent <code>remove(c)</code> by A and <code>remove(b)</code> by B on a lock-free list with <code>AtomicMarkableReference</code>: both threads first mark their victim's <code>next</code>. When B then tries the DCAS <code>a.next.CAS([b, unmarked], [c, unmarked])</code>, it {{c1::fails, because <code>b.next</code> is now <em>marked</em> (no longer matches the expected <code>unmarked</code>)}}. The outcome: {{c2::<code>c</code> remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries}}. | |
| Extra | This is the core observation: the mark bit on <code>b.next</code> is what protects <code>c</code> from being silently "un-deleted" by a concurrent operation on the predecessor. The DCAS over (reference, mark) ties the two together. |
Note 73: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
UdYi6ee,)?
Previous
Note did not exist
New Note
Front
Even with a sentinel, an enqueue still updates two pointers (
tail.next then tail), so tail may transiently fail to point to the last element. Making other threads wait for the enqueuer to fix this would be locking in disguise (a thread that dies between the two updates would stall everyone). Resolution: other threads help by advancing tail themselves when they observe it is lagging behind.Back
Even with a sentinel, an enqueue still updates two pointers (
tail.next then tail), so tail may transiently fail to point to the last element. Making other threads wait for the enqueuer to fix this would be locking in disguise (a thread that dies between the two updates would stall everyone). Resolution: other threads help by advancing tail themselves when they observe it is lagging behind.This is the same helping pattern as in the lock-free list-set: an inconsistency that any thread is allowed to repair preserves lock-freedom; an inconsistency that only one specific thread can repair does not.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Even with a sentinel, an enqueue still updates two pointers (<code>tail.next</code> then <code>tail</code>), so <code>tail</code> may {{c1::transiently fail to point to the last element}}. Making other threads wait for the enqueuer to fix this would be {{c2::locking in disguise (a thread that dies between the two updates would stall everyone)}}. Resolution: {{c3::other threads <em>help</em> by advancing <code>tail</code> themselves when they observe it is lagging behind}}. | |
| Extra | This is the same helping pattern as in the lock-free list-set: an inconsistency that any thread is allowed to repair preserves lock-freedom; an inconsistency that only one specific thread can repair does not. |
Note 74: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
X#]/;rXP;n
Previous
Note did not exist
New Note
Front
contains(x) on the lazy skip list is wait-free. It returns true iff a sequential find located x, the node is not logically removed (marked), and the node is fully linked. Even if other nodes are concurrently being removed, a fully linked unmarked target stays reachable.Back
contains(x) on the lazy skip list is wait-free. It returns true iff a sequential find located x, the node is not logically removed (marked), and the node is fully linked. Even if other nodes are concurrently being removed, a fully linked unmarked target stays reachable.Two flags are needed (unlike the single-level lazy list): marked certifies "not yet removed" and fully linked certifies "already inserted at every level". Without the fully linked check,
contains could observe a half-spliced node.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <code>contains(x)</code> on the lazy skip list is {{c1::wait-free}}. It returns <code>true</code> iff a sequential <code>find</code> located <code>x</code>, {{c2::the node is not logically removed (marked)}}, and {{c3::the node is fully linked}}. Even if other nodes are concurrently being removed, a fully linked unmarked target stays reachable. | |
| Extra | Two flags are needed (unlike the single-level lazy list): <em>marked</em> certifies "not yet removed" and <em>fully linked</em> certifies "already inserted at every level". Without the <em>fully linked</em> check, <code>contains</code> could observe a half-spliced node. |
Note 75: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
XuC3?Q]l$v
Previous
Note did not exist
New Note
Front
A naive linked-list queue with
head and tail pointers cannot be made lock-free directly because three locations are updated concurrently: head, tail, and tail.next. A single CAS cannot commit all three atomically.Back
A naive linked-list queue with
head and tail pointers cannot be made lock-free directly because three locations are updated concurrently: head, tail, and tail.next. A single CAS cannot commit all three atomically.Two design ideas resolve this: (1) add a persistent sentinel at the front so
head and tail never alias the same "empty" cell, and (2) split each operation into smaller CAS-able steps, with traversing threads helping to advance any pointer that is lagging behind.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A naive linked-list queue with <code>head</code> and <code>tail</code> pointers cannot be made lock-free directly because three locations are updated concurrently: {{c1::<code>head</code>}}, {{c1::<code>tail</code>}}, and {{c1::<code>tail.next</code>}}. A single CAS cannot commit all three atomically. | |
| Extra | Two design ideas resolve this: (1) add a persistent sentinel at the front so <code>head</code> and <code>tail</code> never alias the same "empty" cell, and (2) split each operation into smaller CAS-able steps, with traversing threads <em>helping</em> to advance any pointer that is lagging behind. |
Note 76: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
[kD44j4d18
Previous
Note did not exist
New Note
Front
Motivation for a lock-free unbounded queue: the scheduling queues at the heart of an OS kernel (ready / waiting-for-x / waiting-for-y) are accessed concurrently by threads and interrupt service routines on different cores, and using (spin)locks for protection creates the usual problems (BKL-style scalability disasters). Going lock-free here brings two specific new challenges: transient inconsistencies during multi-pointer updates, and without garbage collection the kernel must reuse queue nodes, which opens the door to the ABA problem.
Back
Motivation for a lock-free unbounded queue: the scheduling queues at the heart of an OS kernel (ready / waiting-for-x / waiting-for-y) are accessed concurrently by threads and interrupt service routines on different cores, and using (spin)locks for protection creates the usual problems (BKL-style scalability disasters). Going lock-free here brings two specific new challenges: transient inconsistencies during multi-pointer updates, and without garbage collection the kernel must reuse queue nodes, which opens the door to the ABA problem.
This is the canonical motivating story for the Michael-Scott queue and for ABA: the Linux Big Kernel Lock (BKL) was a single coarse-grained spinlock and was eventually removed precisely because of its scalability problems.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Motivation for a lock-free unbounded queue: the scheduling queues at the heart of an OS kernel (ready / waiting-for-x / waiting-for-y) are accessed concurrently by {{c1::threads and interrupt service routines on different cores}}, and using (spin)locks for protection creates the usual problems (BKL-style scalability disasters). Going lock-free here brings two specific new challenges: {{c2::transient inconsistencies during multi-pointer updates}}, and {{c3::without garbage collection the kernel must reuse queue nodes, which opens the door to the ABA problem}}. | |
| Extra | This is the canonical motivating story for the Michael-Scott queue and for ABA: the Linux Big Kernel Lock (BKL) was a single coarse-grained spinlock and was eventually removed precisely because of its scalability problems. |
Note 77: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
]zEJ,F=ap5
Previous
Note did not exist
New Note
Front
The standard CAS update pattern (here for an
AtomicInteger counter): int v;
do {
v = value.get(); // (a) read current
} while (!value.compareAndSet(v, v+1)); // (b) compute v'; (c) CAS; (d) return on success
return v+1; A successful CAS suggests (not guarantees) that no other thread has written between (a) and (c). If a thread dies inside the loop, other threads are unaffected and continue to make progress, and if two threads see the same v, exactly one CAS succeeds, the other one retries.Back
The standard CAS update pattern (here for an
AtomicInteger counter): int v;
do {
v = value.get(); // (a) read current
} while (!value.compareAndSet(v, v+1)); // (b) compute v'; (c) CAS; (d) return on success
return v+1; A successful CAS suggests (not guarantees) that no other thread has written between (a) and (c). If a thread dies inside the loop, other threads are unaffected and continue to make progress, and if two threads see the same v, exactly one CAS succeeds, the other one retries.This is the canonical lock-free read-modify-write pattern. The reason for "suggests, not guarantees" is the ABA problem: a value can be changed and changed back between (a) and (c), and CAS cannot tell the difference.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The standard CAS update pattern (here for an <code>AtomicInteger</code> counter): <pre>int v; do { v = value.get(); // (a) read current } while (!value.compareAndSet(v, v+1)); // (b) compute v'; (c) CAS; (d) return on success return v+1;</pre> A successful CAS {{c1::<em>suggests</em> (not guarantees) that no other thread has written between (a) and (c)}}. If a thread dies inside the loop, other threads {{c2::are unaffected and continue to make progress}}, and if two threads see the same <code>v</code>, {{c3::exactly one CAS succeeds, the other one retries}}. | |
| Extra | This is the canonical lock-free read-modify-write pattern. The reason for "suggests, not guarantees" is the ABA problem: a value can be changed and changed back between (a) and (c), and CAS cannot tell the difference. |
Note 78: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
`@a6%d`j41
Previous
Note did not exist
New Note
Front
Why the first CAS of the lock-free enqueue (
CAS(last.next, null, new)) can fail: another thread wrote last.next just before me, or I read a stale tail -- either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing tail. Conclusion: if my CAS fails, I should not blindly retry on the same last; I must re-read tail first.Back
Why the first CAS of the lock-free enqueue (
CAS(last.next, null, new)) can fail: another thread wrote last.next just before me, or I read a stale tail -- either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing tail. Conclusion: if my CAS fails, I should not blindly retry on the same last; I must re-read tail first.Case (c3) is exactly the scenario that forces helping in the final version: a future dequeuer or enqueuer must be willing to advance
tail on behalf of a thread that may never return.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Why the first CAS of the lock-free enqueue (<code>CAS(last.next, null, new)</code>) can fail: {{c1::another thread wrote <code>last.next</code> just before me}}, or {{c2::I read a stale <code>tail</code>}} -- either because I missed an update or {{c3::because some earlier enqueuer failed (e.g. died) before advancing <code>tail</code>}}. Conclusion: if my CAS fails, {{c4::I should not blindly retry on the same <code>last</code>; I must re-read <code>tail</code> first}}. | |
| Extra | Case (c3) is exactly the scenario that forces helping in the final version: a future dequeuer or enqueuer must be willing to advance <code>tail</code> on behalf of a thread that may never return. |
Note 79: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
`C;b_
Previous
Note did not exist
New Note
Front
Reasons to look beyond locks. They are pessimistic by design: mutual exclusion is enforced even when no real conflict would occur; they impose overhead in every call, even uncontended ones, and degrade badly under contention (Amdahl); and their blocking semantics mean that if one thread is delayed or dies inside the critical section, all others stall. They are also prone to deadlocks and livelocks and, without precautions, cannot be used inside interrupt handlers.
Back
Reasons to look beyond locks. They are pessimistic by design: mutual exclusion is enforced even when no real conflict would occur; they impose overhead in every call, even uncontended ones, and degrade badly under contention (Amdahl); and their blocking semantics mean that if one thread is delayed or dies inside the critical section, all others stall. They are also prone to deadlocks and livelocks and, without precautions, cannot be used inside interrupt handlers.
These five points together motivate non-blocking (lock-free / wait-free) data structures: progress should not depend on any one thread continuing to execute.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Reasons to look beyond locks. They are {{c1::pessimistic by design: mutual exclusion is enforced even when no real conflict would occur}}; they impose {{c2::overhead in every call, even uncontended ones, and degrade badly under contention (Amdahl)}}; and their blocking semantics mean that {{c3::if one thread is delayed or dies inside the critical section, all others stall}}. They are also prone to {{c4::deadlocks and livelocks}} and, without precautions, {{c5::cannot be used inside interrupt handlers}}. | |
| Extra | These five points together motivate non-blocking (lock-free / wait-free) data structures: progress should not depend on any one thread continuing to execute. |
Note 80: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
`uVge9(G(!
Previous
Note did not exist
New Note
Front
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: finish the job, i.e.
CAS the predecessor's next field past the marked node and continue (repeating as needed if more marked nodes follow).Back
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: finish the job, i.e.
CAS the predecessor's next field past the marked node and continue (repeating as needed if more marked nodes follow).This is the canonical helping pattern: every traverser shares responsibility for completing the physical-delete step that another thread left half-done. Without it, a thread that died right after step 1 of
remove would leave a marked node in the list forever, which would not violate correctness, but would degrade performance and is incompatible with practical use.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: {{c1::finish the job}}, i.e. {{c2::<code>CAS</code> the predecessor's <code>next</code> field past the marked node}} and {{c3::continue (repeating as needed if more marked nodes follow)}}. | |
| Extra | This is the canonical <em>helping</em> pattern: every traverser shares responsibility for completing the physical-delete step that another thread left half-done. Without it, a thread that died right after step 1 of <code>remove</code> would leave a marked node in the list forever, which would not violate correctness, but would degrade performance and is incompatible with practical use. |
Note 81: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
b7fM8L_JYH
Previous
Note did not exist
New Note
Front
Two progress conditions for non-blocking algorithms: lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation); wait-freedom: every thread eventually makes progress (implies freedom from starvation). Wait-freedom is strictly stronger than lock-freedom.
Back
Two progress conditions for non-blocking algorithms: lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation); wait-freedom: every thread eventually makes progress (implies freedom from starvation). Wait-freedom is strictly stronger than lock-freedom.
"Implies" here is the standard arrow: every wait-free algorithm is automatically lock-free, but not vice versa.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Two progress conditions for non-blocking algorithms: {{c1::lock-freedom}}: {{c2::at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation)}}; {{c3::wait-freedom}}: {{c4::every thread eventually makes progress (implies freedom from starvation)}}. Wait-freedom is strictly stronger than lock-freedom. | |
| Extra | "Implies" here is the standard arrow: every wait-free algorithm is automatically lock-free, but not vice versa. |
Note 82: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Classic
GUID:
modified
Note Type: Horvath Classic
GUID:
buqWa{Q2-l
Before
Front
What is the tradeoff between busy-waiting and blocking?
Back
What is the tradeoff between busy-waiting and blocking?
busy waiting uses up CPU time, whereas blocking may cause additional context switches
After
Front
What is the tradeoff between busy-waiting and blocking?
Back
What is the tradeoff between busy-waiting and blocking?
Busy-waiting has low latency to wake up but wastes CPU cycles; blocking frees the CPU for other work but incurs context-switch overhead, making busy-waiting better for very short waits and blocking better for longer ones.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Back | <div>Busy-waiting has low latency to wake up but wastes CPU cycles; blocking frees the CPU for other work but incurs context-switch overhead, making busy-waiting better for very short waits and blocking better for longer ones.</div> |
Note 83: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
b{kg%0Ane{
Before
Front
Work partitioning is the split-up of a program into smaller tasks that can be executed in parallel.
Back
Work partitioning is the split-up of a program into smaller tasks that can be executed in parallel.
After
Front
Work partitioning is the split-up of a program into smaller tasks that can be executed in parallel.
Back
Work partitioning is the split-up of a program into smaller tasks that can be executed in parallel.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Work partitioning}} is |
{{c1::Work partitioning}} is {{c2::the split-up of a program into smaller tasks that can be executed in parallel}}. |
Note 84: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
c+k1>KVqs:
Previous
Note did not exist
New Note
Front
Final Michael-Scott
enqueue: Node node = new Node(item);
while (true) {
Node last = tail.get();
Node next = last.next.get();
if (next == null) {
if (last.next.compareAndSet(null, node)) {
tail.compareAndSet(last, node); // try to swing tail
return;
}
} else {
tail.compareAndSet(last, next); // help advance tail
}
} The else branch is the helping step: if tail.next != null, some other enqueuer is mid-operation, so this thread advances tail on its behalf before retrying.Back
Final Michael-Scott
enqueue: Node node = new Node(item);
while (true) {
Node last = tail.get();
Node next = last.next.get();
if (next == null) {
if (last.next.compareAndSet(null, node)) {
tail.compareAndSet(last, node); // try to swing tail
return;
}
} else {
tail.compareAndSet(last, next); // help advance tail
}
} The else branch is the helping step: if tail.next != null, some other enqueuer is mid-operation, so this thread advances tail on its behalf before retrying.The two
compareAndSet calls on tail (in the success branch and in the helping branch) both deliberately ignore their return value: if some other thread has already done the swing, that's fine.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Final Michael-Scott <code>enqueue</code>: <pre>Node node = new Node(item); while (true) { Node last = tail.get(); Node next = last.next.get(); if (next == null) { if (last.next.compareAndSet(null, node)) { tail.compareAndSet(last, node); // try to swing tail return; } } else { tail.compareAndSet(last, next); // help advance tail } }</pre> The <code>else</code> branch is the {{c1::helping step}}: if <code>tail.next != null</code>, some other enqueuer is mid-operation, so this thread {{c2::advances <code>tail</code> on its behalf before retrying}}. | |
| Extra | The two <code>compareAndSet</code> calls on <code>tail</code> (in the success branch and in the helping branch) both deliberately ignore their return value: if some other thread has already done the swing, that's fine. |
Note 85: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
e@.#qnN#(e
Before
Front
Multiprocessing (or multitasking) is the concurrent execution of multiple tasks/processes, typically referring to parallelism on the operating system level.
Back
Multiprocessing (or multitasking) is the concurrent execution of multiple tasks/processes, typically referring to parallelism on the operating system level.
After
Front
Multiprocessing (or multitasking) is the concurrent execution of multiple tasks/processes, typically referring to parallelism on the operating system level.
Back
Multiprocessing (or multitasking) is the concurrent execution of multiple tasks/processes, typically referring to parallelism on the operating system level.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Multiprocessing |
{{c1::Multiprocessing (or multitasking)}} is {{c2::the concurrent execution of multiple tasks/processes, typically referring to parallelism on the operating system level}}. |
Note 86: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
eYjiQvphJf
Previous
Note did not exist
New Note
Front
Searching a skip list takes \(O(\log n)\) time with high probability. The search starts at the top level of the head sentinel, walks right while the next key is less than the target, then drops down one level when the next key is too large or is \(+\infty\).
Back
Searching a skip list takes \(O(\log n)\) time with high probability. The search starts at the top level of the head sentinel, walks right while the next key is less than the target, then drops down one level when the next key is too large or is \(+\infty\).
The expected search length per level is constant because of the geometric height distribution, and the number of levels is \(O(\log n)\) w.h.p.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Searching a skip list takes {{c1::\(O(\log n)\) time with high probability}}. The search starts at {{c2::the top level of the head sentinel}}, walks right while the next key is less than the target, then drops down one level when the next key is too large or is \(+\infty\). | |
| Extra | The expected search length per level is constant because of the geometric height distribution, and the number of levels is \(O(\log n)\) w.h.p. |
Note 87: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
gX9o]qJfQD
Before
Front
Code can be vectorised automatically, by compilers, or manually, by using intrinsics libraries provided by hardware vendors.
Back
Code can be vectorised automatically, by compilers, or manually, by using intrinsics libraries provided by hardware vendors.
After
Front
Code can be vectorised automatically, by compilers, or manually, by using intrinsics libraries provided by hardware vendors.
Back
Code can be vectorised automatically, by compilers, or manually, by using intrinsics libraries provided by hardware vendors.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Code can be vectorised {{c1::automatically, by compilers}}, or {{c2::manually, by using intrinsics libraries |
Code can be vectorised {{c1::automatically, by compilers}}, or {{c2::manually, by using intrinsics libraries provided by hardware vendors}}. |
Note 88: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
glVh:^#cYn
Before
Front
A statement is abstractly atomic if it appears atomic at a certain level of abstraction, but may take several steps at a lower level.
Back
A statement is abstractly atomic if it appears atomic at a certain level of abstraction, but may take several steps at a lower level.
E.g.
synchronized append(x) appears as one step to the caller, but not to the queue itself.After
Front
A statement is abstractly atomic if it appears atomic at a certain level of abstraction, but may take several steps at a lower level.
Back
A statement is abstractly atomic if it appears atomic at a certain level of abstraction, but may take several steps at a lower level.
E.g.
synchronized append(x) appears as one step to the caller, but not to the queue itself.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A statement is {{c1::abstractly atomic}} if |
A statement is {{c1::abstractly atomic}} if {{c2::it appears atomic at a certain level of abstraction, but may take several steps at a lower level}}. |
Note 89: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
iKAC-UBBQ1
Before
Front
Cache coherence protocols are hardware protocols that ensure consistency across caches, typically by tracking which locations are cached, and synchronising them if necessary.
Back
Cache coherence protocols are hardware protocols that ensure consistency across caches, typically by tracking which locations are cached, and synchronising them if necessary.
After
Front
Cache coherence protocols are hardware protocols that ensure consistency across caches, typically by tracking which locations are cached, and synchronising them if necessary.
Back
Cache coherence protocols are hardware protocols that ensure consistency across caches, typically by tracking which locations are cached, and synchronising them if necessary.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Cache coherence protocols}} are hardware protocols that {{c2::ensure consistency across caches |
{{c1::Cache coherence protocols}} are hardware protocols that {{c2::ensure consistency across caches, typically by tracking which locations are cached, and synchronising them if necessary}}. |
Note 90: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
lL_$?<@pF+
Before
Front
S_p means speedup with p processors
Back
S_p means speedup with p processors
After
Front
\(S_p\) means speedup with \(p\) processors.
Back
\(S_p\) means speedup with \(p\) processors.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::S_p}} means {{c2::speedup |
{{c1::\(S_p\)}} means {{c2::speedup with \(p\) processors}}. |
Note 91: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
lQ>g2Nf<##
Previous
Note did not exist
New Note
Front
Six steps of
add on the lazy skip list: find predecessors (lock-free traversal), lock the predecessors on every level the new node will occupy, validate (as in lazy synchronisation: predecessors unmarked and still linked to their successors), splice the new node in at every level (bottom-up), mark the node as fully linked, then unlock all predecessors.Back
Six steps of
add on the lazy skip list: find predecessors (lock-free traversal), lock the predecessors on every level the new node will occupy, validate (as in lazy synchronisation: predecessors unmarked and still linked to their successors), splice the new node in at every level (bottom-up), mark the node as fully linked, then unlock all predecessors.The fully linked flag plays the same role here that the unmarked-flag plays in the lazy list: it certifies that a concurrent
contains may rely on this node.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Six steps of <code>add</code> on the lazy skip list: {{c1::find predecessors (lock-free traversal)}}, {{c2::lock the predecessors on every level the new node will occupy}}, {{c3::validate (as in lazy synchronisation: predecessors unmarked and still linked to their successors)}}, {{c4::splice the new node in at every level (bottom-up)}}, {{c5::mark the node as <em>fully linked</em>}}, then {{c6::unlock all predecessors}}. | |
| Extra | The <em>fully linked</em> flag plays the same role here that the unmarked-flag plays in the lazy list: it certifies that a concurrent <code>contains</code> may rely on this node. |
Note 92: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
l{B3CynHyc
Before
Front
Process context is all state associated with a process
Back
Process context is all state associated with a process
this includes CPU state (registers, program counter), program state (stack, heap, resource handles) and additional management information
After
Front
Process context is all state associated with a process.
Back
Process context is all state associated with a process.
this includes CPU state (registers, program counter), program state (stack, heap, resource handles) and additional management information
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Process context}} is all state associated with a process | {{c1::Process context}} is all state associated with a process. |
Note 93: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
m$HzW2de@M
Before
Front
CISC stands for Complex Instruction Set Computer. A fundamental CPU architecture model with complex, feature-rich instructions.
Back
CISC stands for Complex Instruction Set Computer. A fundamental CPU architecture model with complex, feature-rich instructions.
After
Front
CISC stands for Complex Instruction Set Computer.
Back
CISC stands for Complex Instruction Set Computer.
A fundamental CPU architecture model with complex, feature-rich instructions.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | CISC stands for {{c1::Complex Instruction Set Computer}}. | |
| Extra | A fundamental CPU architecture model with complex, feature-rich instructions. |
Note 94: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
m7?!UWmaST
Before
Front
Throughput is an evaluation metric for pipelines that measures the amount of work that can be done by a pipeline in a given period of time.
Back
Throughput is an evaluation metric for pipelines that measures the amount of work that can be done by a pipeline in a given period of time.
e.g. CPU instructions
After
Front
Throughput is an evaluation metric for pipelines that measures the amount of work that can be done by a pipeline in a given period of time.
Back
Throughput is an evaluation metric for pipelines that measures the amount of work that can be done by a pipeline in a given period of time.
e.g. CPU instructions
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Throughput}} is an evaluation metric for pipelines that measures |
{{c1::Throughput}} is {{c2::an evaluation metric for pipelines that measures the amount of work that can be done by a pipeline in a given period of time}}. |
Note 95: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
m_S%MN-kA/
Previous
Note did not exist
New Note
Front
Three lessons from the lock-free list-set construction. DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once. Lazy + open repair: leaving the physical delete "half-done" is fine as long as any thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise. Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes.
Back
Three lessons from the lock-free list-set construction. DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once. Lazy + open repair: leaving the physical delete "half-done" is fine as long as any thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise. Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes.
The third point distinguishes lock-free from wait-free: lock-freedom only requires that some thread makes progress; wait-freedom requires every thread to finish in a bounded number of steps, which in practice means other threads must complete its half-done operations.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Three lessons from the lock-free list-set construction. {{c1::DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once}}. {{c2::Lazy + open repair: leaving the physical delete "half-done" is fine as long as <em>any</em> thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise}}. {{c3::Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes}}. | |
| Extra | The third point distinguishes lock-free from wait-free: lock-freedom only requires that <em>some</em> thread makes progress; wait-freedom requires every thread to finish in a bounded number of steps, which in practice means other threads must complete its half-done operations. |
Note 96: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
ngUGF,o``:
Previous
Note did not exist
New Note
Front
Lock performance has two very different regimes. Uncontended: threads do not compete; a good implementation costs roughly one atomic operation. Contended: threads compete; the result is significant performance degradation and possible starvation.
Back
Lock performance has two very different regimes. Uncontended: threads do not compete; a good implementation costs roughly one atomic operation. Contended: threads compete; the result is significant performance degradation and possible starvation.
Specialised lock implementations (queue locks, backoff locks, MCS, etc.) primarily target the contended regime, while keeping the uncontended cost close to a single CAS.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Lock performance has two very different regimes. {{c1::Uncontended}}: threads do not compete; a good implementation costs {{c2::roughly one atomic operation}}. {{c1::Contended}}: threads compete; the result is {{c3::significant performance degradation and possible starvation}}. | |
| Extra | Specialised lock implementations (queue locks, backoff locks, MCS, etc.) primarily target the contended regime, while keeping the uncontended cost close to a single CAS. |
Note 97: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
o7QwkjA$)F
Previous
Note did not exist
New Note
Front
Four steps of
remove in the lazy list: scan the list (without locks) to find pred and curr, lock pred and curr (hand-over-hand on the two-node window), logical delete: mark curr as deleted, physical delete: redirect pred.next past curr.Back
Four steps of
remove in the lazy list: scan the list (without locks) to find pred and curr, lock pred and curr (hand-over-hand on the two-node window), logical delete: mark curr as deleted, physical delete: redirect pred.next past curr.Marking before unlinking ensures the key invariant: any thread that locks an unmarked node knows it is still reachable.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Four steps of <code>remove</code> in the lazy list: {{c1::scan the list (without locks) to find <code>pred</code> and <code>curr</code>}}, {{c2::lock <code>pred</code> and <code>curr</code> (hand-over-hand on the two-node window)}}, {{c3::logical delete: mark <code>curr</code> as deleted}}, {{c4::physical delete: redirect <code>pred.next</code> past <code>curr</code>}}. | |
| Extra | Marking before unlinking ensures the key invariant: any thread that locks an unmarked node knows it is still reachable. |
Note 98: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
o?%~4t?Q]?
Before
Front
Span is the critical path (height) of the task graph. It corresponds to T_∞.
Back
Span is the critical path (height) of the task graph. It corresponds to T_∞.
After
Front
Span is the critical path (height) of the task graph.
It corresponds to \(T_∞\).
It corresponds to \(T_∞\).
Back
Span is the critical path (height) of the task graph.
It corresponds to \(T_∞\).
It corresponds to \(T_∞\).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Span}} is |
{{c1::Span}} is {{c2::the critical path (height) of the task graph}}. <br><br>It corresponds to {{c3::\(T_∞\)}}. |
Note 99: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
oc}?&fK}O8
Before
Front
RISC stands for Reduced Instruction Set Computer. A fundamental CPU architecture model. Classical RISC is simpler: RISC instructions can only work on registers, and reading/writing memory are separate instructions.
Back
RISC stands for Reduced Instruction Set Computer. A fundamental CPU architecture model. Classical RISC is simpler: RISC instructions can only work on registers, and reading/writing memory are separate instructions.
After
Front
RISC stands for Reduced Instruction Set Computer.
Back
RISC stands for Reduced Instruction Set Computer.
A fundamental CPU architecture model.
Classical RISC is simpler: RISC instructions can only work on registers, and reading/writing memory are separate instructions.
Classical RISC is simpler: RISC instructions can only work on registers, and reading/writing memory are separate instructions.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | RISC stands for {{c1::Reduced Instruction Set Computer}}. | |
| Extra | A fundamental CPU architecture model. <br><br>Classical RISC is simpler: RISC instructions can only work on registers, and reading/writing memory are separate instructions. |
Note 100: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
orPo?8l!zc
Before
Front
A task graph is a graph (DAG) created by drawing nodes (tasks) and edges (spawns, joins).
Back
A task graph is a graph (DAG) created by drawing nodes (tasks) and edges (spawns, joins).
After
Front
A task graph is a graph (DAG) created by drawing nodes (tasks) and edges (spawns, joins).
Back
A task graph is a graph (DAG) created by drawing nodes (tasks) and edges (spawns, joins).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A {{c1::task graph}} is a graph ( |
A {{c1::task graph}} is a graph (DAG) created by drawing {{c2::nodes (tasks) and edges (spawns, joins)}}. |
Note 101: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
pOel:.8@{W
Previous
Note did not exist
New Note
Front
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. Scenario: thread A runs
remove(c) as CAS(c.mark, false, true) then CAS(b.next, c, d), while thread B runs add(c') after c as CAS(c.next, d, c'). The result: c' is appended to c, but c is then unlinked, so c' is silently lost.Back
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. Scenario: thread A runs
remove(c) as CAS(c.mark, false, true) then CAS(b.next, c, d), while thread B runs add(c') after c as CAS(c.next, d, c'). The result: c' is appended to c, but c is then unlinked, so c' is silently lost.The lesson: the mark bit and the next-pointer must be updated together, atomically, otherwise an inserter can splice onto a node that is about to be unlinked.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. Scenario: thread A runs <code>remove(c)</code> as {{c1::<code>CAS(c.mark, false, true)</code> then <code>CAS(b.next, c, d)</code>}}, while thread B runs <code>add(c')</code> after <code>c</code> as {{c2::<code>CAS(c.next, d, c')</code>}}. The result: {{c3::<code>c'</code> is appended to <code>c</code>, but <code>c</code> is then unlinked, so <code>c'</code> is silently lost}}. | |
| Extra | The lesson: the mark bit and the next-pointer must be updated <em>together</em>, atomically, otherwise an inserter can splice onto a node that is about to be unlinked. |
Note 102: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
q5sPBXAN&z
Before
Front
Instruction level parallelism (ILP) is CPU-internal parallelisation of independent instructions, with the goal of improving performance by increasing utilisation of a CPU's functional units.
Back
Instruction level parallelism (ILP) is CPU-internal parallelisation of independent instructions, with the goal of improving performance by increasing utilisation of a CPU's functional units.
After
Front
Instruction level parallelism (ILP) is CPU-internal parallelisation of independent instructions, with the goal of improving performance by increasing utilisation of a CPU's functional units.
Back
Instruction level parallelism (ILP) is CPU-internal parallelisation of independent instructions, with the goal of improving performance by increasing utilisation of a CPU's functional units.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | {{c1::Instruction level parallelism (ILP)}} is {{c2::CPU-internal parallelisation |
{{c1::Instruction level parallelism (ILP)}} is {{c2::CPU-internal parallelisation of independent instructions}}, with the goal of improving performance by {{c3::increasing utilisation of a CPU's functional units}}. |
Note 103: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
q=mQ8Za9W-
Previous
Note did not exist
New Note
Front
A second transient inconsistency in the lock-free queue. Thread A enqueues into an empty queue: it writes
sentinel.next = new but has not yet updated tail. Thread B then dequeues, advancing head past the sentinel onto new. Now tail still points to the original sentinel, which has just been removed from the queue. Without helping this is unrecoverable; the final algorithm fixes it by having any thread that observes tail.next != null attempt CAS(tail, tail, tail.next) to drag tail forward.Back
A second transient inconsistency in the lock-free queue. Thread A enqueues into an empty queue: it writes
sentinel.next = new but has not yet updated tail. Thread B then dequeues, advancing head past the sentinel onto new. Now tail still points to the original sentinel, which has just been removed from the queue. Without helping this is unrecoverable; the final algorithm fixes it by having any thread that observes tail.next != null attempt CAS(tail, tail, tail.next) to drag tail forward.This is why the final dequeue code, before doing the actual dequeue, checks
if (first == last) and, if so, helps advance tail.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A second transient inconsistency in the lock-free queue. Thread A enqueues into an empty queue: it writes <code>sentinel.next = new</code> but has not yet updated <code>tail</code>. Thread B then dequeues, advancing <code>head</code> past the sentinel onto <code>new</code>. Now {{c1::<code>tail</code> still points to the original sentinel, which has just been removed from the queue}}. Without helping this is unrecoverable; the final algorithm fixes it by {{c2::having any thread that observes <code>tail.next != null</code> attempt <code>CAS(tail, tail, tail.next)</code> to drag <code>tail</code> forward}}. | |
| Extra | This is why the final dequeue code, before doing the actual dequeue, checks <code>if (first == last)</code> and, if so, helps advance <code>tail</code>. |
Note 104: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
qEgTjb0lpA
Before
Front
The sequential part is the part of a given program that can't be executed in parallel. It limits the maximum speedup.
Back
The sequential part is the part of a given program that can't be executed in parallel. It limits the maximum speedup.
After
Front
The sequential part is the part of a given program that can't be executed in parallel.
Back
The sequential part is the part of a given program that can't be executed in parallel.
It limits the maximum speedup.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The {{c1::sequential part}} is the part of a given program that {{c2::can't be executed in parallel}}. |
The {{c1::sequential part}} is the part of a given program that {{c2::can't be executed in parallel}}. |
| Extra | It limits the maximum speedup. |
Note 105: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
qWB`2aaYqS
Before
Front
\(S_p\) measures how much faster a program runs using p processors, compared to running the sequential version of the same program.
Back
\(S_p\) measures how much faster a program runs using p processors, compared to running the sequential version of the same program.
After
Front
\(S_p\) measures how much faster a program runs using \(p\) processors, compared to running the sequential version of the same program.
Back
\(S_p\) measures how much faster a program runs using \(p\) processors, compared to running the sequential version of the same program.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | \(S_p\) measures how much faster a program runs using |
\(S_p\) measures how much faster a program runs using \(p\) processors, compared to running the {{c1::sequential version}} of the same program. |
Note 106: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
qu=oxqpTpf
Before
Front
The concept of threads exists on various levels:hardware (CPU), operating systems, programming languages.
Back
The concept of threads exists on various levels:hardware (CPU), operating systems, programming languages.
In Java, thread also refers to an instance of the
Thread class.After
Front
The concept of threads exists on various levels: hardware (CPU), operating systems, programming languages.
Back
The concept of threads exists on various levels: hardware (CPU), operating systems, programming languages.
In Java, thread also refers to an instance of the
Thread class.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The concept of threads exists on various levels:{{c1::hardware (CPU), operating systems, programming languages}}. | The concept of threads exists on various levels: {{c1::hardware (CPU), operating systems, programming languages}}. |
Note 107: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
r=Z+@LUhz[
Previous
Note did not exist
New Note
Front
java.util.concurrent.atomic.AtomicMarkableReference<V> packages a reference and a boolean mark into one atomic cell. Key methods: compareAndSet(expRef, newRef, expMark, newMark): atomic CAS over the (reference, mark) pair; attemptMark(expRef, newMark): CAS the mark only, leaving the reference; get(boolean[] markHolder): read both at once. Implementation trick: steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word.Back
java.util.concurrent.atomic.AtomicMarkableReference<V> packages a reference and a boolean mark into one atomic cell. Key methods: compareAndSet(expRef, newRef, expMark, newMark): atomic CAS over the (reference, mark) pair; attemptMark(expRef, newMark): CAS the mark only, leaving the reference; get(boolean[] markHolder): read both at once. Implementation trick: steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word.The bit-stealing trick relies on object addresses being 8-byte aligned, so the bottom three bits are always zero in a real pointer. Using one of them as a mark costs nothing - the slide jokes that a fully addressable 64-bit space is \(2^{64}\,\text{B} = 5.6 \cdot 10^{14}\,\text{PB}\), so the lost bit is not missed.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | <code>java.util.concurrent.atomic.AtomicMarkableReference<V></code> packages a reference and a boolean mark into one atomic cell. Key methods: {{c1::<code>compareAndSet(expRef, newRef, expMark, newMark)</code>}}: atomic CAS over the (reference, mark) pair; {{c2::<code>attemptMark(expRef, newMark)</code>}}: CAS the mark only, leaving the reference; {{c2::<code>get(boolean[] markHolder)</code>}}: read both at once. Implementation trick: {{c3::steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word}}. | |
| Extra | The bit-stealing trick relies on object addresses being 8-byte aligned, so the bottom three bits are always zero in a real pointer. Using one of them as a mark costs nothing - the slide jokes that a fully addressable 64-bit space is \(2^{64}\,\text{B} = 5.6 \cdot 10^{14}\,\text{PB}\), so the lost bit is not missed. |
Note 108: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
rj]$8hdL3s
Before
Front
S_p = \(T_1/T_p\)
Back
S_p = \(T_1/T_p\)
After
Front
\(S_p\) = \(T_1/T_p\)
Back
\(S_p\) = \(T_1/T_p\)
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | S_p |
\(S_p\) = {{c1::\(T_1/T_p\)}} |
Note 109: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
s.@YR(&3S3
Before
Front
The maximum possible speedup (parallelism) is {{c2::\(\frac{T_1}{T_\infty} \)}}.
Back
The maximum possible speedup (parallelism) is {{c2::\(\frac{T_1}{T_\infty} \)}}.
After
Front
The maximum possible speedup (parallelism) is {{c1::\(\frac{T_1}{T_\infty} \)}}.
Back
The maximum possible speedup (parallelism) is {{c1::\(\frac{T_1}{T_\infty} \)}}.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The maximum possible speedup ( |
The maximum possible speedup (parallelism) is {{c1::\(\frac{T_1}{T_\infty} \)}}. |
Note 110: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
v8kBry=w:T
Before
Front
Locks are typically used to enforce mutual exclusion by guarding/protecting a critical section.
Back
Locks are typically used to enforce mutual exclusion by guarding/protecting a critical section.
After
Front
Locks are typically used to enforce mutual exclusion by guarding/protecting a critical section.
Back
Locks are typically used to enforce mutual exclusion by guarding/protecting a critical section.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Locks are typically used to {{c |
Locks are typically used to {{c1::enforce mutual exclusion by guarding/protecting a critical section}}. |
Note 111: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
xtz_B1$7[Y
Before
Front
With coarse granularity, work is split into large tasks. This reduces overhead, but might not use all available threads.
Back
With coarse granularity, work is split into large tasks. This reduces overhead, but might not use all available threads.
After
Front
With coarse granularity, work is split into large tasks.
Back
With coarse granularity, work is split into large tasks.
This reduces overhead, but might not use all available threads.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | With {{c1::coarse granularity}}, work is split into {{c2::large tasks}}. |
With {{c1::coarse granularity}}, work is split into {{c2::large tasks}}. |
| Extra | This reduces overhead, but might not use all available threads. |
Note 112: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
y:6
Previous
Note did not exist
New Note
Front
Balanced trees (AVL, red-black, treap, ...) are awkward for concurrent sets because rebalancing after
add/remove is expensive and, more importantly, it is a global operation that may touch the entire tree, which makes lock-free implementations particularly hard. Skip lists sidestep this by solving the balancing problem probabilistically (Las Vegas style).Back
Balanced trees (AVL, red-black, treap, ...) are awkward for concurrent sets because rebalancing after
add/remove is expensive and, more importantly, it is a global operation that may touch the entire tree, which makes lock-free implementations particularly hard. Skip lists sidestep this by solving the balancing problem probabilistically (Las Vegas style)."Las Vegas" means: always correct, but the runtime is a random variable. Performance bounds are with high probability rather than worst-case.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Balanced trees (AVL, red-black, treap, ...) are awkward for concurrent sets because {{c1::rebalancing after <code>add</code>/<code>remove</code> is expensive}} and, more importantly, {{c2::it is a <em>global</em> operation that may touch the entire tree}}, which makes lock-free implementations particularly hard. Skip lists sidestep this by solving the balancing problem {{c3::probabilistically (Las Vegas style)}}. | |
| Extra | "Las Vegas" means: always correct, but the runtime is a random variable. Performance bounds are with high probability rather than worst-case. |
Note 113: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
y@3K3O]aTH
Previous
Note did not exist
New Note
Front
A skip list is a sorted multi-level linked list. Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\)}} (geometric distribution), and no rebalancing is ever performed.
Back
A skip list is a sorted multi-level linked list. Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\)}} (geometric distribution), and no rebalancing is ever performed.
The geometric height distribution makes the expected number of nodes at level \(k\) decrease by a factor of two with each level, which is what gives the logarithmic search.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A skip list is a {{c1::sorted multi-level linked list}}. Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\)}} (geometric distribution), and {{c3::no rebalancing is ever performed}}. | |
| Extra | The geometric height distribution makes the expected number of nodes at level \(k\) decrease by a factor of two with each level, which is what gives the logarithmic search. |
Note 114: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
zTH
Previous
Note did not exist
New Note
Front
Design trick for the lock-free queue: introduce a persistent sentinel node at the front. Then enqueuers only ever touch
tail and tail.next, and dequeuers only ever touch head and read head.next; the two sides do not directly contend on the same pointer. Dequeue returns the item carried by head.next (not the sentinel itself), then advances head to that node, which becomes the new sentinel.Back
Design trick for the lock-free queue: introduce a persistent sentinel node at the front. Then enqueuers only ever touch
tail and tail.next, and dequeuers only ever touch head and read head.next; the two sides do not directly contend on the same pointer. Dequeue returns the item carried by head.next (not the sentinel itself), then advances head to that node, which becomes the new sentinel.The sentinel makes the empty-queue case uniform: an empty queue has
head == tail and head.next == null, with no aliasing pathology.Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Design trick for the lock-free queue: introduce a {{c1::persistent sentinel node at the front}}. Then enqueuers only ever touch {{c2::<code>tail</code> and <code>tail.next</code>}}, and dequeuers only ever touch {{c3::<code>head</code> and read <code>head.next</code>}}; the two sides do not directly contend on the same pointer. Dequeue returns the item carried by <code>head.next</code> (not the sentinel itself), then {{c4::advances <code>head</code> to that node, which becomes the new sentinel}}. | |
| Extra | The sentinel makes the empty-queue case uniform: an empty queue has <code>head == tail</code> and <code>head.next == null</code>, with no aliasing pathology. |
Note 115: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
zjY{_
Before
Front
The trick with granularity is to find a size that minimizes overhead while maximizing parallelism.
Back
The trick with granularity is to find a size that minimizes overhead while maximizing parallelism.
After
Front
The trick with granularity is to find a size that minimizes overhead while maximizing parallelism.
Back
The trick with granularity is to find a size that minimizes overhead while maximizing parallelism.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | The trick with {{c1::granularity}} is to find a size that {{c2::minimizes overhead |
The trick with {{c1::granularity}} is to find a size that {{c2::minimizes overhead while maximizing parallelism}}. |
Note 116: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
|*vZdVldU`
Previous
Note did not exist
New Note
Front
A successful CAS only suggests that no other thread has written between the read and the swap, it does not guarantee it. The counterexample is the ABA problem: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A. Stronger alternatives that avoid ABA are LL/SC (and its variants).
Back
A successful CAS only suggests that no other thread has written between the read and the swap, it does not guarantee it. The counterexample is the ABA problem: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A. Stronger alternatives that avoid ABA are LL/SC (and its variants).
Transactional memory has been proposed as a more compositional alternative, but is not yet broadly competitive in practice.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | A successful CAS only {{c1::<em>suggests</em>}} that no other thread has written between the read and the swap, it does not {{c2::guarantee}} it. The counterexample is the {{c3::ABA problem}}: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A. Stronger alternatives that avoid ABA are {{c4::LL/SC (and its variants)}}. | |
| Extra | Transactional memory has been proposed as a more compositional alternative, but is not yet broadly competitive in practice. |
Note 117: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
modified
Note Type: Horvath Cloze
GUID:
|2|f7e7DL}
Before
Front
Number of interleavings for 2 threads with \(k\) statements each: {{c1::\[\binom{2k}{k} = O\!\left(\dfrac{4^k}{\sqrt{2k} }\right) \]}}
Back
Number of interleavings for 2 threads with \(k\) statements each: {{c1::\[\binom{2k}{k} = O\!\left(\dfrac{4^k}{\sqrt{2k} }\right) \]}}
Derivation: the merged trace has length \(2k\). Once we fix which \(k\) of the \(2k\) positions belong to thread 1, the interleaving is determined (sampling without replacement).
After
Front
Number of interleavings for 2 threads with \(k\) statements each: \[{{c1::\binom{2k}{k} = O\!\left(\dfrac{4^k}{\sqrt{2k} }\right) }}\]
Back
Number of interleavings for 2 threads with \(k\) statements each: \[{{c1::\binom{2k}{k} = O\!\left(\dfrac{4^k}{\sqrt{2k} }\right) }}\]
Derivation: the merged trace has length \(2k\). Once we fix which \(k\) of the \(2k\) positions belong to thread 1, the interleaving is determined (sampling without replacement).
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Number of interleavings for 2 threads with \(k\) statements each: {{c1::\ |
Number of interleavings for 2 threads with \(k\) statements each: \[{{c1::\binom{2k}{k} = O\!\left(\dfrac{4^k}{\sqrt{2k} }\right) }}\] |
Note 118: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID:
added
Note Type: Horvath Cloze
GUID:
|MHL/1dHvH
Previous
Note did not exist
New Note
Front
Properties of scheduled (waiting) locks: they require support from the runtime system / OS scheduler, their wakeup latency is higher than a spinlock's (a scheduling round-trip is involved), and their internal queues need their own protection (spinlock or lock-free). A common hybrid is competitive spinning: spin for a bounded duration first, then fall back to rescheduling.
Back
Properties of scheduled (waiting) locks: they require support from the runtime system / OS scheduler, their wakeup latency is higher than a spinlock's (a scheduling round-trip is involved), and their internal queues need their own protection (spinlock or lock-free). A common hybrid is competitive spinning: spin for a bounded duration first, then fall back to rescheduling.
Competitive spinning gets the best of both worlds for short critical sections: low latency when the lock is released quickly, but no CPU burned when the wait turns out to be long.
Field-by-field Comparison
| Field | Before | After |
|---|---|---|
| Text | Properties of scheduled (waiting) locks: {{c1::they require support from the runtime system / OS scheduler}}, {{c2::their wakeup latency is higher than a spinlock's (a scheduling round-trip is involved)}}, and {{c3::their internal queues need their own protection (spinlock or lock-free)}}. A common hybrid is {{c4::<em>competitive spinning</em>: spin for a bounded duration first, then fall back to rescheduling}}. | |
| Extra | Competitive spinning gets the best of both worlds for short critical sections: low latency when the lock is released quickly, but no CPU burned when the wait turns out to be long. |