Note 1: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: %#b6ej?k{S
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Bei einem Monte-Carlo-Algorithmus ist die Korrektheit (bzw. Qualität) eine Zufallsvariable, die Laufzeit hingegen nicht vom Zufall abhängig.
Ziel: immer schnell, meistens korrekt/gut.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Bei einem Monte-Carlo-Algorithmus ist die Korrektheit (bzw. Qualität) eine Zufallsvariable, die Laufzeit hingegen nicht vom Zufall abhängig.
Ziel: immer schnell, meistens korrekt/gut.
Merksatz: Monte-Carlo ist schnell und vielleicht falsch, Las-Vegas ist korrekt und vielleicht langsam.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Bei einem <b>Monte-Carlo-Algorithmus</b> ist {{c1::die Korrektheit (bzw. Qualität)}} eine Zufallsvariable, die {{c1::Laufzeit}} hingegen nicht vom Zufall abhängig.<br><br>Ziel: {{c2::immer schnell, meistens korrekt/gut}}. |
| Extra |
|
Merksatz: Monte-Carlo ist <i>schnell und vielleicht falsch</i>, Las-Vegas ist <i>korrekt und vielleicht langsam</i>. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 2: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: )fMa+B?>K.
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Bei einem Las-Vegas-Algorithmus ist die Laufzeit eine Zufallsvariable, die Korrektheit hingegen nicht vom Zufall abhängig.
Ziel: immer korrekt/gut, meistens schnell.
Alternative Sichtweise: Algorithmus, der manchmal '???' statt eines Ergebnisses ausgibt. Man kann ihn dann entweder wiederholen, bis ein Ergebnis kommt, oder nach fester Laufzeit abbrechen.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Bei einem Las-Vegas-Algorithmus ist die Laufzeit eine Zufallsvariable, die Korrektheit hingegen nicht vom Zufall abhängig.
Ziel: immer korrekt/gut, meistens schnell.
Alternative Sichtweise: Algorithmus, der manchmal '???' statt eines Ergebnisses ausgibt. Man kann ihn dann entweder wiederholen, bis ein Ergebnis kommt, oder nach fester Laufzeit abbrechen.
Die alternative Sichtweise ist die Brücke zum Monte-Carlo-Algorithmus: Lässt man den Las-Vegas-Algorithmus nach fester Laufzeit abbrechen, wird daraus ein Monte-Carlo-Algorithmus mit einseitigem Fehler.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Bei einem <b>Las-Vegas-Algorithmus</b> ist {{c1::die Laufzeit}} eine Zufallsvariable, die {{c1::Korrektheit}} hingegen nicht vom Zufall abhängig.<br><br>Ziel: {{c2::immer korrekt/gut, meistens schnell}}.<br><br><b>Alternative Sichtweise:</b> Algorithmus, der manchmal {{c3::'???' statt eines Ergebnisses}} ausgibt. Man kann ihn dann entweder {{c4::wiederholen, bis ein Ergebnis kommt}}, oder {{c4::nach fester Laufzeit abbrechen}}. |
| Extra |
|
Die alternative Sichtweise ist die Brücke zum Monte-Carlo-Algorithmus: Lässt man den Las-Vegas-Algorithmus nach fester Laufzeit abbrechen, wird daraus ein Monte-Carlo-Algorithmus mit einseitigem Fehler. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 3: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: ,)x/S/PKsh
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Randomisierter Algorithmus für Optimierungsprobleme
Sei \(\varepsilon > 0\) und \(A\) ein randomisierter Algorithmus, der immer eine zulässige Lösung liefert, mit\[\Pr[A(I) \geq f(I)] \geq \varepsilon\]für eine Zielschwelle \(f(I)\). Sei \(A_\delta\) der Algorithmus, der\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\]Aufrufe von \(A\) macht und die beste der erhaltenen Antworten ausgibt. Dann gilt:\[\Pr[A_\delta(I) \geq f(I)] \geq 1 - \delta.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Randomisierter Algorithmus für Optimierungsprobleme
Sei \(\varepsilon > 0\) und \(A\) ein randomisierter Algorithmus, der immer eine zulässige Lösung liefert, mit\[\Pr[A(I) \geq f(I)] \geq \varepsilon\]für eine Zielschwelle \(f(I)\). Sei \(A_\delta\) der Algorithmus, der\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\]Aufrufe von \(A\) macht und die beste der erhaltenen Antworten ausgibt. Dann gilt:\[\Pr[A_\delta(I) \geq f(I)] \geq 1 - \delta.\]
Selbe Iterationsschranke wie bei Las-Vegas und MC mit einseitigem Fehler. Die Idee ist analog: ein einziger Aufruf, der die Schwelle überschreitet, genügt, da das Maximum mehrerer Aufrufe genommen wird.
Typischerweise ist \(f(I) = \mathbb{E}[A(I)]\), d.h. man möchte mit hoher Wahrscheinlichkeit mindestens den Erwartungswert erreichen.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Randomisierter Algorithmus für Optimierungsprobleme</b> <br>Sei \(\varepsilon > 0\) und \(A\) ein randomisierter Algorithmus, der immer eine zulässige Lösung liefert, mit\[\Pr[A(I) \geq f(I)] \geq \varepsilon\]für eine Zielschwelle \(f(I)\). Sei \(A_\delta\) der Algorithmus, der\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\]Aufrufe von \(A\) macht und {{c2::die beste der erhaltenen Antworten}} ausgibt. Dann gilt:\[\Pr[A_\delta(I) \geq f(I)] \geq 1 - \delta.\] |
| Extra |
|
Selbe Iterationsschranke wie bei Las-Vegas und MC mit einseitigem Fehler. Die Idee ist analog: ein einziger Aufruf, der die Schwelle überschreitet, genügt, da das Maximum mehrerer Aufrufe genommen wird.<br><br>Typischerweise ist \(f(I) = \mathbb{E}[A(I)]\), d.h. man möchte mit hoher Wahrscheinlichkeit mindestens den Erwartungswert erreichen. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 4: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: 3,p]}*RsV:
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Üppige-Auswahl-Problem (gegeben \(x_1, \ldots, x_n \in \{0, 1\}\) mit \(n/2\) Einsen, finde \(i\) mit \(x_i = 1\)):
Was ist die Laufzeit des schnellsten deterministischen Algorithmus, was die erwartete Laufzeit des schnellsten Las-Vegas-Algorithmus?
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Üppige-Auswahl-Problem (gegeben \(x_1, \ldots, x_n \in \{0, 1\}\) mit \(n/2\) Einsen, finde \(i\) mit \(x_i = 1\)):
Was ist die Laufzeit des schnellsten deterministischen Algorithmus, was die erwartete Laufzeit des schnellsten Las-Vegas-Algorithmus?
Deterministisch: \(\Theta(n)\) (Worst Case).
Las-Vegas: \(O(1)\) erwartet, unabhängig von \(n\).
Das ist ein dramatischer Unterschied und ein Paradebeispiel für den Vorteil von Randomisierung: der Las-Vegas-Algorithmus probiert wiederholt zufällige Indizes und stoppt, sobald er eine \(1\) findet. Da die Hälfte der Bits \(1\) ist, ist die erwartete Anzahl Versuche \(\mathbb{E}[T] = 2\).
Die deterministische untere Schranke folgt aus einem Adversary-Argument: gegen jeden festen Algorithmus kann man eine Instanz konstruieren, auf der er \(n/2 + 1\) Bits lesen muss.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Üppige-Auswahl-Problem (gegeben \(x_1, \ldots, x_n \in \{0, 1\}\) mit \(n/2\) Einsen, finde \(i\) mit \(x_i = 1\)):<br><br>Was ist die Laufzeit des schnellsten <b>deterministischen</b> Algorithmus, was die <b>erwartete</b> Laufzeit des schnellsten <b>Las-Vegas</b>-Algorithmus? |
| Back |
|
Deterministisch: \(\Theta(n)\) (Worst Case).<br>Las-Vegas: \(O(1)\) erwartet, unabhängig von \(n\).<br><br>Das ist ein dramatischer Unterschied und ein Paradebeispiel für den Vorteil von Randomisierung: der Las-Vegas-Algorithmus probiert wiederholt zufällige Indizes und stoppt, sobald er eine \(1\) findet. Da die Hälfte der Bits \(1\) ist, ist die erwartete Anzahl Versuche \(\mathbb{E}[T] = 2\).<br><br>Die deterministische untere Schranke folgt aus einem Adversary-Argument: gegen jeden festen Algorithmus kann man eine Instanz konstruieren, auf der er \(n/2 + 1\) Bits lesen muss. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Note 5: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: 5]{}ADU2JV
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Sei \(n > 2\) ungerade, schreibe \(n - 1 = 2^k d\) mit \(d\) ungerade.
Vorüberlegung: Für \(n\) prim ist \((\mathbb{Z}_n, +, \cdot)\) ein
Körper, und in einem Körper hat \(x^2 = 1\) genau zwei Lösungen: \({{c2::x = 1\ \text{und}\ x = n - 1\ (= -1)}}\).
Ist \(n\) prim und \(a \in [n-1]\), dann gilt:
- \(a^{2^k d} = a^{n-1} \equiv_n 1\) (kleiner Fermat),
- also \(a^{2^{k-1}d} \equiv_n 1\) oder \(n - 1\),
- falls \(\equiv_n 1\): wieder Quadratwurzel ziehen, \(a^{2^{k-2}d} \equiv_n 1\) oder \(n-1\),
- ... bis: falls \(a^{2d} \equiv_n 1\), dann \(a^d \equiv_n 1\) oder \(n - 1\).
Miller-Rabin-Bedingung: für \(n\) prim und alle \(a\) gilt
\[{{c3::a^d \equiv_n 1 \quad \text{oder} \quad \exists\, i \in \{0, 1, \ldots, k-1\}: a^{2^i d} \equiv_n n - 1.}}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Sei \(n > 2\) ungerade, schreibe \(n - 1 = 2^k d\) mit \(d\) ungerade.
Vorüberlegung: Für \(n\) prim ist \((\mathbb{Z}_n, +, \cdot)\) ein
Körper, und in einem Körper hat \(x^2 = 1\) genau zwei Lösungen: \({{c2::x = 1\ \text{und}\ x = n - 1\ (= -1)}}\).
Ist \(n\) prim und \(a \in [n-1]\), dann gilt:
- \(a^{2^k d} = a^{n-1} \equiv_n 1\) (kleiner Fermat),
- also \(a^{2^{k-1}d} \equiv_n 1\) oder \(n - 1\),
- falls \(\equiv_n 1\): wieder Quadratwurzel ziehen, \(a^{2^{k-2}d} \equiv_n 1\) oder \(n-1\),
- ... bis: falls \(a^{2d} \equiv_n 1\), dann \(a^d \equiv_n 1\) oder \(n - 1\).
Miller-Rabin-Bedingung: für \(n\) prim und alle \(a\) gilt
\[{{c3::a^d \equiv_n 1 \quad \text{oder} \quad \exists\, i \in \{0, 1, \ldots, k-1\}: a^{2^i d} \equiv_n n - 1.}}\]
Idee: aus \(a^{n-1} \equiv_n 1\) wiederholt Quadratwurzeln ziehen, solange das Ergebnis noch \(1\) ist. Im Körper sind die einzigen Quadratwurzeln von \(1\) genau \(\pm 1\), daher muss man irgendwann auf \(n-1\) treffen oder bei \(a^d \equiv_n 1\) landen.
Ein \(a\), das diese Bedingung verletzt, ist ein Miller-Rabin-Zertifikat dafür, dass \(n\) nicht prim ist.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Sei \(n > 2\) ungerade, schreibe \(n - 1 = 2^k d\) mit \(d\) ungerade.
Vorüberlegung: Für \(n\) prim ist \((\mathbb{Z}_n, +, \cdot)\) ein
Körper, und in einem
Körper hat \(x^2 = 1\) genau zwei Lösungen: \({{c2::x = 1\ \text{und}\ x = n - 1\ (= -1)}}\).
Ist \(n\) prim und \(a \in [n-1]\), dann gilt:
- \(a^{2^k d} = a^{n-1} \equiv_n 1\) (kleiner Fermat),
- also \(a^{2^{k-1}d} \equiv_n 1\) oder \(n - 1\),
- falls \(\equiv_n 1\): wieder Quadratwurzel ziehen, \(a^{2^{k-2}d} \equiv_n 1\) oder \(n-1\),
- ... bis: falls \(a^{2d} \equiv_n 1\), dann \(a^d \equiv_n 1\) oder \(n - 1\).
Miller-Rabin-Bedingung: für \(n\) prim und alle \(a\) gilt
\[{{c3::a^d \equiv_n 1 \quad \text{oder} \quad \exists\, i \in \{0, 1, \ldots, k-1\}: a^{2^i d} \equiv_n n - 1.}}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Sei \(n > 2\) ungerade, schreibe \(n - 1 = 2^k d\) mit \(d\) ungerade.
Vorüberlegung: Für \(n\) prim ist \((\mathbb{Z}_n, +, \cdot)\) ein
Körper, und in einem
Körper hat \(x^2 = 1\) genau zwei Lösungen: \({{c2::x = 1\ \text{und}\ x = n - 1\ (= -1)}}\).
Ist \(n\) prim und \(a \in [n-1]\), dann gilt:
- \(a^{2^k d} = a^{n-1} \equiv_n 1\) (kleiner Fermat),
- also \(a^{2^{k-1}d} \equiv_n 1\) oder \(n - 1\),
- falls \(\equiv_n 1\): wieder Quadratwurzel ziehen, \(a^{2^{k-2}d} \equiv_n 1\) oder \(n-1\),
- ... bis: falls \(a^{2d} \equiv_n 1\), dann \(a^d \equiv_n 1\) oder \(n - 1\).
Miller-Rabin-Bedingung: für \(n\) prim und alle \(a\) gilt
\[{{c3::a^d \equiv_n 1 \quad \text{oder} \quad \exists\, i \in \{0, 1, \ldots, k-1\}: a^{2^i d} \equiv_n n - 1.}}\]
Idee: aus \(a^{n-1} \equiv_n 1\) wiederholt Quadratwurzeln ziehen, solange das Ergebnis noch \(1\) ist. Im Körper sind die einzigen Quadratwurzeln von \(1\) genau \(\pm 1\), daher muss man irgendwann auf \(n-1\) treffen oder bei \(a^d \equiv_n 1\) landen.
Ein \(a\), das diese Bedingung verletzt, ist ein Miller-Rabin-Zertifikat dafür, dass \(n\) nicht prim ist.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Sei \(n > 2\) ungerade, schreibe \(n - 1 = 2^k d\) mit \(d\) ungerade.<br><br>Vorüberlegung: Für \(n\) prim ist \((\mathbb{Z}_n, +, \cdot)\) ein {{c1::Körper}}, und in einem Körper hat \(x^2 = 1\) genau zwei Lösungen: \({{c2::x = 1\ \text{und}\ x = n - 1\ (= -1)}}\).<br><br>Ist \(n\) prim und \(a \in [n-1]\), dann gilt:<ul><li>\(a^{2^k d} = a^{n-1} \equiv_n 1\) (kleiner Fermat),</li><li>also \(a^{2^{k-1}d} \equiv_n 1\) oder \(n - 1\),</li><li>falls \(\equiv_n 1\): wieder Quadratwurzel ziehen, \(a^{2^{k-2}d} \equiv_n 1\) oder \(n-1\),</li><li>... bis: falls \(a^{2d} \equiv_n 1\), dann \(a^d \equiv_n 1\) oder \(n - 1\).</li></ul><b>Miller-Rabin-Bedingung</b>: für \(n\) prim und alle \(a\) gilt<br>\[{{c3::a^d \equiv_n 1 \quad \text{oder} \quad \exists\, i \in \{0, 1, \ldots, k-1\}: a^{2^i d} \equiv_n n - 1.}}\] |
Sei \(n > 2\) ungerade, schreibe \(n - 1 = 2^k d\) mit \(d\) ungerade.<br><br>Vorüberlegung: Für \(n\) prim ist \((\mathbb{Z}_n, +, \cdot)\) ein {{c1::Körper}}, und in einem {{c1::Körper}} hat \(x^2 = 1\) genau zwei Lösungen: \({{c2::x = 1\ \text{und}\ x = n - 1\ (= -1)}}\).<br><br>Ist \(n\) prim und \(a \in [n-1]\), dann gilt:<ul><li>\(a^{2^k d} = a^{n-1} \equiv_n 1\) (kleiner Fermat),</li><li>also \(a^{2^{k-1}d} \equiv_n 1\) oder \(n - 1\),</li><li>falls \(\equiv_n 1\): wieder Quadratwurzel ziehen, \(a^{2^{k-2}d} \equiv_n 1\) oder \(n-1\),</li><li>... bis: falls \(a^{2d} \equiv_n 1\), dann \(a^d \equiv_n 1\) oder \(n - 1\).</li></ul><b>Miller-Rabin-Bedingung</b>: für \(n\) prim und alle \(a\) gilt<br>\[{{c3::a^d \equiv_n 1 \quad \text{oder} \quad \exists\, i \in \{0, 1, \ldots, k-1\}: a^{2^i d} \equiv_n n - 1.}}\] |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Note 6: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: 7t4EPy8r-E
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Im Allgemeinen ist die Fehlerreduktion bei Monte-Carlo-Algorithmen
nicht möglich.
(Gegenbeispiel: Algorithmus, der mit Wahrscheinlichkeit \(\tfrac{1}{2}\) JA bzw. NEIN antwortet, unabhängig von der Eingabe.)
Möglich ist sie aber bei:
- einseitigem Fehler, oder
- {{c2::Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\)}}.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Im Allgemeinen ist die Fehlerreduktion bei Monte-Carlo-Algorithmen
nicht möglich.
(Gegenbeispiel: Algorithmus, der mit Wahrscheinlichkeit \(\tfrac{1}{2}\) JA bzw. NEIN antwortet, unabhängig von der Eingabe.)
Möglich ist sie aber bei:
- einseitigem Fehler, oder
- {{c2::Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\)}}.
Bei einseitigem Fehler genügt eine einzige korrekte Antwort, um die Wahrheit zu kennen (Wiederholung + erste eindeutige Antwort).
Bei Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\) hilft Mehrheitsentscheid (Chernoff-Argument).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Im Allgemeinen ist die Fehlerreduktion bei Monte-Carlo-Algorithmen <b>nicht möglich</b>.<br>(Gegenbeispiel: Algorithmus, der mit Wahrscheinlichkeit \(\tfrac{1}{2}\) JA bzw. NEIN antwortet, unabhängig von der Eingabe.)<br><br>Möglich ist sie aber bei:<ul><li>{{c1::einseitigem Fehler}}, oder</li><li>{{c2::Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\)}}.</li></ul> |
| Extra |
|
Bei einseitigem Fehler genügt eine einzige korrekte Antwort, um die Wahrheit zu kennen (Wiederholung + erste eindeutige Antwort).<br>Bei Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\) hilft Mehrheitsentscheid (Chernoff-Argument). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 7: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: ;8NM;X(w+1
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Ein
klassischer Algorithmus \(A\) erhält Eingabe \(I\) und liefert Ausgabe \(A(I)\). Es gilt:
- \(A(I)\) ist immer genau und korrekt,
- bei gleicher Eingabe immer dieselbe Ausgabe (\(A\) ist eine Funktion),
- dieselbe Laufzeit.
Ein
randomisierter Algorithmus erhält zusätzlich eine Zufallsquelle \(R\) und liefert Ausgabe \(A(I, R)\). Die Ausgabe ist
manchmal richtig, manchmal fast richtig, manchmal schnell, das Verhalten ist
nicht reproduzierbar. \(A\) ist nach wie vor eine Funktion auf den Paaren \((I, R)\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Ein
klassischer Algorithmus \(A\) erhält Eingabe \(I\) und liefert Ausgabe \(A(I)\). Es gilt:
- \(A(I)\) ist immer genau und korrekt,
- bei gleicher Eingabe immer dieselbe Ausgabe (\(A\) ist eine Funktion),
- dieselbe Laufzeit.
Ein
randomisierter Algorithmus erhält zusätzlich eine Zufallsquelle \(R\) und liefert Ausgabe \(A(I, R)\). Die Ausgabe ist
manchmal richtig, manchmal fast richtig, manchmal schnell, das Verhalten ist
nicht reproduzierbar. \(A\) ist nach wie vor eine Funktion auf den Paaren \((I, R)\).
Reproduzierbarkeit ist die zentrale Eigenschaft, die beim Übergang zum randomisierten Algorithmus verloren geht.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Ein <b>klassischer</b> Algorithmus \(A\) erhält Eingabe \(I\) und liefert Ausgabe \(A(I)\). Es gilt:<ul><li>\(A(I)\) ist immer {{c1::genau und korrekt}},</li><li>bei gleicher Eingabe immer {{c2::dieselbe Ausgabe (\(A\) ist eine Funktion)}},</li><li>{{c3::dieselbe Laufzeit}}.</li></ul>Ein <b>randomisierter</b> Algorithmus erhält zusätzlich eine Zufallsquelle \(R\) und liefert Ausgabe \(A(I, R)\). Die Ausgabe ist {{c4::manchmal richtig, manchmal fast richtig, manchmal schnell}}, das Verhalten ist {{c5::nicht reproduzierbar}}. \(A\) ist nach wie vor eine Funktion auf den Paaren \((I, R)\). |
| Extra |
|
Reproduzierbarkeit ist die zentrale Eigenschaft, die beim Übergang zum randomisierten Algorithmus verloren geht. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 8: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: @e3zvshd`*
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Fehlerreduktion Las-Vegas
Sei \(A\) ein randomisierter Algorithmus, der nie eine falsche Antwort gibt, aber zuweilen '???' ausgibt, mit \(\Pr[A(I) \text{ korrekt}] \geq \varepsilon\).
Sei \(A_\delta\) der Algorithmus, der \(A\) solange aufruft, bis entweder ein Wert verschieden von '???' ausgegeben wird (und diesen Wert dann ebenfalls ausgibt) oder bis
\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\] mal '???' ausgegeben wurde (und dann '???' ausgibt). Dann gilt:
\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Fehlerreduktion Las-Vegas
Sei \(A\) ein randomisierter Algorithmus, der nie eine falsche Antwort gibt, aber zuweilen '???' ausgibt, mit \(\Pr[A(I) \text{ korrekt}] \geq \varepsilon\).
Sei \(A_\delta\) der Algorithmus, der \(A\) solange aufruft, bis entweder ein Wert verschieden von '???' ausgegeben wird (und diesen Wert dann ebenfalls ausgibt) oder bis
\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\] mal '???' ausgegeben wurde (und dann '???' ausgibt). Dann gilt:
\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\]
Beweisskizze: Pr[\(A_\delta\) gibt '???' aus] \(\leq (1-\varepsilon)^N \leq e^{-\varepsilon N} \leq \delta\) für \(N \geq \varepsilon^{-1} \ln \delta^{-1}\), via \(1 - x \leq e^{-x}\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Fehlerreduktion Las-Vegas</b> <br>Sei \(A\) ein randomisierter Algorithmus, der nie eine falsche Antwort gibt, aber zuweilen '???' ausgibt, mit \(\Pr[A(I) \text{ korrekt}] \geq \varepsilon\).<br><br>Sei \(A_\delta\) der Algorithmus, der \(A\) solange aufruft, bis entweder ein Wert verschieden von '???' ausgegeben wird (und diesen Wert dann ebenfalls ausgibt) oder bis <br>\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\] mal '???' ausgegeben wurde (und dann '???' ausgibt). Dann gilt:<br>\[\Pr[A_\delta(I) \text{ korrekt}] \geq {{c2::1 - \delta}}.\] |
| Extra |
|
Beweisskizze: Pr[\(A_\delta\) gibt '???' aus] \(\leq (1-\varepsilon)^N \leq e^{-\varepsilon N} \leq \delta\) für \(N \geq \varepsilon^{-1} \ln \delta^{-1}\), via \(1 - x \leq e^{-x}\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 9: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: BEp+Di
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Für \(\mathrm{QuickSelect}(A, 1, n, k)\) mit zufälligem Pivot gilt:\[\mathbb{E}[T] \leq 8n,\]also \(\mathbb{E}[T] = O(n)\) erwartet, wobei \(T\) die Anzahl Vergleiche bezeichnet.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Für \(\mathrm{QuickSelect}(A, 1, n, k)\) mit zufälligem Pivot gilt:\[\mathbb{E}[T] \leq 8n,\]also \(\mathbb{E}[T] = O(n)\) erwartet, wobei \(T\) die Anzahl Vergleiche bezeichnet.
Proof Included.
Beweisidee (siehe separate Karte zur \(N_j\)-Konstruktion): Man partitioniert die Aufrufe nach Grössenklassen und nutzt, dass mit Wahrscheinlichkeit \(\geq 1/2\) ein Aufruf das Intervall um Faktor \(3/4\) verkleinert. Die geometrische Reihe \(\sum_{j \geq 1} (3/4)^{j-1} = 4\) zusammen mit \(\mathbb{E}[N_j] \leq 2\) liefert \(\mathbb{E}[T] \leq 2n \cdot 4 = 8n\).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Für \(\mathrm{QuickSelect}(A, 1, n, k)\) mit zufälligem Pivot gilt:\[\mathbb{E}[T] \leq 8n,\]also \(\mathbb{E}[T] = O(n)\) erwartet, wobei \(T\) die Anzahl Vergleiche bezeichnet.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Für \(\mathrm{QuickSelect}(A, 1, n, k)\) mit zufälligem Pivot gilt:\[\mathbb{E}[T] \leq 8n,\]also \(\mathbb{E}[T] = O(n)\) erwartet, wobei \(T\) die Anzahl Vergleiche bezeichnet.
Beweisidee (siehe separate Karte zur \(N_j\)-Konstruktion):
Man partitioniert die Aufrufe nach Grössenklassen und nutzt, dass mit Wahrscheinlichkeit \(\geq 1/2\) ein Aufruf das Intervall um Faktor \(3/4\) verkleinert. Die geometrische Reihe \(\sum_{j \geq 1} (3/4)^{j-1} = 4\) zusammen mit \(\mathbb{E}[N_j] \leq 2\) liefert \(\mathbb{E}[T] \leq 2n \cdot 4 = 8n\).
Field-by-field Comparison
| Field |
Before |
After |
| Extra |
Proof Included.<br><br>Beweisidee (siehe separate Karte zur \(N_j\)-Konstruktion): Man partitioniert die Aufrufe nach Grössenklassen und nutzt, dass mit Wahrscheinlichkeit \(\geq 1/2\) ein Aufruf das Intervall um Faktor \(3/4\) verkleinert. Die geometrische Reihe \(\sum_{j \geq 1} (3/4)^{j-1} = 4\) zusammen mit \(\mathbb{E}[N_j] \leq 2\) liefert \(\mathbb{E}[T] \leq 2n \cdot 4 = 8n\). |
Beweisidee (siehe separate Karte zur \(N_j\)-Konstruktion): <br>Man partitioniert die Aufrufe nach Grössenklassen und nutzt, dass mit Wahrscheinlichkeit \(\geq 1/2\) ein Aufruf das Intervall um Faktor \(3/4\) verkleinert. Die geometrische Reihe \(\sum_{j \geq 1} (3/4)^{j-1} = 4\) zusammen mit \(\mathbb{E}[N_j] \leq 2\) liefert \(\mathbb{E}[T] \leq 2n \cdot 4 = 8n\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Note 10: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: GUSRKOlJ(I
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Miller-Rabin-Primzahltest (für \(n > 1\) ungerade):
1. Schreibe n - 1 = 2^k · d mit d ungerade
2. Wähle a ∈ [n-1] zufällig gleichverteilt
3. if a^d mod n = 1 oder ∃i ∈ {0,...,k-1}: a^(2^i·d) mod n = n-1:
return 'Primzahl'
else:
return 'keine Primzahl'Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt.
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\), tatsächlich sogar \(\leq \tfrac{1}{4}\)}}.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Miller-Rabin-Primzahltest (für \(n > 1\) ungerade):
1. Schreibe n - 1 = 2^k · d mit d ungerade
2. Wähle a ∈ [n-1] zufällig gleichverteilt
3. if a^d mod n = 1 oder ∃i ∈ {0,...,k-1}: a^(2^i·d) mod n = n-1:
return 'Primzahl'
else:
return 'keine Primzahl'Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt.
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\), tatsächlich sogar \(\leq \tfrac{1}{4}\)}}.
Im Gegensatz zum Fermat-Test funktioniert Miller-Rabin auch für Carmichael-Zahlen.
Beispiel \(n = 561\) mit \(a = 2\): \(n - 1 = 560 = 2^4 \cdot 35\), und \(2^{280} \equiv_{561} 1\), aber \(2^{140} \equiv_{561} 67 \notin \{1, 560\}\). Also ist \(2\) ein Miller-Rabin-Zertifikat dafür, dass \(561\) nicht prim ist.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Miller-Rabin-Primzahltest (für \(n > 1\) ungerade):
1. Schreibe n - 1 = 2^k · d mit d ungerade
2. Wähle a ∈ [n-1] zufällig gleichverteilt
3. if a^d mod n = 1
oder ∃i ∈ {0,...,k-1}: a^(2^i·d) mod n = n-1:
return 'Primzahl'
else:
return 'keine Primzahl'Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt.
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\), tatsächlich sogar \(\leq \tfrac{1}{4}\)}}.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Miller-Rabin-Primzahltest (für \(n > 1\) ungerade):
1. Schreibe n - 1 = 2^k · d mit d ungerade
2. Wähle a ∈ [n-1] zufällig gleichverteilt
3. if a^d mod n = 1
oder ∃i ∈ {0,...,k-1}: a^(2^i·d) mod n = n-1:
return 'Primzahl'
else:
return 'keine Primzahl'Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt.
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\), tatsächlich sogar \(\leq \tfrac{1}{4}\)}}.
Im Gegensatz zum Fermat-Test funktioniert Miller-Rabin auch für Carmichael-Zahlen.
Beispiel \(n = 561\) mit \(a = 2\):
\(n - 1 = 560 = 2^4 \cdot 35\),
und \(2^{280} \equiv_{561} 1\),
aber \(2^{140} \equiv_{561} 67 \notin \{1, 560\}\).
Also ist \(2\) ein Miller-Rabin-Zertifikat dafür, dass \(561\) nicht prim ist.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Miller-Rabin-Primzahltest</b> (für \(n > 1\) ungerade):<pre>1. Schreibe n - 1 = 2^k · d mit d ungerade
2. Wähle a ∈ [n-1] zufällig gleichverteilt
3. if a^d mod n = 1 oder ∃i ∈ {0,...,k-1}: a^(2^i·d) mod n = n-1:
return 'Primzahl'
else:
return 'keine Primzahl'</pre>Korrektheit:<ul><li>Falls \(n\) prim: {{c1::Ausgabe immer korrekt}}.</li><li>Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\), tatsächlich sogar \(\leq \tfrac{1}{4}\)}}.</li></ul> |
<b>Miller-Rabin-Primzahltest</b> (für \(n > 1\) ungerade):<pre>1. Schreibe n - 1 = 2^k · d mit d ungerade
2. Wähle a ∈ [n-1] zufällig gleichverteilt
3. if a^d mod n = 1
oder ∃i ∈ {0,...,k-1}: a^(2^i·d) mod n = n-1:
return 'Primzahl'
else:
return 'keine Primzahl'</pre>Korrektheit:<ul><li>Falls \(n\) prim: {{c1::Ausgabe immer korrekt}}.</li><li>Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\), tatsächlich sogar \(\leq \tfrac{1}{4}\)}}.</li></ul> |
| Extra |
Im Gegensatz zum Fermat-Test funktioniert Miller-Rabin auch für Carmichael-Zahlen.<br><br>Beispiel \(n = 561\) mit \(a = 2\): \(n - 1 = 560 = 2^4 \cdot 35\), und \(2^{280} \equiv_{561} 1\), aber \(2^{140} \equiv_{561} 67 \notin \{1, 560\}\). Also ist \(2\) ein Miller-Rabin-Zertifikat dafür, dass \(561\) nicht prim ist. |
Im Gegensatz zum Fermat-Test funktioniert Miller-Rabin auch für Carmichael-Zahlen.<br><br>Beispiel \(n = 561\) mit \(a = 2\):<br>\(n - 1 = 560 = 2^4 \cdot 35\), <br>und \(2^{280} \equiv_{561} 1\), <br>aber \(2^{140} \equiv_{561} 67 \notin \{1, 560\}\). <br><br>Also ist \(2\) ein Miller-Rabin-Zertifikat dafür, dass \(561\) nicht prim ist. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Note 11: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: MzW@KkLJq_
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Monte-Carlo, einseitiger Fehler
Sei \(A\) ein randomisierter Algorithmus, der immer JA oder NEIN ausgibt, mit\[\begin{gathered}\Pr[A(I) = \text{JA}] = 1, \text{ falls } I \text{ JA-Instanz},\\ \Pr[A(I) = \text{NEIN}] \geq \varepsilon, \text{ falls } I \text{ NEIN-Instanz}.\end{gathered}\]Sei \(A_\delta\) der Algorithmus, der \(A\) solange aufruft, bis entweder NEIN ausgegeben wird (dann selbst NEIN) oder bis\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\]mal JA ausgegeben wurde (dann selbst JA). Dann gilt:\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Monte-Carlo, einseitiger Fehler
Sei \(A\) ein randomisierter Algorithmus, der immer JA oder NEIN ausgibt, mit\[\begin{gathered}\Pr[A(I) = \text{JA}] = 1, \text{ falls } I \text{ JA-Instanz},\\ \Pr[A(I) = \text{NEIN}] \geq \varepsilon, \text{ falls } I \text{ NEIN-Instanz}.\end{gathered}\]Sei \(A_\delta\) der Algorithmus, der \(A\) solange aufruft, bis entweder NEIN ausgegeben wird (dann selbst NEIN) oder bis\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\]mal JA ausgegeben wurde (dann selbst JA). Dann gilt:\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\]
Selbe Iterationsschranke wie bei Las-Vegas: \(N = \lceil \varepsilon^{-1} \ln \delta^{-1} \rceil\). Tatsächlich ist das hier äquivalent zur Las-Vegas-Sicht: man kann den einseitig-fehlerhaften MC-Algorithmus als Las-Vegas-Algorithmus auffassen, der '???' (alias 'JA') ausgibt, wenn er nicht sicher ist.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Monte-Carlo, einseitiger Fehler<br></b>Sei \(A\) ein randomisierter Algorithmus, der immer JA oder NEIN ausgibt, mit\[\begin{gathered}\Pr[A(I) = \text{JA}] = 1, \text{ falls } I \text{ JA-Instanz},\\ \Pr[A(I) = \text{NEIN}] \geq \varepsilon, \text{ falls } I \text{ NEIN-Instanz}.\end{gathered}\]Sei \(A_\delta\) der Algorithmus, der \(A\) solange aufruft, bis entweder NEIN ausgegeben wird (dann selbst NEIN) oder bis\[N = {{c1::\left\lceil \varepsilon^{-1} \ln \delta^{-1} \right\rceil}}\]mal JA ausgegeben wurde (dann selbst JA). Dann gilt:\[\Pr[A_\delta(I) \text{ korrekt}] \geq {{c2::1 - \delta}}.\] |
| Extra |
|
Selbe Iterationsschranke wie bei Las-Vegas: \(N = \lceil \varepsilon^{-1} \ln \delta^{-1} \rceil\). Tatsächlich ist das hier äquivalent zur Las-Vegas-Sicht: man kann den einseitig-fehlerhaften MC-Algorithmus als Las-Vegas-Algorithmus auffassen, der '???' (alias 'JA') ausgibt, wenn er nicht sicher ist. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 12: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: a1rkJfjyfd
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::5._Wichtige_diskrete_Verteilungen::1._Bernoulli-Verteilung
Eine Zufallsvariable \(X\) mit Wertebereich \(W_X = \{0, 1\}\) und Dichte\[f_X(\alpha) = \begin{cases} p & {{c1::\text{für } \alpha = 1}} \\ 1 - p & {{c1::\text{für } \alpha = 0}} \\ 0 & \text{sonst} \end{cases}\]heisst Bernoulli-verteilt mit Erfolgswahrscheinlichkeit \(p\).
Man schreibt dann auch \({{c2::X \sim \text{Bernoulli}(p)}}\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::5._Wichtige_diskrete_Verteilungen::1._Bernoulli-Verteilung
Eine Zufallsvariable \(X\) mit Wertebereich \(W_X = \{0, 1\}\) und Dichte\[f_X(\alpha) = \begin{cases} p & {{c1::\text{für } \alpha = 1}} \\ 1 - p & {{c1::\text{für } \alpha = 0}} \\ 0 & \text{sonst} \end{cases}\]heisst Bernoulli-verteilt mit Erfolgswahrscheinlichkeit \(p\).
Man schreibt dann auch \({{c2::X \sim \text{Bernoulli}(p)}}\).
Modelliert einen einzelnen Münzwurf (mit verzerrter Münze).
Indikator-ZV \(X_A\) ist genau \(\text{Bernoulli}(\Pr[A])\).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::5._Wichtige_diskrete_Verteilungen::1._Bernoulli-Verteilung
Eine Zufallsvariable \(X\) mit Wertebereich \(W_X = \{0, 1\}\) und Dichte\[f_X(\alpha) = \begin{cases} p & {{c1::\text{für } \alpha = 1}} \\ 1 - p & {{c1::\text{für } \alpha = 0}} \\ 0 & {{c1::\text{sonst} }} \end{cases}\]heisst Bernoulli-verteilt mit Erfolgswahrscheinlichkeit \(p\).
Man schreibt dann auch \({{c2::X \sim \text{Bernoulli}(p)}}\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::5._Wichtige_diskrete_Verteilungen::1._Bernoulli-Verteilung
Eine Zufallsvariable \(X\) mit Wertebereich \(W_X = \{0, 1\}\) und Dichte\[f_X(\alpha) = \begin{cases} p & {{c1::\text{für } \alpha = 1}} \\ 1 - p & {{c1::\text{für } \alpha = 0}} \\ 0 & {{c1::\text{sonst} }} \end{cases}\]heisst Bernoulli-verteilt mit Erfolgswahrscheinlichkeit \(p\).
Man schreibt dann auch \({{c2::X \sim \text{Bernoulli}(p)}}\).
Modelliert einen einzelnen Münzwurf (mit verzerrter Münze).
Indikator-ZV \(X_A\) ist genau \(\text{Bernoulli}(\Pr[A])\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eine Zufallsvariable \(X\) mit Wertebereich \(W_X = \{0, 1\}\) und Dichte\[f_X(\alpha) = \begin{cases} p & {{c1::\text{für } \alpha = 1}} \\ 1 - p & {{c1::\text{für } \alpha = 0}} \\ 0 & {{c1::\text{sonst}}} \end{cases}\]heisst {{c2::Bernoulli-verteilt}} mit {{c3::<b>Erfolgswahrscheinlichkeit</b>}} \(p\).<br><br>Man schreibt dann auch \({{c2::X \sim \text{Bernoulli}(p)}}\). |
Eine Zufallsvariable \(X\) mit Wertebereich \(W_X = \{0, 1\}\) und Dichte\[f_X(\alpha) = \begin{cases} p & {{c1::\text{für } \alpha = 1}} \\ 1 - p & {{c1::\text{für } \alpha = 0}} \\ 0 & {{c1::\text{sonst} }} \end{cases}\]heisst {{c2::Bernoulli-verteilt}} mit {{c3::<b>Erfolgswahrscheinlichkeit</b>}} \(p\).<br><br>Man schreibt dann auch \({{c2::X \sim \text{Bernoulli}(p)}}\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::5._Wichtige_diskrete_Verteilungen::1._Bernoulli-Verteilung
Note 13: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: andmV{gT6%
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Fermat-Primzahltest:Fermat-Primzahltest(n):
wähle a ∈ [n-1] zufällig gleichverteilt
if a^(n-1) mod n = 1: return 'Primzahl'
else: return 'keine Primzahl'
(Berechnung von \(a^{n-1} \bmod n\) schnell mit binärer Exponentiation.)
Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt (kleiner Fermat).
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\)}}, es sei denn \(n\) ist eine Carmichael-Zahl.
Durch \(k\)-faches Wiederholen lässt sich die Fehlerwahrscheinlichkeit auf {{c4::\(\leq \tfrac{1}{2^k}\)}} drücken.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Fermat-Primzahltest:Fermat-Primzahltest(n):
wähle a ∈ [n-1] zufällig gleichverteilt
if a^(n-1) mod n = 1: return 'Primzahl'
else: return 'keine Primzahl'
(Berechnung von \(a^{n-1} \bmod n\) schnell mit binärer Exponentiation.)
Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt (kleiner Fermat).
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\)}}, es sei denn \(n\) ist eine Carmichael-Zahl.
Durch \(k\)-faches Wiederholen lässt sich die Fehlerwahrscheinlichkeit auf {{c4::\(\leq \tfrac{1}{2^k}\)}} drücken.
Wir machen einen Fehler genau dann, wenn \(n\) nicht prim und \(a^{n-1} \equiv_n 1\). Ein solches \(a\) heisst Pseudoprimzahlbasis von \(n\).
Achtung: Die \(\tfrac{1}{2}\)-Schranke greift nicht für Carmichael-Zahlen, dort ist die Fehlerrate effektiv \(1\) (siehe nächste Karte).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Fermat-Primzahltest:Fermat-Primzahltest(n):
wähle a ∈ [n-1] zufällig gleichverteilt
if a^(n-1) mod n = 1: return 'Primzahl'
else: return 'keine Primzahl'
(Berechnung von \(a^{n-1} \bmod n\) schnell mit binärer Exponentiation.)
Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt (kleiner Fermat).
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\)}}, es sei denn \(n\) ist eine Carmichael-Zahl.
Durch \(k\)-faches Wiederholen lässt sich die Fehlerwahrscheinlichkeit auf {{c4::\(\leq \tfrac{1}{2^k}\)}} drücken.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Fermat-Primzahltest:Fermat-Primzahltest(n):
wähle a ∈ [n-1] zufällig gleichverteilt
if a^(n-1) mod n = 1: return 'Primzahl'
else: return 'keine Primzahl'
(Berechnung von \(a^{n-1} \bmod n\) schnell mit binärer Exponentiation.)
Korrektheit:
- Falls \(n\) prim: Ausgabe immer korrekt (kleiner Fermat).
- Falls \(n\) nicht prim: Falsche Ausgabe 'Primzahl' mit Wahrscheinlichkeit {{c2::\(\leq \tfrac{1}{2}\)}}, es sei denn \(n\) ist eine Carmichael-Zahl.
Durch \(k\)-faches Wiederholen lässt sich die Fehlerwahrscheinlichkeit auf {{c4::\(\leq \tfrac{1}{2^k}\)}} drücken.
Wir machen einen Fehler genau dann, wenn \(n\) nicht prim und \(a^{n-1} \equiv_n 1\). Ein solches \(a\) heisst Pseudoprimzahlbasis von \(n\).
Achtung: Die \(\tfrac{1}{2}\)-Schranke greift nicht für Carmichael-Zahlen, dort ist die Fehlerrate effektiv \(1\).
Field-by-field Comparison
| Field |
Before |
After |
| Extra |
Wir machen einen Fehler genau dann, wenn \(n\) nicht prim und \(a^{n-1} \equiv_n 1\). Ein solches \(a\) heisst <b>Pseudoprimzahlbasis</b> von \(n\).<br><br>Achtung: Die \(\tfrac{1}{2}\)-Schranke greift nicht für Carmichael-Zahlen, dort ist die Fehlerrate effektiv \(1\) (siehe nächste Karte). |
Wir machen einen Fehler genau dann, wenn \(n\) nicht prim und \(a^{n-1} \equiv_n 1\). Ein solches \(a\) heisst <b>Pseudoprimzahlbasis</b> von \(n\).<br><br>Achtung: Die \(\tfrac{1}{2}\)-Schranke greift nicht für Carmichael-Zahlen, dort ist die Fehlerrate effektiv \(1\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Note 14: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: b:S43brt$<
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Üppige-Auswahl-Problem
Gegeben sind \(x_1, \ldots, x_n \in \{0, 1\}\), von denen
genau die Hälfte gleich \(1\) sind (\(n\) gerade).
Berechne
einen Index \(i\) mit \(x_i = 1\).
Trivialer deterministischer Algorithmus (in Zeit \(O(
n)\)):
for i = 1, ..., n:
if x_i = 1: return i
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Üppige-Auswahl-Problem
Gegeben sind \(x_1, \ldots, x_n \in \{0, 1\}\), von denen
genau die Hälfte gleich \(1\) sind (\(n\) gerade).
Berechne
einen Index \(i\) mit \(x_i = 1\).
Trivialer deterministischer Algorithmus (in Zeit \(O(
n)\)):
for i = 1, ..., n:
if x_i = 1: return i
Das Problem heisst üppig, weil es sehr viele gültige Antworten gibt (genau \(n/2\)). Trotzdem braucht jeder deterministische Algorithmus im Worst Case \(\Omega(n)\) Zeit, während ein einfacher Las-Vegas-Algorithmus mit erwartet \(O(1)\) auskommt.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Üppige-Auswahl-Problem<br></b>Gegeben sind \(x_1, \ldots, x_n \in \{0, 1\}\), von denen {{c1::genau die Hälfte}} gleich \(1\) sind (\(n\) gerade).<br>Berechne {{c2::einen Index \(i\) mit \(x_i = 1\)}}.<br><br>Trivialer deterministischer Algorithmus (in Zeit \(O({{c3::n}})\)):<pre>for i = 1, ..., n:
if x_i = 1: return i</pre> |
| Extra |
|
Das Problem heisst <i>üppig</i>, weil es sehr viele gültige Antworten gibt (genau \(n/2\)). Trotzdem braucht jeder deterministische Algorithmus im Worst Case \(\Omega(n)\) Zeit, während ein einfacher Las-Vegas-Algorithmus mit erwartet \(O(1)\) auskommt. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Note 15: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: cF!WjeyLtp
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings::1._Algorithmen
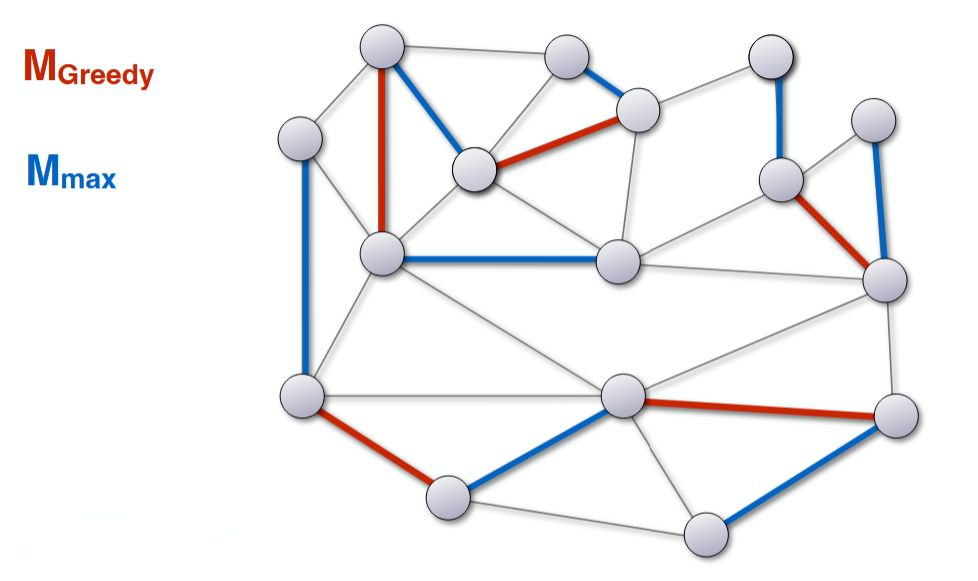
Jede Kante in \( M_{\text{Greedy}} \) kann höchstens {{c1::zwei Kanten aus \( M_{\text{max} } \)}} überdecken.
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings::1._Algorithmen
Jede Kante in \( M_{\text{Greedy}} \) kann höchstens {{c1::zwei Kanten aus \( M_{\text{max} } \)}} überdecken.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings::1._Algorithmen
Jede Kante in \( M_{\text{Greedy}} \) kann höchstens
zwei Kanten aus \( M_{\text{max} } \) überdecken.
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings::1._Algorithmen
Jede Kante in \( M_{\text{Greedy}} \) kann höchstens
zwei Kanten aus \( M_{\text{max} } \) überdecken.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<img src="paste-889d732e37d44fee9ae8a068d3fc03393243ad71.jpg"><br><br>Jede Kante in \( M_{\text{Greedy}} \) kann höchstens {{c1::zwei Kanten aus \( M_{\text{max} } \)}} überdecken. |
<img src="paste-889d732e37d44fee9ae8a068d3fc03393243ad71.jpg"><br><br>Jede Kante in \( M_{\text{Greedy}} \) kann höchstens {{c1::zwei}} Kanten aus \( M_{\text{max} } \) überdecken. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings::1._Algorithmen
Note 16: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: dbMcJI
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Bei der Fehlerreduktion eines Las-Vegas-Algorithmus mit Erfolgswahrscheinlichkeit \(\geq \varepsilon\) genügen \(N = \lceil \varepsilon^{-1} \ln \delta^{-1} \rceil\) Wiederholungen, um \(\Pr[\text{korrekt}] \geq 1 - \delta\) zu erreichen.
Wie skaliert \(N\) in \(\delta\)? Was bedeutet das praktisch?
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Bei der Fehlerreduktion eines Las-Vegas-Algorithmus mit Erfolgswahrscheinlichkeit \(\geq \varepsilon\) genügen \(N = \lceil \varepsilon^{-1} \ln \delta^{-1} \rceil\) Wiederholungen, um \(\Pr[\text{korrekt}] \geq 1 - \delta\) zu erreichen.
Wie skaliert \(N\) in \(\delta\)? Was bedeutet das praktisch?
\(N\) skaliert logarithmisch in \(\delta^{-1}\).
Praktisch: Um die Fehlerwahrscheinlichkeit um einen konstanten Faktor (z.B. von \(10^{-2}\) auf \(10^{-3}\)) zu reduzieren, sind nur konstant viele zusätzliche Iterationen nötig.
Beispiel \(\varepsilon = 0{,}25\): \(\delta = 10^{-1} \Rightarrow N = 10\), \(\delta = 10^{-2} \Rightarrow N = 19\), \(\delta = 10^{-3} \Rightarrow N = 28\), \(\ldots\) (jeweils \(+9\)).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Bei der Fehlerreduktion eines Las-Vegas-Algorithmus mit Erfolgswahrscheinlichkeit \(\geq \varepsilon\) genügen \(N = \lceil \varepsilon^{-1} \ln \delta^{-1} \rceil\) Wiederholungen, um \(\Pr[\text{korrekt}] \geq 1 - \delta\) zu erreichen.<br><br>Wie skaliert \(N\) in \(\delta\)? Was bedeutet das praktisch? |
| Back |
|
\(N\) skaliert <b>logarithmisch</b> in \(\delta^{-1}\).<br><br>Praktisch: Um die Fehlerwahrscheinlichkeit um einen <b>konstanten Faktor</b> (z.B. von \(10^{-2}\) auf \(10^{-3}\)) zu reduzieren, sind nur <b>konstant viele zusätzliche Iterationen</b> nötig.<br><br>Beispiel \(\varepsilon = 0{,}25\): \(\delta = 10^{-1} \Rightarrow N = 10\), \(\delta = 10^{-2} \Rightarrow N = 19\), \(\delta = 10^{-3} \Rightarrow N = 28\), \(\ldots\) (jeweils \(+9\)). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 17: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: j21wCKqyxl
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Im Beweis von \(\mathbb{E}[T_{1,n}] \leq 2(n+1) \ln n + O(n)\) für QuickSort beobachtet man, dass \(\mathbb{E}[T_{\ell, r}]\) nur von \(r - \ell + 1\) abhängt, also nur von der Anzahl zu sortierender Elemente.
Dies motiviert die rekursive Definition von Zahlen \(t_n\) mit \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\):
\[t_n = {{c2::\begin{cases} 0, & \text{falls } n \leq 1, \\ \frac{1}{n} \sum_{i=0}^{n-1} (n - 1 + t_i + t_{n-i-1}), & \text{falls } n \geq 2. \end{cases} }}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Im Beweis von \(\mathbb{E}[T_{1,n}] \leq 2(n+1) \ln n + O(n)\) für QuickSort beobachtet man, dass \(\mathbb{E}[T_{\ell, r}]\) nur von \(r - \ell + 1\) abhängt, also nur von der Anzahl zu sortierender Elemente.
Dies motiviert die rekursive Definition von Zahlen \(t_n\) mit \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\):
\[t_n = {{c2::\begin{cases} 0, & \text{falls } n \leq 1, \\ \frac{1}{n} \sum_{i=0}^{n-1} (n - 1 + t_i + t_{n-i-1}), & \text{falls } n \geq 2. \end{cases} }}\]
Herleitung: \(\mathbb{E}[T_{\ell, r}] = \sum_{i=\ell}^{r} \Pr[t = i] \cdot (r - \ell + \mathbb{E}[T_{\ell, i-1}] + \mathbb{E}[T_{i+1, r}])\) (Linearität des Erwartungswerts + Satz über bedingten Erwartungswert), wobei \(t\) auf \(\{\ell, \ldots, r\}\) gleichverteilt ist (paarweise verschiedene Elemente). Daraus folgt durch Induktion über \(r - \ell\), dass \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Im Beweis von \(\mathbb{E}[T_{1,n}] \leq 2(n+1) \ln n + O(n)\) für QuickSort beobachtet man, dass \(\mathbb{E}[T_{\ell, r}]\) nur von \(r - \ell + 1\) abhängt, also nur von der Anzahl zu sortierender Elemente.
Dies motiviert die rekursive Definition von Zahlen \(t_n\) mit \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\):
\[t_n = {{c2::\begin{cases} 0, & \text{falls } n \leq 1, \\ \frac{1}{n} \sum_{i=0}^{n-1} (n - 1 + t_i + t_{n-i-1}), & \text{falls } n \geq 2. \end{cases} }}\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Im Beweis von \(\mathbb{E}[T_{1,n}] \leq 2(n+1) \ln n + O(n)\) für QuickSort beobachtet man, dass \(\mathbb{E}[T_{\ell, r}]\) nur von \(r - \ell + 1\) abhängt, also nur von der Anzahl zu sortierender Elemente.
Dies motiviert die rekursive Definition von Zahlen \(t_n\) mit \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\):
\[t_n = {{c2::\begin{cases} 0, & \text{falls } n \leq 1, \\ \frac{1}{n} \sum_{i=0}^{n-1} (n - 1 + t_i + t_{n-i-1}), & \text{falls } n \geq 2. \end{cases} }}\]
Herleitung: \(\mathbb{E}[T_{\ell, r}] = \sum_{i=\ell}^{r} \Pr[t = i] \cdot (r - \ell + \mathbb{E}[T_{\ell, i-1}] + \mathbb{E}[T_{i+1, r}])\) (Linearität des Erwartungswerts + Satz über bedingten Erwartungswert), wobei \(t\) auf \(\{\ell, \ldots, r\}\) gleichverteilt ist (paarweise verschiedene Elemente). Daraus folgt durch Induktion über \(r - \ell\), dass \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Im Beweis von \(\mathbb{E}[T_{1,n}] \leq 2(n+1) \ln n + O(n)\) für QuickSort beobachtet man, dass \(\mathbb{E}[T_{\ell, r}]\) {{c1::nur von \(r - \ell + 1\) abhängt}}, also nur von der Anzahl zu sortierender Elemente.<br><br>Dies motiviert die rekursive Definition von Zahlen \(t_n\) mit \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\):<br>\[t_n = {{c2::\begin{cases} 0, & \text{falls } n \leq 1, \\ \frac{1}{n} \sum_{i=0}^{n-1} (n - 1 + t_i + t_{n-i-1}), & \text{falls } n \geq 2. \end{cases} }}\] |
Im Beweis von \(\mathbb{E}[T_{1,n}] \leq 2(n+1) \ln n + O(n)\) für QuickSort beobachtet man, dass \(\mathbb{E}[T_{\ell, r}]\) nur von {{c1::\(r - \ell + 1\)}} abhängt, also nur von der Anzahl zu sortierender Elemente.<br><br>Dies motiviert die rekursive Definition von Zahlen \(t_n\) mit \(\mathbb{E}[T_{\ell, r}] = t_{r - \ell + 1}\):<br>\[t_n = {{c2::\begin{cases} 0, & \text{falls } n \leq 1, \\ \frac{1}{n} \sum_{i=0}^{n-1} (n - 1 + t_i + t_{n-i-1}), & \text{falls } n \geq 2. \end{cases} }}\] |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
Note 18: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: kXMy@|,s{F
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Beim Las-Vegas-Algorithmus für das Üppige-Auswahl-Problem ist \(T\) die Anzahl an Wiederholungen mit \(\Pr[T > k] = (1/2)^k\).
Was ist \(\mathbb{E}[T]\)? Gib zwei Herleitungen an.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Beim Las-Vegas-Algorithmus für das Üppige-Auswahl-Problem ist \(T\) die Anzahl an Wiederholungen mit \(\Pr[T > k] = (1/2)^k\).
Was ist \(\mathbb{E}[T]\)? Gib zwei Herleitungen an.
\[\mathbb{E}[T] = 2.\]Erwartete Laufzeit des Algorithmus: \(O(1)\), unabhängig von \(n\).
Direkter Ansatz (über \(\mathbb{E}[T] = \sum_{k \geq 1} \Pr[T \geq k]\)):
\[\begin{gathered}\mathbb{E}[T] = \sum_{k=1}^{\infty} \Pr[T \geq k] = \sum_{k=1}^{\infty} \Pr[T > k - 1] = \sum_{k=1}^{\infty} \left(\tfrac{1}{2}\right)^{k-1}\\= 1 + \tfrac{1}{2} + \tfrac{1}{4} + \tfrac{1}{8} + \cdots = 2.\end{gathered}\]Indirekter Ansatz (Rekursion via Fallunterscheidung im ersten Versuch):
\[\mathbb{E}[T] = \Pr[x_i = 1] \cdot 1 + \Pr[x_i = 0] \cdot (1 + \mathbb{E}[T']),\]wobei \(T'\) die Anzahl an weiteren Wiederholungen ist, falls die erste fehlschlägt. Da \(T'\) und \(T\) gleichverteilt sind:
\[\mathbb{E}[T] = \tfrac{1}{2} \cdot 1 + \tfrac{1}{2}(1 + \mathbb{E}[T]) = 1 + \tfrac{1}{2}\mathbb{E}[T] \;\Longrightarrow\; \mathbb{E}[T] = 2.\]
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Beim Las-Vegas-Algorithmus für das Üppige-Auswahl-Problem ist \(T\) die Anzahl an Wiederholungen mit \(\Pr[T > k] = (1/2)^k\).<br><br>Was ist \(\mathbb{E}[T]\)? Gib zwei Herleitungen an. |
| Back |
|
\[\mathbb{E}[T] = 2.\]Erwartete Laufzeit des Algorithmus: \(O(1)\), unabhängig von \(n\).<br><br><b>Direkter Ansatz</b> (über \(\mathbb{E}[T] = \sum_{k \geq 1} \Pr[T \geq k]\)):<br>\[\begin{gathered}\mathbb{E}[T] = \sum_{k=1}^{\infty} \Pr[T \geq k] = \sum_{k=1}^{\infty} \Pr[T > k - 1] = \sum_{k=1}^{\infty} \left(\tfrac{1}{2}\right)^{k-1}\\= 1 + \tfrac{1}{2} + \tfrac{1}{4} + \tfrac{1}{8} + \cdots = 2.\end{gathered}\]<b>Indirekter Ansatz</b> (Rekursion via Fallunterscheidung im ersten Versuch):<br>\[\mathbb{E}[T] = \Pr[x_i = 1] \cdot 1 + \Pr[x_i = 0] \cdot (1 + \mathbb{E}[T']),\]wobei \(T'\) die Anzahl an weiteren Wiederholungen ist, falls die erste fehlschlägt. Da \(T'\) und \(T\) gleichverteilt sind:<br>\[\mathbb{E}[T] = \tfrac{1}{2} \cdot 1 + \tfrac{1}{2}(1 + \mathbb{E}[T]) = 1 + \tfrac{1}{2}\mathbb{E}[T] \;\Longrightarrow\; \mathbb{E}[T] = 2.\] |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Note 19: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: o~85^tBatc
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Eine
Zufallsquelle liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:
- Physikalische Zufallsgeneratoren: Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente.
- Deterministische (Pseudo-)Zufallsgeneratoren: liefern, basierend auf einem Startwert (seed) \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht Reproduzierbarkeit, wenn man sich den Startwert merkt.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Eine
Zufallsquelle liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:
- Physikalische Zufallsgeneratoren: Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente.
- Deterministische (Pseudo-)Zufallsgeneratoren: liefern, basierend auf einem Startwert (seed) \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht Reproduzierbarkeit, wenn man sich den Startwert merkt.
In der Analyse geht man von idealen Zufallsgeneratoren aus. Bei der Anwendung muss man aber berücksichtigen, dass Pseudo-Zufallsgeneratoren das nur näherungsweise leisten.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Eine <b>Zufallsquelle</b> liefert nach vorgegebener Verteilung zufällige unabhängige Zufallsbits oder -zahlen. Zwei Typen:<ul><li><b>Physikalische Zufallsgeneratoren</b>: {{c1::Lottozahlen, Geigerzähler, Rauschen, Quantenexperimente::Beispiele?}}.</li><li><b>Deterministische (Pseudo-)Zufallsgeneratoren</b>: liefern, basierend auf einem {{c2::Startwert (seed)}} \(s\), eine Folge \(s \to r_0(s), r_1(s), r_2(s), \ldots\) Das ermöglicht {{c3::Reproduzierbarkeit, wenn man sich den Startwert merkt}}.</li></ul> |
| Extra |
|
In der Analyse geht man von idealen Zufallsgeneratoren aus. Bei der Anwendung muss man aber berücksichtigen, dass Pseudo-Zufallsgeneratoren das nur näherungsweise leisten. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 20: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: p,MlVR+5|=
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Welche Anteile von \(a \in [n-1]\) sind
Zertifikate dafür, dass \(n\)
nicht prim ist?
| Zertifikat | Bedingung an \(a\) | Anteil |
|---|
| Trivial | \(a \geq 2\) und \(a \mid n\) | \({{c1::> \tfrac{1}{n}}}\) |
| Euklid | \(\mathrm{ggT}(a, n) > 1\) | \({{c2::> \tfrac{1}{\sqrt{n}}}}\) |
| Fermat | \(a^{n-1} \not\equiv_n 1\) | {{c3::\(\geq \tfrac{1}{2}\), ausser \(n\) Carmichael}}
|
| Miller-Rabin | verletzt MR-Bedingung | {{c4::\(\geq \tfrac{3}{4}\) (\(n\) ungerade)}}
|
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Welche Anteile von \(a \in [n-1]\) sind
Zertifikate dafür, dass \(n\)
nicht prim ist?
| Zertifikat | Bedingung an \(a\) | Anteil |
|---|
| Trivial | \(a \geq 2\) und \(a \mid n\) | \({{c1::> \tfrac{1}{n}}}\) |
| Euklid | \(\mathrm{ggT}(a, n) > 1\) | \({{c2::> \tfrac{1}{\sqrt{n}}}}\) |
| Fermat | \(a^{n-1} \not\equiv_n 1\) | {{c3::\(\geq \tfrac{1}{2}\), ausser \(n\) Carmichael}}
|
| Miller-Rabin | verletzt MR-Bedingung | {{c4::\(\geq \tfrac{3}{4}\) (\(n\) ungerade)}}
|
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Welche Anteile von \(a \in [n-1]\) sind
Zertifikate dafür, dass \(n\)
nicht prim ist?
| Zertifikat | Bedingung an \(a\) | Anteil |
|---|
| Trivial | \(a \geq 2\) und \(a \mid n\) | \({{c1::> \tfrac{1}{n} }}\) |
| Euklid | \(\mathrm{ggT}(a, n) > 1\) | \({{c2::> \tfrac{1}{\sqrt{n} } }}\) |
| Fermat | \(a^{n-1} \not\equiv_n 1\) | {{c3::\(\geq \tfrac{1}{2}\), ausser \(n\) Carmichael}}
|
| Miller-Rabin | verletzt MR-Bedingung | {{c4::\(\geq \tfrac{3}{4}\) (\(n\) ungerade)}}
|
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Welche Anteile von \(a \in [n-1]\) sind
Zertifikate dafür, dass \(n\)
nicht prim ist?
| Zertifikat | Bedingung an \(a\) | Anteil |
|---|
| Trivial | \(a \geq 2\) und \(a \mid n\) | \({{c1::> \tfrac{1}{n} }}\) |
| Euklid | \(\mathrm{ggT}(a, n) > 1\) | \({{c2::> \tfrac{1}{\sqrt{n} } }}\) |
| Fermat | \(a^{n-1} \not\equiv_n 1\) | {{c3::\(\geq \tfrac{1}{2}\), ausser \(n\) Carmichael}}
|
| Miller-Rabin | verletzt MR-Bedingung | {{c4::\(\geq \tfrac{3}{4}\) (\(n\) ungerade)}}
|
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Welche Anteile von \(a \in [n-1]\) sind <b>Zertifikate</b> dafür, dass \(n\) <b>nicht prim</b> ist?<br><br><table style="border-collapse:collapse;border:1px solid;"><thead><tr><th style="border:1px solid;padding:4px;">Zertifikat</th><th style="border:1px solid;padding:4px;">Bedingung an \(a\)</th><th style="border:1px solid;padding:4px;">Anteil</th></tr></thead><tbody><tr><td style="border:1px solid;padding:4px;">Trivial</td><td style="border:1px solid;padding:4px;">\(a \geq 2\) und \(a \mid n\)</td><td style="border:1px solid;padding:4px;">\({{c1::> \tfrac{1}{n}}}\)</td></tr><tr><td style="border:1px solid;padding:4px;">Euklid</td><td style="border:1px solid;padding:4px;">\(\mathrm{ggT}(a, n) > 1\)</td><td style="border:1px solid;padding:4px;">\({{c2::> \tfrac{1}{\sqrt{n}}}}\)</td></tr><tr><td style="border:1px solid;padding:4px;">Fermat</td><td style="border:1px solid;padding:4px;">\(a^{n-1} \not\equiv_n 1\)</td><td style="border:1px solid;padding:4px;">{{c3::\(\geq \tfrac{1}{2}\), ausser \(n\) Carmichael}}<br></td></tr><tr><td style="border:1px solid;padding:4px;">Miller-Rabin</td><td style="border:1px solid;padding:4px;">verletzt MR-Bedingung</td><td style="border:1px solid;padding:4px;">{{c4::\(\geq \tfrac{3}{4}\) (\(n\) ungerade)}}<br></td></tr></tbody></table> |
Welche Anteile von \(a \in [n-1]\) sind <b>Zertifikate</b> dafür, dass \(n\) <b>nicht prim</b> ist?<br><br><table style="border-collapse:collapse;border:1px solid;"><thead><tr><th style="border:1px solid;padding:4px;">Zertifikat</th><th style="border:1px solid;padding:4px;">Bedingung an \(a\)</th><th style="border:1px solid;padding:4px;">Anteil</th></tr></thead><tbody><tr><td style="border:1px solid;padding:4px;">Trivial</td><td style="border:1px solid;padding:4px;">\(a \geq 2\) und \(a \mid n\)</td><td style="border:1px solid;padding:4px;">\({{c1::> \tfrac{1}{n} }}\)</td></tr><tr><td style="border:1px solid;padding:4px;">Euklid</td><td style="border:1px solid;padding:4px;">\(\mathrm{ggT}(a, n) > 1\)</td><td style="border:1px solid;padding:4px;">\({{c2::> \tfrac{1}{\sqrt{n} } }}\)</td></tr><tr><td style="border:1px solid;padding:4px;">Fermat</td><td style="border:1px solid;padding:4px;">\(a^{n-1} \not\equiv_n 1\)</td><td style="border:1px solid;padding:4px;">{{c3::\(\geq \tfrac{1}{2}\), ausser \(n\) Carmichael}}<br></td></tr><tr><td style="border:1px solid;padding:4px;">Miller-Rabin</td><td style="border:1px solid;padding:4px;">verletzt MR-Bedingung</td><td style="border:1px solid;padding:4px;">{{c4::\(\geq \tfrac{3}{4}\) (\(n\) ungerade)}}<br></td></tr></tbody></table> |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Note 21: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: r]#O[Wixhv
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Las-Vegas-Algorithmus für das Üppige-Auswahl-Problemrepeat:
i := Uniform({1, ..., n})
if x_i = 1: return iSei \(T\) die Anzahl an Wiederholungen. Da \(\Pr[x_i = 1] = \Pr[x_i = 0] = \tfrac{1}{2}\) für einen zufälligen Index \(i\), gilt:\[\Pr[T > k] = {{c1::\left(\tfrac{1}{2}\right)^k}}.\]Folglich:\[\Pr[T \leq k] = {{c2::1 - \left(\tfrac{1}{2}\right)^k}}.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Las-Vegas-Algorithmus für das Üppige-Auswahl-Problemrepeat:
i := Uniform({1, ..., n})
if x_i = 1: return iSei \(T\) die Anzahl an Wiederholungen. Da \(\Pr[x_i = 1] = \Pr[x_i = 0] = \tfrac{1}{2}\) für einen zufälligen Index \(i\), gilt:\[\Pr[T > k] = {{c1::\left(\tfrac{1}{2}\right)^k}}.\]Folglich:\[\Pr[T \leq k] = {{c2::1 - \left(\tfrac{1}{2}\right)^k}}.\]
\(T\) ist geometrisch verteilt mit Parameter \(p = \tfrac{1}{2}\).
Konkrete Werte: \(\Pr[T > 10] = 1/1024 < 0{,}001\), also \(\Pr[T \leq 10] > 0{,}999\). Mit \(\leq 20\) Wiederholungen erreicht man Wahrscheinlichkeit \(> 0{,}999999\).
Wichtig: \(T\) hängt nicht von \(n\) ab, weil die Erfolgswahrscheinlichkeit pro Versuch konstant \(\tfrac{1}{2}\) ist (genau die Hälfte der Bits sind \(1\)).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Las-Vegas-Algorithmus für das Üppige-Auswahl-Problem</b><pre>repeat:
i := Uniform({1, ..., n})
if x_i = 1: return i</pre>Sei \(T\) die Anzahl an Wiederholungen. Da \(\Pr[x_i = 1] = \Pr[x_i = 0] = \tfrac{1}{2}\) für einen zufälligen Index \(i\), gilt:\[\Pr[T > k] = {{c1::\left(\tfrac{1}{2}\right)^k}}.\]Folglich:\[\Pr[T \leq k] = {{c2::1 - \left(\tfrac{1}{2}\right)^k}}.\] |
| Extra |
|
\(T\) ist geometrisch verteilt mit Parameter \(p = \tfrac{1}{2}\).<br><br>Konkrete Werte: \(\Pr[T > 10] = 1/1024 < 0{,}001\), also \(\Pr[T \leq 10] > 0{,}999\). Mit \(\leq 20\) Wiederholungen erreicht man Wahrscheinlichkeit \(> 0{,}999999\).<br><br>Wichtig: \(T\) hängt <b>nicht von \(n\)</b> ab, weil die Erfolgswahrscheinlichkeit pro Versuch konstant \(\tfrac{1}{2}\) ist (genau die Hälfte der Bits sind \(1\)). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Note 22: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: s=]4*X3Fbz
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Kleiner fermatscher Satz
Ist \(n \in \mathbb{N}\) prim, so gilt für alle \(a \in [n-1]\):\[a^{n-1} \equiv_n 1\quad\text{(bzw.} a^{n-1} = 1 \text{ in } \mathbb{Z}_n^*).\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Kleiner fermatscher Satz
Ist \(n \in \mathbb{N}\) prim, so gilt für alle \(a \in [n-1]\):\[a^{n-1} \equiv_n 1\quad\text{(bzw.} a^{n-1} = 1 \text{ in } \mathbb{Z}_n^*).\]
Folgt aus dem Satz von Lagrange: für die Gruppe \(\mathbb{Z}_n^*\) gilt \(a^{|\mathbb{Z}_n^*|} = 1\) für alle \(a \in \mathbb{Z}_n^*\). Da \(n\) prim, ist \(|\mathbb{Z}_n^*| = \varphi(n) = n - 1\).
Allgemeiner gilt für jedes \(n\) und jedes \(a \in \mathbb{Z}_n^*\): \(a^{\varphi(n)} \equiv_n 1\) (Satz von Euler).
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Kleiner fermatscher Satz
Ist \(n \in \mathbb{N}\) prim, so gilt für alle \(a \in [n-1]\):\[a^{n-1} \equiv_n 1\quad\text{(bzw. } a^{n-1} = 1 \text{ in } \mathbb{Z}_n^*).\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Kleiner fermatscher Satz
Ist \(n \in \mathbb{N}\) prim, so gilt für alle \(a \in [n-1]\):\[a^{n-1} \equiv_n 1\quad\text{(bzw. } a^{n-1} = 1 \text{ in } \mathbb{Z}_n^*).\]
Folgt aus dem Satz von Lagrange: für die Gruppe \(\mathbb{Z}_n^*\) gilt \(a^{|\mathbb{Z}_n^*|} = 1\) für alle \(a \in \mathbb{Z}_n^*\). Da \(n\) prim, ist \(|\mathbb{Z}_n^*| = \varphi(n) = n - 1\).
Allgemeiner gilt für jedes \(n\) und jedes \(a \in \mathbb{Z}_n^*\): \(a^{\varphi(n)} \equiv_n 1\) (Satz von Euler).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Kleiner fermatscher Satz</b> <br>Ist \(n \in \mathbb{N}\) prim, so gilt für alle \(a \in [n-1]\):\[a^{n-1} \equiv_n {{c1::1}}\quad\text{(bzw.} a^{n-1} = 1 \text{ in } \mathbb{Z}_n^*).\] |
<b>Kleiner fermatscher Satz</b> <br>Ist \(n \in \mathbb{N}\) prim, so gilt für alle \(a \in [n-1]\):\[a^{n-1} \equiv_n {{c1::1}}\quad\text{(bzw. } a^{n-1} = 1 \text{ in } \mathbb{Z}_n^*).\] |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
Note 23: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: y}{[9<@l)v
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Monte-Carlo, Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\)
Sei \(\varepsilon > 0\) und \(A\) ein randomisierter Algorithmus, der immer JA oder NEIN ausgibt, mit\[\Pr[A(I) \text{ korrekt}] \geq \tfrac{1}{2} + \varepsilon.\]Sei \(A_\delta\) der Algorithmus, der\[N = {{c1::\left\lceil 4\varepsilon^{-2} \ln \delta^{-1} \right\rceil}}\]Aufrufe von \(A\) macht und die Mehrheit der erhaltenen Antworten ausgibt. Dann gilt:\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\]
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Monte-Carlo, Fehlerwahrscheinlichkeit \(< \tfrac{1}{2}\)
Sei \(\varepsilon > 0\) und \(A\) ein randomisierter Algorithmus, der immer JA oder NEIN ausgibt, mit\[\Pr[A(I) \text{ korrekt}] \geq \tfrac{1}{2} + \varepsilon.\]Sei \(A_\delta\) der Algorithmus, der\[N = {{c1::\left\lceil 4\varepsilon^{-2} \ln \delta^{-1} \right\rceil}}\]Aufrufe von \(A\) macht und die Mehrheit der erhaltenen Antworten ausgibt. Dann gilt:\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\]
Achtung: \(N\) skaliert hier quadratisch in \(\varepsilon^{-1}\) (statt linear wie bei einseitigem Fehler oder Las-Vegas) und nutzt nicht die erste richtige Antwort, sondern den Mehrheitsentscheid.
Beweis nutzt die Chernoff-Schranke \(\Pr[X \leq (1-\eta)\mathbb{E}[X]] \leq e^{-\eta^2 \mathbb{E}[X]/2}\) auf die Anzahl korrekter Aufrufe.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
<b>Monte-Carlo, Fehlerwahrscheinlichkeit </b>\(< \tfrac{1}{2}\) <br>Sei \(\varepsilon > 0\) und \(A\) ein randomisierter Algorithmus, der immer JA oder NEIN ausgibt, mit\[\Pr[A(I) \text{ korrekt}] \geq \tfrac{1}{2} + \varepsilon.\]Sei \(A_\delta\) der Algorithmus, der\[N = {{c1::\left\lceil 4\varepsilon^{-2} \ln \delta^{-1} \right\rceil}}\]Aufrufe von \(A\) macht und {{c2::die Mehrheit der erhaltenen Antworten}} ausgibt. Dann gilt:\[\Pr[A_\delta(I) \text{ korrekt}] \geq 1 - \delta.\] |
| Extra |
|
Achtung: \(N\) skaliert hier <b>quadratisch</b> in \(\varepsilon^{-1}\) (statt linear wie bei einseitigem Fehler oder Las-Vegas) und nutzt nicht die erste richtige Antwort, sondern den Mehrheitsentscheid.<br><br>Beweis nutzt die Chernoff-Schranke \(\Pr[X \leq (1-\eta)\mathbb{E}[X]] \leq e^{-\eta^2 \mathbb{E}[X]/2}\) auf die Anzahl korrekter Aufrufe. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
Note 24: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: z0k}SHzjrH
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Jeder deterministische Algorithmus für das Üppige-Auswahl-Problem benötigt Laufzeit \(\Omega(n)\).
Beweisidee (Adversary-Argument):
Für fixen Algorithmus konstruieren wir die Instanz schrittweise. Auf jede Anfrage \(x_i\) des Algorithmus antworten wir mit \(0\), solange wir noch nicht \(n/2\) Nullen platziert haben. Sobald \(n/2\) Nullen platziert sind, füllen wir die restlichen Positionen mit \(1\) auf. Damit liest der Algorithmus mindestens \(n/2 + 1\) Eingabezahlen, bevor er eine \(1\) sieht.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Jeder deterministische Algorithmus für das Üppige-Auswahl-Problem benötigt Laufzeit \(\Omega(n)\).
Beweisidee (Adversary-Argument):
Für fixen Algorithmus konstruieren wir die Instanz schrittweise. Auf jede Anfrage \(x_i\) des Algorithmus antworten wir mit \(0\), solange wir noch nicht \(n/2\) Nullen platziert haben. Sobald \(n/2\) Nullen platziert sind, füllen wir die restlichen Positionen mit \(1\) auf. Damit liest der Algorithmus mindestens \(n/2 + 1\) Eingabezahlen, bevor er eine \(1\) sieht.
Das ist ein typisches Adversary-Argument: Der "Gegenspieler" entscheidet die Eingabe erst während der Ausführung, immer so, dass der Algorithmus möglichst lange braucht. Da der Algorithmus deterministisch ist, weiss der Adversary genau, welche Position als nächstes gelesen wird, und kann sie auf \(0\) setzen.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
|
Jeder deterministische Algorithmus für das Üppige-Auswahl-Problem benötigt Laufzeit \(\Omega({{c1::n}})\).<br><br><b>Beweisidee (Adversary-Argument):</b> <br>Für fixen Algorithmus konstruieren wir die Instanz schrittweise. Auf jede Anfrage \(x_i\) des Algorithmus antworten wir mit {{c2::\(0\)}}, solange wir noch nicht \(n/2\) Nullen platziert haben. Sobald \(n/2\) Nullen platziert sind, füllen wir die restlichen Positionen mit \(1\) auf. Damit liest der Algorithmus mindestens {{c3::\(n/2 + 1\)}} Eingabezahlen, bevor er eine \(1\) sieht. |
| Extra |
|
Das ist ein typisches <b>Adversary-Argument</b>: Der "Gegenspieler" entscheidet die Eingabe erst während der Ausführung, immer so, dass der Algorithmus möglichst lange braucht. Da der Algorithmus deterministisch ist, weiss der Adversary genau, welche Position als nächstes gelesen wird, und kann sie auf \(0\) setzen. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::5._Üppige-Auswahl-Problem
Note 25: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: )S?6%dT4^L
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Für einen Winkel \(\omega\) im Einheitskreis sei \(P\) der Punkt auf der Kreislinie, der dem Winkel entspricht. Dann gilt:
- \(\sin(\omega) = {{c1::\text{y-Koordinate von } P}}\)
- \(\cos(\omega) = {{c2::\text{x-Koordinate von } P}}\)
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Für einen Winkel \(\omega\) im Einheitskreis sei \(P\) der Punkt auf der Kreislinie, der dem Winkel entspricht. Dann gilt:
- \(\sin(\omega) = {{c1::\text{y-Koordinate von } P}}\)
- \(\cos(\omega) = {{c2::\text{x-Koordinate von } P}}\)
Daraus folgt unmittelbar (Pythagoras): \(\cos^2(\omega) + \sin^2(\omega) = 1\).
After
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Für einen Winkel \(\omega\) im Einheitskreis sei \(P\) der Punkt auf der Kreislinie, der dem Winkel entspricht. Dann gilt:
- \(\sin(\omega) = {{c1::\text{y-Koordinate von } P}}\)
- \(\cos(\omega) = {{c1::\text{x-Koordinate von } P}}\)
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Für einen Winkel \(\omega\) im Einheitskreis sei \(P\) der Punkt auf der Kreislinie, der dem Winkel entspricht. Dann gilt:
- \(\sin(\omega) = {{c1::\text{y-Koordinate von } P}}\)
- \(\cos(\omega) = {{c1::\text{x-Koordinate von } P}}\)
Daraus folgt unmittelbar (Pythagoras): \(\cos^2(\omega) + \sin^2(\omega) = 1\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Für einen Winkel \(\omega\) im Einheitskreis sei \(P\) der Punkt auf der Kreislinie, der dem Winkel entspricht. Dann gilt:<ul><li>\(\sin(\omega) = {{c1::\text{y-Koordinate von } P}}\)</li><li>\(\cos(\omega) = {{c2::\text{x-Koordinate von } P}}\)</li></ul> |
Für einen Winkel \(\omega\) im Einheitskreis sei \(P\) der Punkt auf der Kreislinie, der dem Winkel entspricht. Dann gilt:<ul><li>\(\sin(\omega) = {{c1::\text{y-Koordinate von } P}}\)</li><li>\(\cos(\omega) = {{c1::\text{x-Koordinate von } P}}\)</li></ul> |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Note 26: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: 99zvEoaswY
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Der Übergang \(f(x) \rightarrow g(x) = f(x + k)\) entspricht einer Verschiebung in horizontaler Richtung:
- \(k < 0\): Verschiebung in positiver horizontaler Richtung um \(|k|\) Einheiten.
- \(k > 0\): Verschiebung in negativer horizontaler Richtung um \(|k|\) Einheiten.
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Der Übergang \(f(x) \rightarrow g(x) = f(x + k)\) entspricht einer Verschiebung in horizontaler Richtung:
- \(k < 0\): Verschiebung in positiver horizontaler Richtung um \(|k|\) Einheiten.
- \(k > 0\): Verschiebung in negativer horizontaler Richtung um \(|k|\) Einheiten.
Achtung: Das Vorzeichen wirkt entgegengesetzt zur Intuition. \(f(x-3)\) verschiebt nach rechts um 3, weil der "alte" Funktionswert \(f(0)\) jetzt erst bei \(x = 3\) erreicht wird.
After
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Der Übergang \(f(x) \rightarrow g(x) = f(x + k)\) entspricht einer Verschiebung in horizontaler Richtung:
- \(k < 0\): Verschiebung in positiver horizontaler Richtung um \(|k|\) Einheiten.
- \(k > 0\): Verschiebung in negativer horizontaler Richtung um \(|k|\) Einheiten.
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Der Übergang \(f(x) \rightarrow g(x) = f(x + k)\) entspricht einer Verschiebung in horizontaler Richtung:
- \(k < 0\): Verschiebung in positiver horizontaler Richtung um \(|k|\) Einheiten.
- \(k > 0\): Verschiebung in negativer horizontaler Richtung um \(|k|\) Einheiten.
Achtung: Das Vorzeichen wirkt entgegengesetzt zur Intuition. \(f(x-3)\) verschiebt nach rechts um 3, weil der "alte" Funktionswert \(f(0)\) jetzt erst bei \(x = 3\) erreicht wird.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Der Übergang \(f(x) \rightarrow g(x) = f(x + k)\) entspricht einer Verschiebung in horizontaler Richtung:<ul><li>\(k < 0\): Verschiebung in {{c1::positiver}} horizontaler Richtung um \(|k|\) Einheiten.</li><li>\(k > 0\): Verschiebung in {{c2::negativer}} horizontaler Richtung um \(|k|\) Einheiten.</li></ul> |
Der Übergang \(f(x) \rightarrow g(x) = f(x + k)\) entspricht einer Verschiebung in horizontaler Richtung:<ul><li>\(k < 0\): Verschiebung in {{c1::positiver}} horizontaler Richtung um \(|k|\) Einheiten.</li><li>\(k > 0\): Verschiebung in {{c1::negativer}} horizontaler Richtung um \(|k|\) Einheiten.</li></ul> |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Note 27: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: ==Fn-80|4a
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\).
Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\).
Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
(Wurzelkriterium)
Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber
nicht umgekehrt.
Proof:
- Convergence \(L < 1\)
-
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).
- Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)
- So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).
- Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)
-
Divergence \(L > 1\)
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).
- Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)
- So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence
After
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Wurzelkriterium
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\).
Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Wurzelkriterium
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\).
Dann:
- \(\rho < 1\) \(\implies\) \(\sum a_n\) konvergiert absolut
- \(\rho > 1\) \(\implies\) \(\sum a_n\) divergiert
- \(\rho = 1\) \(\implies\) keine Aussage möglich
Proof Included
Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber
nicht umgekehrt.
Proof:
- Convergence \(L < 1\)
-
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).
- Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)
- So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).
- Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)
-
Divergence \(L > 1\)
- \(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).
- Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)
- So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\). <br>Dann:<br><ul><li>\(\rho < 1\) \(\implies\) {{c1::\(\sum a_n\) konvergiert <b>absolut</b>}}</li><li>\(\rho > 1\) \(\implies\) {{c1::\(\sum a_n\) divergiert}}</li><li>\(\rho = 1\) \(\implies\) {{c1::<b>keine Aussage</b> möglich}}<br></li></ul><i>Proof Included</i> |
Wurzelkriterium<br><br>Sei \(\rho = {{c4:: \limsup_{n\to\infty} |a_n|^{1/n} }}\). <br>Dann:<br><ul><li>\(\rho < 1\) \(\implies\) {{c1::\(\sum a_n\) konvergiert <b>absolut</b>}}</li><li>\(\rho > 1\) \(\implies\) {{c1::\(\sum a_n\) divergiert}}</li><li>\(\rho = 1\) \(\implies\) {{c1::<b>keine Aussage</b> möglich}}<br></li></ul><i>Proof Included</i> |
| Extra |
(Wurzelkriterium)<br><br>Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber <b>nicht umgekehrt</b>.<br><div><div><br></div></div><div><div><strong>Proof:</strong> </div><ol>
<li>Convergence \(L < 1\)</li><li>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).</li>
<li>Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)</li>
<li>So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).</li>
<li>Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)</li>
</ol>
</li>
<li>
<div>Divergence \(L > 1\)</div>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).</li>
<li>Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)</li>
<li>So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence </li></ol></li></ol></div> |
Wenn Quotientenkriterium versagt (\(\rho=1\)), versagt auch das Wurzelkriterium — aber <b>nicht umgekehrt</b>.<br><div><div><br></div></div><div><div><strong>Proof:</strong> </div><ol>
<li>Convergence \(L < 1\)</li><li>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right| < 1\).</li>
<li>Choose \(q\) with \(L < q < 1\). Since \(\limsup \left| {a_n}^{1/n} \right| = L\), there exists \(N\) such that for all \(n \geq N: \left| {a_n}^{1/n} \right| \leq\) \(q \implies \left| a_n \right| \leq q^n\)</li>
<li>So \(\sum_{n=N}^{\infty} \left| a_n \right| \leq\) \(\sum_{n=N}^{\infty} q^n < \infty\) (geometric series, \(q < 1\)).</li>
<li>Hence \(\sum \left| a_n \right|\) converges. (Majorantenkriterium)</li>
</ol>
</li>
<li>
<div>Divergence \(L > 1\)</div>
<ol>
<li>\(\sum a_n \geq 0\), \(\displaystyle L = \limsup_{n\to\infty} \left| {a_n}^{1/n} \right|\) \(> 1\).</li>
<li>Since \(\limsup \left| {a_n}^{1/n} \right| > 1\), there exist infinitely many \(n\) such that: \(\left| {a_n}^{1/n} \right| >\) \(1 \implies |a_n| > 1\)</li>
<li>So \(|a_n| \not\to 0\), hence \(\sum a_n\) diverges.Convergence </li></ol></li></ol></div> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Note 28: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: _`R_]9P+k8
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Eigenschaften der trigonometrischen Funktionen:
- \(\sin\), \(\cos\), \(\tan\) sind periodisch.
- Der Tangens hat für \(\omega = \pm \frac{(2n+1)\pi}{2}\), \(n \in \mathbb{N}\), eine vertikale Asymptote.
- \(\sin\) ist eine ungerade Funktion: \(\sin(-x) = -\sin(x)\).
- \(\cos\) ist eine gerade Funktion: \(\cos(-x) = \cos(x)\).
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Eigenschaften der trigonometrischen Funktionen:
- \(\sin\), \(\cos\), \(\tan\) sind periodisch.
- Der Tangens hat für \(\omega = \pm \frac{(2n+1)\pi}{2}\), \(n \in \mathbb{N}\), eine vertikale Asymptote.
- \(\sin\) ist eine ungerade Funktion: \(\sin(-x) = -\sin(x)\).
- \(\cos\) ist eine gerade Funktion: \(\cos(-x) = \cos(x)\).
After
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Eigenschaften der trigonometrischen Funktionen:
- \(\sin\), \(\cos\), \(\tan\) sind periodisch.
- Der Tangens hat für \(\omega = \pm \frac{(2n+1)\pi}{2}\), \(n \in \mathbb{N}\), eine vertikale Asymptote.
- \(\sin\) ist eine ungerade Funktion: \(\sin(-x) = -\sin(x)\).
- \(\cos\) ist eine gerade Funktion: \(\cos(-x) = \cos(x)\).
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Eigenschaften der trigonometrischen Funktionen:
- \(\sin\), \(\cos\), \(\tan\) sind periodisch.
- Der Tangens hat für \(\omega = \pm \frac{(2n+1)\pi}{2}\), \(n \in \mathbb{N}\), eine vertikale Asymptote.
- \(\sin\) ist eine ungerade Funktion: \(\sin(-x) = -\sin(x)\).
- \(\cos\) ist eine gerade Funktion: \(\cos(-x) = \cos(x)\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eigenschaften der trigonometrischen Funktionen:<br><ul><li>\(\sin\), \(\cos\), \(\tan\) sind {{c1::periodisch}}.</li><li>Der Tangens hat für \(\omega = \pm \frac{(2n+1)\pi}{2}\), \(n \in \mathbb{N}\), eine {{c2::vertikale Asymptote}}.</li><li>\(\sin\) ist eine {{c3::ungerade}} Funktion: \(\sin(-x) = -\sin(x)\).</li><li>\(\cos\) ist eine {{c4::gerade}} Funktion: \(\cos(-x) = \cos(x)\).</li></ul> |
Eigenschaften der trigonometrischen Funktionen:<br><ul><li>\(\sin\), \(\cos\), \(\tan\) sind {{c1::periodisch}}.</li><li>Der Tangens hat für \(\omega = \pm \frac{(2n+1)\pi}{2}\), \(n \in \mathbb{N}\), eine {{c2::vertikale Asymptote}}.</li><li>\(\sin\) ist eine {{c3::ungerade}} Funktion: \({{c3::\sin(-x) = -\sin(x)}}\).</li><li>\(\cos\) ist eine {{c4::gerade}} Funktion: \({{c4::\cos(-x) = \cos(x)}}\).</li></ul> |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::5._Trigonometrische
Note 29: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: j1*KfG}T{:
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heisst
bedingt konvergent, wenn sie
konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert.
Counterexample Included
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heisst
bedingt konvergent, wenn sie
konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert.
Counterexample Included
(D.h. nicht absolut konvergiert..)
Beispiel:
\(\sum \frac{(-1)^n}{n}\) ist bedingt konvergent.
After
Front
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heisst
bedingt konvergent, wenn sie
konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert.
Example Included
Back
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Eine Reihe heisst
bedingt konvergent, wenn sie
konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert.
Example Included
(D.h. nicht absolut konvergiert..)
Beispiel:
\(\sum \frac{(-1)^n}{n}\) ist bedingt konvergent.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Eine Reihe heisst <b>bedingt konvergent</b>, wenn sie {{c1::konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert}}.<div><br></div><div><i>Counterexample Included</i></div> |
Eine Reihe heisst <b>bedingt konvergent</b>, wenn sie {{c1::konvergiert, aber die Reihe der Beträge \(\sum |a_k|\) divergiert}}.<div><br></div><div><i>Example Included</i></div> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::1._Definitionen
Note 30: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: m^V,=Dr7q]
modified
Before
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Wir betrachten den Übergang \(f(x) \rightarrow g(x) = k \cdot f(x)\):
- \(k > 1\): Graph wird in y-Richtung von der x-Achse weg gestreckt.
- \(0 < k < 1\): Graph wird in y-Richtung zur x-Achse hin gestaucht.
- \(k < 0\): Graph wird zusätzlich an der x-Achse gespiegelt.
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Wir betrachten den Übergang \(f(x) \rightarrow g(x) = k \cdot f(x)\):
- \(k > 1\): Graph wird in y-Richtung von der x-Achse weg gestreckt.
- \(0 < k < 1\): Graph wird in y-Richtung zur x-Achse hin gestaucht.
- \(k < 0\): Graph wird zusätzlich an der x-Achse gespiegelt.
Die multiplikative Konstante wirkt auf den Funktionswert, also auf die y-Achse.
After
Front
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Wir betrachten den Übergang \(f(x) \rightarrow g(x) = k \cdot f(x)\):
- \(k > 1\): Graph wird in y-Richtung von der x-Achse weg gestreckt.
- \(0 < k < 1\): Graph wird in y-Richtung zur x-Achse hin gestaucht.
- \(k < 0\): Graph wird zusätzlich an der x-Achse gespiegelt.
Back
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Wir betrachten den Übergang \(f(x) \rightarrow g(x) = k \cdot f(x)\):
- \(k > 1\): Graph wird in y-Richtung von der x-Achse weg gestreckt.
- \(0 < k < 1\): Graph wird in y-Richtung zur x-Achse hin gestaucht.
- \(k < 0\): Graph wird zusätzlich an der x-Achse gespiegelt.
Die multiplikative Konstante wirkt auf den Funktionswert, also auf die y-Achse.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Wir betrachten den Übergang \(f(x) \rightarrow g(x) = k \cdot f(x)\):<ul><li>\(k > 1\): Graph wird in y-Richtung {{c1::von der x-Achse weg gestreckt}}.</li><li>\(0 < k < 1\): Graph wird in y-Richtung {{c2::zur x-Achse hin gestaucht}}.</li><li>\(k < 0\): Graph wird zusätzlich {{c3::an der x-Achse gespiegelt}}.</li></ul> |
Wir betrachten den Übergang \(f(x) \rightarrow g(x) = k \cdot f(x)\):<ul><li>\(k > 1\): Graph wird in y-Richtung {{c1::von der x-Achse weg gestreckt}}.</li><li>\(0 < k < 1\): Graph wird in y-Richtung {{c1::zur x-Achse hin gestaucht}}.</li><li>\(k < 0\): Graph wird zusätzlich {{c2::an der x-Achse gespiegelt}}.</li></ul> |
Tags:
ETH::2._Semester::Analysis::4._Funktionen::4._Elementare_Funktionen::6._Transformationen
Note 31: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: 1*Jyz+ZJLF
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
When constructing mutex algorithms from atomic registers, three assumptions are made: atomic reads and writes of primitive-type variables; no reorderings of read/write sequences (not true in practice; assumed here for simplicity); threads that enter a critical section eventually leave it. About progress outside the critical section, no assumption is made.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
When constructing mutex algorithms from atomic registers, three assumptions are made: atomic reads and writes of primitive-type variables; no reorderings of read/write sequences (not true in practice; assumed here for simplicity); threads that enter a critical section eventually leave it. About progress outside the critical section, no assumption is made.
Threads may therefore stall, die, or pause arbitrarily long outside a CS. This matters for arguments like starvation freedom: an algorithm must not rely on the "other" thread continuing to make progress.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
When constructing mutex algorithms from atomic registers, three assumptions are made:
- atomic reads and writes of primitive-type variables
- no reorderings of read/write sequences (not true in practice; assumed here for simplicity)
- threads that enter a critical section eventually leave it.
About progress
outside the critical section, no assumption is made.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
When constructing mutex algorithms from atomic registers, three assumptions are made:
- atomic reads and writes of primitive-type variables
- no reorderings of read/write sequences (not true in practice; assumed here for simplicity)
- threads that enter a critical section eventually leave it.
About progress
outside the critical section, no assumption is made.
Threads may therefore stall, die, or pause arbitrarily long outside a CS. This matters for arguments like starvation freedom: an algorithm must not rely on the "other" thread continuing to make progress.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
When constructing mutex algorithms from atomic registers, three assumptions are made: {{c1::atomic reads and writes of primitive-type variables}}; {{c1::no reorderings of read/write sequences (not true in practice; assumed here for simplicity)}}; {{c1::threads that enter a critical section eventually leave it}}. About progress {{c2::outside the critical section, no assumption is made}}. |
When constructing mutex algorithms from atomic registers, three assumptions are made: <br><ol><li>{{c1::atomic reads and writes of primitive-type variables}}</li><li>{{c2::no reorderings of read/write sequences (not true in practice; assumed here for simplicity)}} </li><li>{{c3::threads that enter a critical section eventually leave it}}. </li></ol>About progress {{c4::outside the critical section, no assumption is made}}.<br> |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::5._Locks_with_Atomic_Registers
Note 32: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: 7kNVF}Z|oG
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Which memory operations actually get reordered depends on the hardware architecture; e.g. AMD64 (x86) differs significantly from ARM: x86 essentially only allows "stores reordered after loads", while ARM, POWER, and Alpha permit almost every kind of reordering.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Which memory operations actually get reordered depends on the hardware architecture; e.g. AMD64 (x86) differs significantly from ARM: x86 essentially only allows "stores reordered after loads", while ARM, POWER, and Alpha permit almost every kind of reordering.
Consequence: correct multi-threaded code that "works" on x86 can break on ARM without any change to the source. This is exactly why a memory model is needed as a language-level guarantee.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Which memory operations actually get reordered depends on the hardware architecture.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Which memory operations actually get reordered depends on the hardware architecture.
E.g. AMD64 (x86) differs significantly from ARM: x86 essentially only allows "stores reordered after loads", while ARM, POWER, and Alpha permit almost every kind of reordering.
Consequence: correct multi-threaded code that "works" on x86 can break on ARM without any change to the source. This is exactly why a memory model is needed as a language-level guarantee.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Which memory operations actually get reordered depends on the {{c1::hardware architecture}}; e.g. {{c2::AMD64 (x86) differs significantly from ARM}}: x86 essentially only allows "stores reordered after loads", while ARM, POWER, and Alpha permit almost every kind of reordering. |
Which memory operations actually get reordered depends on the {{c1::hardware architecture}}. |
| Extra |
Consequence: correct multi-threaded code that "works" on x86 can break on ARM without any change to the source. This is exactly why a memory model is needed as a language-level guarantee. |
E.g. AMD64 (x86) differs significantly from ARM: x86 essentially only allows "stores reordered after loads", while ARM, POWER, and Alpha permit almost every kind of reordering.<br><br>Consequence: correct multi-threaded code that "works" on x86 can break on ARM without any change to the source. This is exactly why a memory model is needed as a language-level guarantee. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Note 33: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: :UEQ*@nnq1
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Synchronization Order (SO) in the JMM is a total order over all synchronization actions; all threads see the SA in the same order; the SA inside a thread occur in PO; SO is consistent: every read in SO sees the latest write in SO.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Synchronization Order (SO) in the JMM is a total order over all synchronization actions; all threads see the SA in the same order; the SA inside a thread occur in PO; SO is consistent: every read in SO sees the latest write in SO.
The globality of SO is the reason that volatile and locks can synchronise threads at all.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Synchronization Order (SO) in the JMM is a total order over all synchronization actions.
All threads see the SA in the same order.
The SA inside a thread occur in PO.
SO is consistent: every read in SO sees the latest write in SO.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Synchronization Order (SO) in the JMM is a total order over all synchronization actions.
All threads see the SA in the same order.
The SA inside a thread occur in PO.
SO is consistent: every read in SO sees the latest write in SO.
The globality of SO is the reason that volatile and locks can synchronise threads at all.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
The <i>Synchronization Order (SO)</i> in the JMM is {{c1::a total order over all synchronization actions}}; {{c1::all threads see the SA in the same order}}; {{c1::the SA inside a thread occur in PO}}; {{c1::SO is consistent: every read in SO sees the latest write in SO}}. |
The <i>Synchronization Order (SO)</i> in the JMM is {{c1::a total order over all synchronization actions}}. <br>All threads see the SA in {{c2::the same}} order. <br>The SA inside a thread occur in {{c3::PO}}. <br>SO is {{c4::consistent: every read in SO sees the latest write in SO}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Note 34: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: @rzMyS*OnN
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Accesses to volatile fields in Java do not count as a data race. In terms of performance, volatile is slower than ordinary fields, but faster than locks.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Accesses to volatile fields in Java do not count as a data race. In terms of performance, volatile is slower than ordinary fields, but faster than locks.
Recommendation: only for experts; otherwise use the standard library (java.util.concurrent, AtomicInteger, …).
Caveat: volatile guarantees visibility, but not atomicity of compound operations like i++.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Accesses to volatile fields in Java do not count as a data race.
In terms of performance, volatile is slower than ordinary fields, but faster than locks.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Accesses to volatile fields in Java do not count as a data race.
In terms of performance, volatile is slower than ordinary fields, but faster than locks.
Recommendation: only for experts; otherwise use the standard library (java.util.concurrent, AtomicInteger, …).
Caveat: volatile guarantees visibility, but not atomicity of compound operations like i++.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Accesses to <code>volatile</code> fields in Java do {{c1::not count as a data race}}. In terms of performance, <code>volatile</code> is {{c2::slower than ordinary fields, but faster than locks}}. |
Accesses to <code>volatile</code> fields in Java do not count as {{c1::a data race}}. <br><br>In terms of performance, <code>volatile</code> is {{c2::slower than ordinary fields, but faster than locks}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Note 35: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: MH1KRE1DzH
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Program Order (PO) in the JMM is a total order over the actions of a single thread, defined on an execution trace. PO gives no ordering guarantee for memory accesses and is not total across threads.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Program Order (PO) in the JMM is a total order over the actions of a single thread, defined on an execution trace. PO gives no ordering guarantee for memory accesses and is not total across threads.
Its only purpose is to link an execution back to the original program.
Intra-thread consistency: per thread, PO is consistent with the thread's isolated execution. E.g. taking the else-branch of an if whose condition was true makes the execution invalid.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Program Order (PO) in the JMM is a total order over the actions of a single thread, defined on an execution trace.
PO gives no ordering guarantee for memory accesses and is not total across threads.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Program Order (PO) in the JMM is a total order over the actions of a single thread, defined on an execution trace.
PO gives no ordering guarantee for memory accesses and is not total across threads.
Its only purpose is to link an execution back to the original program.
Intra-thread consistency: per thread, PO is consistent with the thread's isolated execution. E.g. taking the else-branch of an if whose condition was true makes the execution invalid.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<i>Program Order (PO)</i> in the JMM is a {{c1::total order over the actions of a single thread, defined on an execution trace}}. PO gives {{c2::no ordering guarantee for memory accesses}} and is {{c2::not total across threads}}. |
<i>Program Order (PO)</i> in the JMM is a {{c1::total order over the actions of a single thread, defined on an execution trace}}. <br><br>PO gives no {{c2::ordering guarantee for memory accesses}} and is {{c2::not total across threads}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Note 36: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: Pa^@bE6s8n
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
In the classic x86 example with \(x{=}y{=}0\), thread 1: x=1; j=y; and thread 2: y=1; i=x;, besides \((1,1), (0,1), (1,0)\), the outcome \((i,j) = (0,0)\) is also possible, because under x86's "stores reordered after loads" rule the load (j=y / i=x) may be executed before the store (x=1 / y=1).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
In the classic x86 example with \(x{=}y{=}0\), thread 1: x=1; j=y; and thread 2: y=1; i=x;, besides \((1,1), (0,1), (1,0)\), the outcome \((i,j) = (0,0)\) is also possible, because under x86's "stores reordered after loads" rule the load (j=y / i=x) may be executed before the store (x=1 / y=1).
Both threads thus read \(y\) and \(x\) while still 0, before either store becomes visible. This is a simple, actually-reproducible reordering effect on x86 (StoreLoad).
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Here, besides \((1,1), (0,1), (1,0)\), the outcome \((i,j) = (0,0)\) is also possible, because
under x86's "stores reordered after loads" rule the load (j=y / i=x) may be executed before the store (x=1 / y=1).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Here, besides \((1,1), (0,1), (1,0)\), the outcome \((i,j) = (0,0)\) is also possible, because
under x86's "stores reordered after loads" rule the load (j=y / i=x) may be executed before the store (x=1 / y=1).
Both threads thus read \(y\) and \(x\) while still 0, before either store becomes visible. This is a simple, actually-reproducible reordering effect on x86 (StoreLoad).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
In the classic x86 example with \(x{=}y{=}0\), thread 1: <code>x=1; j=y;</code> and thread 2: <code>y=1; i=x;</code>, besides \((1,1), (0,1), (1,0)\), the outcome {{c1::\((i,j) = (0,0)\) is also possible}}, because under x86's "stores reordered after loads" rule {{c2::the load (<code>j=y</code> / <code>i=x</code>) may be executed before the store (<code>x=1</code> / <code>y=1</code>)}}. |
<img src="paste-578cfc8f8670d5608216e60d3e0cd1611334a9cf.jpg"><br><br>Here, besides \((1,1), (0,1), (1,0)\), the outcome \((i,j) = (0,0)\) is also possible, because {{c1::under x86's "stores reordered after loads" rule the load (<code>j=y</code> / <code>i=x</code>) may be executed before the store (<code>x=1</code> / <code>y=1</code>)}}. |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::3._Memory_Model
Note 37: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: a+AQXsL|IC
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::2._Memory_Hierarchy
Typical latencies in the memory hierarchy of one core (order of magnitude): registers ~0.5 ns, L1 cache ~1 ns, L2 cache ~7 ns, system memory ~100 ns.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::2._Memory_Hierarchy
Typical latencies in the memory hierarchy of one core (order of magnitude): registers ~0.5 ns, L1 cache ~1 ns, L2 cache ~7 ns, system memory ~100 ns.
Trade-off across the hierarchy: top is fast, low latency, high cost, low capacity; bottom is slow, high latency, low cost, high capacity.
Factor between register and RAM: roughly \(200{\times}\).
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::2._Memory_Hierarchy
Typical latencies in the memory hierarchy of one core (order of magnitude):
- registers ~0.5 ns,
- L1 cache ~1 ns,
- L2 cache ~7 ns,
- system memory ~100 ns.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::2._Memory_Hierarchy
Typical latencies in the memory hierarchy of one core (order of magnitude):
- registers ~0.5 ns,
- L1 cache ~1 ns,
- L2 cache ~7 ns,
- system memory ~100 ns.
Trade-off across the hierarchy: top is fast, low latency, high cost, low capacity; bottom is slow, high latency, low cost, high capacity.
Factor between register and RAM: roughly \(200{\times}\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Typical latencies in the memory hierarchy of one core (order of magnitude): registers {{c1::~0.5 ns}}, L1 cache {{c1::~1 ns}}, L2 cache {{c1::~7 ns}}, system memory {{c1::~100 ns}}. |
Typical latencies in the memory hierarchy of one core (order of magnitude): <br><ol><li>{{c1::registers ~0.5 ns}}, </li><li>{{c1::L1 cache ~1 ns}}, </li><li>{{c1::L2 cache ~7 ns}}, </li><li>{{c1::system memory ~100 ns}}.</li></ol> |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::2._Memory_Hierarchy
Note 38: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: m;emJ<(X_K
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Java Memory Model (JMM) defines actions such as read(x):1 ("read variable x; the value read is 1"). Executions combine actions with four orderings: Program Order (PO), Synchronizes-With (SW), Synchronization Order (SO), Happens-Before (HB).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Java Memory Model (JMM) defines actions such as read(x):1 ("read variable x; the value read is 1"). Executions combine actions with four orderings: Program Order (PO), Synchronizes-With (SW), Synchronization Order (SO), Happens-Before (HB).
The JMM restricts the allowed outcomes of programs. Without volatile / synchronized the result is essentially "arbitrary".
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Java Memory Model (JMM) defines
actions such as
read(x):1 ("read variable x; the value read is 1").
Executions combine actions with four orderings:
- Program Order (PO),
- Synchronizes-With (SW),
- Synchronization Order (SO),
- Happens-Before (HB).
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
The Java Memory Model (JMM) defines
actions such as
read(x):1 ("read variable x; the value read is 1").
Executions combine actions with four orderings:
- Program Order (PO),
- Synchronizes-With (SW),
- Synchronization Order (SO),
- Happens-Before (HB).
The JMM restricts the allowed outcomes of programs. Without volatile / synchronized the result is essentially "arbitrary".
Field-by-field Comparison
| Field |
Before |
After |
| Text |
The Java Memory Model (JMM) defines <i>actions</i> such as {{c1::<code>read(x):1</code> ("read variable x; the value read is 1")}}. <i>Executions</i> combine actions with four orderings: {{c2::Program Order (PO), Synchronizes-With (SW), Synchronization Order (SO), Happens-Before (HB)}}. |
The Java Memory Model (JMM) defines <i>actions</i> such as {{c1::<code>read(x):1</code> ("read variable x; the value read is 1")}}. <br><i><br>Executions</i> combine actions with four orderings:<br><ol><li>{{c2::Program Order (PO)}}, </li><li>{{c3::Synchronizes-With (SW)}}, </li><li>{{c4::Synchronization Order (SO)}}, </li><li>{{c5::Happens-Before (HB)}}.</li></ol> |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Note 39: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: t&2cm[5&m<
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Synchronization actions (SA) in the JMM are: read/write of a volatile variable; lock and unlock of a monitor; the first and last action of a thread (synthetic); actions that start a thread; actions that determine whether a thread has terminated.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Synchronization actions (SA) in the JMM are: read/write of a volatile variable; lock and unlock of a monitor; the first and last action of a thread (synthetic); actions that start a thread; actions that determine whether a thread has terminated.
SA are the building blocks of the synchronization order (SO). Anything else is an "ordinary" action.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Synchronization actions (SA) in the JMM are:
- read/write of a
volatile variable; - lock and unlock of a monitor;
- the first and last action of a thread (synthetic);
- actions that start a thread;
- actions that determine whether a thread has terminated.
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Synchronization actions (SA) in the JMM are:
- read/write of a
volatile variable; - lock and unlock of a monitor;
- the first and last action of a thread (synthetic);
- actions that start a thread;
- actions that determine whether a thread has terminated.
SA are the building blocks of the synchronization order (SO). Anything else is an "ordinary" action.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<i>Synchronization actions (SA)</i> in the JMM are: {{c1::read/write of a <code>volatile</code> variable}}; {{c1::lock and unlock of a monitor}}; {{c1::the first and last action of a thread (synthetic)}}; {{c1::actions that start a thread}}; {{c1::actions that determine whether a thread has terminated}}. |
<i>Synchronization actions (SA)</i> in the JMM are: <br><ol><li>{{c1::read/write of a <code>volatile</code> variable}}; </li><li>{{c2::lock and unlock of a monitor}}; </li><li>{{c3::the first and last action of a thread (synthetic)}}; </li><li>{{c4::actions that start a thread}}; </li><li>{{c5::actions that determine whether a thread has terminated}}.</li></ol> |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::4._Java_Memory_Model
Note 40: ETH::2. Semester::PProg
Deck: ETH::2. Semester::PProg
Note Type: Horvath Cloze
GUID: ~i|&N8&P3M
modified
Before
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::1._Memory_Reordering
Realistic example of incorrect code:
boolean stop = false;
void f() { while(!stop) { /* draw */ } }
void g() { stop = didUserQuit(); } There is
no guarantee that thread 1 will ever stop - although it
will "likely work in practice".
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::1._Memory_Reordering
Realistic example of incorrect code:
boolean stop = false;
void f() { while(!stop) { /* draw */ } }
void g() { stop = didUserQuit(); } There is
no guarantee that thread 1 will ever stop - although it
will "likely work in practice".
Reason: the compiler may hoist stop into a register and never reload it inside the loop. Additionally, thread 2's write may sit in its local cache.
Fix: volatile boolean stop or AtomicBoolean.
After
Front
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::1._Memory_Reordering
Realistic example of incorrect code:

There is
no guarantee that thread 1 will ever stop - although it will "likely work in practice".
Back
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::1._Memory_Reordering
Realistic example of incorrect code:
There is
no guarantee that thread 1 will ever stop - although it will "likely work in practice".
Reason: the compiler may hoist stop into a register and never reload it inside the loop. Additionally, thread 2's write may sit in its local cache.
Fix: volatile boolean stop or AtomicBoolean.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Realistic example of incorrect code: <pre>boolean stop = false;
void f() { while(!stop) { /* draw */ } }
void g() { stop = didUserQuit(); }</pre> There is {{c1::no guarantee that thread 1 will ever stop}} - although it {{c2::will "likely work in practice"}}. |
Realistic example of incorrect code: <pre><img src="paste-d7089d212514b2d525fb57dd148d9e8b0aa7db83.jpg"><br></pre> There is {{c1::no guarantee that thread 1 will ever stop}} - although it will "likely work in practice". |
Tags:
ETH::2._Semester::PProg::12._Shared_Memory_Concurrency::1._Memory_Reordering