Note 1: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: #o$V|.|Ehe
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Die erwartete Laufzeit von Quickselect ist \(O(n)\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Die erwartete Laufzeit von Quickselect ist \(O(n)\).
Wahr.
Randomisiertes Quickselect (Suche nach dem \(k\)-kleinsten Element mit zufälligem Pivot) hat erwartete Laufzeit \(O(n)\), da die Teilprobleme im Mittel geometrisch schrumpfen.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Die erwartete Laufzeit von Quickselect ist \(O(n)\). |
| Back |
|
Wahr.<br><br>Randomisiertes Quickselect (Suche nach dem \(k\)-kleinsten Element mit zufälligem Pivot) hat erwartete Laufzeit \(O(n)\), da die Teilprobleme im Mittel geometrisch schrumpfen. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
ETH::2._Semester::A&W::Minitests::5
Note 2: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: $d[!gH*t9;
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::2._Die_Ungleichung_von_Chernoff ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Sarah besitzt zwei sehr spezielle Münzen: eine zeigt immer „Kopf" (weil auf beiden Seiten „Kopf" abgebildet ist ...), die andere immer „Zahl". Sie wählt eine der beiden Münzen zufällig und wirft sie \(n = 1000\) mal. Sie bezeichnet mit \(X\) die Anzahl „Kopf", die sie sieht. Dann gilt für \(\delta := 1/4\):
\(\Pr[X \geq (1 + \delta)n/2] \leq e^{-\delta^2 n/6}\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::2._Die_Ungleichung_von_Chernoff ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Sarah besitzt zwei sehr spezielle Münzen: eine zeigt immer „Kopf" (weil auf beiden Seiten „Kopf" abgebildet ist ...), die andere immer „Zahl". Sie wählt eine der beiden Münzen zufällig und wirft sie \(n = 1000\) mal. Sie bezeichnet mit \(X\) die Anzahl „Kopf", die sie sieht. Dann gilt für \(\delta := 1/4\):
\(\Pr[X \geq (1 + \delta)n/2] \leq e^{-\delta^2 n/6}\).
Falsch.
Die Chernoff-Schranke verlangt unabhängige Versuche; hier sind alle Würfe vollständig abhängig (die gewählte Münze legt alles fest). \(X\) ist entweder \(0\) oder \(1000\), je mit Wahrscheinlichkeit \(1/2\). Also \(\Pr[X \geq 625] = 1/2\), während die rechte Seite \(e^{-(1/16)\cdot 1000/6} \approx e^{-10.4}\) winzig ist.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sarah besitzt zwei sehr spezielle Münzen: eine zeigt immer „Kopf" (weil auf beiden Seiten „Kopf" abgebildet ist ...), die andere immer „Zahl". Sie wählt eine der beiden Münzen zufällig und wirft sie \(n = 1000\) mal. Sie bezeichnet mit \(X\) die Anzahl „Kopf", die sie sieht. Dann gilt für \(\delta := 1/4\):<br>\(\Pr[X \geq (1 + \delta)n/2] \leq e^{-\delta^2 n/6}\). |
| Back |
|
Falsch.<br><br>Die Chernoff-Schranke verlangt unabhängige Versuche; hier sind alle Würfe vollständig abhängig (die gewählte Münze legt alles fest). \(X\) ist entweder \(0\) oder \(1000\), je mit Wahrscheinlichkeit \(1/2\). Also \(\Pr[X \geq 625] = 1/2\), während die rechte Seite \(e^{-(1/16)\cdot 1000/6} \approx e^{-10.4}\) winzig ist. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::2._Die_Ungleichung_von_Chernoff
ETH::2._Semester::A&W::Minitests::5
Note 3: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: 1_lbf7r?#K
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::4._Target-Shooting ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Sei \(A\) ein probabilistischer Algorithmus, dessen Ausgabe immer entweder \(0\) oder \(1\) ist, und gelte \(\mathbb{E}[A] = s > 0\). Seien ausserdem \(0 < \varepsilon < 1\) und \(0 < \delta < 0.5\). Wenn wir \(A\) unabhängig \(m = \lceil \frac{100 \log(1/\delta)}{s\varepsilon^2} \rceil\) Mal ausführen und \(\hat{s}\) als Durchschnitt der Ausgaben definieren, dann gilt mit Wahrscheinlichkeit mindestens \(1 - \delta\):
\(\hat{s} \in [(1 - \varepsilon)s, (1 + \varepsilon)s]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::4._Target-Shooting ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Sei \(A\) ein probabilistischer Algorithmus, dessen Ausgabe immer entweder \(0\) oder \(1\) ist, und gelte \(\mathbb{E}[A] = s > 0\). Seien ausserdem \(0 < \varepsilon < 1\) und \(0 < \delta < 0.5\). Wenn wir \(A\) unabhängig \(m = \lceil \frac{100 \log(1/\delta)}{s\varepsilon^2} \rceil\) Mal ausführen und \(\hat{s}\) als Durchschnitt der Ausgaben definieren, dann gilt mit Wahrscheinlichkeit mindestens \(1 - \delta\):
\(\hat{s} \in [(1 - \varepsilon)s, (1 + \varepsilon)s]\).
Wahr.
Das ist die Schätzgarantie des Target-Shooting. Mit \(m = \Theta\!\left(\frac{\log(1/\delta)}{s\varepsilon^2}\right)\) Stichproben liefert der Durchschnitt \(\hat{s}\) per Chernoff mit Wahrscheinlichkeit \(\geq 1 - \delta\) eine relative \((1 \pm \varepsilon)\)-Approximation von \(s\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(A\) ein probabilistischer Algorithmus, dessen Ausgabe immer entweder \(0\) oder \(1\) ist, und gelte \(\mathbb{E}[A] = s > 0\). Seien ausserdem \(0 < \varepsilon < 1\) und \(0 < \delta < 0.5\). Wenn wir \(A\) unabhängig \(m = \lceil \frac{100 \log(1/\delta)}{s\varepsilon^2} \rceil\) Mal ausführen und \(\hat{s}\) als Durchschnitt der Ausgaben definieren, dann gilt mit Wahrscheinlichkeit mindestens \(1 - \delta\):<br>\(\hat{s} \in [(1 - \varepsilon)s, (1 + \varepsilon)s]\). |
| Back |
|
Wahr.<br><br>Das ist die Schätzgarantie des Target-Shooting. Mit \(m = \Theta\!\left(\frac{\log(1/\delta)}{s\varepsilon^2}\right)\) Stichproben liefert der Durchschnitt \(\hat{s}\) per Chernoff mit Wahrscheinlichkeit \(\geq 1 - \delta\) eine relative \((1 \pm \varepsilon)\)-Approximation von \(s\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::4._Target-Shooting
ETH::2._Semester::A&W::Minitests::5
Note 4: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: 3Bh2KT2=dQ
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::1._Die_Ungleichungen_von_Markov_und_Chebyshev ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Wenn \(X\) eine nicht-negative Zufallsvariable ist mit \(\mathbb{E}[X] > 100\), dann ist \(\Pr[X > 10] \geq 1/2\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::1._Die_Ungleichungen_von_Markov_und_Chebyshev ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Wenn \(X\) eine nicht-negative Zufallsvariable ist mit \(\mathbb{E}[X] > 100\), dann ist \(\Pr[X > 10] \geq 1/2\).
Falsch.
Markov liefert obere, keine unteren Schranken. Gegenbeispiel: \(X = 10000\) mit Wahrscheinlichkeit \(1/50\), sonst \(0\). Dann ist \(\mathbb{E}[X] = 200 > 100\), aber \(\Pr[X > 10] = 1/50 < 1/2\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Wenn \(X\) eine nicht-negative Zufallsvariable ist mit \(\mathbb{E}[X] > 100\), dann ist \(\Pr[X > 10] \geq 1/2\). |
| Back |
|
Falsch.<br><br>Markov liefert obere, keine unteren Schranken. Gegenbeispiel: \(X = 10000\) mit Wahrscheinlichkeit \(1/50\), sonst \(0\). Dann ist \(\mathbb{E}[X] = 200 > 100\), aber \(\Pr[X > 10] = 1/50 < 1/2\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::1._Die_Ungleichungen_von_Markov_und_Chebyshev
ETH::2._Semester::A&W::Minitests::4
Note 5: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: 4Qm4TG:P|(
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Seien \(X, Y, Z\) drei Zufallsvariablen, wobei \(X, Y, Z\) unabhängig sind. Dann gilt immer
\(\mathbb{E}[X + Y \cdot Z] = \mathbb{E}[X] + \mathbb{E}[Y] \cdot \mathbb{E}[Z]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Seien \(X, Y, Z\) drei Zufallsvariablen, wobei \(X, Y, Z\) unabhängig sind. Dann gilt immer
\(\mathbb{E}[X + Y \cdot Z] = \mathbb{E}[X] + \mathbb{E}[Y] \cdot \mathbb{E}[Z]\).
Wahr.
Mit Linearität ist \(\mathbb{E}[X + YZ] = \mathbb{E}[X] + \mathbb{E}[YZ]\). Da \(Y\) und \(Z\) unabhängig sind, gilt \(\mathbb{E}[YZ] = \mathbb{E}[Y]\,\mathbb{E}[Z]\). (Vergleiche die Minitest-4-Variante, wo nur \(X, Y\) unabhängig waren und die Aussage falsch ist.)
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Seien \(X, Y, Z\) drei Zufallsvariablen, wobei \(X, Y, Z\) unabhängig sind. Dann gilt immer<br>\(\mathbb{E}[X + Y \cdot Z] = \mathbb{E}[X] + \mathbb{E}[Y] \cdot \mathbb{E}[Z]\). |
| Back |
|
Wahr.<br><br>Mit Linearität ist \(\mathbb{E}[X + YZ] = \mathbb{E}[X] + \mathbb{E}[YZ]\). Da \(Y\) und \(Z\) unabhängig sind, gilt \(\mathbb{E}[YZ] = \mathbb{E}[Y]\,\mathbb{E}[Z]\). (Vergleiche die Minitest-4-Variante, wo nur \(X, Y\) unabhängig waren und die Aussage falsch ist.) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen
ETH::2._Semester::A&W::Minitests::5
Note 6: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: 4]b_YsE,k}
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Wir können jeden Las-Vegas-Algorithmus mit bekannter erwarteter Laufzeit höchstens \(T\) in einen randomisierten Algorithmus umwandeln, dessen Laufzeit höchstens \(10T\) ist und der mit Wahrscheinlichkeit mindestens \(0.9\) erfolgreich ist.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Wir können jeden Las-Vegas-Algorithmus mit bekannter erwarteter Laufzeit höchstens \(T\) in einen randomisierten Algorithmus umwandeln, dessen Laufzeit höchstens \(10T\) ist und der mit Wahrscheinlichkeit mindestens \(0.9\) erfolgreich ist.
Wahr.
Markov-Ungleichung: Bricht man den Las-Vegas-Algorithmus nach \(10T\) Schritten ab, ist \(\Pr[\text{Laufzeit} > 10T] \leq T/(10T) = 1/10\). Mit Wahrscheinlichkeit \(\geq 0.9\) terminiert er also korrekt innerhalb von \(10T\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Wir können jeden Las-Vegas-Algorithmus mit bekannter erwarteter Laufzeit höchstens \(T\) in einen randomisierten Algorithmus umwandeln, dessen Laufzeit höchstens \(10T\) ist und der mit Wahrscheinlichkeit mindestens \(0.9\) erfolgreich ist. |
| Back |
|
Wahr.<br><br>Markov-Ungleichung: Bricht man den Las-Vegas-Algorithmus nach \(10T\) Schritten ab, ist \(\Pr[\text{Laufzeit} > 10T] \leq T/(10T) = 1/10\). Mit Wahrscheinlichkeit \(\geq 0.9\) terminiert er also korrekt innerhalb von \(10T\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
ETH::2._Semester::A&W::Minitests::5
Note 7: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: 7idN$=Uea/
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Seien \(X, Y, Z\) drei Zufallsvariablen, wobei \(X, Y\) unabhängig sind. Dann gilt immer
\(\mathbb{E}[X + Y \cdot Z] = \mathbb{E}[X] + \mathbb{E}[Y] \cdot \mathbb{E}[Z]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Seien \(X, Y, Z\) drei Zufallsvariablen, wobei \(X, Y\) unabhängig sind. Dann gilt immer
\(\mathbb{E}[X + Y \cdot Z] = \mathbb{E}[X] + \mathbb{E}[Y] \cdot \mathbb{E}[Z]\).
Falsch.
Wegen Linearität gilt \(\mathbb{E}[X + YZ] = \mathbb{E}[X] + \mathbb{E}[YZ]\). Für \(\mathbb{E}[YZ] = \mathbb{E}[Y]\,\mathbb{E}[Z]\) müssten \(Y\) und \(Z\) unabhängig sein; hier sind aber nur \(X\) und \(Y\) unabhängig.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Seien \(X, Y, Z\) drei Zufallsvariablen, wobei \(X, Y\) unabhängig sind. Dann gilt immer<br>\(\mathbb{E}[X + Y \cdot Z] = \mathbb{E}[X] + \mathbb{E}[Y] \cdot \mathbb{E}[Z]\). |
| Back |
|
Falsch.<br><br>Wegen Linearität gilt \(\mathbb{E}[X + YZ] = \mathbb{E}[X] + \mathbb{E}[YZ]\). Für \(\mathbb{E}[YZ] = \mathbb{E}[Y]\,\mathbb{E}[Z]\) müssten \(Y\) und \(Z\) unabhängig sein; hier sind aber nur \(X\) und \(Y\) unabhängig. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen
ETH::2._Semester::A&W::Minitests::4
Note 8: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: =Z#bvK?DXW
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Erwartungswert ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Wenn wir unabhängig voneinander zufällig \(n\) Bälle in \(n\) Behälter werfen (wobei jeder Ball mit gleicher Wahrscheinlichkeit in jedem Behälter landet) und \(X_1\) die Anzahl der Bälle im ersten Behälter am Ende des Prozesses bezeichnet, dann ist \(\mathbb{E}[X_1] = 1\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Erwartungswert ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Wenn wir unabhängig voneinander zufällig \(n\) Bälle in \(n\) Behälter werfen (wobei jeder Ball mit gleicher Wahrscheinlichkeit in jedem Behälter landet) und \(X_1\) die Anzahl der Bälle im ersten Behälter am Ende des Prozesses bezeichnet, dann ist \(\mathbb{E}[X_1] = 1\).
Wahr.
Mit Indikatoren \(I_j = 1\), falls Ball \(j\) im ersten Behälter landet, ist \(X_1 = \sum_{j=1}^n I_j\) und nach Linearität \(\mathbb{E}[X_1] = n \cdot \frac{1}{n} = 1\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Wenn wir unabhängig voneinander zufällig \(n\) Bälle in \(n\) Behälter werfen (wobei jeder Ball mit gleicher Wahrscheinlichkeit in jedem Behälter landet) und \(X_1\) die Anzahl der Bälle im ersten Behälter am Ende des Prozesses bezeichnet, dann ist \(\mathbb{E}[X_1] = 1\). |
| Back |
|
Wahr.<br><br>Mit Indikatoren \(I_j = 1\), falls Ball \(j\) im ersten Behälter landet, ist \(X_1 = \sum_{j=1}^n I_j\) und nach Linearität \(\mathbb{E}[X_1] = n \cdot \frac{1}{n} = 1\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Erwartungswert
ETH::2._Semester::A&W::Minitests::4
Note 9: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: Be=;$Cm7!Y
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein Graph mit 51 Knoten, in dem jeder Knoten Grad 17 hat.
Back
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein Graph mit 51 Knoten, in dem jeder Knoten Grad 17 hat.
Falsch.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein Graph mit 51 Knoten, in dem jeder Knoten Grad 17 hat.
Back
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein Graph mit 51 Knoten, in dem jeder Knoten Grad 17 hat.
Falsch.
Handschlaglemma: Die Summe aller Knotengrade ist \(2|E|\), also gerade. Hier wäre sie \(51 \cdot 17 = 867\), ungerade. Solch ein Graph kann nicht existieren.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Falsch. |
Falsch.<br><br>Handschlaglemma: Die Summe aller Knotengrade ist \(2|E|\), also gerade. Hier wäre sie \(51 \cdot 17 = 867\), ungerade. Solch ein Graph kann nicht existieren. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen
ETH::2._Semester::A&W::Minitests::1
Note 10: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: D/A{W?@*_o
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Jeder Kreis ist 2-färbbar.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Jeder Kreis ist 2-färbbar.
Falsch.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Jeder Kreis ist 2-färbbar.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Jeder Kreis ist 2-färbbar.
Falsch.
Nur Kreise gerader Länge sind 2-färbbar (bipartit). Ein ungerader Kreis, etwa das Dreieck \(C_3\), hat chromatische Zahl 3.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Falsch. |
Falsch.<br><br>Nur Kreise gerader Länge sind 2-färbbar (bipartit). Ein ungerader Kreis, etwa das Dreieck \(C_3\), hat chromatische Zahl 3. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen
ETH::2._Semester::A&W::Minitests::2
Note 11: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: DYtDxyAjnV
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es gibt einen Hamiltonkreis für einen Schachspringer, der auf einem \( 7 \times 7 \) Schachbrett springt.
Zur Erinnerung: Nachfolgend sind die zulässigen Springerzüge im Schach aufgeführt.

Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es gibt einen Hamiltonkreis für einen Schachspringer, der auf einem \( 7 \times 7 \) Schachbrett springt.
Zur Erinnerung: Nachfolgend sind die zulässigen Springerzüge im Schach aufgeführt.
Falsch.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es gibt einen Hamiltonkreis für einen Schachspringer, der auf einem \( 7 \times 7 \) Schachbrett springt.
Zur Erinnerung: Nachfolgend sind die zulässigen Springerzüge im Schach aufgeführt.
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es gibt einen Hamiltonkreis für einen Schachspringer, der auf einem \( 7 \times 7 \) Schachbrett springt.
Zur Erinnerung: Nachfolgend sind die zulässigen Springerzüge im Schach aufgeführt.
Falsch.
Färbe das Brett wie ein Schachbrett. Jeder Springerzug wechselt die Feldfarbe, ein Hamiltonkreis besucht also abwechselnd schwarze und weisse Felder und hat damit gerade Länge. Das \(7 \times 7\)-Brett hat aber 49 Felder (ungerade), also kann kein Hamiltonkreis existieren.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Falsch. |
Falsch.<br><br>Färbe das Brett wie ein Schachbrett. Jeder Springerzug wechselt die Feldfarbe, ein Hamiltonkreis besucht also abwechselnd schwarze und weisse Felder und hat damit gerade Länge. Das \(7 \times 7\)-Brett hat aber 49 Felder (ungerade), also kann kein Hamiltonkreis existieren. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
ETH::2._Semester::A&W::Minitests::1
Note 12: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: HZl_|1j*Dx
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Es gibt einen probabilistischen Algorithmus, der testet, ob \(n\) eine Primzahl ist, und zwar in einer Zeit, die polynomiell in \(\log n\) ist.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Es gibt einen probabilistischen Algorithmus, der testet, ob \(n\) eine Primzahl ist, und zwar in einer Zeit, die polynomiell in \(\log n\) ist.
Wahr.
Der Miller-Rabin-Test entscheidet die Primalität von \(n\) probabilistisch in Zeit polynomiell in \(\log n\), also in der Bitlänge von \(n\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Es gibt einen probabilistischen Algorithmus, der testet, ob \(n\) eine Primzahl ist, und zwar in einer Zeit, die polynomiell in \(\log n\) ist. |
| Back |
|
Wahr.<br><br>Der Miller-Rabin-Test entscheidet die Primalität von \(n\) probabilistisch in Zeit polynomiell in \(\log n\), also in der Bitlänge von \(n\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::3._Primzahltest
ETH::2._Semester::A&W::Minitests::5
Note 13: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: Hn3zY|Yv&)
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für beliebige unabhängige Zufallsvariablen \(X_1, X_2\) gilt \(\text{Var}[X_1 + X_2] = \text{Var}[X_1] + \text{Var}[X_2]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für beliebige unabhängige Zufallsvariablen \(X_1, X_2\) gilt \(\text{Var}[X_1 + X_2] = \text{Var}[X_1] + \text{Var}[X_2]\).
Wahr.
Für unabhängige (sogar bereits unkorrelierte) Zufallsvariablen ist die Varianz additiv. Allgemein gilt \(\text{Var}[X_1 + X_2] = \text{Var}[X_1] + \text{Var}[X_2] + 2\,\text{Cov}[X_1, X_2]\), und die Kovarianz verschwindet bei Unabhängigkeit.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Für beliebige unabhängige Zufallsvariablen \(X_1, X_2\) gilt \(\text{Var}[X_1 + X_2] = \text{Var}[X_1] + \text{Var}[X_2]\). |
| Back |
|
Wahr.<br><br>Für unabhängige (sogar bereits unkorrelierte) Zufallsvariablen ist die Varianz additiv. Allgemein gilt \(\text{Var}[X_1 + X_2] = \text{Var}[X_1] + \text{Var}[X_2] + 2\,\text{Cov}[X_1, X_2]\), und die Kovarianz verschwindet bei Unabhängigkeit. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz
ETH::2._Semester::A&W::Minitests::4
Note 14: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: J~>ftA6Yjk
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Idee hinter der Erreichbarkeits-Approximation
Wähle \(r_v \leftarrow \mathrm{Uniform}([0,1])\) und setze \(x_v = \min_{u \in R(v)} r_u\).
Dann ist \(x_v\) das Minimum von \(n_v\) Zufallszahlen in \([0,1]\), also grob \(x_v \approx 1/n_v\).
Folglich ist \(1/x_v\) eine Schätzung für \(n_v\).
Den Fehler reduziert man, indem man über mehrere Läufe den Median bildet.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Idee hinter der Erreichbarkeits-Approximation
Wähle \(r_v \leftarrow \mathrm{Uniform}([0,1])\) und setze \(x_v = \min_{u \in R(v)} r_u\).
Dann ist \(x_v\) das Minimum von \(n_v\) Zufallszahlen in \([0,1]\), also grob \(x_v \approx 1/n_v\).
Folglich ist \(1/x_v\) eine Schätzung für \(n_v\).
Den Fehler reduziert man, indem man über mehrere Läufe den Median bildet.
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Idee hinter der Erreichbarkeits-Approximation
Wähle \(r_v \leftarrow \mathrm{Uniform}([0,1])\) und setze \(x_v = \min_{u \in R(v)} r_u\).
Dann ist \(x_v\) das Minimum von \(n_v\) Zufallszahlen in \([0,1]\), also grob \(x_v \approx 1/n_v\).
Folglich ist \(1/x_v\) eine Schätzung für \(n_v\).
Den Fehler reduziert man, indem man über mehrere Läufe den Median bildet.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Idee hinter der Erreichbarkeits-Approximation
Wähle \(r_v \leftarrow \mathrm{Uniform}([0,1])\) und setze \(x_v = \min_{u \in R(v)} r_u\).
Dann ist \(x_v\) das Minimum von \(n_v\) Zufallszahlen in \([0,1]\), also grob \(x_v \approx 1/n_v\).
Folglich ist \(1/x_v\) eine Schätzung für \(n_v\).
Den Fehler reduziert man, indem man über mehrere Läufe den Median bildet.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Idee hinter der Erreichbarkeits-Approximation</b><br>Wähle \(r_v \leftarrow \mathrm{Uniform}([0,1])\) und setze \(x_v = \min_{u \in R(v)} r_u\).<br><br>Dann ist \(x_v\) das {{c1::Minimum von \(n_v\) Zufallszahlen in \([0,1]\)}}, also grob \(x_v \approx {{c2::1/n_v}}\).<br>Folglich ist {{c3::\(1/x_v\)}} eine Schätzung für \(n_v\).<br>Den Fehler reduziert man, indem man über mehrere Läufe den {{c4::Median}} bildet. |
<b>Idee hinter der Erreichbarkeits-Approximation</b><br>Wähle \(r_v \leftarrow \mathrm{Uniform}([0,1])\) und setze \(x_v = \min_{u \in R(v)} r_u\).<br><br>Dann ist \(x_v\) das {{c1::Minimum von \(n_v\) Zufallszahlen in \([0,1]\)}}, also grob \(x_v \approx {{c1::1/n_v}}\).<br>Folglich ist {{c1::\(1/x_v\)}} eine Schätzung für \(n_v\).<br><br>Den Fehler reduziert man, indem man über mehrere Läufe den {{c2::Median}} bildet. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 15: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: K>bJ4n9}2B
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen Algorithmus mit polynomieller Laufzeit, der eine \(1,5\)-Approximation für das metrische Problem des Handlungsreisenden (TSP) findet.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen Algorithmus mit polynomieller Laufzeit, der eine \(1,5\)-Approximation für das metrische Problem des Handlungsreisenden (TSP) findet.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen Algorithmus mit polynomieller Laufzeit, der eine \(1,5\)-Approximation für das metrische Problem des Handlungsreisenden (TSP) findet.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen Algorithmus mit polynomieller Laufzeit, der eine \(1,5\)-Approximation für das metrische Problem des Handlungsreisenden (TSP) findet.
Wahr.
Der Christofides-Algorithmus liefert in Polynomzeit eine \(3/2\)-Approximation für das metrische TSP (MST, minimales perfektes Matching auf den Knoten ungeraden Grades, Eulertour, dann Abkürzen).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Der Christofides-Algorithmus liefert in Polynomzeit eine \(3/2\)-Approximation für das metrische TSP (MST, minimales perfektes Matching auf den Knoten ungeraden Grades, Eulertour, dann Abkürzen). |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen
ETH::2._Semester::A&W::Minitests::2
Note 16: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: L!lj3a@0Z0
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::2._Brücken ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jede Brücke in einem Graphen ist zu mindestens einem Artikulationspunkt inzident.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::2._Brücken ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jede Brücke in einem Graphen ist zu mindestens einem Artikulationspunkt inzident.
Falsch.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::2._Brücken ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jede Brücke in einem Graphen ist zu mindestens einem Artikulationspunkt inzident.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::2._Brücken ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jede Brücke in einem Graphen ist zu mindestens einem Artikulationspunkt inzident.
Falsch.
Gegenbeispiel: der \(K_2\) (zwei Knoten, eine Kante). Die Kante ist eine Brücke, aber keiner der Endknoten ist ein Artikulationspunkt, denn das Entfernen eines Grad-1-Knotens lässt den Rest zusammenhängend.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Falsch. |
Falsch.<br><br>Gegenbeispiel: der \(K_2\) (zwei Knoten, eine Kante). Die Kante ist eine Brücke, aber keiner der Endknoten ist ein Artikulationspunkt, denn das Entfernen eines Grad-1-Knotens lässt den Rest zusammenhängend. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::2._Brücken
ETH::2._Semester::A&W::Minitests::1
Note 17: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: L>/LlPBg9.
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein 4-zusammenhängender Graph, in dem jeder Knoten Grad genau 4 hat.
Back
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein 4-zusammenhängender Graph, in dem jeder Knoten Grad genau 4 hat.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein 4-zusammenhängender Graph, in dem jeder Knoten Grad genau 4 hat.
Back
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Es existiert ein 4-zusammenhängender Graph, in dem jeder Knoten Grad genau 4 hat.
Wahr.
Beispiel: der vollständige Graph \(K_5\). Jeder Knoten hat Grad 4 und der Knotenzusammenhang ist \(\kappa(K_5) = 4\).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Beispiel: der vollständige Graph \(K_5\). Jeder Knoten hat Grad 4 und der Knotenzusammenhang ist \(\kappa(K_5) = 4\). |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume
ETH::2._Semester::A&W::Minitests::1
Note 18: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: MK
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen polynomiellen Algorithmus, der für jeden planaren Graphen eine geeignete Einfärbung mit 6 Farben findet.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen polynomiellen Algorithmus, der für jeden planaren Graphen eine geeignete Einfärbung mit 6 Farben findet.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen polynomiellen Algorithmus, der für jeden planaren Graphen eine geeignete Einfärbung mit 6 Farben findet.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Es gibt einen polynomiellen Algorithmus, der für jeden planaren Graphen eine geeignete Einfärbung mit 6 Farben findet.
Wahr.
Jeder planare Graph hat einen Knoten vom Grad \(\leq 5\). Entfernt man ihn rekursiv und färbt rückwärts greedy, genügen 6 Farben, und das in Polynomzeit. (Der Vier-Farben-Satz ist stärker, aber 6 Farben sind viel einfacher zu garantieren.)
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Jeder planare Graph hat einen Knoten vom Grad \(\leq 5\). Entfernt man ihn rekursiv und färbt rückwärts greedy, genügen 6 Farben, und das in Polynomzeit. (Der Vier-Farben-Satz ist stärker, aber 6 Farben sind viel einfacher zu garantieren.) |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen
ETH::2._Semester::A&W::Minitests::2
Note 19: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: N!:N@%LrfY
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::3._Block-Zerlegung ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für zwei Knoten \( a, b \) eines Graphen sei \( a \sim b \) genau dann, wenn \( a = b \) gilt oder wenn \( a \) und \( b \) auf einem gemeinsamen Kreis liegen. Dann ist \( \sim \) eine Äquivalenzrelation.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::3._Block-Zerlegung ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für zwei Knoten \( a, b \) eines Graphen sei \( a \sim b \) genau dann, wenn \( a = b \) gilt oder wenn \( a \) und \( b \) auf einem gemeinsamen Kreis liegen. Dann ist \( \sim \) eine Äquivalenzrelation.
Falsch.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::3._Block-Zerlegung ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für zwei Knoten \( a, b \) eines Graphen sei \( a \sim b \) genau dann, wenn \( a = b \) gilt oder wenn \( a \) und \( b \) auf einem gemeinsamen Kreis liegen. Dann ist \( \sim \) eine Äquivalenzrelation.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::3._Block-Zerlegung ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für zwei Knoten \( a, b \) eines Graphen sei \( a \sim b \) genau dann, wenn \( a = b \) gilt oder wenn \( a \) und \( b \) auf einem gemeinsamen Kreis liegen. Dann ist \( \sim \) eine Äquivalenzrelation.
Falsch.
Die Relation ist nicht transitiv: Berühren sich zwei Kreise nur in einem Knoten \(b\), so gilt \(a \sim b\) und \(b \sim c\), aber \(a\) und \(c\) liegen auf keinem gemeinsamen Kreis (\(b\) ist ein Artikulationspunkt). Also keine Äquivalenzrelation.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Falsch. |
Falsch.<br><br>Die Relation ist nicht transitiv: Berühren sich zwei Kreise nur in einem Knoten \(b\), so gilt \(a \sim b\) und \(b \sim c\), aber \(a\) und \(c\) liegen auf keinem gemeinsamen Kreis (\(b\) ist ein Artikulationspunkt). Also keine Äquivalenzrelation. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang::3._Block-Zerlegung
ETH::2._Semester::A&W::Minitests::1
Note 20: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: N1t@rvGH9(
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Wenn ein probabilistischer Algorithmus mit einer Wahrscheinlichkeit von mindestens \(2/3\) eine korrekte JA/NEIN-Antwort liefert und wir ihn unabhängig \(n\)-mal ausführen, ist die Wahrscheinlichkeit, dass er mehr als \(n/2\) Mal eine falsche Antwort gibt, kleiner als \(\exp(-0.001n)\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Wenn ein probabilistischer Algorithmus mit einer Wahrscheinlichkeit von mindestens \(2/3\) eine korrekte JA/NEIN-Antwort liefert und wir ihn unabhängig \(n\)-mal ausführen, ist die Wahrscheinlichkeit, dass er mehr als \(n/2\) Mal eine falsche Antwort gibt, kleiner als \(\exp(-0.001n)\).
Wahr.
Mehrheitsentscheid mit Chernoff: Die erwartete Anzahl falscher Durchläufe ist \(\leq n/3\). Die Wahrscheinlichkeit, dass mehr als \(n/2\) der \(n\) Durchläufe falsch liegen, fällt exponentiell in \(n\) und liegt damit unter \(\exp(-0.001n)\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Wenn ein probabilistischer Algorithmus mit einer Wahrscheinlichkeit von mindestens \(2/3\) eine korrekte JA/NEIN-Antwort liefert und wir ihn unabhängig \(n\)-mal ausführen, ist die Wahrscheinlichkeit, dass er mehr als \(n/2\) Mal eine falsche Antwort gibt, kleiner als \(\exp(-0.001n)\). |
| Back |
|
Wahr.<br><br>Mehrheitsentscheid mit Chernoff: Die erwartete Anzahl falscher Durchläufe ist \(\leq n/3\). Die Wahrscheinlichkeit, dass mehr als \(n/2\) der \(n\) Durchläufe falsch liegen, fällt exponentiell in \(n\) und liegt damit unter \(\exp(-0.001n)\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
ETH::2._Semester::A&W::Minitests::5
Note 21: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: No!Y=X~s0W
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder 2-zusammenhängende Graph hat einen Hamiltonkreis.
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder 2-zusammenhängende Graph hat einen Hamiltonkreis.
Falsch.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder 2-zusammenhängende Graph hat einen Hamiltonkreis.
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder 2-zusammenhängende Graph hat einen Hamiltonkreis.
Falsch.
Gegenbeispiel: der vollständige bipartite Graph \(K_{2,3}\) ist 2-zusammenhängend, hat aber keinen Hamiltonkreis (in einem bipartiten Graphen müssten dafür beide Seiten gleich gross sein).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Falsch. |
Falsch.<br><br>Gegenbeispiel: der vollständige bipartite Graph \(K_{2,3}\) ist 2-zusammenhängend, hat aber keinen Hamiltonkreis (in einem bipartiten Graphen müssten dafür beide Seiten gleich gross sein). |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
ETH::2._Semester::A&W::Minitests::1
Note 22: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: Ods#nvZO:/
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss, sodass \(\mathrm{val}(f) > 0\). Sei \(N_f\) das Restnetzwerk. Dann enthält \(N_f\) einen (gerichteten) Weg von \(t\) nach \(s\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss, sodass \(\mathrm{val}(f) > 0\). Sei \(N_f\) das Restnetzwerk. Dann enthält \(N_f\) einen (gerichteten) Weg von \(t\) nach \(s\).
Wahr.
Wegen \(\mathrm{val}(f) > 0\) fliesst entlang mindestens eines \(s\)-\(t\)-Weges positiver Fluss. Jede dabei benutzte Vorwärtskante erzeugt im Restnetzwerk eine Rückwärtskante; diese Rückwärtskanten bilden einen gerichteten Weg von \(t\) zurück nach \(s\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss, sodass \(\mathrm{val}(f) > 0\). Sei \(N_f\) das Restnetzwerk. Dann enthält \(N_f\) einen (gerichteten) Weg von \(t\) nach \(s\). |
| Back |
|
Wahr.<br><br>Wegen \(\mathrm{val}(f) > 0\) fliesst entlang mindestens eines \(s\)-\(t\)-Weges positiver Fluss. Jede dabei benutzte Vorwärtskante erzeugt im Restnetzwerk eine Rückwärtskante; diese Rückwärtskanten bilden einen gerichteten Weg von \(t\) zurück nach \(s\). |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken
ETH::2._Semester::A&W::Minitests::6
Note 23: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: Q.ArG%jeIn
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Union-Bound-Fakt
Für alle \(x \in [0,1]\) und \(n \in \mathbb{N}\) gilt\[1 - (1-x)^n \leq n x\]Beweisidee: Für unabhängige \(X_1,\ldots,X_n \sim \mathrm{Ber}(x)\) ist \(\Pr[X_1=1 \vee \ldots \vee X_n=1] = 1-(1-x)^n\); die Union Bound liefert andererseits \(\Pr[X_1=1 \vee \ldots \vee X_n=1] \leq \sum_i \Pr[X_i=1] = n x\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Union-Bound-Fakt
Für alle \(x \in [0,1]\) und \(n \in \mathbb{N}\) gilt\[1 - (1-x)^n \leq n x\]Beweisidee: Für unabhängige \(X_1,\ldots,X_n \sim \mathrm{Ber}(x)\) ist \(\Pr[X_1=1 \vee \ldots \vee X_n=1] = 1-(1-x)^n\); die Union Bound liefert andererseits \(\Pr[X_1=1 \vee \ldots \vee X_n=1] \leq \sum_i \Pr[X_i=1] = n x\).
Spezialfall der Booleschen Ungleichung, im Beweis von ReachabilityCounting (Teil 2) verwendet.
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Union-Bound-Fakt
Für alle \(x \in [0,1]\) und \(n \in \mathbb{N}\) gilt\[1 - (1-x)^n \leq n x\]Beweisidee: Für unabhängige \(X_1,\ldots,X_n \sim \mathrm{Ber}(x)\) ist \(\Pr[X_1=1 \vee \ldots \vee X_n=1] = 1-(1-x)^n\); die Union Bound liefert andererseits \(\Pr[X_1=1 \vee \ldots \vee X_n=1] \leq \sum_i \Pr[X_i=1] = n x\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Union-Bound-Fakt
Für alle \(x \in [0,1]\) und \(n \in \mathbb{N}\) gilt\[1 - (1-x)^n \leq n x\]Beweisidee: Für unabhängige \(X_1,\ldots,X_n \sim \mathrm{Ber}(x)\) ist \(\Pr[X_1=1 \vee \ldots \vee X_n=1] = 1-(1-x)^n\); die Union Bound liefert andererseits \(\Pr[X_1=1 \vee \ldots \vee X_n=1] \leq \sum_i \Pr[X_i=1] = n x\).
Spezialfall der Booleschen Ungleichung, im Beweis von ReachabilityCounting (Teil 2) verwendet.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Union-Bound-Fakt</b><br>Für alle \(x \in [0,1]\) und \(n \in \mathbb{N}\) gilt\[{{c1::1 - (1-x)^n \leq n x}}\]Beweisidee: Für unabhängige \(X_1,\ldots,X_n \sim \mathrm{Ber}(x)\) ist \(\Pr[X_1=1 \vee \ldots \vee X_n=1] = {{c2::1-(1-x)^n}}\); die Union Bound liefert andererseits \(\Pr[X_1=1 \vee \ldots \vee X_n=1] \leq \sum_i \Pr[X_i=1] = {{c3::n x}}\). |
<b>Union-Bound-Fakt</b><br>Für alle \(x \in [0,1]\) und \(n \in \mathbb{N}\) gilt\[{{c1::1 - (1-x)^n \leq n x}}\]Beweisidee: Für unabhängige \(X_1,\ldots,X_n \sim \mathrm{Ber}(x)\) ist \(\Pr[X_1=1 \vee \ldots \vee X_n=1] = {{c1::1-(1-x)^n}}\); die Union Bound liefert andererseits \(\Pr[X_1=1 \vee \ldots \vee X_n=1] \leq \sum_i \Pr[X_i=1] = {{c1::n x}}\). |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 24: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: Qde^b~C`@N
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::1._Die_Ungleichungen_von_Markov_und_Chebyshev ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für eine Zufallsvariable \(X\) mit \(\text{Var}[X] = \sigma^2\) und \(\mathbb{E}[X] = 0\) und jedes \(\lambda > 0\) gilt \(\Pr[X > \lambda\sigma] \leq 1/\lambda^2\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::1._Die_Ungleichungen_von_Markov_und_Chebyshev ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für eine Zufallsvariable \(X\) mit \(\text{Var}[X] = \sigma^2\) und \(\mathbb{E}[X] = 0\) und jedes \(\lambda > 0\) gilt \(\Pr[X > \lambda\sigma] \leq 1/\lambda^2\).
Wahr.
Chebyshev liefert \(\Pr[|X - \mathbb{E}[X]| \geq \lambda\sigma] \leq 1/\lambda^2\). Wegen \(\mathbb{E}[X] = 0\) ist \(\Pr[X > \lambda\sigma] \leq \Pr[|X| \geq \lambda\sigma] \leq 1/\lambda^2\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Für eine Zufallsvariable \(X\) mit \(\text{Var}[X] = \sigma^2\) und \(\mathbb{E}[X] = 0\) und jedes \(\lambda > 0\) gilt \(\Pr[X > \lambda\sigma] \leq 1/\lambda^2\). |
| Back |
|
Wahr.<br><br>Chebyshev liefert \(\Pr[|X - \mathbb{E}[X]| \geq \lambda\sigma] \leq 1/\lambda^2\). Wegen \(\mathbb{E}[X] = 0\) ist \(\Pr[X > \lambda\sigma] \leq \Pr[|X| \geq \lambda\sigma] \leq 1/\lambda^2\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::7._Abschätzen_von_Wahrscheinlichkeiten::1._Die_Ungleichungen_von_Markov_und_Chebyshev
ETH::2._Semester::A&W::Minitests::4
Note 25: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: Qr.dD.:Qfo
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Nützliche Subroutine
Gegeben ein gerichteter Graph \(G\) und Zahlen \(r_v\), berechne für jeden Knoten \(v\) die kleinste erreichbare Zahl \(\min_{u \in R(v)} r_u\).
Naiv \(O(n(n+m))\). Verbesserung auf \(O(n \log n + m)\):
Sortiere die Knoten aufsteigend nach \(r_v\) und starte von jedem noch unbesuchten Knoten eine Rückwärts-DFS (entlang eingehender Kanten), die \(\min[\cdot]\) auf den aktuellen Wert setzt.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Nützliche Subroutine
Gegeben ein gerichteter Graph \(G\) und Zahlen \(r_v\), berechne für jeden Knoten \(v\) die kleinste erreichbare Zahl \(\min_{u \in R(v)} r_u\).
Naiv \(O(n(n+m))\). Verbesserung auf \(O(n \log n + m)\):
Sortiere die Knoten aufsteigend nach \(r_v\) und starte von jedem noch unbesuchten Knoten eine Rückwärts-DFS (entlang eingehender Kanten), die \(\min[\cdot]\) auf den aktuellen Wert setzt.
Subroutine(G, r):
sortiere V aufsteigend nach r_v: v_1, ..., v_n
min[v] := ∞ für alle v
for i = 1, ..., n:
if min[v_i] = ∞:
DFSrev(v_i, r_{v_i})
return min
DFSrev(v, r):
min[v] := r
for each eingehender Nachbar u von v:
if min[u] = ∞:
DFSrev(u, r)Bemerkung: Hier ist \(\min\) einfacher zu berechnen als eine Summe \(\sum\).
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Nützliche Subroutine
Gegeben ein gerichteter Graph \(G\) und Zahlen \(r_v\), berechne für jeden Knoten \(v\) die kleinste erreichbare Zahl \(\min_{u \in R(v)} r_u\).
Naiv \(O(n(n+m))\). Verbesserung auf \(O(n \log n + m)\):
Sortiere die Knoten aufsteigend nach \(r_v\) und starte von jedem noch unbesuchten Knoten eine Rückwärts-DFS (entlang eingehender Kanten), die \(\min[\cdot]\) auf den aktuellen Wert setzt.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Nützliche Subroutine
Gegeben ein gerichteter Graph \(G\) und Zahlen \(r_v\), berechne für jeden Knoten \(v\) die kleinste erreichbare Zahl \(\min_{u \in R(v)} r_u\).
Naiv \(O(n(n+m))\). Verbesserung auf \(O(n \log n + m)\):
Sortiere die Knoten aufsteigend nach \(r_v\) und starte von jedem noch unbesuchten Knoten eine Rückwärts-DFS (entlang eingehender Kanten), die \(\min[\cdot]\) auf den aktuellen Wert setzt.
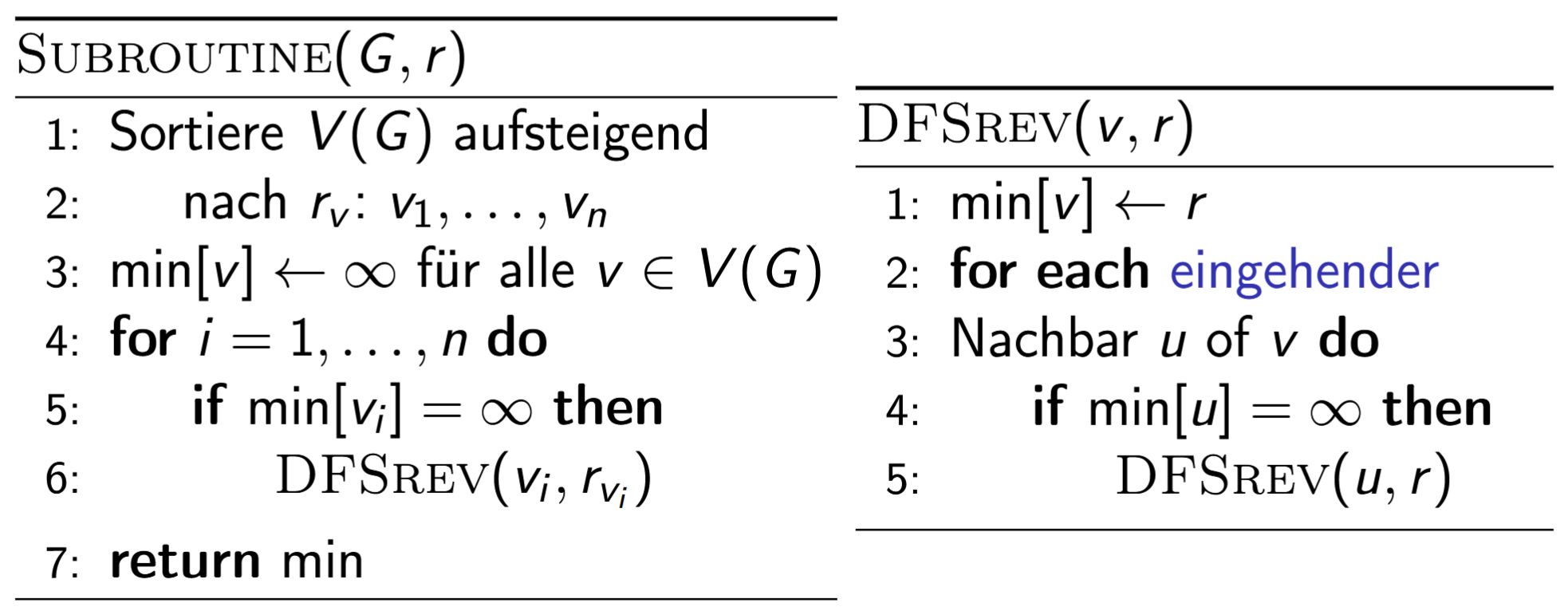
Bemerkung: Hier ist \(\min\)
einfacher zu berechnen als eine Summe \(\sum\)
.
Field-by-field Comparison
| Field |
Before |
After |
| Extra |
<pre>Subroutine(G, r):
sortiere V aufsteigend nach r_v: v_1, ..., v_n
min[v] := ∞ für alle v
for i = 1, ..., n:
if min[v_i] = ∞:
DFSrev(v_i, r_{v_i})
return min
DFSrev(v, r):
min[v] := r
for each eingehender Nachbar u von v:
if min[u] = ∞:
DFSrev(u, r)</pre>Bemerkung: Hier ist \(\min\) einfacher zu berechnen als eine Summe \(\sum\). |
<img src="paste-5452163b12c43f35bec8d8e73c3d62196537963b.jpg"><span style="font-family: "Liberation Sans";"><br><br>Bemerkung: Hier ist </span>\(\min\)<span style="font-family: "Liberation Sans";"> einfacher zu berechnen als eine Summe </span>\(\sum\)<span style="font-family: "Liberation Sans";">.</span> |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 26: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: Sn.UaAMFL}
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Approximation der Erreichbarkeit (gerichtet)
Die Menge der von \(v\) erreichbaren Knoten ist \(R(v) = \{u \in V : u \text{ von } v \text{ erreichbar}\}\), und man schreibt \(n_v = |R(v)|\) für ihre Grösse.
Da exaktes Zählen vermutlich nicht nahe-linear geht, approximiert man \(n_v\): berechne \(\tilde n_v\) mit {{c2::\(\tfrac{n_v}{20} \leq \tilde n_v \leq 20 n_v\)}} (oder sogar \((1-\varepsilon)n_v \leq \tilde n_v \leq (1+\varepsilon)n_v\)).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Approximation der Erreichbarkeit (gerichtet)
Die Menge der von \(v\) erreichbaren Knoten ist \(R(v) = \{u \in V : u \text{ von } v \text{ erreichbar}\}\), und man schreibt \(n_v = |R(v)|\) für ihre Grösse.
Da exaktes Zählen vermutlich nicht nahe-linear geht, approximiert man \(n_v\): berechne \(\tilde n_v\) mit {{c2::\(\tfrac{n_v}{20} \leq \tilde n_v \leq 20 n_v\)}} (oder sogar \((1-\varepsilon)n_v \leq \tilde n_v \leq (1+\varepsilon)n_v\)).
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Approximation der Erreichbarkeit (gerichtet)
Die Menge der von \(v\) erreichbaren Knoten ist \(R(v) = \{u \in V : u \text{ von } v \text{ erreichbar}\}\), und man schreibt \(n_v = |R(v)|\) für ihre Grösse.
Da exaktes Zählen vermutlich nicht nahe-linear geht, approximiert man \(n_v\): berechne \(\tilde n_v\) mit {{c2::\(\tfrac{n_v}{20} \leq \tilde n_v \leq 20 n_v\) (oder sogar \((1-\varepsilon)n_v \leq \tilde n_v \leq (1+\varepsilon)n_v\))}}.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Approximation der Erreichbarkeit (gerichtet)
Die Menge der von \(v\) erreichbaren Knoten ist \(R(v) = \{u \in V : u \text{ von } v \text{ erreichbar}\}\), und man schreibt \(n_v = |R(v)|\) für ihre Grösse.
Da exaktes Zählen vermutlich nicht nahe-linear geht, approximiert man \(n_v\): berechne \(\tilde n_v\) mit {{c2::\(\tfrac{n_v}{20} \leq \tilde n_v \leq 20 n_v\) (oder sogar \((1-\varepsilon)n_v \leq \tilde n_v \leq (1+\varepsilon)n_v\))}}.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Approximation der Erreichbarkeit (gerichtet)</b><br>Die Menge der von \(v\) erreichbaren Knoten ist \(R(v) = \{u \in V : u \text{ von } v \text{ erreichbar}\}\), und man schreibt {{c1::\(n_v = |R(v)|\)}} für ihre Grösse.<br><br>Da exaktes Zählen vermutlich nicht nahe-linear geht, approximiert man \(n_v\): berechne \(\tilde n_v\) mit {{c2::\(\tfrac{n_v}{20} \leq \tilde n_v \leq 20 n_v\)}} (oder sogar \((1-\varepsilon)n_v \leq \tilde n_v \leq (1+\varepsilon)n_v\)). |
<b>Approximation der Erreichbarkeit (gerichtet)</b><br>Die Menge der von \(v\) erreichbaren Knoten ist \(R(v) = \{u \in V : u \text{ von } v \text{ erreichbar}\}\), und man schreibt {{c1::\(n_v = |R(v)|\)}} für ihre Grösse.<br><br>Da exaktes Zählen vermutlich nicht nahe-linear geht, approximiert man \(n_v\): berechne \(\tilde n_v\) mit {{c2::\(\tfrac{n_v}{20} \leq \tilde n_v \leq 20 n_v\) (oder sogar \((1-\varepsilon)n_v \leq \tilde n_v \leq (1+\varepsilon)n_v\))}}. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 27: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: SnM~n@l(Tz
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Erwartungswert ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für beliebige Zufallsvariablen \(X_1, X_2, \ldots, X_n\) und Konstanten \(a_1, \ldots, a_n\) gilt
\(\mathbb{E}[a_1 X_1 + a_2 X_2 + \ldots + a_n X_n] = a_1 \mathbb{E}[X_1] + \ldots + a_n \mathbb{E}[X_n]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Erwartungswert ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für beliebige Zufallsvariablen \(X_1, X_2, \ldots, X_n\) und Konstanten \(a_1, \ldots, a_n\) gilt
\(\mathbb{E}[a_1 X_1 + a_2 X_2 + \ldots + a_n X_n] = a_1 \mathbb{E}[X_1] + \ldots + a_n \mathbb{E}[X_n]\).
Wahr.
Linearität des Erwartungswerts. Sie gilt für beliebige Zufallsvariablen, auch wenn diese nicht unabhängig sind.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Für beliebige Zufallsvariablen \(X_1, X_2, \ldots, X_n\) und Konstanten \(a_1, \ldots, a_n\) gilt<br>\(\mathbb{E}[a_1 X_1 + a_2 X_2 + \ldots + a_n X_n] = a_1 \mathbb{E}[X_1] + \ldots + a_n \mathbb{E}[X_n]\). |
| Back |
|
Wahr.<br><br>Linearität des Erwartungswerts. Sie gilt für beliebige Zufallsvariablen, auch wenn diese nicht unabhängig sind. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::1._Erwartungswert
ETH::2._Semester::A&W::Minitests::4
Note 28: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: U!DdON#Iwd
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Sind \(X\) und \(Y\) unabhängige Zufallsvariablen, dann ist \(\mathbb{E}[XY] = \mathbb{E}[X]\,\mathbb{E}[Y]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Sind \(X\) und \(Y\) unabhängige Zufallsvariablen, dann ist \(\mathbb{E}[XY] = \mathbb{E}[X]\,\mathbb{E}[Y]\).
Wahr.
Für unabhängige Zufallsvariablen faktorisiert der Erwartungswert des Produkts. (Die Umkehrung gilt nicht: \(\mathbb{E}[XY] = \mathbb{E}[X]\,\mathbb{E}[Y]\) bedeutet nur Unkorreliertheit, nicht Unabhängigkeit.)
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sind \(X\) und \(Y\) unabhängige Zufallsvariablen, dann ist \(\mathbb{E}[XY] = \mathbb{E}[X]\,\mathbb{E}[Y]\). |
| Back |
|
Wahr.<br><br>Für unabhängige Zufallsvariablen faktorisiert der Erwartungswert des Produkts. (Die Umkehrung gilt nicht: \(\mathbb{E}[XY] = \mathbb{E}[X]\,\mathbb{E}[Y]\) bedeutet nur Unkorreliertheit, nicht Unabhängigkeit.) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::6._Mehrere_Zufallsvariablen::1._Unabhängigkeit_von_Zufallsvariablen
ETH::2._Semester::A&W::Minitests::4
Note 29: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: W`udl4Z*k;
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
ReachabilityCounting (Faktor-20-Approximation)
Wähle \(\ell = \lceil 2 \log_2(2n/\delta) \rceil\) Läufe. In jedem Lauf \(i\): ziehe \(r_{i,v} \sim \mathrm{Uniform}([0,1])\) und berechne \(x_{i,v} = \min_{u\in R(v)} r_{i,u}\) mit der Subroutine.
Setze \(x_v = \mathrm{Median}(x_{1,v}, \ldots, x_{\ell,v})\) und gib \(\tilde n_v = 1/x_v\) zurück.
Laufzeit: \(O((n \log n + m)\log(n/\delta))\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
ReachabilityCounting (Faktor-20-Approximation)
Wähle \(\ell = \lceil 2 \log_2(2n/\delta) \rceil\) Läufe. In jedem Lauf \(i\): ziehe \(r_{i,v} \sim \mathrm{Uniform}([0,1])\) und berechne \(x_{i,v} = \min_{u\in R(v)} r_{i,u}\) mit der Subroutine.
Setze \(x_v = \mathrm{Median}(x_{1,v}, \ldots, x_{\ell,v})\) und gib \(\tilde n_v = 1/x_v\) zurück.
Laufzeit: \(O((n \log n + m)\log(n/\delta))\).
ReachabilityCounting(G):
ℓ := ⌈2 log_2(2n/δ)⌉
for i = 1, ..., ℓ:
r_{i,v} := Uniform([0,1]) für alle v
x_{i,v} := min_{u ∈ R(v)} r_{i,u} # Subroutine, O(n log n + m)
x_v := Median(x_{1,v}, ..., x_{ℓ,v}) für alle v
return ñ_v := 1/x_v für alle v
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
ReachabilityCounting (Faktor-20-Approximation)
Wähle \(\ell = \lceil 2 \log_2(2n/\delta) \rceil\) Läufe.
In jedem Lauf \(i\): ziehe \(r_{i,v} \sim \mathrm{Uniform}([0,1])\) und berechne \(x_{i,v} = \min_{u\in R(v)} r_{i,u}\) mit der Subroutine.
Setze \(x_v = \mathrm{Median}(x_{1,v}, \ldots, x_{\ell,v})\) und gib \(\tilde n_v = 1/x_v\) zurück.
Laufzeit: \(O((n \log n + m)\log(n/\delta))\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
ReachabilityCounting (Faktor-20-Approximation)
Wähle \(\ell = \lceil 2 \log_2(2n/\delta) \rceil\) Läufe.
In jedem Lauf \(i\): ziehe \(r_{i,v} \sim \mathrm{Uniform}([0,1])\) und berechne \(x_{i,v} = \min_{u\in R(v)} r_{i,u}\) mit der Subroutine.
Setze \(x_v = \mathrm{Median}(x_{1,v}, \ldots, x_{\ell,v})\) und gib \(\tilde n_v = 1/x_v\) zurück.
Laufzeit: \(O((n \log n + m)\log(n/\delta))\).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>ReachabilityCounting (Faktor-20-Approximation)</b><br>Wähle {{c1::\(\ell = \lceil 2 \log_2(2n/\delta) \rceil\)}} Läufe. In jedem Lauf \(i\): ziehe \(r_{i,v} \sim \mathrm{Uniform}([0,1])\) und berechne \(x_{i,v} = \min_{u\in R(v)} r_{i,u}\) mit der Subroutine.<br>Setze \(x_v = \mathrm{Median}(x_{1,v}, \ldots, x_{\ell,v})\) und gib {{c2::\(\tilde n_v = 1/x_v\)}} zurück.<br><br>Laufzeit: {{c3::\(O((n \log n + m)\log(n/\delta))\)}}. |
<b>ReachabilityCounting (Faktor-20-Approximation)</b><br>Wähle {{c1::\(\ell = \lceil 2 \log_2(2n/\delta) \rceil\)}} Läufe. <br>In jedem Lauf \(i\): ziehe \(r_{i,v} \sim \mathrm{Uniform}([0,1])\) und berechne \(x_{i,v} = \min_{u\in R(v)} r_{i,u}\) mit der Subroutine.<br>Setze \(x_v = \mathrm{Median}(x_{1,v}, \ldots, x_{\ell,v})\) und gib {{c2::\(\tilde n_v = 1/x_v\)}} zurück.<br><br>Laufzeit: {{c3::\(O((n \log n + m)\log(n/\delta))\)}}. |
| Extra |
<pre>ReachabilityCounting(G):
ℓ := ⌈2 log_2(2n/δ)⌉
for i = 1, ..., ℓ:
r_{i,v} := Uniform([0,1]) für alle v
x_{i,v} := min_{u ∈ R(v)} r_{i,u} # Subroutine, O(n log n + m)
x_v := Median(x_{1,v}, ..., x_{ℓ,v}) für alle v
return ñ_v := 1/x_v für alle v</pre> |
<img src="paste-76a3ea5fa2fdc0c3afd4eca0bd16625723b235b3.jpg"> |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 30: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: bu_xT)V=>+
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für zwei beliebige Ereignisse \(A, B\) mit \(\Pr[A] > 0\) und \(\Pr[B] > 0\) gilt \(\Pr[A \mid B]\,\Pr[B] = \Pr[B \mid A]\,\Pr[A]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für zwei beliebige Ereignisse \(A, B\) mit \(\Pr[A] > 0\) und \(\Pr[B] > 0\) gilt \(\Pr[A \mid B]\,\Pr[B] = \Pr[B \mid A]\,\Pr[A]\).
Wahr.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für zwei beliebige Ereignisse \(A, B\) mit \(\Pr[A] > 0\) und \(\Pr[B] > 0\) gilt \(\Pr[A \mid B]\,\Pr[B] = \Pr[B \mid A]\,\Pr[A]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für zwei beliebige Ereignisse \(A, B\) mit \(\Pr[A] > 0\) und \(\Pr[B] > 0\) gilt \(\Pr[A \mid B]\,\Pr[B] = \Pr[B \mid A]\,\Pr[A]\).
Wahr.
Beide Seiten sind gleich \(\Pr[A \cap B]\): Nach Definition der bedingten Wahrscheinlichkeit gilt \(\Pr[A \mid B]\,\Pr[B] = \Pr[A \cap B] = \Pr[B \mid A]\,\Pr[A]\).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Beide Seiten sind gleich \(\Pr[A \cap B]\): Nach Definition der bedingten Wahrscheinlichkeit gilt \(\Pr[A \mid B]\,\Pr[B] = \Pr[A \cap B] = \Pr[B \mid A]\,\Pr[A]\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::2._Bedingte_Wahrscheinlichkeiten
ETH::2._Semester::A&W::Minitests::3
Note 31: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: c+mRr)D/mQ
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken::1._Bipartites_Matching_via_Maxflow ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Für jeden \(2\)-färbbaren Graphen \(G\) können wir mithilfe eines Flussproblems herausfinden, ob \(G\) ein perfektes Matching hat.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken::1._Bipartites_Matching_via_Maxflow ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Für jeden \(2\)-färbbaren Graphen \(G\) können wir mithilfe eines Flussproblems herausfinden, ob \(G\) ein perfektes Matching hat.
Wahr.
\(2\)-färbbar bedeutet bipartit. In bipartiten Graphen lässt sich ein kardinalitätsmaximales Matching über ein Flussproblem bestimmen (Quelle \(\to\) eine Seite \(\to\) andere Seite \(\to\) Senke, alle Kapazitäten 1). Ein perfektes Matching existiert genau dann, wenn der maximale Fluss den Wert \(|A| = |B|\) erreicht.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Für jeden \(2\)-färbbaren Graphen \(G\) können wir mithilfe eines Flussproblems herausfinden, ob \(G\) ein perfektes Matching hat. |
| Back |
|
Wahr.<br><br>\(2\)-färbbar bedeutet bipartit. In bipartiten Graphen lässt sich ein kardinalitätsmaximales Matching über ein Flussproblem bestimmen (Quelle \(\to\) eine Seite \(\to\) andere Seite \(\to\) Senke, alle Kapazitäten 1). Ein perfektes Matching existiert genau dann, wenn der maximale Fluss den Wert \(|A| = |B|\) erreicht. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken::1._Bipartites_Matching_via_Maxflow
ETH::2._Semester::A&W::Minitests::6
Note 32: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: c3AJ4U}:te
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Quicksort ist ein Monte-Carlo-Algorithmus.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Quicksort ist ein Monte-Carlo-Algorithmus.
Falsch.
Randomisiertes Quicksort ist ein Las-Vegas-Algorithmus: Es liefert immer das korrekte (sortierte) Ergebnis, nur die Laufzeit ist zufällig. Ein Monte-Carlo-Algorithmus darf dagegen mit gewisser Wahrscheinlichkeit falsch antworten.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Quicksort ist ein Monte-Carlo-Algorithmus. |
| Back |
|
Falsch.<br><br>Randomisiertes Quicksort ist ein Las-Vegas-Algorithmus: Es liefert immer das korrekte (sortierte) Ergebnis, nur die Laufzeit ist zufällig. Ein Monte-Carlo-Algorithmus darf dagegen mit gewisser Wahrscheinlichkeit falsch antworten. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::2._Sortieren_und_Selektieren
ETH::2._Semester::A&W::Minitests::5
Note 33: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: goHp3a#@$a
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für jedes \( t \geq 3 \) ist ein vollständiger Graph \( K_t \) mit \( t \) Knoten 2-zusammenhängend.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für jedes \( t \geq 3 \) ist ein vollständiger Graph \( K_t \) mit \( t \) Knoten 2-zusammenhängend.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für jedes \( t \geq 3 \) ist ein vollständiger Graph \( K_t \) mit \( t \) Knoten 2-zusammenhängend.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Für jedes \( t \geq 3 \) ist ein vollständiger Graph \( K_t \) mit \( t \) Knoten 2-zusammenhängend.
Wahr.
Der Knotenzusammenhang ist \(\kappa(K_t) = t - 1 \geq 2\) für \(t \geq 3\). Das Entfernen eines einzelnen Knotens lässt \(K_{t-1}\) übrig, was zusammenhängend ist.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Der Knotenzusammenhang ist \(\kappa(K_t) = t - 1 \geq 2\) für \(t \geq 3\). Das Entfernen eines einzelnen Knotens lässt \(K_{t-1}\) übrig, was zusammenhängend ist. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang
ETH::2._Semester::A&W::Minitests::1
Note 34: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: ha%W|}X%+q
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Wenn \(A, B, C\) drei unabhängige Ereignisse sind, dann
\(\Pr[A \cap B] = \Pr[A]\,\Pr[B]\),
\(\Pr[B \cap C] = \Pr[B]\,\Pr[C]\), und
\(\Pr[A \cap C] = \Pr[A]\,\Pr[C]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Wenn \(A, B, C\) drei unabhängige Ereignisse sind, dann
\(\Pr[A \cap B] = \Pr[A]\,\Pr[B]\),
\(\Pr[B \cap C] = \Pr[B]\,\Pr[C]\), und
\(\Pr[A \cap C] = \Pr[A]\,\Pr[C]\).
Wahr.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Wenn \(A, B, C\) drei unabhängige Ereignisse sind, dann
\(\Pr[A \cap B] = \Pr[A]\,\Pr[B]\),
\(\Pr[B \cap C] = \Pr[B]\,\Pr[C]\), und
\(\Pr[A \cap C] = \Pr[A]\,\Pr[C]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Wenn \(A, B, C\) drei unabhängige Ereignisse sind, dann
\(\Pr[A \cap B] = \Pr[A]\,\Pr[B]\),
\(\Pr[B \cap C] = \Pr[B]\,\Pr[C]\), und
\(\Pr[A \cap C] = \Pr[A]\,\Pr[C]\).
Wahr.
Vollständige (gemeinsame) Unabhängigkeit verlangt die Produktformel für jede Teilmenge der Ereignisse, insbesondere für alle Paare. Also folgt paarweise Unabhängigkeit. (Die Umkehrung gilt nicht.)
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Vollständige (gemeinsame) Unabhängigkeit verlangt die Produktformel für jede Teilmenge der Ereignisse, insbesondere für alle Paare. Also folgt paarweise Unabhängigkeit. (Die Umkehrung gilt nicht.) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::3._Unabhängigkeit
ETH::2._Semester::A&W::Minitests::3
Note 35: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: heIBL*PYbg
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).
Ein Kantenschnitt ist eine Menge \(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist.
Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst \(\mu(G)\) und ist definiert als\[\mu(G) := {{c2::\min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|}}.\]
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).
Ein Kantenschnitt ist eine Menge \(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist.
Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst \(\mu(G)\) und ist definiert als\[\mu(G) := {{c2::\min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|}}.\]
Äquivalente Sichtweise: Ein Schnitt ist eine Partition \(V = S \sqcup T\) mit \(S, T \neq \emptyset\); man minimiert die Anzahl Kanten zwischen \(S\) und \(T\). Mehrfachkanten dürfen auch durch positiv ganzzahlige Kantengewichte realisiert werden.
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).
Ein Kantenschnitt ist eine Menge \(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist.
Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst \(\mu(G)\) und ist definiert als\[{{c2::\mu(G) := \min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|.}}\]
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).
Ein Kantenschnitt ist eine Menge \(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist.
Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst \(\mu(G)\) und ist definiert als\[{{c2::\mu(G) := \min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|.}}\]
Äquivalente Sichtweise: Ein Schnitt ist eine Partition \(V = S \sqcup T\) mit \(S, T \neq \emptyset\); man minimiert die Anzahl Kanten zwischen \(S\) und \(T\). Mehrfachkanten dürfen auch durch positiv ganzzahlige Kantengewichte realisiert werden.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).<br><br>Ein <b>Kantenschnitt</b> ist eine Menge {{c1::\(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist}}.<br><br>Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst {{c2::\(\mu(G)\)}} und ist definiert als\[\mu(G) := {{c2::\min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|}}.\] |
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).<br><br>Ein <b>Kantenschnitt</b> ist eine Menge {{c1::\(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist}}.<br><br>Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst {{c2::\(\mu(G)\)}} und ist definiert als\[{{c2::\mu(G) := \min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|.}}\] |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
Note 36: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: i.:>Mx]{tq
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Wenn \( G = (V, E) \) ein 3-zusammenhängender Graph ist und \( v \in V \), dann ist \( G[V \setminus \{v\}] \) 2-zusammenhängend.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Wenn \( G = (V, E) \) ein 3-zusammenhängender Graph ist und \( v \in V \), dann ist \( G[V \setminus \{v\}] \) 2-zusammenhängend.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Wenn \( G = (V, E) \) ein 3-zusammenhängender Graph ist und \( v \in V \), dann ist \( G[V \setminus \{v\}] \) 2-zusammenhängend.
Back
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Wenn \( G = (V, E) \) ein 3-zusammenhängender Graph ist und \( v \in V \), dann ist \( G[V \setminus \{v\}] \) 2-zusammenhängend.
Wahr.
Das Entfernen eines Knotens senkt den Knotenzusammenhang um höchstens 1: \(\kappa(G - v) \geq \kappa(G) - 1 \geq 3 - 1 = 2\). Also ist \(G[V \setminus \{v\}]\) 2-zusammenhängend.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Das Entfernen eines Knotens senkt den Knotenzusammenhang um höchstens 1: \(\kappa(G - v) \geq \kappa(G) - 1 \geq 3 - 1 = 2\). Also ist \(G[V \setminus \{v\}]\) 2-zusammenhängend. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::4._Zusammenhang
ETH::2._Semester::A&W::Minitests::1
Note 37: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: iFT1qkyT$@
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Ein deterministischer Algorithmus kann immer als randomisierter Algorithmus gesehen werden.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Ein deterministischer Algorithmus kann immer als randomisierter Algorithmus gesehen werden.
Wahr.
Ein deterministischer Algorithmus ist der Spezialfall eines randomisierten Algorithmus, der die zur Verfügung stehenden Zufallsbits einfach ignoriert.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Ein deterministischer Algorithmus kann immer als randomisierter Algorithmus gesehen werden. |
| Back |
|
Wahr.<br><br>Ein deterministischer Algorithmus ist der Spezialfall eines randomisierten Algorithmus, der die zur Verfügung stehenden Zufallsbits einfach ignoriert. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
ETH::2._Semester::A&W::Minitests::5
Note 38: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: itUq/f`To4
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ist \(G\) ein Graph mit maximalem Grad \(\Delta(G)\), so findet der Greedy-Algorithmus (mit beliebiger Knotenreihenfolge) stets eine zulässige Färbung mit höchstens \(\Delta(G) + 1\) Farben.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ist \(G\) ein Graph mit maximalem Grad \(\Delta(G)\), so findet der Greedy-Algorithmus (mit beliebiger Knotenreihenfolge) stets eine zulässige Färbung mit höchstens \(\Delta(G) + 1\) Farben.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ist \(G\) ein Graph mit maximalem Grad \(\Delta(G)\), so findet der Greedy-Algorithmus (mit beliebiger Knotenreihenfolge) stets eine zulässige Färbung mit höchstens \(\Delta(G) + 1\) Farben.
Back
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ist \(G\) ein Graph mit maximalem Grad \(\Delta(G)\), so findet der Greedy-Algorithmus (mit beliebiger Knotenreihenfolge) stets eine zulässige Färbung mit höchstens \(\Delta(G) + 1\) Farben.
Wahr.
Beim Greedy-Färben hat jeder Knoten höchstens \(\Delta(G)\) bereits gefärbte Nachbarn. Unter \(\Delta(G) + 1\) Farben ist daher stets mindestens eine frei.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Beim Greedy-Färben hat jeder Knoten höchstens \(\Delta(G)\) bereits gefärbte Nachbarn. Unter \(\Delta(G) + 1\) Farben ist daher stets mindestens eine frei. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::7._Färbungen
ETH::2._Semester::A&W::Minitests::2
Note 39: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: k/*bc^92[M
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ein (kardinalitäts-)maximale Matching in einem bipartiten Graphen kann in der Zeit \(O(\sqrt{|V|}(|V| + |E|))\) gefunden werden.
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ein (kardinalitäts-)maximale Matching in einem bipartiten Graphen kann in der Zeit \(O(\sqrt{|V|}(|V| + |E|))\) gefunden werden.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ein (kardinalitäts-)maximale Matching in einem bipartiten Graphen kann in der Zeit \(O(\sqrt{|V|}(|V| + |E|))\) gefunden werden.
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Ein (kardinalitäts-)maximale Matching in einem bipartiten Graphen kann in der Zeit \(O(\sqrt{|V|}(|V| + |E|))\) gefunden werden.
Wahr.
Das ist die Laufzeit des Hopcroft-Karp-Algorithmus für kardinalitätsmaximale Matchings in bipartiten Graphen.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Das ist die Laufzeit des Hopcroft-Karp-Algorithmus für kardinalitätsmaximale Matchings in bipartiten Graphen. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings
ETH::2._Semester::A&W::Minitests::2
Note 40: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: m4#lyB@&R)
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Jeder Monte-Carlo-Algorithmus kann in einen Las-Vegas-Algorithmus umgewandelt werden.
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit ETH::2._Semester::A&W::Minitests::5
Wahr oder falsch?
Jeder Monte-Carlo-Algorithmus kann in einen Las-Vegas-Algorithmus umgewandelt werden.
Falsch.
Die Umwandlung Monte Carlo \(\to\) Las Vegas setzt voraus, dass man eine Ausgabe effizient auf Korrektheit prüfen kann. Ohne eine solche Verifikation lässt sich der Fehler nicht ausschliessen. (Umgekehrt geht es immer: Las Vegas \(\to\) Monte Carlo durch Abbruch.)
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Jeder Monte-Carlo-Algorithmus kann in einen Las-Vegas-Algorithmus umgewandelt werden. |
| Back |
|
Falsch.<br><br>Die Umwandlung Monte Carlo \(\to\) Las Vegas setzt voraus, dass man eine Ausgabe effizient auf Korrektheit prüfen kann. Ohne eine solche Verifikation lässt sich der Fehler nicht ausschliessen. (Umgekehrt geht es immer: Las Vegas \(\to\) Monte Carlo durch Abbruch.) |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::8._Randomisierte_Algorithmen::1._Reduktion_der_Fehlerwahrscheinlichkeit
ETH::2._Semester::A&W::Minitests::5
Note 41: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: nqB#s@hN8H
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder zusammenhängende Graph mit allen Knoten geraden Grades hat einen Eulerkreis.
Back
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder zusammenhängende Graph mit allen Knoten geraden Grades hat einen Eulerkreis.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder zusammenhängende Graph mit allen Knoten geraden Grades hat einen Eulerkreis.
Back
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Jeder zusammenhängende Graph mit allen Knoten geraden Grades hat einen Eulerkreis.
Wahr.
Satz von Euler: Ein zusammenhängender Graph besitzt genau dann einen Eulerkreis, wenn jeder Knoten geraden Grad hat.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Satz von Euler: Ein zusammenhängender Graph besitzt genau dann einen Eulerkreis, wenn jeder Knoten geraden Grad hat. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::1._Grundbegriffe_&_Notationen::1._Zusammenhänge_und_Bäume
ETH::2._Semester::A&W::Minitests::1
Note 42: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: o;UWu[N~}|
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für eine Zufallsvariable \(X\) und eine Konstante \(a\) gilt \(\text{Var}[X + a] = \text{Var}[X] + a\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Für eine Zufallsvariable \(X\) und eine Konstante \(a\) gilt \(\text{Var}[X + a] = \text{Var}[X] + a\).
Falsch.
Eine additive Konstante verschiebt nur den Erwartungswert, nicht die Streuung: \(\text{Var}[X + a] = \text{Var}[X]\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Für eine Zufallsvariable \(X\) und eine Konstante \(a\) gilt \(\text{Var}[X + a] = \text{Var}[X] + a\). |
| Back |
|
Falsch.<br><br>Eine additive Konstante verschiebt nur den Erwartungswert, nicht die Streuung: \(\text{Var}[X + a] = \text{Var}[X]\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz
ETH::2._Semester::A&W::Minitests::4
Note 43: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: qUCywE=:ez
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(G\) ein Multigraph. Wenn es einen minimalen Schnitt \(C\) von \(G\) mit \(e \notin C\) gibt, dann gilt \(\mu(G/e) = \mu(G)\), wobei \(\mu(G)\) die Kardinalität eines minimalen Schnitts in \(G\) bezeichnet.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(G\) ein Multigraph. Wenn es einen minimalen Schnitt \(C\) von \(G\) mit \(e \notin C\) gibt, dann gilt \(\mu(G/e) = \mu(G)\), wobei \(\mu(G)\) die Kardinalität eines minimalen Schnitts in \(G\) bezeichnet.
Wahr.
Gehört \(e\) nicht zum Minimalschnitt \(C\), so überlebt \(C\) die Kontraktion und liefert \(\mu(G/e) \leq \mu(G)\). Zusammen mit \(\mu(G/e) \geq \mu(G)\) (Kontraktion verkleinert den Schnitt nie) folgt Gleichheit. Kargers Algorithmus zerstört \(C\) also nicht, wenn er \(e\) kontrahiert.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(G\) ein Multigraph. Wenn es einen minimalen Schnitt \(C\) von \(G\) mit \(e \notin C\) gibt, dann gilt \(\mu(G/e) = \mu(G)\), wobei \(\mu(G)\) die Kardinalität eines minimalen Schnitts in \(G\) bezeichnet. |
| Back |
|
Wahr.<br><br>Gehört \(e\) nicht zum Minimalschnitt \(C\), so überlebt \(C\) die Kontraktion und liefert \(\mu(G/e) \leq \mu(G)\). Zusammen mit \(\mu(G/e) \geq \mu(G)\) (Kontraktion verkleinert den Schnitt nie) folgt Gleichheit. Kargers Algorithmus zerstört \(C\) also nicht, wenn er \(e\) kontrahiert. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
ETH::2._Semester::A&W::Minitests::6
Note 44: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: qXf%fOj@KW
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Seien \(X, Y\) unabhängige Zufallsvariablen mit \(\text{Var}[X] = 1\) und \(\text{Var}[Y] = 4\). Dann ist \(\text{Var}[X - Y] = -3\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Seien \(X, Y\) unabhängige Zufallsvariablen mit \(\text{Var}[X] = 1\) und \(\text{Var}[Y] = 4\). Dann ist \(\text{Var}[X - Y] = -3\).
Falsch.
Eine Varianz ist nie negativ. Für unabhängige Variablen gilt \(\text{Var}[X - Y] = \text{Var}[X] + \text{Var}[Y] = 1 + 4 = 5\) (das Minuszeichen quadriert sich weg).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Seien \(X, Y\) unabhängige Zufallsvariablen mit \(\text{Var}[X] = 1\) und \(\text{Var}[Y] = 4\). Dann ist \(\text{Var}[X - Y] = -3\). |
| Back |
|
Falsch.<br><br>Eine Varianz ist nie negativ. Für unabhängige Variablen gilt \(\text{Var}[X - Y] = \text{Var}[X] + \text{Var}[Y] = 1 + 4 = 5\) (das Minuszeichen quadriert sich weg). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz
ETH::2._Semester::A&W::Minitests::4
Note 45: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: r{e*;R=MrL
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk, \(f\) ein Fluss in \(N\) und \((S, T)\) ein \(s\)-\(t\)-Schnitt in \(N\). Dann gilt \(\mathrm{val}(f) \geq \mathrm{cap}(S, T)\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk, \(f\) ein Fluss in \(N\) und \((S, T)\) ein \(s\)-\(t\)-Schnitt in \(N\). Dann gilt \(\mathrm{val}(f) \geq \mathrm{cap}(S, T)\).
Falsch.
Es gilt stets die umgekehrte Ungleichung (schwache Dualität): \(\mathrm{val}(f) \leq \mathrm{cap}(S, T)\) für jeden Fluss und jeden \(s\)-\(t\)-Schnitt. Gleichheit tritt genau bei maximalem Fluss und minimalem Schnitt ein (Max-Flow-Min-Cut).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(N = (V, A, c, s, t)\) ein Netzwerk, \(f\) ein Fluss in \(N\) und \((S, T)\) ein \(s\)-\(t\)-Schnitt in \(N\). Dann gilt \(\mathrm{val}(f) \geq \mathrm{cap}(S, T)\). |
| Back |
|
Falsch.<br><br>Es gilt stets die umgekehrte Ungleichung (schwache Dualität): \(\mathrm{val}(f) \leq \mathrm{cap}(S, T)\) für jeden Fluss und jeden \(s\)-\(t\)-Schnitt. Gleichheit tritt genau bei maximalem Fluss und minimalem Schnitt ein (Max-Flow-Min-Cut). |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken
ETH::2._Semester::A&W::Minitests::6
Note 46: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: s!zsm$&sf}
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Für einen vollständigen Graphen \(G\) mit gerader Anzahl von Knoten und positiven Gewichten \(\ell(x,y)\), der die Dreiecksungleichung erfüllt, sei \(M\) ein perfektes Matching mit minimalen Kosten und \(C\) die minimale Kosten-Reise des Handlungsreisenden (TSP-Tour).
Dann ist \(\ell(M) \leq \ell(C)/2\).
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Für einen vollständigen Graphen \(G\) mit gerader Anzahl von Knoten und positiven Gewichten \(\ell(x,y)\), der die Dreiecksungleichung erfüllt, sei \(M\) ein perfektes Matching mit minimalen Kosten und \(C\) die minimale Kosten-Reise des Handlungsreisenden (TSP-Tour).
Dann ist \(\ell(M) \leq \ell(C)/2\).
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Für einen vollständigen Graphen \(G\) mit gerader Anzahl von Knoten und positiven Gewichten \(\ell(x,y)\), der die Dreiecksungleichung erfüllt, sei \(M\) ein perfektes Matching mit minimalen Kosten und \(C\) die minimale Kosten-Reise des Handlungsreisenden (TSP-Tour).
Dann ist \(\ell(M) \leq \ell(C)/2\).
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Für einen vollständigen Graphen \(G\) mit gerader Anzahl von Knoten und positiven Gewichten \(\ell(x,y)\), der die Dreiecksungleichung erfüllt, sei \(M\) ein perfektes Matching mit minimalen Kosten und \(C\) die minimale Kosten-Reise des Handlungsreisenden (TSP-Tour).
Dann ist \(\ell(M) \leq \ell(C)/2\).
Wahr.
Die optimale TSP-Tour \(C\) ist ein Hamiltonkreis gerader Länge und zerfällt in zwei kantendisjunkte perfekte Matchings. Jedes davon hat Kosten \(\geq \ell(M)\), also \(\ell(C) \geq 2\,\ell(M)\), d. h. \(\ell(M) \leq \ell(C)/2\).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Die optimale TSP-Tour \(C\) ist ein Hamiltonkreis gerader Länge und zerfällt in zwei kantendisjunkte perfekte Matchings. Jedes davon hat Kosten \(\geq \ell(M)\), also \(\ell(C) \geq 2\,\ell(M)\), d. h. \(\ell(M) \leq \ell(C)/2\). |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings
ETH::2._Semester::A&W::Minitests::2
Note 47: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: s*WL?i;Ys/
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Wenn \(e\) eine Kante eines Multigraphen \(G\) ist, dann gilt immer \(\mu(G/e) \leq \mu(G)\), wobei \(\mu(G)\) die Kardinalität eines minimalen Schnitts in \(G\) bezeichnet.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Wenn \(e\) eine Kante eines Multigraphen \(G\) ist, dann gilt immer \(\mu(G/e) \leq \mu(G)\), wobei \(\mu(G)\) die Kardinalität eines minimalen Schnitts in \(G\) bezeichnet.
Falsch.
Kontraktion kann den minimalen Schnitt nur vergrössern oder gleich lassen: \(\mu(G/e) \geq \mu(G)\). Durch das Verschmelzen der Endknoten von \(e\) fallen genau jene Schnitte weg, die diese beiden Knoten trennen, sodass nie ein kleinerer Schnitt entsteht. (Genau das macht Kargers Algorithmus korrekt.)
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Wenn \(e\) eine Kante eines Multigraphen \(G\) ist, dann gilt immer \(\mu(G/e) \leq \mu(G)\), wobei \(\mu(G)\) die Kardinalität eines minimalen Schnitts in \(G\) bezeichnet. |
| Back |
|
Falsch.<br><br>Kontraktion kann den minimalen Schnitt nur vergrössern oder gleich lassen: \(\mu(G/e) \geq \mu(G)\). Durch das Verschmelzen der Endknoten von \(e\) fallen genau jene Schnitte weg, die diese beiden Knoten trennen, sodass nie ein kleinerer Schnitt entsteht. (Genau das macht Kargers Algorithmus korrekt.) |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
ETH::2._Semester::A&W::Minitests::6
Note 48: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: sX~}|v&|ng
modified
Before
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für drei beliebige Ereignisse \(A, B, C\) gilt \(\Pr[A \cup B \cup C] = \Pr[A] + \Pr[B] + \Pr[C] - \Pr[A \cap B] - \Pr[A \cap C] - \Pr[B \cap C] + \Pr[A \cap B \cap C]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für drei beliebige Ereignisse \(A, B, C\) gilt \(\Pr[A \cup B \cup C] = \Pr[A] + \Pr[B] + \Pr[C] - \Pr[A \cap B] - \Pr[A \cap C] - \Pr[B \cap C] + \Pr[A \cap B \cap C]\).
Wahr.
After
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für drei beliebige Ereignisse \(A, B, C\) gilt \(\Pr[A \cup B \cup C] = \Pr[A] + \Pr[B] + \Pr[C] - \Pr[A \cap B] - \Pr[A \cap C] - \Pr[B \cap C] + \Pr[A \cap B \cap C]\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen ETH::2._Semester::A&W::Minitests::3
Wahr oder falsch?
Für drei beliebige Ereignisse \(A, B, C\) gilt \(\Pr[A \cup B \cup C] = \Pr[A] + \Pr[B] + \Pr[C] - \Pr[A \cap B] - \Pr[A \cap C] - \Pr[B \cap C] + \Pr[A \cap B \cap C]\).
Wahr.
Das ist die Inklusions-Exklusions-Formel (Siebformel) für drei Ereignisse; sie gilt für beliebige, nicht notwendig unabhängige Ereignisse.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Das ist die Inklusions-Exklusions-Formel (Siebformel) für drei Ereignisse; sie gilt für beliebige, nicht notwendig unabhängige Ereignisse. |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::1._Grundbegriffe_und_Notationen
ETH::2._Semester::A&W::Minitests::3
Note 49: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: t(Mpx9`&5i
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk. Wenn \(c\) nur ganzzahlige Werte annimmt, so ist jeder maximale Fluss in \(N\) ganzzahlig.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk. Wenn \(c\) nur ganzzahlige Werte annimmt, so ist jeder maximale Fluss in \(N\) ganzzahlig.
Falsch.
Der Ganzzahligkeitssatz garantiert nur, dass ein ganzzahliger maximaler Fluss existiert, nicht dass jeder maximale Fluss ganzzahlig ist. Bei mehreren maximalen Wegen kann man den Flusswert auch gebrochen (etwa \(0.5\)) auf parallele Pfade aufteilen.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(N = (V, A, c, s, t)\) ein Netzwerk. Wenn \(c\) nur ganzzahlige Werte annimmt, so ist jeder maximale Fluss in \(N\) ganzzahlig. |
| Back |
|
Falsch.<br><br>Der Ganzzahligkeitssatz garantiert nur, dass ein ganzzahliger maximaler Fluss existiert, nicht dass jeder maximale Fluss ganzzahlig ist. Bei mehreren maximalen Wegen kann man den Flusswert auch gebrochen (etwa \(0.5\)) auf parallele Pfade aufteilen. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken
ETH::2._Semester::A&W::Minitests::6
Note 50: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: uKi[~bS3)r
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Das MIN-CUT-Problem für einen gegebenen Multigraphen \((V, E)\) kann gelöst werden, indem man einen Knoten \(s \in V\) fest wählt und minimale \(s\)-\(t\)-Schnitte für alle \(t \in V \setminus \{s\}\) berechnet.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Das MIN-CUT-Problem für einen gegebenen Multigraphen \((V, E)\) kann gelöst werden, indem man einen Knoten \(s \in V\) fest wählt und minimale \(s\)-\(t\)-Schnitte für alle \(t \in V \setminus \{s\}\) berechnet.
Wahr.
Ein globaler minimaler Schnitt trennt \(s\) von mindestens einem anderen Knoten \(t\). Berechnet man also für ein festes \(s\) die minimalen \(s\)-\(t\)-Schnitte über alle \(t \neq s\) und nimmt davon das Minimum, so erhält man den globalen Minimalschnitt.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Das MIN-CUT-Problem für einen gegebenen Multigraphen \((V, E)\) kann gelöst werden, indem man einen Knoten \(s \in V\) fest wählt und minimale \(s\)-\(t\)-Schnitte für alle \(t \in V \setminus \{s\}\) berechnet. |
| Back |
|
Wahr.<br><br>Ein globaler minimaler Schnitt trennt \(s\) von mindestens einem anderen Knoten \(t\). Berechnet man also für ein festes \(s\) die minimalen \(s\)-\(t\)-Schnitte über alle \(t \neq s\) und nimmt davon das Minimum, so erhält man den globalen Minimalschnitt. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::3._Minimale_Schnitte_in_Graphen
ETH::2._Semester::A&W::Minitests::6
Note 51: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: uQY~p8N1Tf
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten. Sei zudem die Kapazität jeder Kante höchstens \(U\). Dann berechnet der Ford-Fulkerson-Algorithmus in Zeit \(O(mnU)\) einen maximalen Fluss.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten. Sei zudem die Kapazität jeder Kante höchstens \(U\). Dann berechnet der Ford-Fulkerson-Algorithmus in Zeit \(O(mnU)\) einen maximalen Fluss.
Falsch.
Die Schranke \(O(mnU)\) gilt nur bei ganzzahligen (oder rationalen) Kapazitäten: dann wächst der Flusswert pro Augmentierung um \(\geq 1\), und \(\mathrm{val}(f^\ast) \leq nU\). Da die Ganzzahligkeit hier nicht vorausgesetzt wird, kann Ford-Fulkerson bei reellen Kapazitäten sogar gar nicht terminieren.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten. Sei zudem die Kapazität jeder Kante höchstens \(U\). Dann berechnet der Ford-Fulkerson-Algorithmus in Zeit \(O(mnU)\) einen maximalen Fluss. |
| Back |
|
Falsch.<br><br>Die Schranke \(O(mnU)\) gilt nur bei ganzzahligen (oder rationalen) Kapazitäten: dann wächst der Flusswert pro Augmentierung um \(\geq 1\), und \(\mathrm{val}(f^\ast) \leq nU\). Da die Ganzzahligkeit hier nicht vorausgesetzt wird, kann Ford-Fulkerson bei reellen Kapazitäten sogar gar nicht terminieren. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken
ETH::2._Semester::A&W::Minitests::6
Note 52: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: uf^.=Rr;Q]
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Wahr.
Satz von Brooks: Für einen zusammenhängenden Graphen gilt \(\chi(G) \leq \Delta(G)\), ausser \(G\) ist ein vollständiger Graph oder ein ungerader Kreis. Bei \(\Delta = 100\) ist \(G\) sicher kein ungerader Kreis (dort ist \(\Delta = 2\)), also genügen 100 Farben, sofern \(G\) nicht vollständig ist.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Satz von Brooks: Für einen zusammenhängenden Graphen gilt \(\chi(G) \leq \Delta(G)\), ausser \(G\) ist ein vollständiger Graph oder ein ungerader Kreis. Bei \(\Delta = 100\) ist \(G\) sicher kein ungerader Kreis (dort ist \(\Delta = 2\)), also genügen 100 Farben, sofern \(G\) nicht vollständig ist. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings
ETH::2._Semester::A&W::Minitests::2
Note 53: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: uzC1We:u-n
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Back
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings ETH::2._Semester::A&W::Minitests::2
Wahr oder falsch?
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Wahr.
Satz von Berge: Ein Matching \(M\) ist genau dann kardinalitätsmaximal, wenn es keinen \(M\)-augmentierenden Pfad gibt. Ist \(M\) nicht maximal, existiert also ein solcher Pfad (das gilt allgemein, nicht nur für bipartite Graphen).
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Satz von Berge: Ein Matching \(M\) ist genau dann kardinalitätsmaximal, wenn es keinen \(M\)-augmentierenden Pfad gibt. Ist \(M\) nicht maximal, existiert also ein solcher Pfad (das gilt allgemein, nicht nur für bipartite Graphen). |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::6._Matchings
ETH::2._Semester::A&W::Minitests::2
Note 54: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: v%M$D/Lp:4
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (gerichtet): Laufzeit
Für einen einzelnen Startknoten \(s\) bestimmt ein DFS/BFS die Anzahl erreichbarer Knoten in Zeit \(O(n + m)\).
Für alle Knoten ergibt das \(O(n(n + m))\).
Geht es schneller? Vermutlich nicht: Ein \(O(n^{0.99}(n+m))\)-Algorithmus würde \(k\)-SAT in \(O(1.999^n)\) lösen und damit der starken Exponentialzeithypothese (SETH) widersprechen.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (gerichtet): Laufzeit
Für einen einzelnen Startknoten \(s\) bestimmt ein DFS/BFS die Anzahl erreichbarer Knoten in Zeit \(O(n + m)\).
Für alle Knoten ergibt das \(O(n(n + m))\).
Geht es schneller? Vermutlich nicht: Ein \(O(n^{0.99}(n+m))\)-Algorithmus würde \(k\)-SAT in \(O(1.999^n)\) lösen und damit der starken Exponentialzeithypothese (SETH) widersprechen.
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (gerichtet): Laufzeit
Für einen einzelnen Startknoten \(s\) bestimmt ein DFS/BFS die Anzahl erreichbarer Knoten in Zeit \(O(n + m)\).
Für alle Knoten ergibt das \(O(n(n + m))\).
Geht es schneller? {{c3::Vermutlich nicht: Ein \(O(n^{0.99}(n+m))\)-Algorithmus würde \(k\)-SAT in \(O(1.999^n)\) lösen und damit der starken Exponentialzeithypothese (SETH) widersprechen}}.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (gerichtet): Laufzeit
Für einen einzelnen Startknoten \(s\) bestimmt ein DFS/BFS die Anzahl erreichbarer Knoten in Zeit \(O(n + m)\).
Für alle Knoten ergibt das \(O(n(n + m))\).
Geht es schneller? {{c3::Vermutlich nicht: Ein \(O(n^{0.99}(n+m))\)-Algorithmus würde \(k\)-SAT in \(O(1.999^n)\) lösen und damit der starken Exponentialzeithypothese (SETH) widersprechen}}.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Zählen erreichbarer Knoten (gerichtet): Laufzeit</b><br>Für einen <b>einzelnen</b> Startknoten \(s\) bestimmt ein DFS/BFS die Anzahl erreichbarer Knoten in Zeit \({{c1::O(n + m)}}\).<br>Für <b>alle</b> Knoten ergibt das \({{c2::O(n(n + m))}}\).<br><br>Geht es schneller? {{c3::Vermutlich nicht}}: Ein \(O(n^{0.99}(n+m))\)-Algorithmus würde \(k\)-SAT in \(O(1.999^n)\) lösen und damit der {{c4::starken Exponentialzeithypothese (SETH)}} widersprechen. |
<b>Zählen erreichbarer Knoten (gerichtet): Laufzeit</b><br>Für einen <b>einzelnen</b> Startknoten \(s\) bestimmt ein DFS/BFS die Anzahl erreichbarer Knoten in Zeit \({{c1::O(n + m)}}\).<br>Für <b>alle</b> Knoten ergibt das \({{c1::O(n(n + m))}}\).<br><br>Geht es schneller? {{c3::Vermutlich nicht: Ein \(O(n^{0.99}(n+m))\)-Algorithmus würde \(k\)-SAT in \(O(1.999^n)\) lösen und damit der starken Exponentialzeithypothese (SETH) widersprechen}}. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 55: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Cloze
GUID: xHPCu-
modified
Before
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (ungerichtet)
Gegeben ein ungerichteter Graph \(G\), bestimme für jeden Knoten \(v\) die Anzahl erreichbarer Knoten.
Idee: Berechne mit DFS die Zusammenhangskomponenten; die Antwort für \(v\) ist dann die Grösse der Komponente von \(v\).
Laufzeit: \(O(n + m)\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (ungerichtet)
Gegeben ein ungerichteter Graph \(G\), bestimme für jeden Knoten \(v\) die Anzahl erreichbarer Knoten.
Idee: Berechne mit DFS die Zusammenhangskomponenten; die Antwort für \(v\) ist dann die Grösse der Komponente von \(v\).
Laufzeit: \(O(n + m)\).
Konkret markiert ConnectedComponents jede Komponente mit einer eigenen Zahl, danach zählt man die Komponentengrössen \(\mathrm{cnt}[c]\) und setzt \(\mathrm{res}[v] = \mathrm{cnt}[\mathrm{comp}[v]]\).
After
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (ungerichtet)
Gegeben ein ungerichteter Graph \(G\), bestimme für jeden Knoten \(v\) die Anzahl erreichbarer Knoten.
Idee: Berechne mit DFS die Zusammenhangskomponenten; die Antwort für \(v\) ist dann die Grösse der Komponente von \(v\).
Laufzeit: \(O(n + m)\).
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Zählen erreichbarer Knoten (ungerichtet)
Gegeben ein ungerichteter Graph \(G\), bestimme für jeden Knoten \(v\) die Anzahl erreichbarer Knoten.
Idee: Berechne mit DFS die Zusammenhangskomponenten; die Antwort für \(v\) ist dann die Grösse der Komponente von \(v\).
Laufzeit: \(O(n + m)\).
Konkret markiert
ConnectedComponents jede Komponente mit einer eigenen Zahl, danach zählt man die Komponentengrössen \(\mathrm{cnt}[c]\) und setzt \(\mathrm{res}[v] = \mathrm{cnt}[\mathrm{comp}[v]]\).
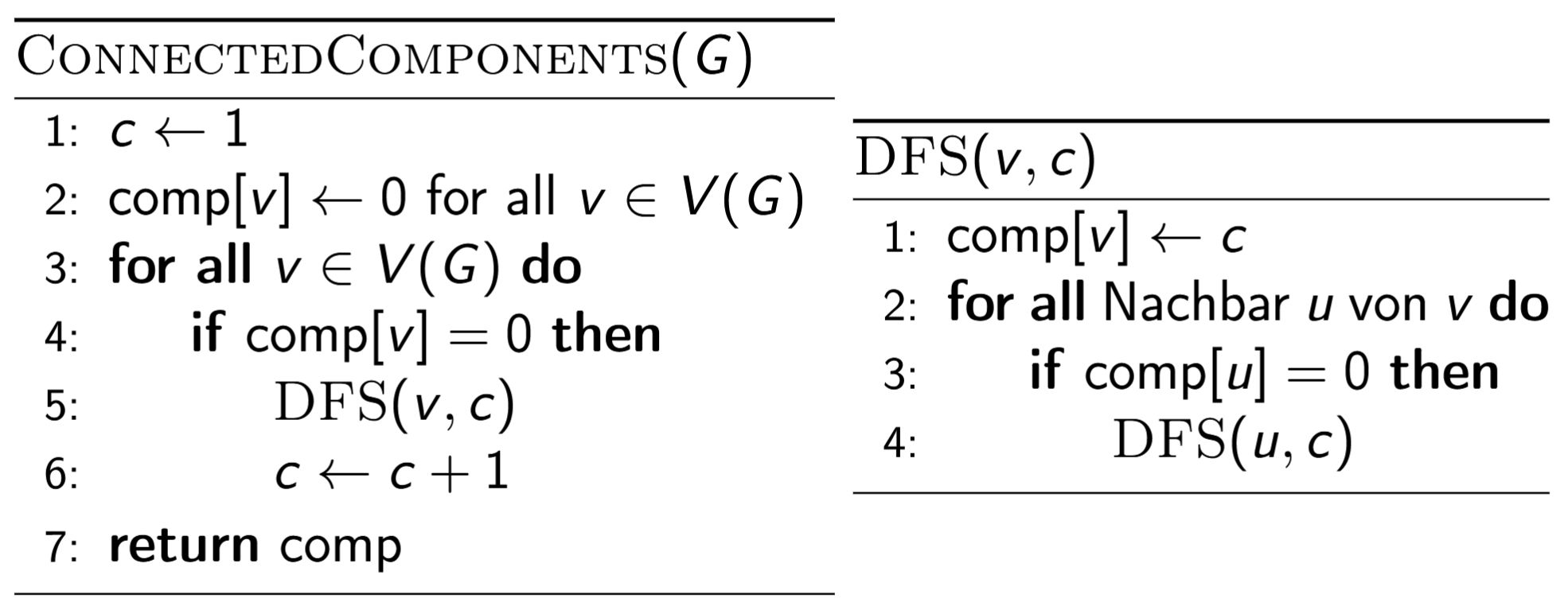
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Zählen erreichbarer Knoten (ungerichtet)</b><br>Gegeben ein ungerichteter Graph \(G\), bestimme für jeden Knoten \(v\) die Anzahl erreichbarer Knoten.<br><br>Idee: Berechne mit DFS die {{c1::Zusammenhangskomponenten}}; die Antwort für \(v\) ist dann die {{c2::Grösse der Komponente von \(v\)}}.<br>Laufzeit: \({{c3::O(n + m)}}\). |
<b>Zählen erreichbarer Knoten (ungerichtet)</b><br>Gegeben ein ungerichteter Graph \(G\), bestimme für jeden Knoten \(v\) die Anzahl erreichbarer Knoten.<br><br>Idee: Berechne mit DFS die {{c1::Zusammenhangskomponenten}}; die Antwort für \(v\) ist dann die {{c1::Grösse der Komponente von \(v\)}}.<br>Laufzeit: \({{c2::O(n + m)}}\). |
| Extra |
Konkret markiert <code>ConnectedComponents</code> jede Komponente mit einer eigenen Zahl, danach zählt man die Komponentengrössen \(\mathrm{cnt}[c]\) und setzt \(\mathrm{res}[v] = \mathrm{cnt}[\mathrm{comp}[v]]\). |
Konkret markiert <code>ConnectedComponents</code> jede Komponente mit einer eigenen Zahl, danach zählt man die Komponentengrössen \(\mathrm{cnt}[c]\) und setzt \(\mathrm{res}[v] = \mathrm{cnt}[\mathrm{comp}[v]]\).<br><br><img src="paste-31d1907a74de856810545bc6d468a2a5d3f2392f.jpg"> |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::6._Zählen_erreichbarer_Knoten
Note 56: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: xWezPYdiRx
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(f\) ein maximaler Fluss in einem Netzwerk \(N = (V, A, c, s, t)\) ohne entgegen gerichtete Kanten. Dann gibt es keine zwei Knoten \(u, v \in V\), sodass sowohl die Kante \((u, v)\) als auch die Kante \((v, u)\) im Restnetzwerk \(N_f\) vorkommt.
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(f\) ein maximaler Fluss in einem Netzwerk \(N = (V, A, c, s, t)\) ohne entgegen gerichtete Kanten. Dann gibt es keine zwei Knoten \(u, v \in V\), sodass sowohl die Kante \((u, v)\) als auch die Kante \((v, u)\) im Restnetzwerk \(N_f\) vorkommt.
Falsch.
Wird eine Kante \((u, v) \in A\) teilweise genutzt, also \(0 < f(u, v) < c(u, v)\), so enthält \(N_f\) sowohl die Vorwärtskante \((u, v)\) (Restkapazität \(c - f\)) als auch die Rückwärtskante \((v, u)\) (Restkapazität \(f\)). Das kann auch bei maximalem Fluss auftreten.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(f\) ein maximaler Fluss in einem Netzwerk \(N = (V, A, c, s, t)\) ohne entgegen gerichtete Kanten. Dann gibt es keine zwei Knoten \(u, v \in V\), sodass sowohl die Kante \((u, v)\) als auch die Kante \((v, u)\) im Restnetzwerk \(N_f\) vorkommt. |
| Back |
|
Falsch.<br><br>Wird eine Kante \((u, v) \in A\) teilweise genutzt, also \(0 < f(u, v) < c(u, v)\), so enthält \(N_f\) sowohl die Vorwärtskante \((u, v)\) (Restkapazität \(c - f\)) als auch die Rückwärtskante \((v, u)\) (Restkapazität \(f\)). Das kann auch bei maximalem Fluss auftreten. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken
ETH::2._Semester::A&W::Minitests::6
Note 57: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: y[xH&!tXvz
modified
Before
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Ein Hamiltonkreis in einem Graphen besucht jeden Knoten genau einmal.
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Ein Hamiltonkreis in einem Graphen besucht jeden Knoten genau einmal.
Wahr.
After
Front
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Ein Hamiltonkreis in einem Graphen besucht jeden Knoten genau einmal.
Back
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise ETH::2._Semester::A&W::Minitests::1
Wahr oder falsch?
Ein Hamiltonkreis in einem Graphen besucht jeden Knoten genau einmal.
Wahr.
Das ist gerade die Definition eines Hamiltonkreises: ein Kreis, der jeden Knoten des Graphen genau einmal enthält.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
Wahr. |
Wahr.<br><br>Das ist gerade die Definition eines Hamiltonkreises: ein Kreis, der jeden Knoten des Graphen genau einmal enthält. |
Tags:
ETH::2._Semester::A&W::1._Graphentheorie::5._Kreise::2._Hamiltonkreise
ETH::2._Semester::A&W::Minitests::1
Note 58: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: z0V~V#8D*w
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Sind \(X_1, X_2, \ldots, X_n\) Zufallsvariablen, sodass \(\text{Var}[X_i] = 1\) für alle \(i\), dann ist \(\text{Var}[X_1 + \ldots + X_n] = n\).
Back
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz ETH::2._Semester::A&W::Minitests::4
Wahr oder falsch?
Sind \(X_1, X_2, \ldots, X_n\) Zufallsvariablen, sodass \(\text{Var}[X_i] = 1\) für alle \(i\), dann ist \(\text{Var}[X_1 + \ldots + X_n] = n\).
Falsch.
Das gilt nur, wenn die \(X_i\) (paarweise) unkorreliert sind. Ohne diese Annahme tragen die Kovarianzterme bei: Für \(X_1 = \ldots = X_n = X\) mit \(\text{Var}[X] = 1\) ist etwa \(\text{Var}[nX] = n^2\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sind \(X_1, X_2, \ldots, X_n\) Zufallsvariablen, sodass \(\text{Var}[X_i] = 1\) für alle \(i\), dann ist \(\text{Var}[X_1 + \ldots + X_n] = n\). |
| Back |
|
Falsch.<br><br>Das gilt nur, wenn die \(X_i\) (paarweise) unkorreliert sind. Ohne diese Annahme tragen die Kovarianzterme bei: Für \(X_1 = \ldots = X_n = X\) mit \(\text{Var}[X] = 1\) ist etwa \(\text{Var}[nX] = n^2\). |
Tags:
ETH::2._Semester::A&W::2._Wahrscheinlichkeitstheorie_und_randomisierte_Algorithmen::4._Zufallsvariablen::2._Varianz
ETH::2._Semester::A&W::Minitests::4
Note 59: ETH::2. Semester::A&W
Deck: ETH::2. Semester::A&W
Note Type: Horvath Classic
GUID: zn-!xwhI3H
added
Previous
Note did not exist
New Note
Front
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss. Das Restnetzwerk \(N_f\) ist wie folgt gegeben:
Ist der Fluss \(f\) maximal?
Back
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken ETH::2._Semester::A&W::Minitests::6
Wahr oder falsch?
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss. Das Restnetzwerk \(N_f\) ist wie folgt gegeben:
Ist der Fluss \(f\) maximal?
Wahr.
Ein Fluss ist genau dann maximal, wenn das Restnetzwerk \(N_f\) keinen gerichteten Weg von \(s\) nach \(t\) enthält (also keinen augmentierenden Weg). Im gegebenen \(N_f\) existiert kein solcher \(s\)-\(t\)-Weg, also ist \(f\) maximal.
Field-by-field Comparison
| Field |
Before |
After |
| Front |
|
Wahr oder falsch?<br><br>Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss. Das Restnetzwerk \(N_f\) ist wie folgt gegeben:<br><br><img src="paste-1a4474459863b2afa09bd61bd434b5b98e5ba22d.jpg"><br><br>Ist der Fluss \(f\) maximal? |
| Back |
|
Wahr.<br><br>Ein Fluss ist genau dann maximal, wenn das Restnetzwerk \(N_f\) keinen gerichteten Weg von \(s\) nach \(t\) enthält (also keinen augmentierenden Weg). Im gegebenen \(N_f\) existiert kein solcher \(s\)-\(t\)-Weg, also ist \(f\) maximal. |
Tags:
ETH::2._Semester::A&W::3._Algorithmen_-_Highlights::1._Graphenalgorithmen::2._Flüsse_in_Netzwerken
ETH::2._Semester::A&W::Minitests::6
Note 60: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Classic
GUID: %1FyF+2eV}
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien ETH::2._Semester::Analysis::Serie::05
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent.
Was gilt für \(\sum_{k\geq1} a_k^2\)?
- konvergiert nicht notwendigerweise
- konvergiert immer, aber nicht notwendigerweise absolut
- konvergiert immer absolut
- keine der obigen Aussagen trifft zu
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien ETH::2._Semester::Analysis::Serie::05
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent.
Was gilt für \(\sum_{k\geq1} a_k^2\)?
- konvergiert nicht notwendigerweise
- konvergiert immer, aber nicht notwendigerweise absolut
- konvergiert immer absolut
- keine der obigen Aussagen trifft zu
(c) konvergiert immer absolut.
Da \(\sum a_k\) konvergiert, ist \((a_k)\) eine Nullfolge, also beschränkt: \(|a_k| \leq C\). Dann \(|a_k|^2 \leq C|a_k|\), und mit dem Vergleichssatz folgt aus der absoluten Konvergenz von \(\sum a_k\) die absolute Konvergenz von \(\sum a_k^2\).
After
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien ETH::2._Semester::Analysis::Serie::05
Sei \(\sum_{k\geq1} a_k\) absolut konvergent.
Was gilt für \(\sum_{k\geq1} a_k^2\)?
- konvergiert nicht notwendigerweise
- konvergiert immer, aber nicht notwendigerweise absolut
- konvergiert immer absolut
- keine der obigen Aussagen trifft zu
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien ETH::2._Semester::Analysis::Serie::05
Sei \(\sum_{k\geq1} a_k\) absolut konvergent.
Was gilt für \(\sum_{k\geq1} a_k^2\)?
- konvergiert nicht notwendigerweise
- konvergiert immer, aber nicht notwendigerweise absolut
- konvergiert immer absolut
- keine der obigen Aussagen trifft zu
(c) konvergiert immer absolut.
Da \(\sum a_k\) konvergiert, ist \((a_k)\) eine Nullfolge, also beschränkt: \(|a_k| \leq C\). Dann \(|a_k|^2 \leq C|a_k|\), und mit dem Vergleichssatz folgt aus der absoluten Konvergenz von \(\sum a_k\) die absolute Konvergenz von \(\sum a_k^2\).
Field-by-field Comparison
| Field |
Before |
After |
| Front |
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent. <br>Was gilt für \(\sum_{k\geq1} a_k^2\)?<ol type="a"><li>konvergiert nicht notwendigerweise</li><li>konvergiert immer, aber nicht notwendigerweise absolut</li><li>konvergiert immer absolut</li><li>keine der obigen Aussagen trifft zu</li></ol> |
Sei \(\sum_{k\geq1} a_k\) absolut konvergent. <br>Was gilt für \(\sum_{k\geq1} a_k^2\)?<ol type="a"><li>konvergiert nicht notwendigerweise</li><li>konvergiert immer, aber nicht notwendigerweise absolut</li><li>konvergiert immer absolut</li><li>keine der obigen Aussagen trifft zu</li></ol> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
ETH::2._Semester::Analysis::Serie::05
Note 61: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: F.4_b[[a[X
modified
Before
Front
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::3._Ansatz_partikuläre_Lösung
Ansatz für die partikuläre Lösung bei einer exponentiellen Störfunktion
Störfunktion \(s(t) = A e^{kt}\):
\[ y(t) = {{c1::C e^{kt} }} \]Spezialfall (Resonanz): Ist \(k\) eine \(m\)-fache Nullstelle des charakteristischen Polynoms, so lautet der Ansatz
\[ y(t) = {{c1::(C e^{kt})\, t^m}} \]
Back
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::3._Ansatz_partikuläre_Lösung
Ansatz für die partikuläre Lösung bei einer exponentiellen Störfunktion
Störfunktion \(s(t) = A e^{kt}\):
\[ y(t) = {{c1::C e^{kt} }} \]Spezialfall (Resonanz): Ist \(k\) eine \(m\)-fache Nullstelle des charakteristischen Polynoms, so lautet der Ansatz
\[ y(t) = {{c1::(C e^{kt})\, t^m}} \]
After
Front
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::3._Ansatz_partikuläre_Lösung
Ansatz für die partikuläre Lösung bei einer exponentiellen Störfunktion
Störfunktion \(s(t) = A e^{kt}\):
\[ y(t) = {{c1::C e^{kt} }} \]Spezialfall (Resonanz): Ist \(k\) eine \(m\)-fache Nullstelle des charakteristischen Polynoms, so lautet der Ansatz
\[ y(t) = {{c1::(C e^{kt})\, t^m}} \]
Back
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::3._Ansatz_partikuläre_Lösung
Ansatz für die partikuläre Lösung bei einer exponentiellen Störfunktion
Störfunktion \(s(t) = A e^{kt}\):
\[ y(t) = {{c1::C e^{kt} }} \]Spezialfall (Resonanz): Ist \(k\) eine \(m\)-fache Nullstelle des charakteristischen Polynoms, so lautet der Ansatz
\[ y(t) = {{c1::(C e^{kt})\, t^m}} \]
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Ansatz für die partikuläre Lösung</b> bei einer <b>exponentiellen</b> Störfunktion<br>Störfunktion \(s(t) = A e^{kt}\):<br>\[ y(t) = {{c1::C e^{kt} }} \]<b>Spezialfall</b> (Resonanz): Ist \(k\) eine \(m\)-fache Nullstelle des charakteristischen Polynoms, so lautet der Ansatz<br>\[ y(t) = {{c1::(C e^{kt})\, t^m}} \] |
<b>Ansatz für die partikuläre Lösung</b> bei einer <b>exponentiellen</b> Störfunktion<br>Störfunktion \(s(t) = {{c1::A e^{kt}}}\):<br>\[ y(t) = {{c1::C e^{kt} }} \]<b>Spezialfall</b> (Resonanz): Ist \(k\) eine \(m\)-fache Nullstelle des charakteristischen Polynoms, so lautet der Ansatz<br>\[ y(t) = {{c1::(C e^{kt})\, t^m}} \] |
Tags:
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::3._Ansatz_partikuläre_Lösung
Note 62: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: FVZ$*)>ic6
modified
Before
Front
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::2._Variation_der_Konstanten
Variation der Konstanten: Beispiel \(y' - y = x\)
Die homogene DGl \(y' - y = 0\) hat die allgemeine Lösung \(y_h(x) = K e^x\).
Der Ansatz für die partikuläre Lösung (Variation der Konstanten) lautet daher
\[ y_p(x) = K(x)\,e^x \]
Back
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::2._Variation_der_Konstanten
Variation der Konstanten: Beispiel \(y' - y = x\)
Die homogene DGl \(y' - y = 0\) hat die allgemeine Lösung \(y_h(x) = K e^x\).
Der Ansatz für die partikuläre Lösung (Variation der Konstanten) lautet daher
\[ y_p(x) = K(x)\,e^x \]
Die Konstante \(K\) wird durch die Funktion \(K(x)\) ersetzt.
After
Front
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::2._Variation_der_Konstanten
Variation der Konstanten: Beispiel \(y' - y = x\)
Die homogene DGl \(y' - y = 0\) hat die allgemeine Lösung \(y_h(x) = K e^x\).
Der Ansatz für die partikuläre Lösung (Variation der Konstanten) lautet daher
\[ y_p(x) = K(x)\,e^x \]
Back
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::2._Variation_der_Konstanten
Variation der Konstanten: Beispiel \(y' - y = x\)
Die homogene DGl \(y' - y = 0\) hat die allgemeine Lösung \(y_h(x) = K e^x\).
Der Ansatz für die partikuläre Lösung (Variation der Konstanten) lautet daher
\[ y_p(x) = K(x)\,e^x \]
Die Konstante \(K\) wird durch die Funktion \(K(x)\) ersetzt.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
<b>Variation der Konstanten: Beispiel</b> \(y' - y = x\)<br>Die homogene DGl \(y' - y = 0\) hat die allgemeine Lösung \(y_h(x) = {{c1::K e^x}}\).<br>Der Ansatz für die partikuläre Lösung (Variation der Konstanten) lautet daher<br>\[ y_p(x) = {{c1::K(x)\,e^x}} \] |
<b>Variation der Konstanten: Beispiel</b> \(y' - y = x\)<br>Die homogene DGl \(y' - y = 0\) hat die allgemeine Lösung \(y_h(x) = K e^x\).<br>Der Ansatz für die partikuläre Lösung (Variation der Konstanten) lautet daher<br>\[ y_p(x) = {{c1::K(x)\,e^x}} \] |
Tags:
ETH::2._Semester::Analysis::6._Differentialgleichungen::4._Lineare_inhomogene::2._Variation_der_Konstanten
Note 63: ETH::2. Semester::Analysis
Deck: ETH::2. Semester::Analysis
Note Type: Horvath Cloze
GUID: KYS^r9uI5z
modified
Before
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Leibniz-Kriterium (alternierende Reihen)
Sei \((a_n)\) monoton fallend, \(a_n \geq 0\), \(\lim a_n = 0\).
Dann konvergiert \({{c1:: \displaystyle\sum_{n=0}^\infty (-1)^n a_n }}\).
Proof Sketch included
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Leibniz-Kriterium (alternierende Reihen)
Sei \((a_n)\) monoton fallend, \(a_n \geq 0\), \(\lim a_n = 0\).
Dann konvergiert \({{c1:: \displaystyle\sum_{n=0}^\infty (-1)^n a_n }}\).
Proof Sketch included
Beachte: Liefert i.A. nur
bedingte Konvergenz, nicht absolute.
Proof Sketch:
- Die Folge der geraden Partialsummen \(S_{2n}\) ist monoton wachsend und beschränkt, konvergiert also gegen \(L_1\)
- Die Folge der ungeraden Partialsummen \(S_{2n + 1}\) ist monoton fallend und beschränkt, konvergiert also gegen \(L_2\)
- Da aber gilt \(S_{2n - 1} - S_{2n} = a_{2n} \rightarrow_\infty = 0 \text{gilt} L_1 - L_2 = 0\) und so konvergieren beide gegen den selben Grenzwert.
After
Front
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Leibniz-Kriterium (alternierende Reihen)
Sei \((a_n)\) monoton fallend, \(a_n \geq 0\), \(\lim a_n = 0\).
Dann konvergiert \(\displaystyle\sum_{n=0}^\infty (-1)^n a_n\).
Proof Sketch Included
Back
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Leibniz-Kriterium (alternierende Reihen)
Sei \((a_n)\) monoton fallend, \(a_n \geq 0\), \(\lim a_n = 0\).
Dann konvergiert \(\displaystyle\sum_{n=0}^\infty (-1)^n a_n\).
Proof Sketch Included
Beachte: Liefert i.A. nur
bedingte Konvergenz, nicht absolute.
Proof Sketch:
- Die Folge der geraden Partialsummen \(S_{2n}\) ist monoton wachsend und beschränkt, konvergiert also gegen \(L_1\)
- Die Folge der ungeraden Partialsummen \(S_{2n + 1}\) ist monoton fallend und beschränkt, konvergiert also gegen \(L_2\)
- Da aber gilt \(S_{2n - 1} - S_{2n} = a_{2n} \rightarrow_\infty = 0 \text{gilt} L_1 - L_2 = 0\) und so konvergieren beide gegen den selben Grenzwert.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Leibniz-Kriterium (alternierende Reihen)<br><br>Sei \((a_n)\) {{c2::<b>monoton fallend</b>, \(a_n \geq 0\), \(\lim a_n = 0\)}}.<br>Dann konvergiert \({{c1:: \displaystyle\sum_{n=0}^\infty (-1)^n a_n }}\).<br><br><i>Proof Sketch included</i> |
Leibniz-Kriterium (alternierende Reihen)<br><br>Sei \((a_n)\) {{c2::<b>monoton fallend</b>, \(a_n \geq 0\), \(\lim a_n = 0\)}}.<br>Dann {{c1::konvergiert }}\(\displaystyle\sum_{n=0}^\infty (-1)^n a_n\).<br><br><i>Proof Sketch Included</i> |
Tags:
ETH::2._Semester::Analysis::3._Reihen::3._Konvergenzkriterien
Note 64: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Cloze
GUID: %wz-=O@TB?
modified
Before
Front
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
ALU status flags: Z (result is zero), C (carry-out of the MSB), V (signed overflow), and N (negative/sign = MSB of the result).
Back
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
ALU status flags: Z (result is zero), C (carry-out of the MSB), V (signed overflow), and N (negative/sign = MSB of the result).
After
Front
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
ALU status flags:
- Z (result is zero),
- C (carry-out of the MSB),
- V (signed overflow), and
- N (negative/sign = MSB of the result).
Back
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
ALU status flags:
- Z (result is zero),
- C (carry-out of the MSB),
- V (signed overflow), and
- N (negative/sign = MSB of the result).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
ALU status flags: {{c1::Z}} (result is zero), {{c2::C}} (carry-out of the MSB), {{c3::V}} (signed overflow), and {{c4::N}} (negative/sign = MSB of the result). |
ALU status flags: <br><ol><li>Z {{c1::(result is zero)}}, </li><li>C {{c2::(carry-out of the MSB)}}, </li><li>V {{c3::(signed overflow)}}, and </li><li>N {{c4::(negative/sign = MSB of the result)}}.</li></ol> |
Tags:
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
Note 65: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Classic
GUID: EgONhKT=f-
modified
Before
Front
ETH::2._Semester::DDCA::04._Digital_Logic::3._Combinational_Design
List the four steps of the combinational design process.
Back
ETH::2._Semester::DDCA::04._Digital_Logic::3._Combinational_Design
List the four steps of the combinational design process.
1) Functional specification (text, truth table, or equations). 2) Derive Boolean expressions. 3) Simplify (algebra or K-map). 4) Implement and map to gates.
After
Front
ETH::2._Semester::DDCA::04._Digital_Logic::3._Combinational_Design
List the four steps of the combinational design process.
Back
ETH::2._Semester::DDCA::04._Digital_Logic::3._Combinational_Design
List the four steps of the combinational design process.
- Functional specification (text, truth table, or equations).
- Derive Boolean expressions.
- Simplify (algebra or K-map).
- Implement and map to gates.
Field-by-field Comparison
| Field |
Before |
After |
| Back |
1) Functional specification (text, truth table, or equations). 2) Derive Boolean expressions. 3) Simplify (algebra or K-map). 4) Implement and map to gates. |
<ol><li>Functional specification (text, truth table, or equations). </li><li>Derive Boolean expressions. </li><li>Simplify (algebra or K-map). </li><li>Implement and map to gates.</li></ol> |
Tags:
ETH::2._Semester::DDCA::04._Digital_Logic::3._Combinational_Design
Note 66: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Cloze
GUID: FkJ,}T}Kml
modified
Before
Front
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Minterm and maxterm of the same index are complementary: {{c1::\(\overline{m_i} = M_i\)}}.
Back
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Minterm and maxterm of the same index are complementary: {{c1::\(\overline{m_i} = M_i\)}}.
After
Front
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Minterm and maxterm of the same index are {{c1::complementary: \[\overline{m_i} = M_i\]}}
Back
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Minterm and maxterm of the same index are {{c1::complementary: \[\overline{m_i} = M_i\]}}
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Minterm and maxterm of the same index are complementary: {{c1::\(\overline{m_i} = M_i\)}}. |
Minterm and maxterm of the same index are {{c1::complementary: \[\overline{m_i} = M_i\]}} |
Tags:
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Note 67: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Cloze
GUID: mKYqB$]gl6
modified
Before
Front
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
Full adder sum \(S = A \oplus B \oplus C_{in}\) (1 for an odd number of 1s); carry-out \(C_{out} = AB + AC_{in} + BC_{in}\) (1 when two or more inputs are 1, i.e. majority).
Back
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
Full adder sum \(S = A \oplus B \oplus C_{in}\) (1 for an odd number of 1s); carry-out \(C_{out} = AB + AC_{in} + BC_{in}\) (1 when two or more inputs are 1, i.e. majority).
After
Front
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
Full adder sum \(S = A \oplus B \oplus C_{in}\) (1 for an odd number of 1s); carry-out \(C_{out} = AB + AC_{in} + BC_{in}\) (1 when two or more inputs are 1, i.e. majority).
Back
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
Full adder sum \(S = A \oplus B \oplus C_{in}\) (1 for an odd number of 1s); carry-out \(C_{out} = AB + AC_{in} + BC_{in}\) (1 when two or more inputs are 1, i.e. majority).
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Full adder sum \(S = A \oplus B \oplus C_{in}\) (1 for an {{c1::odd}} number of 1s); carry-out \(C_{out} = AB + AC_{in} + BC_{in}\) (1 when {{c2::two or more}} inputs are 1, i.e. majority). |
Full adder sum \(S = A \oplus B \oplus C_{in}\) (1 for an {{c1::odd}} number of 1s); carry-out \(C_{out} = AB + AC_{in} + BC_{in}\) (1 when {{c2::two or more}} inputs are 1, i.e. {{c2::majority}}). |
| Extra |
|
<img alt="" src="Pasted-image-20250214104009.png"> |
Tags:
ETH::2._Semester::DDCA::04._Digital_Logic::4._Combinational_Components
Note 68: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Cloze
GUID: pcG^^H1T)5
modified
Before
Front
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Canonical SOP = OR of all minterms where F = 1; canonical POS = AND of all maxterms where F = 0.
Back
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Canonical SOP = OR of all minterms where F = 1; canonical POS = AND of all maxterms where F = 0.
After
Front
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Canonical SOP = OR of all minterms where F = 1;
canonical POS = AND of all maxterms where F = 0.
Back
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Canonical SOP = OR of all minterms where F = 1;
canonical POS = AND of all maxterms where F = 0.
Field-by-field Comparison
| Field |
Before |
After |
| Text |
Canonical SOP = OR of all {{c1::minterms}} where F = 1; canonical POS = AND of all {{c2::maxterms}} where F = 0. |
Canonical SOP = OR of all {{c1::minterms}} where F = 1; <br>canonical POS = AND of all {{c1::maxterms}} where F = 0. |
| Extra |
|
<img alt="" src="Pasted-image-20250213103809.png"><br><img alt="" src="Pasted-image-20250213104724.png"> |
Tags:
ETH::2._Semester::DDCA::04._Digital_Logic::2._Canonical_Forms
Note 69: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Cloze
GUID: b}(FC;F#gT
deleted
Current
Note has been deleted
Field-by-field Comparison
| Field |
Before |
After |
| Text |
This is a {{c1::test}} card. |
|
Tags:
ETH::2._Semester::DDCA
Note 70: ETH::2. Semester::DDCA
Deck: ETH::2. Semester::DDCA
Note Type: Horvath Classic
GUID: gP:bKN8YdD
deleted
Deleted Note
Back
ETH::2._Semester::DDCA
What is this card?
A test card.
Current
Note has been deleted
Field-by-field Comparison
| Field |
Before |
After |
| Front |
What is this card? |
|
| Back |
A test card. |
|
Tags:
ETH::2._Semester::DDCA