Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss in \(N\). Das Restnetzwerk \(N_f := (V, A_f, r_f, s, t)\) ist definiert durch:
Ist \(e \in A\) mit \(f(e) < c(e)\), dann ist \(e\) eine Kante in \(A_f\) mit \(r_f(e) := c(e) - f(e)\).
Ist \(e \in A\) mit \(f(e) > 0\), dann ist \(e^{\mathrm{opp}}\) in \(A_f\) mit \(r_f(e^{\mathrm{opp}}) := f(e)\).
\(A_f\) enthält nur Kanten wie in (1) und (2).
Den Wert \(r_f(e)\) nennen wir die Restkapazität der Kante \(e\).
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss in \(N\). Das Restnetzwerk \(N_f := (V, A_f, r_f, s, t)\) ist definiert durch:
Ist \(e \in A\) mit \(f(e) < c(e)\), dann ist \(e\) eine Kante in \(A_f\) mit \(r_f(e) := c(e) - f(e)\).
Ist \(e \in A\) mit \(f(e) > 0\), dann ist \(e^{\mathrm{opp}}\) in \(A_f\) mit \(r_f(e^{\mathrm{opp}}) := f(e)\).
\(A_f\) enthält nur Kanten wie in (1) und (2).
Den Wert \(r_f(e)\) nennen wir die Restkapazität der Kante \(e\).
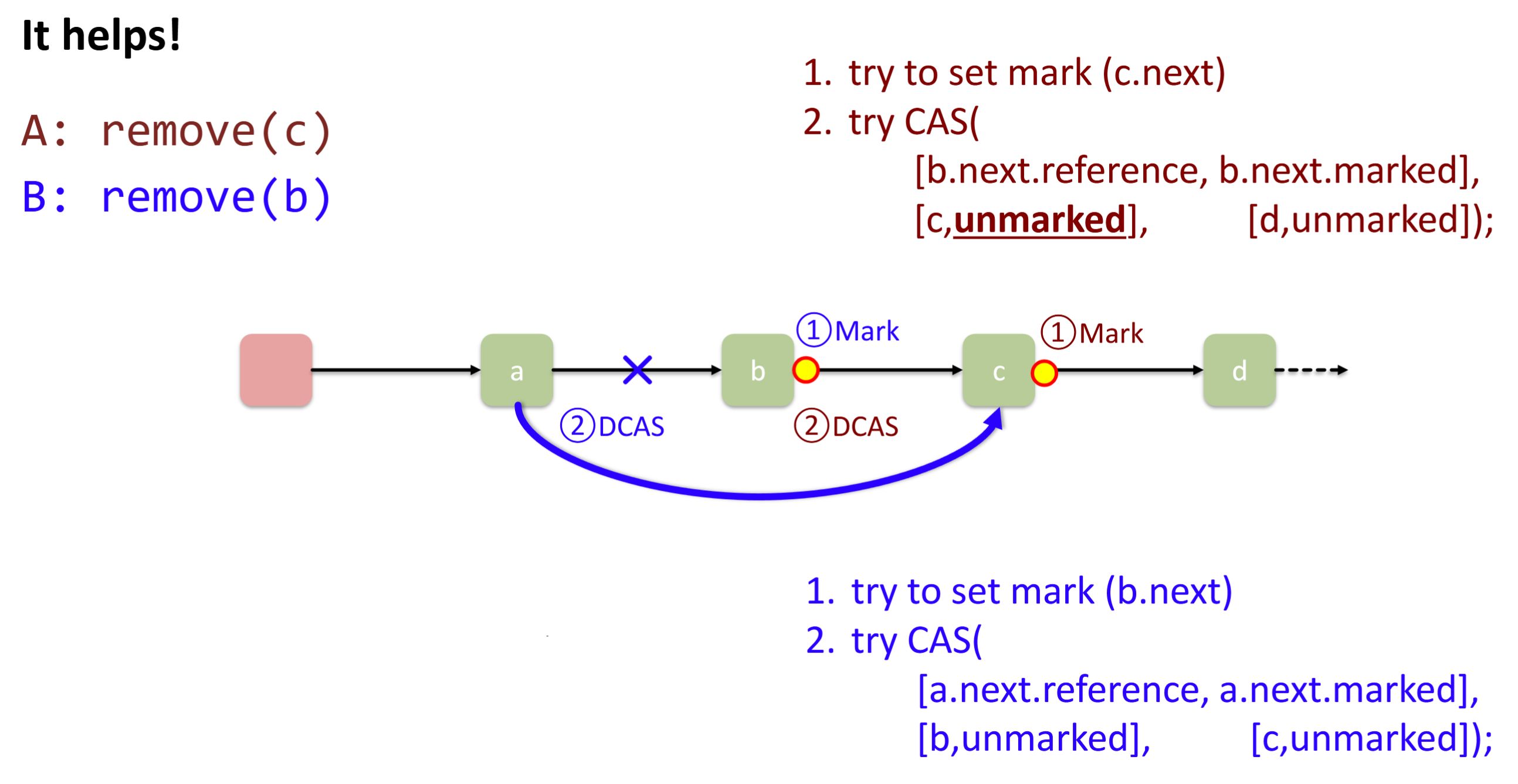
Die Annahme „ohne entgegen gerichtete Kanten“ ist nur eine Vereinfachung, nicht essentiell. Sie sorgt dafür, dass \(e\) und \(e^{\mathrm{opp}}\) eindeutig auseinanderzuhalten sind.
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss in \(N\). Das Restnetzwerk \(N_f := (V, A_f, r_f, s, t)\) ist definiert durch:
Ist \(e \in A\) mit \(f(e) < c(e)\), dann ist \(e\) eine Kante in \(A_f\) mit \(r_f(e) := c(e) - f(e)\).
Ist \(e \in A\) mit \(f(e) > 0\), dann ist \(e^{\mathrm{opp}}\) in \(A_f\) mit \(r_f(e^{\mathrm{opp}}) := f(e)\).
\(A_f\) enthält nur Kanten wie in (1) und (2).
Den Wert \(r_f(e)\) nennen wir die Restkapazität der Kante \(e\).
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss in \(N\). Das Restnetzwerk \(N_f := (V, A_f, r_f, s, t)\) ist definiert durch:
Ist \(e \in A\) mit \(f(e) < c(e)\), dann ist \(e\) eine Kante in \(A_f\) mit \(r_f(e) := c(e) - f(e)\).
Ist \(e \in A\) mit \(f(e) > 0\), dann ist \(e^{\mathrm{opp}}\) in \(A_f\) mit \(r_f(e^{\mathrm{opp}}) := f(e)\).
\(A_f\) enthält nur Kanten wie in (1) und (2).
Den Wert \(r_f(e)\) nennen wir die Restkapazität der Kante \(e\).
Die Annahme „ohne entgegen gerichtete Kanten“ ist nur eine Vereinfachung, nicht essentiell. Sie sorgt dafür, dass \(e\) und \(e^{\mathrm{opp}}\) eindeutig auseinanderzuhalten sind.
Field-by-field Comparison
Field
Before
After
Text
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss in \(N\). Das <b>Restnetzwerk</b> \(N_f := (V, A_f, r_f, s, t)\) ist definiert durch:<ol><li>Ist \(e \in A\) mit \({{c1::f(e) < c(e)}}\), dann ist \(e\) eine Kante in \(A_f\) mit \(r_f(e) := {{c2::c(e) - f(e)}}\).</li><li>Ist \(e \in A\) mit \({{c3::f(e) > 0}}\), dann ist \(e^{\mathrm{opp}}\) in \(A_f\) mit \(r_f(e^{\mathrm{opp}}) := {{c4::f(e)}}\).</li><li>\(A_f\) enthält {{c5::nur Kanten wie in (1) und (2)}}.</li></ol>Den Wert \(r_f(e)\) nennen wir die <b>Restkapazität</b> der Kante \(e\).
Sei \(N = (V, A, c, s, t)\) ein Netzwerk ohne entgegen gerichtete Kanten und \(f\) ein Fluss in \(N\). Das <b>Restnetzwerk</b> \(N_f := (V, A_f, r_f, s, t)\) ist definiert durch:<ol><li>Ist \(e \in A\) mit \({{c1::f(e) < c(e)}}\), dann ist \(e\) eine Kante in \(A_f\) mit \(r_f(e) := {{c1::c(e) - f(e)}}\).</li><li>Ist \(e \in A\) mit \({{c2::f(e) > 0}}\), dann ist \(e^{\mathrm{opp}}\) in \(A_f\) mit \(r_f(e^{\mathrm{opp}}) := {{c2::f(e)}}\).</li><li>\(A_f\) enthält {{c3::nur Kanten wie in (1) und (2)}}.</li></ol>Den Wert \(r_f(e)\) nennen wir die <b>Restkapazität</b> der Kante \(e\).
Beweis von „kein Pfad in \(N_f\) \(\Rightarrow\) \(\exists\) Schnitt \((S, T)\) mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\)“. Definiere\[\begin{gathered}S := {{c1::\{v \in V : v \text{ ist von } s \text{ in } N_f \text{ erreichbar}\}}}, \\T := V \setminus S.\end{gathered}\]Da kein s-t-Pfad in \(N_f\) existiert, gilt \(t \in T\), also ist \((S, T)\) ein s-t-Schnitt. Für jede Kante \((u, w) \in S \times T\) im Originalnetzwerk gilt \(f(u, w) = c(u, w)\) (sonst wäre \(w\) erreichbar), und für \((w, u) \in T \times S\) gilt \(f(w, u) = 0\) (sonst gäbe es \((u, w)^{\mathrm{opp}}\) im Restnetzwerk). Damit \(\operatorname{val}(f) = f(S, T) - f(T, S) = \operatorname{cap}(S, T) - 0\).
Beweis von „kein Pfad in \(N_f\) \(\Rightarrow\) \(\exists\) Schnitt \((S, T)\) mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\)“. Definiere\[\begin{gathered}S := {{c1::\{v \in V : v \text{ ist von } s \text{ in } N_f \text{ erreichbar}\}}}, \\T := V \setminus S.\end{gathered}\]Da kein s-t-Pfad in \(N_f\) existiert, gilt \(t \in T\), also ist \((S, T)\) ein s-t-Schnitt. Für jede Kante \((u, w) \in S \times T\) im Originalnetzwerk gilt \(f(u, w) = c(u, w)\) (sonst wäre \(w\) erreichbar), und für \((w, u) \in T \times S\) gilt \(f(w, u) = 0\) (sonst gäbe es \((u, w)^{\mathrm{opp}}\) im Restnetzwerk). Damit \(\operatorname{val}(f) = f(S, T) - f(T, S) = \operatorname{cap}(S, T) - 0\).
Die zwei Bedingungen geben gleichzeitig die untere und die obere Schranke aus dem schwachen Dualitätslemma scharf: alle vorwärtsführenden Kanten sind saturiert, alle rückwärtsführenden Kanten tragen keinen Fluss.
Beweis von „kein Pfad in \(N_f\) \(\Rightarrow\) \(\exists\) Schnitt \((S, T)\) mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\)“. Definiere\[\begin{gathered}S := {{c1::\{v \in V : v \text{ ist von } s \text{ in } N_f \text{ erreichbar}\} }}, \\ T := V \setminus S.\end{gathered}\]Da kein s-t-Pfad in \(N_f\) existiert, gilt \(t \in T\), also ist \((S, T)\) ein s-t-Schnitt.
Für jede Kante \((u, w) \in S \times T\) im Originalnetzwerk gilt \(f(u, w) = c(u, w)\) (sonst wäre \(w\) erreichbar), und für \((w, u) \in T \times S\) gilt {{c3::\(f(w, u) = 0\) (sonst gäbe es \((u, w)^{\mathrm{opp} }\)}} im Restnetzwerk).
Beweis von „kein Pfad in \(N_f\) \(\Rightarrow\) \(\exists\) Schnitt \((S, T)\) mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\)“. Definiere\[\begin{gathered}S := {{c1::\{v \in V : v \text{ ist von } s \text{ in } N_f \text{ erreichbar}\} }}, \\ T := V \setminus S.\end{gathered}\]Da kein s-t-Pfad in \(N_f\) existiert, gilt \(t \in T\), also ist \((S, T)\) ein s-t-Schnitt.
Für jede Kante \((u, w) \in S \times T\) im Originalnetzwerk gilt \(f(u, w) = c(u, w)\) (sonst wäre \(w\) erreichbar), und für \((w, u) \in T \times S\) gilt {{c3::\(f(w, u) = 0\) (sonst gäbe es \((u, w)^{\mathrm{opp} }\)}} im Restnetzwerk).
Die zwei Bedingungen geben gleichzeitig die untere und die obere Schranke aus dem schwachen Dualitätslemma scharf: alle vorwärtsführenden Kanten sind saturiert, alle rückwärtsführenden Kanten tragen keinen Fluss.
Field-by-field Comparison
Field
Before
After
Text
<b>Beweis von „kein Pfad in \(N_f\) \(\Rightarrow\) \(\exists\) Schnitt \((S, T)\) mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\)“.</b> Definiere\[\begin{gathered}S := {{c1::\{v \in V : v \text{ ist von } s \text{ in } N_f \text{ erreichbar}\}}}, \\T := V \setminus S.\end{gathered}\]Da kein s-t-Pfad in \(N_f\) existiert, gilt {{c2::\(t \in T\)}}, also ist \((S, T)\) ein s-t-Schnitt. Für jede Kante \((u, w) \in S \times T\) im Originalnetzwerk gilt {{c3::\(f(u, w) = c(u, w)\)}} (sonst wäre \(w\) erreichbar), und für \((w, u) \in T \times S\) gilt {{c4::\(f(w, u) = 0\)}} (sonst gäbe es \((u, w)^{\mathrm{opp}}\) im Restnetzwerk). Damit \(\operatorname{val}(f) = f(S, T) - f(T, S) = \operatorname{cap}(S, T) - 0\).
<b>Beweis von „kein Pfad in \(N_f\) \(\Rightarrow\) \(\exists\) Schnitt \((S, T)\) mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\)“.</b> Definiere\[\begin{gathered}S := {{c1::\{v \in V : v \text{ ist von } s \text{ in } N_f \text{ erreichbar}\} }}, \\ T := V \setminus S.\end{gathered}\]Da kein s-t-Pfad in \(N_f\) existiert, gilt {{c2::\(t \in T\)}}, also ist \((S, T)\) ein s-t-Schnitt. <br><br>Für jede Kante \((u, w) \in S \times T\) im Originalnetzwerk gilt {{c3::\(f(u, w) = c(u, w)\) (sonst wäre \(w\) erreichbar)}}, und für \((w, u) \in T \times S\) gilt {{c3::\(f(w, u) = 0\) (sonst gäbe es \((u, w)^{\mathrm{opp} }\)}} im Restnetzwerk). <br><br>Damit \(\operatorname{val}(f) = f(S, T) - f(T, S) = \operatorname{cap}(S, T) - 0\).
Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0\), \(n := |V|\), \(m := |A|\), \(U := \max_{e \in A} c(e)\). Dann gilt\[\operatorname{val}(f) \;\leq\; \operatorname{cap}(\{s\}, V \setminus \{s\}) \;\leq\; (n - 1)\,U,\]und der Ford-Fulkerson-Algorithmus benötigt höchstens \((n - 1)\,U\) Augmentierungsschritte.
Der triviale Schnitt \((\{s\}, V \setminus \{s\})\) hat höchstens \(n - 1\) ausgehende Kanten, jede mit Kapazität \(\leq U\). Da jeder Augmentierungsschritt den Fluss um mindestens \(1\) erhöht, ist \((n - 1)\,U\) auch eine obere Schranke für die Anzahl der Schritte.
Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0\), \(n := |V|\), \(m := |A|\), \(U := \max_{e \in A} c(e)\). Dann gilt\[\operatorname{val}(f) \;\leq\; \operatorname{cap}(\{s\}, V \setminus \{s\}) \;\leq\; (n - 1)\,U,\]und der Ford-Fulkerson-Algorithmus benötigt höchstens \((n - 1)\,U\) Augmentierungsschritte.
Der triviale Schnitt \((\{s\}, V \setminus \{s\})\) hat höchstens \(n - 1\) ausgehende Kanten, jede mit Kapazität \(\leq U\). Da jeder Augmentierungsschritt den Fluss um mindestens \(1\) erhöht, ist \((n - 1)\,U\) auch eine obere Schranke für die Anzahl der Schritte.
Field-by-field Comparison
Field
Before
After
Text
Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0\), \(n := |V|\), \(m := |A|\), \(U := \max_{e \in A} c(e)\). Dann gilt\[\operatorname{val}(f) \;\leq\; \operatorname{cap}(\{s\}, V \setminus \{s\}) \;\leq\; {{c1::(n - 1)\,U}},\]und der Ford-Fulkerson-Algorithmus benötigt höchstens {{c2::\((n - 1)\,U\)}} Augmentierungsschritte.
Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0\), \(n := |V|\), \(m := |A|\), \(U := \max_{e \in A} c(e)\). Dann gilt\[\operatorname{val}(f) \;\leq\; \operatorname{cap}(\{s\}, V \setminus \{s\}) \;\leq\; {{c1::(n - 1)\,U}},\]und der Ford-Fulkerson-Algorithmus benötigt höchstens {{c1::\((n - 1)\,U\)}} Augmentierungsschritte.
Schreibe den modifizierten Algorithmus \(\textsc{Cut}_t(G)\), der die Kantenkontraktion bei \(t\) Knoten abbricht und dann einen randomisierten \(\mathcal{O}(t^4)\)-Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-1}\) verwendet. Gib die untere Schranke für \(\hat{p}_t(n)\) und die resultierende Laufzeit nach \(\alpha / p_t(n)\)-maliger Wiederholung an.
Schreibe den modifizierten Algorithmus \(\textsc{Cut}_t(G)\), der die Kantenkontraktion bei \(t\) Knoten abbricht und dann einen randomisierten \(\mathcal{O}(t^4)\)-Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-1}\) verwendet. Gib die untere Schranke für \(\hat{p}_t(n)\) und die resultierende Laufzeit nach \(\alpha / p_t(n)\)-maliger Wiederholung an.
Cut_t(G) // G zus.hängender Multigraph
1: G' := G
2: while |V(G')| > t do
3: e := gleichverteilt zufällige Kante in G'
4: G' := G' / e
5: return Resultat des O(t^4) Algorithmus auf G'
Untere Schranke für die Erfolgswkt. einer Einzelausführung:\[\hat{p}_t(n) \;\geq\; \tfrac{n-2}{n} \cdot \tfrac{n-3}{n-1} \cdots \tfrac{t}{t+2} \cdot \tfrac{t-1}{t+1} \cdot \hat{p}_t(t) \;\geq\; \tfrac{t(t-1)}{n(n-1)} \cdot \tfrac{e-1}{e}.\]Nach \(\alpha / p_t(n)\)-maligem Wiederholen: Fehlerwkt. \(\leq e^{-\alpha}\) und Laufzeit\[\mathcal{O}\!\left(\alpha\!\left(\tfrac{n^4}{t^2} + n^2 t^2\right)\right).\]Wahl \(t := \sqrt{n}\) balanciert beide Terme und liefert \(\mathcal{O}(\alpha n^3)\).
Field-by-field Comparison
Field
Before
After
Front
Schreibe den modifizierten Algorithmus \(\textsc{Cut}_t(G)\), der die Kantenkontraktion bei \(t\) Knoten abbricht und dann einen randomisierten \(\mathcal{O}(t^4)\)-Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-1}\) verwendet. Gib die untere Schranke für \(\hat{p}_t(n)\) und die resultierende Laufzeit nach \(\alpha / p_t(n)\)-maliger Wiederholung an.
Back
<pre>Cut_t(G) // G zus.hängender Multigraph
1: G' := G
2: while |V(G')| > t do
3: e := gleichverteilt zufällige Kante in G'
4: G' := G' / e
5: return Resultat des O(t^4) Algorithmus auf G'</pre>Untere Schranke für die Erfolgswkt. einer Einzelausführung:\[\hat{p}_t(n) \;\geq\; \tfrac{n-2}{n} \cdot \tfrac{n-3}{n-1} \cdots \tfrac{t}{t+2} \cdot \tfrac{t-1}{t+1} \cdot \hat{p}_t(t) \;\geq\; \tfrac{t(t-1)}{n(n-1)} \cdot \tfrac{e-1}{e}.\]Nach \(\alpha / p_t(n)\)-maligem Wiederholen: Fehlerwkt. \(\leq e^{-\alpha}\) und Laufzeit\[\mathcal{O}\!\left(\alpha\!\left(\tfrac{n^4}{t^2} + n^2 t^2\right)\right).\]Wahl \(t := \sqrt{n}\) balanciert beide Terme und liefert \(\mathcal{O}(\alpha n^3)\).
Satz (Ford-Fulkerson mit ganzzahligen Kapazitäten). Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0^{\leq U}\) (für \(U \in \mathbb{N}\)), ohne entgegen gerichtete Kanten. Dann:
Es gibt einen ganzzahligen maximalen Fluss.
Er kann in Zeit {{c2::\(\mathcal{O}(m\,n\,U)\)}} berechnet werden.
Satz (Ford-Fulkerson mit ganzzahligen Kapazitäten). Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0^{\leq U}\) (für \(U \in \mathbb{N}\)), ohne entgegen gerichtete Kanten. Dann:
Es gibt einen ganzzahligen maximalen Fluss.
Er kann in Zeit {{c2::\(\mathcal{O}(m\,n\,U)\)}} berechnet werden.
Begründung der Laufzeit: höchstens \((n-1)U = \mathcal{O}(nU)\) Augmentierungsschritte, jeder Schritt (Pfadsuche per BFS/DFS in \(N_f\), Augmentierung, Update) braucht \(\mathcal{O}(m)\) Zeit. Die Ganzzahligkeit folgt induktiv: Start mit \(f \equiv 0\), und jeder Schritt erhält die Ganzzahligkeit, da \(\varepsilon = \min_i \varepsilon_i\) ganzzahlig ist.
Ford-Fulkerson mit ganzzahligen Kapazitäten Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0^{\leq U}\) (für \(U \in \mathbb{N}\)), ohne entgegen gerichtete Kanten. Dann:
Es gibt einen ganzzahligen maximalen Fluss.
Er kann in Zeit {{c2::\(\mathcal{O}(m\,n\,U)\)}} berechnet werden.
Ford-Fulkerson mit ganzzahligen Kapazitäten Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0^{\leq U}\) (für \(U \in \mathbb{N}\)), ohne entgegen gerichtete Kanten. Dann:
Es gibt einen ganzzahligen maximalen Fluss.
Er kann in Zeit {{c2::\(\mathcal{O}(m\,n\,U)\)}} berechnet werden.
Begründung der Laufzeit: höchstens \((n-1)U = \mathcal{O}(nU)\) Augmentierungsschritte, jeder Schritt (Pfadsuche per BFS/DFS in \(N_f\), Augmentierung, Update) braucht \(\mathcal{O}(m)\) Zeit. Die Ganzzahligkeit folgt induktiv: Start mit \(f \equiv 0\), und jeder Schritt erhält die Ganzzahligkeit, da \(\varepsilon = \min_i \varepsilon_i\) ganzzahlig ist.
Field-by-field Comparison
Field
Before
After
Text
<b>Satz (Ford-Fulkerson mit ganzzahligen Kapazitäten).</b>Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0^{\leq U}\) (für \(U \in \mathbb{N}\)), ohne entgegen gerichtete Kanten. Dann:<ul><li>{{c1::Es gibt einen ganzzahligen maximalen Fluss}}.</li><li>Er kann in Zeit {{c2::\(\mathcal{O}(m\,n\,U)\)}} berechnet werden.</li></ul>
<b>Ford-Fulkerson mit ganzzahligen Kapazitäten</b> <br>Sei \(N = (V, A, c, s, t)\) ein Netzwerk mit \(c : A \to \mathbb{N}_0^{\leq U}\) (für \(U \in \mathbb{N}\)), ohne entgegen gerichtete Kanten. Dann:<ul><li>{{c1::Es gibt einen ganzzahligen maximalen Fluss}}.</li><li>Er kann in Zeit {{c2::\(\mathcal{O}(m\,n\,U)\)}} berechnet werden.</li></ul>
Schreibe den Karger-Stein-Algorithmus als rekursiven Pseudocode.
KargerStein(G) // G zus.hängender Multigraph
1: if |V(G)| <= 6 then
2: Löse Problem in konstanter Zeit
3: G' := G, t := ceil(|V(G)| / sqrt(2) + 1)
4: while |V(G')| > t do
5: e := gleichverteilt zufällige Kante in G'
6: G' := G' / e
7: C_1 := KargerStein(G')
8: C_2 := KargerStein(G') // zweiter, unabhängiger Rekursionsast
9: return die kleinere der beiden Mengen C_1, C_2
Die Wahl \(t \approx n/\sqrt{2}\) garantiert, dass die Erfolgswkt. eines einzelnen Asts (\(n \to t\) Knoten) konstant ist; durch zwei unabhängige rekursive Aufrufe wird die Misserfolgswkt. quadriert, was den Gesamtfehler beherrschbar hält. Resultierende Laufzeit: \(\mathcal{O}(n^2 \log n)\), Erfolgswkt. \(\Omega(1/\log n)\); nach \(\Theta(\log^2 n)\) Wiederholungen Fehlerwkt. \(\leq 1/n\).
Field-by-field Comparison
Field
Before
After
Front
Schreibe den <b>Karger-Stein</b>-Algorithmus als rekursiven Pseudocode.
Back
<pre>KargerStein(G) // G zus.hängender Multigraph
1: if |V(G)| <= 6 then
2: Löse Problem in konstanter Zeit
3: G' := G, t := ceil(|V(G)| / sqrt(2) + 1)
4: while |V(G')| > t do
5: e := gleichverteilt zufällige Kante in G'
6: G' := G' / e
7: C_1 := KargerStein(G')
8: C_2 := KargerStein(G') // zweiter, unabhängiger Rekursionsast
9: return die kleinere der beiden Mengen C_1, C_2</pre>Die Wahl \(t \approx n/\sqrt{2}\) garantiert, dass die Erfolgswkt. eines einzelnen Asts (\(n \to t\) Knoten) konstant ist; durch <b>zwei unabhängige rekursive Aufrufe</b> wird die Misserfolgswkt. quadriert, was den Gesamtfehler beherrschbar hält. Resultierende Laufzeit: \(\mathcal{O}(n^2 \log n)\), Erfolgswkt. \(\Omega(1/\log n)\); nach \(\Theta(\log^2 n)\) Wiederholungen Fehlerwkt. \(\leq 1/n\).
Sei \(G = (V, E)\) ein Multigraph und \(e \in E\). Dann gilt\[\mu(G/e) \;\geq\; \mu(G).\]Hat \(G\) einen minimalen Schnitt \(C\) mit \(e \notin C\), so gilt sogar\[\mu(G/e) \;=\; \mu(G).\]
Sei \(G = (V, E)\) ein Multigraph und \(e \in E\). Dann gilt\[\mu(G/e) \;\geq\; \mu(G).\]Hat \(G\) einen minimalen Schnitt \(C\) mit \(e \notin C\), so gilt sogar\[\mu(G/e) \;=\; \mu(G).\]
Anschaulich: \(\mu\) kann durch Kontraktion nie fallen (Kontraktion vernichtet nur Schnitte, die \(e\) enthalten, fügt aber keine neuen hinzu). \(\mu\) bleibt gleich, sobald es einen minimalen Schnitt gibt, der \(e\) nicht verwendet.
Field-by-field Comparison
Field
Before
After
Text
Sei \(G = (V, E)\) ein Multigraph und \(e \in E\). Dann gilt\[\mu(G/e) \;{{c1::\geq}}\; \mu(G).\]Hat \(G\) einen minimalen Schnitt \(C\) mit \(e \notin C\), so gilt sogar\[\mu(G/e) \;{{c1::=}}\; \mu(G).\]
Extra
Anschaulich: \(\mu\) kann durch Kontraktion <b>nie fallen</b> (Kontraktion vernichtet nur Schnitte, die \(e\) enthalten, fügt aber keine neuen hinzu). \(\mu\) bleibt <b>gleich</b>, sobald es einen minimalen Schnitt gibt, der \(e\) nicht verwendet.
Algorithmus \(\text{Bunt}(G, i)\) Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
BUNT(G, i):
for all v in V:
P_i(v) := empty set
for all x in N(v):
for all R in P_{i-1}(x) with γ(v) ∉ R:
P_i(v) := P_i(v) ∪ { R ∪ {γ(v)} }
Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\). Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
Algorithmus \(\text{Bunt}(G, i)\) Wie berechnet man \(P_i(v)\) für alle \(v \in V\), gegeben \(P_{i-1}(u)\) für alle \(u \in V\)?
Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\). Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
Field-by-field Comparison
Field
Before
After
Back
<pre>BUNT(G, i):
for all v in V:
P_i(v) := empty set
for all x in N(v):
for all R in P_{i-1}(x) with γ(v) ∉ R:
P_i(v) := P_i(v) ∪ { R ∪ {γ(v)} }</pre>Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\).<br>Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
<pre><img src="paste-884c147b586e5ed9dbb57bef7f774cec7cd49e28.jpg"><br></pre>Initialisierung: \(P_0(v) = \{\{\gamma(v)\}\}\) für alle \(v \in V\).<br>Antwort JA \(\Leftrightarrow\) nach \(k-1\) Iterationen ist \(P_{k-1}(v) \neq \emptyset\) für irgendein \(v\).
Fluss \(\to\) kantendisjunkte Pfade. Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):
Beginnend bei \(u\), laufe entlang gerichteter, ungebrauchter Kanten mit Fluss 1 bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.
Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\) Mal}}.
Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach Entfernen von Kreisen).
Fluss \(\to\) kantendisjunkte Pfade. Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):
Beginnend bei \(u\), laufe entlang gerichteter, ungebrauchter Kanten mit Fluss 1 bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.
Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\) Mal}}.
Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach Entfernen von Kreisen).
Kreise können entstehen, wenn der Fluss interne Zyklen mit Fluss 1 enthält; diese sind für die Pfade irrelevant und werden weggelassen.
Fluss \(\to\) kantendisjunkte Pfade. Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):
Beginnend bei \(u\), laufe entlang gerichteter, ungebrauchter Kanten mit Fluss 1 bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.
Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\)}} Mal.
Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach Entfernen von Kreisen).
Fluss \(\to\) kantendisjunkte Pfade. Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):
Beginnend bei \(u\), laufe entlang gerichteter, ungebrauchter Kanten mit Fluss 1 bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.
Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\)}} Mal.
Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach Entfernen von Kreisen).
Kreise können entstehen, wenn der Fluss interne Zyklen mit Fluss 1 enthält; diese sind für die Pfade irrelevant und werden weggelassen.
Field-by-field Comparison
Field
Before
After
Text
<b>Fluss \(\to\) kantendisjunkte Pfade.</b> Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):<ol><li>Beginnend bei \(u\), laufe entlang gerichteter, {{c1::ungebrauchter Kanten mit Fluss 1}} bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.</li><li>Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\) Mal}}.</li><li>Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach {{c3::Entfernen von Kreisen}}).</li></ol>
<b>Fluss \(\to\) kantendisjunkte Pfade.</b> <br>Gegeben ein ganzzahliger maximaler Fluss \(f\) in \(N_G^{*}\):<ol><li>Beginnend bei \(u\), laufe entlang gerichteter, {{c1::ungebrauchter Kanten mit Fluss 1}} bis man bei \(v\) ankommt; durchlaufene Kanten werden als gebraucht markiert.</li><li>Wiederhole das Verfahren {{c2::\(\operatorname{val}(f)\)}} Mal.</li><li>Das liefert \(\operatorname{val}(f)\) kantendisjunkte \(u\)-\(v\)-Pfade (nach {{c3::Entfernen von Kreisen}}).</li></ol>
Bootstrapping. Hat man bereits einen \(\mathcal{O}(n^c)\)-Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-1}\), so liefert die gleiche Konstruktion einen Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-\alpha}\) und Laufzeit\[{{c1::\mathcal{O}\!\left(\alpha\!\left(\tfrac{n^4}{t^2} + n^2 t^{c-2}\right)\right)}}.\]Optimale Wahl: \(t := n^{2/c}\), was Laufzeit \(\mathcal{O}(\alpha n^{4 - 4/c})\) gibt.
Nach \(k\)-maligem Einsetzen erhält man Laufzeit \({{c3::\mathcal{O}(n^{2 + 2/k})}}\); im Limit ein \(\mathcal{O}(n^2 \operatorname{polylog}(n))\)-Algorithmus [Karger-Stein '96].
Bootstrapping. Hat man bereits einen \(\mathcal{O}(n^c)\)-Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-1}\), so liefert die gleiche Konstruktion einen Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-\alpha}\) und Laufzeit\[{{c1::\mathcal{O}\!\left(\alpha\!\left(\tfrac{n^4}{t^2} + n^2 t^{c-2}\right)\right)}}.\]Optimale Wahl: \(t := n^{2/c}\), was Laufzeit \(\mathcal{O}(\alpha n^{4 - 4/c})\) gibt.
Nach \(k\)-maligem Einsetzen erhält man Laufzeit \({{c3::\mathcal{O}(n^{2 + 2/k})}}\); im Limit ein \(\mathcal{O}(n^2 \operatorname{polylog}(n))\)-Algorithmus [Karger-Stein '96].
Die Folge der Exponenten ist \(4 \to 3 \to 8/3 \approx 2.666 \to 5/2 = 2.5 \to 12/5 = 2.4 \to 7/3 \approx 2.333 \to \ldots\); sie konvergiert gegen \(2\). Den polylog-Faktor bringt erst die rekursive Verzweigung (siehe KargerStein-Pseudocode).
Field-by-field Comparison
Field
Before
After
Text
<b>Bootstrapping.</b> Hat man bereits einen \(\mathcal{O}(n^c)\)-Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-1}\), so liefert die gleiche Konstruktion einen Algorithmus mit Erfolgswkt. \(\geq 1 - e^{-\alpha}\) und Laufzeit\[{{c1::\mathcal{O}\!\left(\alpha\!\left(\tfrac{n^4}{t^2} + n^2 t^{c-2}\right)\right)}}.\]Optimale Wahl: \(t := {{c2::n^{2/c}}}\), was Laufzeit \(\mathcal{O}(\alpha n^{4 - 4/c})\) gibt. <br><br>Nach \(k\)-maligem Einsetzen erhält man Laufzeit \({{c3::\mathcal{O}(n^{2 + 2/k})}}\); im Limit ein \(\mathcal{O}(n^2 \operatorname{polylog}(n))\)-Algorithmus [Karger-Stein '96].
Extra
Die Folge der Exponenten ist \(4 \to 3 \to 8/3 \approx 2.666 \to 5/2 = 2.5 \to 12/5 = 2.4 \to 7/3 \approx 2.333 \to \ldots\); sie konvergiert gegen \(2\). Den polylog-Faktor bringt erst die rekursive Verzweigung (siehe KargerStein-Pseudocode).
\(\operatorname{indeg}_f(w)\) und \(\operatorname{outdeg}_f(w)\) bezeichnen die Ein- bzw. Ausgrade bezüglich der Kanten mit Fluss 1.
Field-by-field Comparison
Field
Before
After
Text
Sei \(f\) ein ganzzahliger maximaler Fluss in \(N_G^{*}\). Dann gilt:<ul><li>Flusswerte: {{c1::\(f(e) \in \{0, 1\}\)}} für alle Kanten \(e\).</li><li>Für jeden Knoten \(w \notin \{u, v\}\): {{c2::\(\operatorname{indeg}_f(w) = \operatorname{outdeg}_f(w)\)}} (Flusserhaltung in inneren Knoten).</li><li>\(\operatorname{val}(f) = {{c3::\operatorname{outdeg}_f(u) - \operatorname{indeg}_f(u) = \operatorname{indeg}_f(v) - \operatorname{outdeg}_f(v)}}\).</li></ul>
Sei \(f\) ein ganzzahliger maximaler Fluss in \(N_G^{*}\). Dann gilt:<ul><li>Flusswerte: {{c1::\(f(e) \in \{0, 1\}\)}} für alle Kanten \(e\).</li><li>Für jeden Knoten \(w \notin \{u, v\}\): {{c2::\(\operatorname{indeg}_f(w) = \operatorname{outdeg}_f(w)\) (Flusserhaltung in inneren Knoten)}}.</li><li>\(\operatorname{val}(f) = {{c3::\operatorname{outdeg}_f(u) - \operatorname{indeg}_f(u) = \operatorname{indeg}_f(v) - \operatorname{outdeg}_f(v)}}\).</li></ul>
Im \(\textsc{Cut}\)-Algorithmus sind die letzten Schritte am kritischsten: in der Produktdarstellung\[\hat{p}(n) \;\geq\; \tfrac{n-2}{n} \cdot \tfrac{n-3}{n-1} \cdots \tfrac{3}{5} \cdot \tfrac{2}{4} \cdot \tfrac{1}{3}\]sind die letzten Faktoren am kleinsten (z.B. \(\tfrac{1}{3} \approx 0.33\)).
Idee: bricht man die zufällige Kontraktion bei \(\(t\)\) Knoten ab und löst den Rest mit einem besseren (z.B. \(\mathcal{O}(t^4)\)) Algorithmus, kann man die Gesamtlaufzeit drücken.
Im \(\textsc{Cut}\)-Algorithmus sind die letzten Schritte am kritischsten: in der Produktdarstellung\[\hat{p}(n) \;\geq\; \tfrac{n-2}{n} \cdot \tfrac{n-3}{n-1} \cdots \tfrac{3}{5} \cdot \tfrac{2}{4} \cdot \tfrac{1}{3}\]sind die letzten Faktoren am kleinsten (z.B. \(\tfrac{1}{3} \approx 0.33\)).
Idee: bricht man die zufällige Kontraktion bei \(\(t\)\) Knoten ab und löst den Rest mit einem besseren (z.B. \(\mathcal{O}(t^4)\)) Algorithmus, kann man die Gesamtlaufzeit drücken.
Konkret: die ersten Schritte gelingen mit Wkt. nahe \(1\), die letzten nur mit Wkt. um \(1/3\). Strategisch lohnt es sich, die letzten Schritte „sorgfältiger“ zu machen, statt sich bis ganz nach unten auf das Glück zu verlassen.
Field-by-field Comparison
Field
Before
After
Text
Im \(\textsc{Cut}\)-Algorithmus sind die {{c1::letzten}} Schritte am kritischsten: in der Produktdarstellung\[\hat{p}(n) \;\geq\; \tfrac{n-2}{n} \cdot \tfrac{n-3}{n-1} \cdots \tfrac{3}{5} \cdot \tfrac{2}{4} \cdot \tfrac{1}{3}\]sind die {{c2::letzten Faktoren am kleinsten}} (z.B. \(\tfrac{1}{3} \approx 0.33\)). <br><br>Idee: bricht man die zufällige Kontraktion bei \({{c3::\(t\)}}\) Knoten ab und löst den Rest mit einem besseren (z.B. \(\mathcal{O}(t^4)\)) Algorithmus, kann man die Gesamtlaufzeit drücken.
Extra
Konkret: die ersten Schritte gelingen mit Wkt. nahe \(1\), die letzten nur mit Wkt. um \(1/3\). Strategisch lohnt es sich, die letzten Schritte „sorgfältiger“ zu machen, statt sich bis ganz nach unten auf das Glück zu verlassen.
MaxFlow-Problem Gegeben ein Netzwerk \(N = (V, A, c, s, t)\), finde einen Fluss \(f\) grössten Werts (einen maximalen Fluss).
Der Wert eines Flusses wird über den Nettoabfluss der Quelle gemessen.
Field-by-field Comparison
Field
Before
After
Text
<b>MaxFlow-Problem</b><br>Gegeben ein {{c1::Netzwerk \(N = (V, A, c, s, t)\)}}, finde einen {{c2::Fluss \(f\) grössten Werts (einen <i>maximalen</i> Fluss)}}.
<b>MaxFlow-Problem</b><br>Gegeben ein Netzwerk \(N = (V, A, c, s, t)\), finde einen {{c1::Fluss \(f\) grössten Werts (einen <i>maximalen</i> Fluss)}}.
Sei \(e = \{u, v\} \in E(G)\). Es gibt eine natürliche Bijektion\[\{ \text{Kanten von } G \text{ ohne die zw. } u \text{ und } v\} \;\longleftrightarrow\; E(G/e),\]definiert über \(\{w, w'\} \mapsto \{w, w'\}\), \(\{w, u\} \mapsto \{w, x_{u,v}\}\), \(\{w, v\} \mapsto \{w, x_{u,v}\}\).
Daraus folgt induziert die Bijektion\[{{c1::\{ \text{Schnitte in } G \text{ ohne } e\} \;\longleftrightarrow\; \{ \text{alle Schnitte in } G/e\} }}.\]
Sei \(e = \{u, v\} \in E(G)\). Es gibt eine natürliche Bijektion\[\{ \text{Kanten von } G \text{ ohne die zw. } u \text{ und } v\} \;\longleftrightarrow\; E(G/e),\]definiert über \(\{w, w'\} \mapsto \{w, w'\}\), \(\{w, u\} \mapsto \{w, x_{u,v}\}\), \(\{w, v\} \mapsto \{w, x_{u,v}\}\).
Daraus folgt induziert die Bijektion\[{{c1::\{ \text{Schnitte in } G \text{ ohne } e\} \;\longleftrightarrow\; \{ \text{alle Schnitte in } G/e\} }}.\]
Schnitte, die \(e\) enthalten, verschwinden bei Kontraktion (denn dann landen \(u\) und \(v\) gezwungenermassen auf derselben Seite \(x_{u,v}\), aber die ursprüngliche Partition trennte sie). Alle anderen Schnitte überleben unverändert.
Field-by-field Comparison
Field
Before
After
Text
Sei \(e = \{u, v\} \in E(G)\). Es gibt eine natürliche Bijektion\[\{ \text{Kanten von } G \text{ ohne die zw. } u \text{ und } v\} \;\longleftrightarrow\; E(G/e),\]definiert über \(\{w, w'\} \mapsto \{w, w'\}\), \(\{w, u\} \mapsto \{w, x_{u,v}\}\), \(\{w, v\} \mapsto \{w, x_{u,v}\}\). <br><br>Daraus folgt induziert die Bijektion\[{{c1::\{ \text{Schnitte in } G \text{ ohne } e\} \;\longleftrightarrow\; \{ \text{alle Schnitte in } G/e\} }}.\]
Extra
Schnitte, die \(e\) enthalten, verschwinden bei Kontraktion (denn dann landen \(u\) und \(v\) gezwungenermassen auf derselben Seite \(x_{u,v}\), aber die ursprüngliche Partition trennte sie). Alle anderen Schnitte überleben unverändert.
Jeder Graph ohne Dreieck hat eine chromatische Zahl von höchstens 100.
Falsch
Siehe Mycielski-Konstruktion.
Konstruktion: Aus \(G_k = (V_k, E_k)\) mit \(V_k = \{v_1,\ldots,v_n\}\) bilde \(G_{k+1}\): Füge Knoten \(w_1,\ldots,w_n, z\) hinzu. \(w_i\) ist mit allen Nachbarn von \(v_i\) verbunden (aber nicht mit \(v_i\) selbst). \(z\) ist mit allen \(w_i\) verbunden. Der neue Graph ist dreiecksfrei und braucht eine Farbe mehr als \(G_k\).
Jeder Graph ohne Dreieck hat eine chromatische Zahl von höchstens 100.
Falsch.
Siehe Mycielski-Konstruktion.
Konstruktion: Aus \(G_k = (V_k, E_k)\) mit \(V_k = \{v_1,\ldots,v_n\}\) bilde \(G_{k+1}\): Füge Knoten \(w_1,\ldots,w_n, z\) hinzu. \(w_i\) ist mit allen Nachbarn von \(v_i\) verbunden (aber nicht mit \(v_i\) selbst). \(z\) ist mit allen \(w_i\) verbunden. Der neue Graph ist dreiecksfrei und braucht eine Farbe mehr als \(G_k\).
Field-by-field Comparison
Field
Before
After
Back
Falsch<br><br>Siehe Mycielski-Konstruktion.<b><br><br>Konstruktion:</b><br>Aus \(G_k = (V_k, E_k)\) mit \(V_k = \{v_1,\ldots,v_n\}\) bilde \(G_{k+1}\):<br>Füge Knoten \(w_1,\ldots,w_n, z\) hinzu. \(w_i\) ist mit allen Nachbarn von \(v_i\) verbunden (aber nicht mit \(v_i\) selbst). \(z\) ist mit allen \(w_i\) verbunden.<br>Der neue Graph ist dreiecksfrei und braucht eine Farbe mehr als \(G_k\).
Falsch.<br><br>Siehe Mycielski-Konstruktion.<b><br><br>Konstruktion:</b><br>Aus \(G_k = (V_k, E_k)\) mit \(V_k = \{v_1,\ldots,v_n\}\) bilde \(G_{k+1}\):<br>Füge Knoten \(w_1,\ldots,w_n, z\) hinzu. \(w_i\) ist mit allen Nachbarn von \(v_i\) verbunden (aber nicht mit \(v_i\) selbst). \(z\) ist mit allen \(w_i\) verbunden.<br>Der neue Graph ist dreiecksfrei und braucht eine Farbe mehr als \(G_k\).
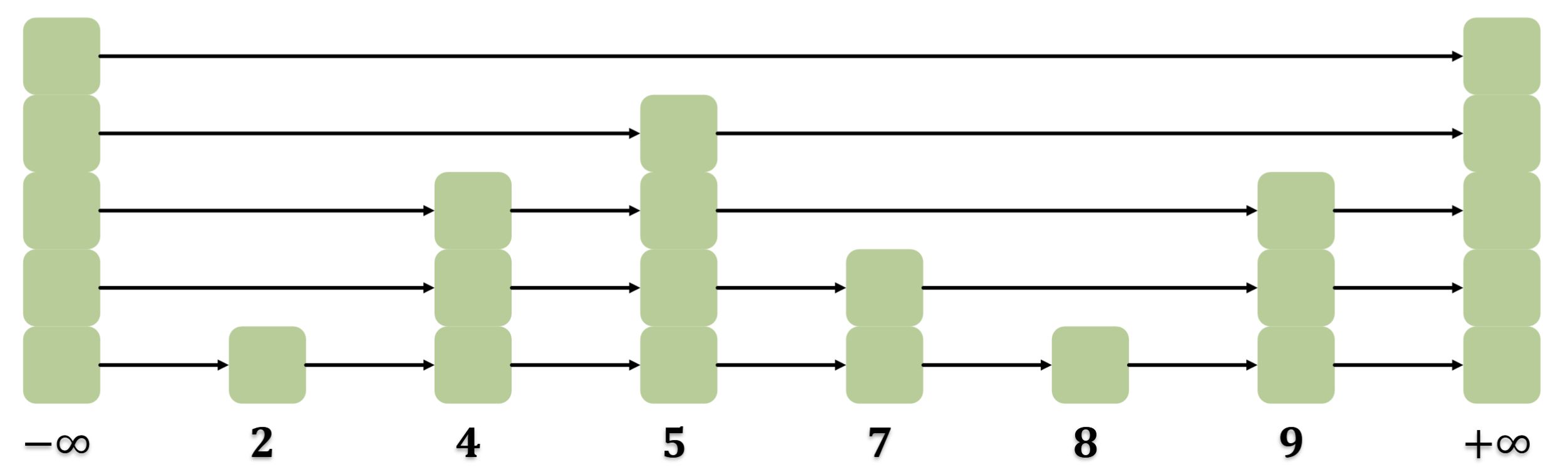
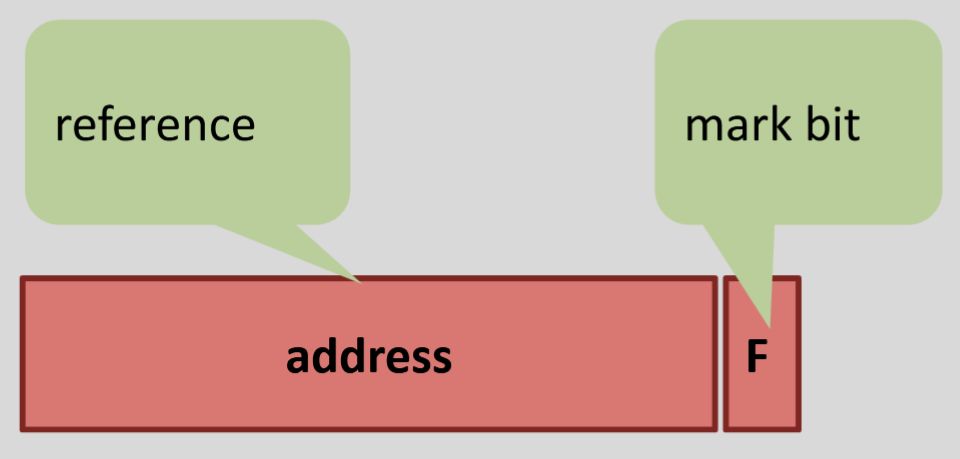
Drei Fälle für eine Kante mit Kapazität \(c\) und Fluss \(f\) im Restnetzwerk:
Fluss \(f\)
Vorwärtskante \(e\)
Rückwärtskante \(e^{\mathrm{opp}}\)
\(0 < f < c\)
existiert mit \(r_f(e) = c - f\)
existiert mit \(r_f(e^{\mathrm{opp) = f\)}}
\(f = c\) (saturiert)
existiert nicht
existiert mit \(r_f(e^{\mathrm{opp) = c\)}}
\(f = 0\)
existiert mit \(r_f(e) = c\)
existiert nicht
Saturierte Kanten produzieren nur die Rückwärtskante, leere Kanten nur die Vorwärtskante. Dazwischen entsteht ein „Doppelpfeil“ mit beiden Restkapazitäten.
Drei Fälle für eine Kante mit Kapazität \(c\) und Fluss \(f\) im Restnetzwerk:
Fluss \(f\)
Vorwärtskante \(e\)
Rückwärtskante \(e^{\mathrm{opp}}\)
\(0 < f < c\)
existiert mit \(r_f(e) = c - f\)
{{c1::existiert mit \(r_f(e^{\mathrm{opp} }) = f\)}}
\(f = c\) (saturiert)
existiert nicht
{{c2::existiert mit \(r_f(e^{\mathrm{opp} }) = c\)}}
\(f = 0\)
existiert mit \(r_f(e) = c\)
existiert nicht
Saturierte Kanten produzieren nur die Rückwärtskante, leere Kanten nur die Vorwärtskante. Dazwischen entsteht ein „Doppelpfeil“ mit beiden Restkapazitäten.
Field-by-field Comparison
Field
Before
After
Text
Drei Fälle für eine Kante mit Kapazität \(c\) und Fluss \(f\) im Restnetzwerk:<table border="1" cellpadding="6" style="border-collapse:collapse"><tr><th>Fluss \(f\)</th><th>Vorwärtskante \(e\)</th><th>Rückwärtskante \(e^{\mathrm{opp}}\)</th></tr><tr><td>\(0 < f < c\)</td><td>{{c1::existiert mit \(r_f(e) = c - f\)}}</td><td>{{c2::existiert mit \(r_f(e^{\mathrm{opp}}) = f\)}}</td></tr><tr><td>\(f = c\) (saturiert)</td><td>{{c3::existiert nicht}}</td><td>{{c4::existiert mit \(r_f(e^{\mathrm{opp}}) = c\)}}</td></tr><tr><td>\(f = 0\)</td><td>{{c5::existiert mit \(r_f(e) = c\)}}</td><td>{{c6::existiert nicht}}</td></tr></table>
Drei Fälle für eine Kante mit Kapazität \(c\) und Fluss \(f\) im Restnetzwerk:<table border="1" cellpadding="6" style="border-collapse:collapse"><tr><th>Fluss \(f\)</th><th>Vorwärtskante \(e\)</th><th>Rückwärtskante \(e^{\mathrm{opp}}\)</th></tr><tr><td>\(0 < f < c\)</td><td>{{c1::existiert mit \(r_f(e) = c - f\)}}</td><td>{{c1::existiert mit \(r_f(e^{\mathrm{opp} }) = f\)}}</td></tr><tr><td>\(f = c\) (saturiert)</td><td>{{c2::existiert nicht}}</td><td>{{c2::existiert mit \(r_f(e^{\mathrm{opp} }) = c\)}}</td></tr><tr><td>\(f = 0\)</td><td>{{c3::existiert mit \(r_f(e) = c\)}}</td><td>{{c3::existiert nicht}}</td></tr></table>
Konstruktion \(G \mapsto N_G\) (bipartites Matching). Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:
\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).
\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)
Konstruktion \(G \mapsto N_G\) (bipartites Matching). Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:
\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).
\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)
\(c \equiv 1\) (alle Kapazitäten gleich 1).
Idee: Die mittleren Kanten zeigen von \(U\) nach \(W\), also nur in eine Richtung; die Einheitskapazitäten erzwingen, dass jeder Knoten höchstens eine Match-Kante bekommt.
Konstruktion \(G \mapsto N_G\) (bipartites Matching). Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:
\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).
\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)
Konstruktion \(G \mapsto N_G\) (bipartites Matching). Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:
\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).
\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)
\(c \equiv 1\) (alle Kapazitäten gleich 1).
Idee: Die mittleren Kanten zeigen von \(U\) nach \(W\), also nur in eine Richtung; die Einheitskapazitäten erzwingen, dass jeder Knoten höchstens eine Match-Kante bekommt.
Field-by-field Comparison
Field
Before
After
Text
<b>Konstruktion \(G \mapsto N_G\) (bipartites Matching).</b> Sei \(G = (U \uplus W, E)\) bipartit. Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:<ul><li>{{c1::\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).}}</li><li>\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)</li><li>{{c3::\(c \equiv 1\)}} (alle Kapazitäten gleich 1).</li></ul>
<b>Konstruktion \(G \mapsto N_G\) (bipartites Matching).</b> <br>Sei \(G = (U \uplus W, E)\) bipartit. <br>Definiere das Netzwerk \(N_G = (U \uplus W \uplus \{s, t\}, A, c, s, t)\) mit:<ul><li>{{c1::\(s \neq t\) sind zwei neue Knoten (Quelle und Senke).}}</li><li>\(A := {{c2::\{s\} \times U \;\cup\; \{(u, w) \in U \times W : \{u, w\} \in E\} \;\cup\; W \times \{t\} }}\)</li><li>{{c3::\(c \equiv 1\) (alle Kapazitäten gleich 1)}}.</li></ul>
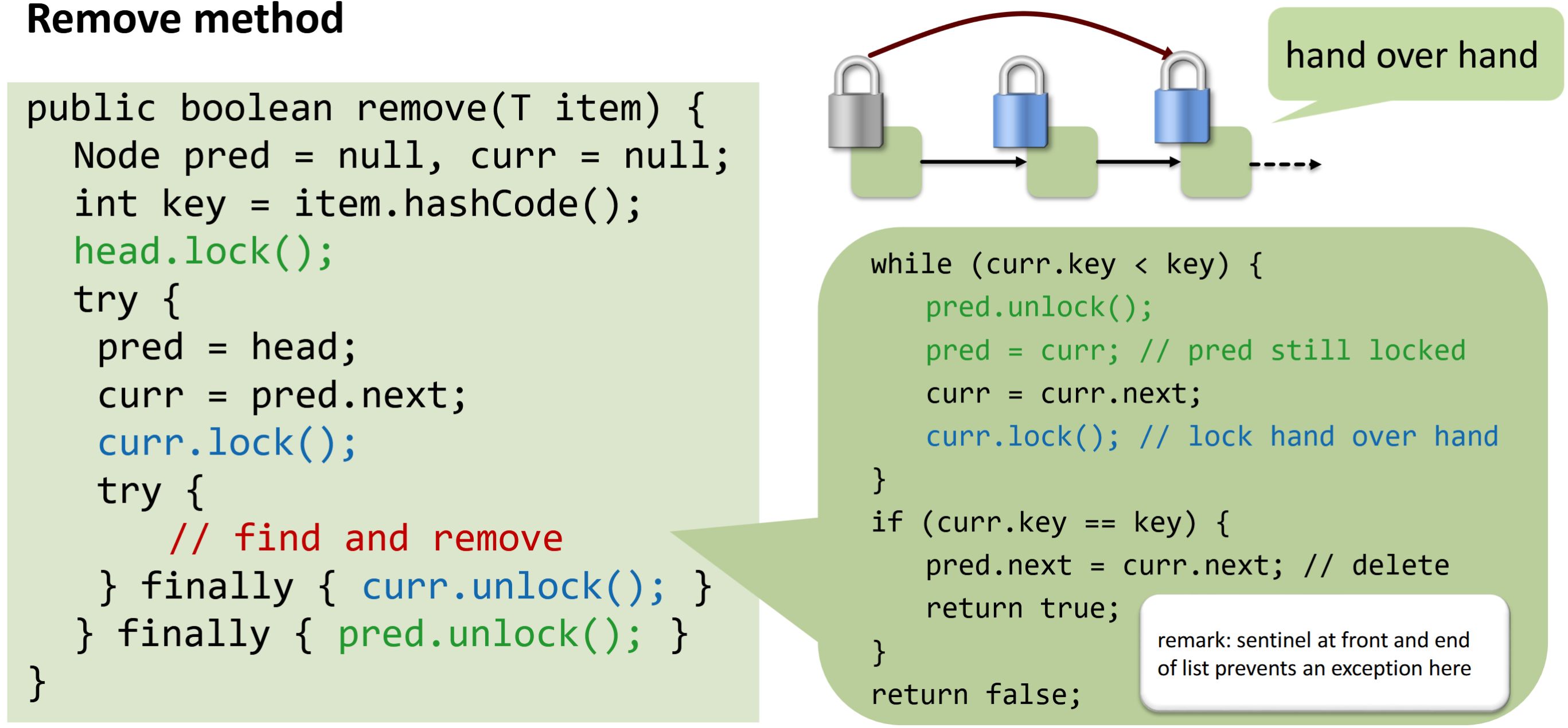
Schreibe den Ford-Fulkerson-Algorithmus als Pseudocode.
Ford-Fulkerson(V, A, c, s, t)
1: f := 0 // Fluss konstant 0
2: while exists s-t-Pfad P in N_f do // augmentierender Pfad
3: Augmentiere den Fluss entlang P
4: return f // maximaler Fluss
Korrektheit folgt direkt aus dem Charakterisierungssatz: bei Terminierung gibt es keinen s-t-Pfad in \(N_f\), also ist \(f\) maximal.
Schreibe den Ford-Fulkerson-Algorithmus als Pseudocode.
Korrektheit folgt direkt aus dem Charakterisierungssatz: bei Terminierung gibt es keinen s-t-Pfad in \(N_f\), also ist \(f\) maximal.
Field-by-field Comparison
Field
Before
After
Back
<pre>Ford-Fulkerson(V, A, c, s, t)
1: f := 0 // Fluss konstant 0
2: while exists s-t-Pfad P in N_f do // augmentierender Pfad
3: Augmentiere den Fluss entlang P
4: return f // maximaler Fluss</pre>Korrektheit folgt direkt aus dem Charakterisierungssatz: bei Terminierung gibt es keinen s-t-Pfad in \(N_f\), also ist \(f\) maximal.
<pre><img src="paste-94db307e0e8fc703f91ace0bb52704ddf5b57ed8.jpg"><br></pre>Korrektheit folgt direkt aus dem Charakterisierungssatz: bei Terminierung gibt es keinen s-t-Pfad in \(N_f\), also ist \(f\) maximal.
Satz. Wiederholt man \(\textsc{Cut}(G)\) \(\alpha \binom{n}{2}\)-mal und gibt den kleinsten erhaltenen Wert aus, so gilt:
Laufzeit \({{c1::\mathcal{O}(\alpha n^4)}}\).
Der ausgegebene Wert ist mit Wahrscheinlichkeit mindestens \(1 - e^{-\alpha}\) gleich \(\mu(G)\).
Begründung Erfolgswahrscheinlichkeit: jede Einzelausführung scheitert mit Wkt. \(\leq 1 - 1/\binom{n}{2}\). Bei \(\alpha\binom{n}{2}\) unabhängigen Wiederholungen ist die Misserfolgswkt. höchstens \((1 - 1/\binom{n}{2})^{\alpha\binom{n}{2}} \leq e^{-\alpha}\).
Mit \(\alpha := \ln n\) erhält man Zeit \(\mathcal{O}(n^4 \log n)\) bei Fehlerwkt. \(\leq 1/n\); aber diese Laufzeit hatten wir bereits deterministisch.
Field-by-field Comparison
Field
Before
After
Text
<b>Satz.</b> Wiederholt man \(\textsc{Cut}(G)\) \(\alpha \binom{n}{2}\)-mal und gibt den kleinsten erhaltenen Wert aus, so gilt:<ol><li>Laufzeit \({{c1::\mathcal{O}(\alpha n^4)}}\).</li><li>Der ausgegebene Wert ist mit Wahrscheinlichkeit mindestens \({{c2::1 - e^{-\alpha}}}\) gleich \(\mu(G)\).</li></ol>
Extra
Begründung Erfolgswahrscheinlichkeit: jede Einzelausführung scheitert mit Wkt. \(\leq 1 - 1/\binom{n}{2}\). Bei \(\alpha\binom{n}{2}\) unabhängigen Wiederholungen ist die Misserfolgswkt. höchstens \((1 - 1/\binom{n}{2})^{\alpha\binom{n}{2}} \leq e^{-\alpha}\). <br><br>Mit \(\alpha := \ln n\) erhält man Zeit \(\mathcal{O}(n^4 \log n)\) bei Fehlerwkt. \(\leq 1/n\); aber diese Laufzeit hatten wir bereits deterministisch.
Korrespondenz Matching \(\leftrightarrow\) Fluss in \(N_G\). Für einen bipartiten Graphen \(G\) gilt:
Jedem Matching \(M\) in \(G\) entspricht ein ganzzahliger Fluss \(f_M\) in \(N_G\) mit {{c1::\(\operatorname{val}(f_M) = |M|\)}}.
Jedem ganzzahligen Fluss \(f\) in \(N_G\) entspricht ein Matching \(M\) in \(G\) mit {{c1::\(|M| = \operatorname{val}(f)\)}}.
Damit folgt:\[\max_{M \text{ Matching in } G}|M| \;=\; {{c1::\max_{f \text{ ganzz. Fluss in } N_G}\operatorname{val}(f) \;=\; \max_{f \text{ Fluss in } N_G}\operatorname{val}(f)}}.\]
Die letzte Gleichheit nutzt Ford-Fulkerson (ganzzahlig): bei ganzzahligen Kapazitäten existiert immer ein ganzzahliger Maxflow.
Field-by-field Comparison
Field
Before
After
Text
<b>Korrespondenz Matching \(\leftrightarrow\) Fluss in \(N_G\).</b> Für einen bipartiten Graphen \(G\) gilt:<ul><li>Jedem Matching \(M\) in \(G\) entspricht ein ganzzahliger Fluss \(f_M\) in \(N_G\) mit {{c1::\(\operatorname{val}(f_M) = |M|\)}}.</li><li>Jedem ganzzahligen Fluss \(f\) in \(N_G\) entspricht ein Matching \(M\) in \(G\) mit {{c1::\(|M| = \operatorname{val}(f)\)}}.</li></ul>Damit folgt:\[\max_{M \text{ Matching in } G}|M| \;=\; {{c2::\max_{f \text{ ganzz. Fluss in } N_G}\operatorname{val}(f) \;=\; \max_{f \text{ Fluss in } N_G}\operatorname{val}(f)}}.\]
<b>Korrespondenz Matching \(\leftrightarrow\) Fluss in \(N_G\).</b> <br>Für einen bipartiten Graphen \(G\) gilt:<ul><li>Jedem Matching \(M\) in \(G\) entspricht ein ganzzahliger Fluss \(f_M\) in \(N_G\) mit {{c1::\(\operatorname{val}(f_M) = |M|\)}}.</li><li>Jedem ganzzahligen Fluss \(f\) in \(N_G\) entspricht ein Matching \(M\) in \(G\) mit {{c1::\(|M| = \operatorname{val}(f)\)}}.</li></ul>Damit folgt:\[\max_{M \text{ Matching in } G}|M| \;=\; {{c1::\max_{f \text{ ganzz. Fluss in } N_G}\operatorname{val}(f) \;=\; \max_{f \text{ Fluss in } N_G}\operatorname{val}(f)}}.\]
Jeder \(k\)-reguläre bipartite Graph \(G = (A \cup B, E)\) für \(k \geq 1\) hat ein Matching der Größe \(|A|\).
Wahr
Hall-Satz: Da \(G\) \(k\)-regulär ist, hat jeder Knoten in \(X\) Grad \(k\), jeder in \(N(X)\) Grad \(\leq k\). Weil in bipartiten Graphen die Gradsumme links gleich der Gradsumme rechts ist, folgt \(|N(X)| \geq |X|\). Damit ist Halls Bedingung erfüllt und ein Matching der Größe \(|A|\) existiert.
Es gilt sogar: \(E\) lässt sich in \(k\) disjunkte perfekte Matchings partitionieren (iteratives Entfernen eines perfekten Matchings liefert jeweils einen \((k-1)\)-regulären Graphen).
Jeder \(k\)-reguläre bipartite Graph \(G = (A \cup B, E)\) für \(k \geq 1\) hat ein Matching der Größe \(|A|\).
Wahr.
Hall-Satz: Da \(G\) \(k\)-regulär ist, hat jeder Knoten in \(X\) Grad \(k\), jeder in \(N(X)\) Grad \(\leq k\). Weil in bipartiten Graphen die Gradsumme links gleich der Gradsumme rechts ist, folgt \(|N(X)| \geq |X|\). Damit ist Halls Bedingung erfüllt und ein Matching der Größe \(|A|\) existiert.
Es gilt sogar: \(E\) lässt sich in \(k\) disjunkte perfekte Matchings partitionieren (iteratives Entfernen eines perfekten Matchings liefert jeweils einen \((k-1)\)-regulären Graphen).
Field-by-field Comparison
Field
Before
After
Back
Wahr<br><br><b>Hall-Satz</b>: Da \(G\) \(k\)-regulär ist, hat jeder Knoten in \(X\) Grad \(k\), jeder in \(N(X)\) Grad \(\leq k\). Weil in bipartiten Graphen die Gradsumme links gleich der Gradsumme rechts ist, folgt \(|N(X)| \geq |X|\). Damit ist Halls Bedingung erfüllt und ein Matching der Größe \(|A|\) existiert. <br><br>Es gilt sogar: \(E\) lässt sich in \(k\) disjunkte perfekte Matchings partitionieren (iteratives Entfernen eines perfekten Matchings liefert jeweils einen \((k-1)\)-regulären Graphen).
Wahr.<br><br><b>Hall-Satz</b>: Da \(G\) \(k\)-regulär ist, hat jeder Knoten in \(X\) Grad \(k\), jeder in \(N(X)\) Grad \(\leq k\). Weil in bipartiten Graphen die Gradsumme links gleich der Gradsumme rechts ist, folgt \(|N(X)| \geq |X|\). Damit ist Halls Bedingung erfüllt und ein Matching der Größe \(|A|\) existiert. <br><br>Es gilt sogar: \(E\) lässt sich in \(k\) disjunkte perfekte Matchings partitionieren (iteratives Entfernen eines perfekten Matchings liefert jeweils einen \((k-1)\)-regulären Graphen).
Sei \(\hat{p}(G)\) die Wahrscheinlichkeit, dass \(\textsc{Cut}(G)\) den Wert \(\mu(G)\) ausgibt, und \(\hat{p}(n) := \inf_{|V(G)| = n} \hat{p}(G)\). Dann gilt für \(n \geq 3\)\[\hat{p}(n) \;\geq\; {{c1::\left(1 - \tfrac{2}{n}\right) \cdot \hat{p}(n - 1)}},\]und durch Auflösung der Rekursion (mit \(\hat{p}(2) = 1\))\[\hat{p}(n) \;\geq\; {{c2::\tfrac{2}{n(n-1)} = 1\big/\binom{n}{2}}}.\]
Sei \(\hat{p}(G)\) die Wahrscheinlichkeit, dass \(\textsc{Cut}(G)\) den Wert \(\mu(G)\) ausgibt, und \(\hat{p}(n) := \inf_{|V(G)| = n} \hat{p}(G)\). Dann gilt für \(n \geq 3\)\[\hat{p}(n) \;\geq\; {{c1::\left(1 - \tfrac{2}{n}\right) \cdot \hat{p}(n - 1)}},\]und durch Auflösung der Rekursion (mit \(\hat{p}(2) = 1\))\[\hat{p}(n) \;\geq\; {{c2::\tfrac{2}{n(n-1)} = 1\big/\binom{n}{2}}}.\]
Beweis der Rekursion: Mit \(E_1 := \{\mu(G) = \mu(G/e)\}\) und \(E_2 := \{\textsc{Cut}(G/e) \text{ liefert } \mu(G/e)\}\) gilt\[\hat{p}(G) = \Pr[E_1 \cap E_2] = \Pr[E_1] \cdot \Pr[E_2 \mid E_1] \geq (1 - 2/n) \cdot \hat{p}(n-1).\] Daraus folgt: erwartete Wiederholungen bis zum ersten Treffer von \(\mu(G)\) sind höchstens \(\binom{n}{2}\). Proof Included
Field-by-field Comparison
Field
Before
After
Text
Sei \(\hat{p}(G)\) die Wahrscheinlichkeit, dass \(\textsc{Cut}(G)\) den Wert \(\mu(G)\) ausgibt, und \(\hat{p}(n) := \inf_{|V(G)| = n} \hat{p}(G)\). Dann gilt für \(n \geq 3\)\[\hat{p}(n) \;\geq\; {{c1::\left(1 - \tfrac{2}{n}\right) \cdot \hat{p}(n - 1)}},\]und durch Auflösung der Rekursion (mit \(\hat{p}(2) = 1\))\[\hat{p}(n) \;\geq\; {{c2::\tfrac{2}{n(n-1)} = 1\big/\binom{n}{2}}}.\]
Extra
Beweis der Rekursion: Mit \(E_1 := \{\mu(G) = \mu(G/e)\}\) und \(E_2 := \{\textsc{Cut}(G/e) \text{ liefert } \mu(G/e)\}\) gilt\[\hat{p}(G) = \Pr[E_1 \cap E_2] = \Pr[E_1] \cdot \Pr[E_2 \mid E_1] \geq (1 - 2/n) \cdot \hat{p}(n-1).\] Daraus folgt: erwartete Wiederholungen bis zum ersten Treffer von \(\mu(G)\) sind höchstens \(\binom{n}{2}\). <i>Proof Included</i>
Kantenkontraktion. Gegeben \(G = (V, E)\) und \(e = \{u, v\} \in E\). Die Kontraktion von \(e\) verschmilzt \(u\) und \(v\) zu einem neuen Knoten \(x_{u,v}\), der nun zu allen Kanten inzident ist, zu denen \(u\) oder \(v\) inzident war. Kanten zwischen \(u\) und \(v\) verschwinden.
Kantenkontraktion. Gegeben \(G = (V, E)\) und \(e = \{u, v\} \in E\). Die Kontraktion von \(e\) verschmilzt \(u\) und \(v\) zu einem neuen Knoten \(x_{u,v}\), der nun zu allen Kanten inzident ist, zu denen \(u\) oder \(v\) inzident war. Kanten zwischen \(u\) und \(v\) verschwinden.
Der entstehende Graph heisst \(G / e\).
Wichtig: Mehrfachkanten zu gemeinsamen Nachbarn von \(u\) und \(v\) bleiben erhalten (daher ist der Multigraph-Rahmen nötig: einfache Graphen sind unter Kontraktion nicht abgeschlossen).
Field-by-field Comparison
Field
Before
After
Text
<b>Kantenkontraktion.</b> <br>Gegeben \(G = (V, E)\) und \(e = \{u, v\} \in E\). Die Kontraktion von \(e\) verschmilzt \(u\) und \(v\) zu einem neuen Knoten \(x_{u,v}\), der nun {{c1::zu allen Kanten inzident ist, zu denen \(u\) oder \(v\) inzident war. Kanten zwischen \(u\) und \(v\) verschwinden.}}<br><br>Der entstehende Graph heisst {{c3::\(G / e\)}}.
Extra
Wichtig: Mehrfachkanten zu gemeinsamen Nachbarn von \(u\) und \(v\) bleiben erhalten (daher ist der Multigraph-Rahmen nötig: einfache Graphen sind unter Kontraktion nicht abgeschlossen).
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).
Ein Kantenschnitt ist eine Menge \(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist.
Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst \(\mu(G)\) und ist definiert als\[\mu(G) := {{c2::\min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|}}.\]
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).
Ein Kantenschnitt ist eine Menge \(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist.
Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst \(\mu(G)\) und ist definiert als\[\mu(G) := {{c2::\min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|}}.\]
Äquivalente Sichtweise: Ein Schnitt ist eine Partition \(V = S \sqcup T\) mit \(S, T \neq \emptyset\); man minimiert die Anzahl Kanten zwischen \(S\) und \(T\). Mehrfachkanten dürfen auch durch positiv ganzzahlige Kantengewichte realisiert werden.
Field-by-field Comparison
Field
Before
After
Text
Sei \(G = (V, E)\) ein Multigraph (ungerichtet, ungewichtet, ohne Schleifen, Mehrfachkanten erlaubt).<br><br>Ein <b>Kantenschnitt</b> ist eine Menge {{c1::\(C \subseteq E\), so dass \((V, E \setminus C)\) nicht zusammenhängend ist}}.<br><br>Die Kardinalität eines kleinstmöglichen Kantenschnitts heisst {{c2::\(\mu(G)\)}} und ist definiert als\[\mu(G) := {{c2::\min_{\substack{C \subseteq E \\ (V, E \setminus C) \text{ n. z.h.} } } |C|}}.\]
Extra
Äquivalente Sichtweise: Ein Schnitt ist eine Partition \(V = S \sqcup T\) mit \(S, T \neq \emptyset\); man minimiert die Anzahl Kanten zwischen \(S\) und \(T\). Mehrfachkanten dürfen auch durch positiv ganzzahlige Kantengewichte realisiert werden.
Wir können das MIN-CUT-Problem auf den s-t-Mincut zurückführen: fixiere ein \(s\) und betrachte alle \(t \in V \setminus \{s\}\); jeder Schnitt ist ein s-t-Schnitt für ein passendes \(t\).
Bei \((n - 1)\)-maligem Aufruf eines s-t-Mincut-Algorithmus mit Laufzeit \(\mathcal{O}(mn \log n)\) erhalten wir Gesamtlaufzeit\[{{c1::\mathcal{O}(mn^2 \log n) = \mathcal{O}(n^4 \log n)}}.\]Dies ist die Messlatte, die wir unterbieten wollen.
Wir können das MIN-CUT-Problem auf den s-t-Mincut zurückführen: fixiere ein \(s\) und betrachte alle \(t \in V \setminus \{s\}\); jeder Schnitt ist ein s-t-Schnitt für ein passendes \(t\).
Bei \((n - 1)\)-maligem Aufruf eines s-t-Mincut-Algorithmus mit Laufzeit \(\mathcal{O}(mn \log n)\) erhalten wir Gesamtlaufzeit\[{{c1::\mathcal{O}(mn^2 \log n) = \mathcal{O}(n^4 \log n)}}.\]Dies ist die Messlatte, die wir unterbieten wollen.
Es genügt, ein einziges \(s\) zu fixieren, weil jeder Schnitt mindestens einen Knoten \(t \neq s\) auf der anderen Seite hat. Die Schranke \(m = \mathcal{O}(n^2)\) gilt im Multigraph nach Reduktion auf Kantengewichte (sonst wäre \(m\) unbeschränkt).
Field-by-field Comparison
Field
Before
After
Text
Wir können das MIN-CUT-Problem auf den s-t-Mincut zurückführen: fixiere ein \(s\) und betrachte alle \(t \in V \setminus \{s\}\); jeder Schnitt ist ein s-t-Schnitt für ein passendes \(t\). <br><br>Bei \((n - 1)\)-maligem Aufruf eines s-t-Mincut-Algorithmus mit Laufzeit \(\mathcal{O}(mn \log n)\) erhalten wir Gesamtlaufzeit\[{{c1::\mathcal{O}(mn^2 \log n) = \mathcal{O}(n^4 \log n)}}.\]Dies ist die Messlatte, die wir unterbieten wollen.
Extra
Es genügt, ein einziges \(s\) zu fixieren, weil jeder Schnitt mindestens einen Knoten \(t \neq s\) auf der anderen Seite hat. Die Schranke \(m = \mathcal{O}(n^2)\) gilt im Multigraph nach Reduktion auf Kantengewichte (sonst wäre \(m\) unbeschränkt).
Schreibe den Karger-Algorithmus \(\text{Cut}(G)\) (random edge contraction) als Pseudocode und gib seine Laufzeit an, unter der Annahme, dass Kantenkontraktion und das Ziehen einer gleichverteilt zufälligen Kante je in \(\mathcal{O}(n)\) Zeit möglich sind.
Schreibe den Karger-Algorithmus \(\text{Cut}(G)\) (random edge contraction) als Pseudocode und gib seine Laufzeit an, unter der Annahme, dass Kantenkontraktion und das Ziehen einer gleichverteilt zufälligen Kante je in \(\mathcal{O}(n)\) Zeit möglich sind.
Laufzeit: \(\mathcal{O}(n^2)\) (genau \(n - 2\) Kontraktionen, jede in \(\mathcal{O}(n)\)).
Achtung: das Ziehen einer gleichverteilt zufälligen Kante in einem Multigraph erfordert die Darstellung der Mehrfachkanten durch Kantengewichte. Der zurückgegebene Wert ist nie kleiner als \(\mu(G)\), aber im Allgemeinen zu gross.
Field-by-field Comparison
Field
Before
After
Front
Schreibe den <b>Karger-Algorithmus</b> \(\text{Cut}(G)\) (random edge contraction) als Pseudocode und gib seine Laufzeit an, unter der Annahme, dass Kantenkontraktion und das Ziehen einer gleichverteilt zufälligen Kante je in \(\mathcal{O}(n)\) Zeit möglich sind.
Back
<pre><img src="paste-eb17e60d42eab10536ca1fd7fc879f6e7d7c708e.jpg"><br></pre>Laufzeit: \(\mathcal{O}(n^2)\) (genau \(n - 2\) Kontraktionen, jede in \(\mathcal{O}(n)\)). <br><br>Achtung: das Ziehen einer <b>gleichverteilt zufälligen Kante</b> in einem Multigraph erfordert die Darstellung der Mehrfachkanten durch Kantengewichte. Der zurückgegebene Wert ist nie kleiner als \(\mu(G)\), aber im Allgemeinen zu gross.
Maximum Bipartite Matching. Für das Problem, in einem bipartiten Graphen ein kardinalitätsmaximales Matching zu finden, gilt:
Greedy funktioniert nicht (liefert nur ein inklusionsmaximales Matching).
Lösungsansatz: Reduktion auf Maxflow.
Field-by-field Comparison
Field
Before
After
Text
<b>Maximum Bipartite Matching.</b> Für das Problem, in einem bipartiten Graphen ein kardinalitätsmaximales Matching zu finden, gilt:<ul><li>{{c1::Greedy funktioniert nicht}} (liefert nur ein inklusionsmaximales Matching).</li><li>Lösungsansatz: {{c2::Reduktion auf Maxflow}}.</li></ul>
<b>Maximum Bipartite Matching.</b> <br>Für das Problem, in einem bipartiten Graphen ein kardinalitätsmaximales Matching zu finden, gilt:<ul><li>Greedy {{c1::funktioniert nicht (liefert nur ein inklusionsmaximales Matching)}}.</li><li>Lösungsansatz: {{c2::Reduktion auf Maxflow}}.</li></ul>
s-t-Schnitt: Menge an Kanten, ohne die \(t\) von \(s\) nicht erreichbar ist.
(Globaler) Schnitt: Menge an Kanten, ohne die der Graph nicht zusammenhängend ist.
Beim globalen Schnitt sind weder Quelle noch Senke fixiert: es genügt, dass irgendeine Partition entsteht. Jeder globale Schnitt ist insbesondere ein s-t-Schnitt für passend gewählte \(s, t\).
Field-by-field Comparison
Field
Before
After
Text
Zwei Schnitt-Begriffe im Vergleich:<ul><li><b>s-t-Schnitt:</b> Menge an Kanten, ohne die {{c1::\(t\) von \(s\) nicht erreichbar}} ist.</li><li><b>(Globaler) Schnitt:</b> Menge an Kanten, ohne die {{c2::der Graph nicht zusammenhängend}} ist.</li></ul>
Extra
Beim globalen Schnitt sind <b>weder Quelle noch Senke fixiert</b>: es genügt, dass <i>irgendeine</i> Partition entsteht. Jeder globale Schnitt ist insbesondere ein s-t-Schnitt für passend gewählte \(s, t\).
Maxflow-Mincut-Theorem (ganzzahlig, konstruktiv). Jedes Netzwerk mit ganzzahligen Kapazitäten erfüllt\[\max_{f \text{ Fluss}} \operatorname{val}(f) \;=\; \min_{(S, T) \text{ s-t-Schnitt}} \operatorname{cap}(S, T).\]Der Beweis ist konstruktiv: nach Terminierung von Ford-Fulkerson liefert {{c1::\(S := \{v \in V : v \text{ in } N_f \text{ von } s \text{ erreichbar}\}\)}} einen Schnitt mit {{c2::\(\operatorname{cap}(S, T) = \operatorname{val}(f)\)}}.
Maxflow-Mincut-Theorem (ganzzahlig, konstruktiv). Jedes Netzwerk mit ganzzahligen Kapazitäten erfüllt\[\max_{f \text{ Fluss}} \operatorname{val}(f) \;=\; \min_{(S, T) \text{ s-t-Schnitt}} \operatorname{cap}(S, T).\]Der Beweis ist konstruktiv: nach Terminierung von Ford-Fulkerson liefert {{c1::\(S := \{v \in V : v \text{ in } N_f \text{ von } s \text{ erreichbar}\}\)}} einen Schnitt mit {{c2::\(\operatorname{cap}(S, T) = \operatorname{val}(f)\)}}.
Die ganzzahlige Variante folgt direkt aus dem Charakterisierungssatz und der Termination von Ford-Fulkerson bei \(c : A \to \mathbb{N}_0\). Im reellwertigen Fall verlangt der Beweis ein Kompaktheits-/Grenzwertargument.
Maxflow-Mincut-Theorem (ganzzahlig, konstruktiv). Jedes Netzwerk mit ganzzahligen Kapazitäten erfüllt\[\max_{f \text{ Fluss}} \operatorname{val}(f) \;=\; \min_{(S, T) \text{ s-t-Schnitt}} \operatorname{cap}(S, T).\]Der Beweis ist konstruktiv: nach Terminierung von Ford-Fulkerson liefert \(S := {{c1::\{v \in V : v \text{ in } N_f \text{ von } s \text{ erreichbar}\} }}\) einen Schnitt mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\).
Maxflow-Mincut-Theorem (ganzzahlig, konstruktiv). Jedes Netzwerk mit ganzzahligen Kapazitäten erfüllt\[\max_{f \text{ Fluss}} \operatorname{val}(f) \;=\; \min_{(S, T) \text{ s-t-Schnitt}} \operatorname{cap}(S, T).\]Der Beweis ist konstruktiv: nach Terminierung von Ford-Fulkerson liefert \(S := {{c1::\{v \in V : v \text{ in } N_f \text{ von } s \text{ erreichbar}\} }}\) einen Schnitt mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\).
Die ganzzahlige Variante folgt direkt aus dem Charakterisierungssatz und der Termination von Ford-Fulkerson bei \(c : A \to \mathbb{N}_0\). Im reellwertigen Fall verlangt der Beweis ein Kompaktheits-/Grenzwertargument.
Field-by-field Comparison
Field
Before
After
Text
<b>Maxflow-Mincut-Theorem (ganzzahlig, konstruktiv).</b> Jedes Netzwerk mit ganzzahligen Kapazitäten erfüllt\[\max_{f \text{ Fluss}} \operatorname{val}(f) \;=\; \min_{(S, T) \text{ s-t-Schnitt}} \operatorname{cap}(S, T).\]Der Beweis ist konstruktiv: nach Terminierung von Ford-Fulkerson liefert {{c1::\(S := \{v \in V : v \text{ in } N_f \text{ von } s \text{ erreichbar}\}\)}} einen Schnitt mit {{c2::\(\operatorname{cap}(S, T) = \operatorname{val}(f)\)}}.
<b>Maxflow-Mincut-Theorem (ganzzahlig, konstruktiv).</b> <br>Jedes Netzwerk mit ganzzahligen Kapazitäten erfüllt\[\max_{f \text{ Fluss}} \operatorname{val}(f) \;=\; \min_{(S, T) \text{ s-t-Schnitt}} \operatorname{cap}(S, T).\]Der Beweis ist konstruktiv: nach Terminierung von Ford-Fulkerson liefert \(S := {{c1::\{v \in V : v \text{ in } N_f \text{ von } s \text{ erreichbar}\} }}\) einen Schnitt mit \(\operatorname{cap}(S, T) = \operatorname{val}(f)\).
Eigenschaften des Ford-Fulkerson-Algorithmus bezüglich Termination:
Allgemein: Terminierung ist nicht garantiert.
Bei Kapazitäten in \(\mathbb{R}\): der Algorithmus kann unendlich laufen.
Bei Kapazitäten in \(\mathbb{N}_0\): Flüsse und Restkapazitäten bleiben ganzzahlig, und der Fluss verbessert sich pro Augmentierung um mindestens \(1\).
Eigenschaften des Ford-Fulkerson-Algorithmus bezüglich Termination:
Allgemein: Terminierung ist nicht garantiert.
Bei Kapazitäten in \(\mathbb{R}\): der Algorithmus kann unendlich laufen.
Bei Kapazitäten in \(\mathbb{N}_0\): Flüsse und Restkapazitäten bleiben ganzzahlig, und der Fluss verbessert sich pro Augmentierung um mindestens \(1\).
Bei reellen (sogar irrationalen) Kapazitäten gibt es Beispiele, in denen Ford-Fulkerson zwar konvergiert, aber gegen einen falschen Wert oder gar nicht. Die Wahl des augmentierenden Pfads (z.B. via BFS bei Edmonds-Karp) liefert eine Polynomialzeitschranke unabhängig von \(U\).
Eigenschaften des Ford-Fulkerson-Algorithmus bezüglich Termination:
Allgemein: Terminierung ist nicht garantiert.
Bei Kapazitäten in \(\mathbb{R}\): der Algorithmus kann unendlich laufen.
Bei Kapazitäten in \(\mathbb{N}_0\): Flüsse und Restkapazitäten bleiben ganzzahlig, und der Fluss verbessert sich pro Augmentierung um mindestens \(1\).
Eigenschaften des Ford-Fulkerson-Algorithmus bezüglich Termination:
Allgemein: Terminierung ist nicht garantiert.
Bei Kapazitäten in \(\mathbb{R}\): der Algorithmus kann unendlich laufen.
Bei Kapazitäten in \(\mathbb{N}_0\): Flüsse und Restkapazitäten bleiben ganzzahlig, und der Fluss verbessert sich pro Augmentierung um mindestens \(1\).
Bei reellen (sogar irrationalen) Kapazitäten gibt es Beispiele, in denen Ford-Fulkerson zwar konvergiert, aber gegen einen falschen Wert oder gar nicht. Die Wahl des augmentierenden Pfads (z.B. via BFS bei Edmonds-Karp) liefert eine Polynomialzeitschranke unabhängig von \(U\).
Field-by-field Comparison
Field
Before
After
Text
Eigenschaften des Ford-Fulkerson-Algorithmus bezüglich Termination:<ul><li>Allgemein: {{c1::Terminierung ist nicht garantiert}}.</li><li>Bei Kapazitäten in \(\mathbb{R}\): {{c2::der Algorithmus kann unendlich laufen}}.</li><li>Bei Kapazitäten in \(\mathbb{N}_0\): {{c3::Flüsse und Restkapazitäten bleiben ganzzahlig}}, und der Fluss verbessert sich pro Augmentierung um {{c4::mindestens \(1\)}}.</li></ul>
Eigenschaften des Ford-Fulkerson-Algorithmus bezüglich Termination:<ul><li>Allgemein: {{c1::Terminierung ist nicht garantiert}}.</li><li>Bei Kapazitäten in \(\mathbb{R}\): {{c2::der Algorithmus kann unendlich laufen}}.</li><li>Bei Kapazitäten in \(\mathbb{N}_0\): {{c3::Flüsse und Restkapazitäten bleiben ganzzahlig, und der Fluss verbessert sich pro Augmentierung um mindestens \(1\)}}.</li></ul>
Beweis von „Pfad in \(N_f\) \(\Rightarrow\) \(f\) nicht maximal“. Gegeben ein gerichteter s-t-Pfad in \(N_f\) mit Restkapazitäten \(\varepsilon_1, \ldots, \varepsilon_k\). Setze \(\varepsilon := \min_i \varepsilon_i > 0\). Augmentiere \(f\) entlang des Pfads um \(\varepsilon\): auf Vorwärtskanten \(+\varepsilon\), auf Rückwärtskanten \(-\varepsilon\). Der neue Fluss ist zulässig (durch Wahl von \(\varepsilon\)) und flusserhaltend, und es gilt \(\operatorname{val}(f') = {{c5::\operatorname{val}(f) + \varepsilon}}\).
Beweis von „Pfad in \(N_f\) \(\Rightarrow\) \(f\) nicht maximal“. Gegeben ein gerichteter s-t-Pfad in \(N_f\) mit Restkapazitäten \(\varepsilon_1, \ldots, \varepsilon_k\). Setze \(\varepsilon := \min_i \varepsilon_i > 0\). Augmentiere \(f\) entlang des Pfads um \(\varepsilon\): auf Vorwärtskanten \(+\varepsilon\), auf Rückwärtskanten \(-\varepsilon\). Der neue Fluss ist zulässig (durch Wahl von \(\varepsilon\)) und flusserhaltend, und es gilt \(\operatorname{val}(f') = {{c5::\operatorname{val}(f) + \varepsilon}}\).
Zulässigkeit: bei \(+\varepsilon\) bleibt man unter \(c\), weil \(\varepsilon \leq c - f\); bei \(-\varepsilon\) bleibt man über \(0\), weil \(\varepsilon \leq f\).
Augmentiere \(f\) entlang des Pfads um \(\varepsilon\): auf Vorwärtskanten \(+\varepsilon\), auf Rückwärtskanten \(-\varepsilon\).
Der neue Fluss ist zulässig (durch Wahl von \(\varepsilon\)) und flusserhaltend, und es gilt \(\operatorname{val}(f') = {{c5::\operatorname{val}(f) + \varepsilon}}\).
Augmentiere \(f\) entlang des Pfads um \(\varepsilon\): auf Vorwärtskanten \(+\varepsilon\), auf Rückwärtskanten \(-\varepsilon\).
Der neue Fluss ist zulässig (durch Wahl von \(\varepsilon\)) und flusserhaltend, und es gilt \(\operatorname{val}(f') = {{c5::\operatorname{val}(f) + \varepsilon}}\).
Zulässigkeit: bei \(+\varepsilon\) bleibt man unter \(c\), weil \(\varepsilon \leq c - f\); bei \(-\varepsilon\) bleibt man über \(0\), weil \(\varepsilon \leq f\).
Field-by-field Comparison
Field
Before
After
Text
<b>Beweis von „Pfad in \(N_f\) \(\Rightarrow\) \(f\) nicht maximal“.</b> Gegeben ein gerichteter s-t-Pfad in \(N_f\) mit Restkapazitäten \(\varepsilon_1, \ldots, \varepsilon_k\).Setze \(\varepsilon := {{c1::\min_i \varepsilon_i}} > 0\).Augmentiere \(f\) entlang des Pfads um \(\varepsilon\): auf Vorwärtskanten {{c2::\(+\varepsilon\)}}, auf Rückwärtskanten {{c3::\(-\varepsilon\)}}. Der neue Fluss ist {{c4::zulässig (durch Wahl von \(\varepsilon\)) und flusserhaltend}}, und es gilt \(\operatorname{val}(f') = {{c5::\operatorname{val}(f) + \varepsilon}}\).
<b>Beweis von „Pfad in \(N_f\) \(\Rightarrow\) \(f\) nicht maximal“.<br></b> <br>Gegeben ein gerichteter s-t-Pfad in \(N_f\) mit Restkapazitäten \(\varepsilon_1, \ldots, \varepsilon_k\).<br><ol><li>Setze \(\varepsilon := {{c1::\min_i \varepsilon_i}} > 0\).</li><li>Augmentiere \(f\) entlang des Pfads um \(\varepsilon\): auf Vorwärtskanten \(+\varepsilon\), auf Rückwärtskanten \(-\varepsilon\).</li><li>Der neue Fluss ist {{c4::zulässig (durch Wahl von \(\varepsilon\)) und flusserhaltend}}, und es gilt \(\operatorname{val}(f') = {{c5::\operatorname{val}(f) + \varepsilon}}\).</li></ol>
Sei \(e = \{u, v\}\) und \(k\) die Anzahl Kanten zwischen \(u\) und \(v\) in \(G\). Dann gilt\[\begin{gathered}\deg_{G/e}(x_{u,v}) = \deg_G(u) + \deg_G(v) - 2k, \\|E(G/e)| = |E(G)| - k.\end{gathered}\]
Sei \(e = \{u, v\}\) und \(k\) die Anzahl Kanten zwischen \(u\) und \(v\) in \(G\). Dann gilt\[\begin{gathered}\deg_{G/e}(x_{u,v}) = \deg_G(u) + \deg_G(v) - 2k, \\|E(G/e)| = |E(G)| - k.\end{gathered}\]
Die \(-2k\) bzw. \(-k\) erfassen genau die \(k\) Kanten zwischen \(u\) und \(v\), die verschwinden. Jede zählt im Knotengrad zweimal (an beiden Enden), in der Kantenzahl nur einmal.
Field-by-field Comparison
Field
Before
After
Text
Sei \(e = \{u, v\}\) und \(k\) die Anzahl Kanten zwischen \(u\) und \(v\) in \(G\). <br>Dann gilt\[\begin{gathered}\deg_{G/e}(x_{u,v}) = {{c1::\deg_G(u) + \deg_G(v) - 2k}}, \\|E(G/e)| = {{c2::|E(G)| - k}}.\end{gathered}\]
Extra
Die \(-2k\) bzw. \(-k\) erfassen genau die \(k\) Kanten zwischen \(u\) und \(v\), die verschwinden. Jede zählt im Knotengrad zweimal (an beiden Enden), in der Kantenzahl nur einmal.
Sei \(N\) ein Netzwerk ohne entgegen gerichtete Kanten. Dann gilt:
\(f\) ist maximaler Fluss \(\iff\) im Restnetzwerk \(N_f\) gibt es keinen gerichteten s-t-Pfad.
Für jeden maximalen Fluss \(f\) gibt es einen s-t-Schnitt \((S, T)\) mit {{c2::\(\operatorname{val}(f) = \operatorname{cap}(S, T)\)}}.
Der zweite Punkt liefert konstruktiv das Maxflow-Mincut-Theorem.
Field-by-field Comparison
Field
Before
After
Text
<b>Satz (Charakterisierung maximaler Fluss).</b> Sei \(N\) ein Netzwerk ohne entgegen gerichtete Kanten. Dann gilt:<ul><li>\(f\) ist maximaler Fluss \(\iff\) {{c1::im Restnetzwerk \(N_f\) gibt es keinen gerichteten s-t-Pfad}}.</li><li>Für jeden maximalen Fluss \(f\) gibt es einen s-t-Schnitt \((S, T)\) mit {{c2::\(\operatorname{val}(f) = \operatorname{cap}(S, T)\)}}.</li></ul>
Sei \(N\) ein Netzwerk ohne entgegen gerichtete Kanten. Dann gilt:<ul><li>\(f\) ist maximaler Fluss \(\iff\) {{c1::im Restnetzwerk \(N_f\) gibt es keinen gerichteten s-t-Pfad}}.</li><li>Für jeden maximalen Fluss \(f\) gibt es einen s-t-Schnitt \((S, T)\) mit {{c2::\(\operatorname{val}(f) = \operatorname{cap}(S, T)\)}}.</li></ul>
Extra
Der zweite Punkt liefert konstruktiv das Maxflow-Mincut-Theorem. <i>Proof Included</i>
Der zweite Punkt liefert konstruktiv das Maxflow-Mincut-Theorem.
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
Wenn \(G\) ein zusammenhängender Graph mit einem maximalen Grad von 100 ist, dann hat \(G\) eine korrekte Färbung mit 100 Farben, es sei denn, \(G\) ist ein vollständiger Graph.
In einem Multigraphen \(G = (V, E)\) ist der Grad \(\deg(v)\) eines Knoten \(v\) die Anzahl inzidenter Kanten (nicht die Anzahl Nachbarn). Es gelten\[\begin{gathered}|E| = {{c2::\tfrac{1}{2} \sum_{v \in V} \deg(v)}}, \\\mu(G) \leq {{c3::\min_{v \in V} \deg(v)}}.\end{gathered}\]
In einem Multigraphen \(G = (V, E)\) ist der Grad \(\deg(v)\) eines Knoten \(v\) die Anzahl inzidenter Kanten (nicht die Anzahl Nachbarn). Es gelten\[\begin{gathered}|E| = {{c2::\tfrac{1}{2} \sum_{v \in V} \deg(v)}}, \\\mu(G) \leq {{c3::\min_{v \in V} \deg(v)}}.\end{gathered}\]
Die Schranke \(\mu(G) \leq \min_v \deg(v)\) folgt, weil das Isolieren des Knotens \(v\) mit kleinstem Grad einen gültigen Schnitt der Grösse \(\deg(v)\) liefert. Sie ist im Allgemeinen nicht scharf: es gibt Graphen mit \(\min \deg = 4\) und \(\mu = 3\).
Field-by-field Comparison
Field
Before
After
Text
In einem <b>Multigraphen</b> \(G = (V, E)\) ist der <b>Grad</b> \(\deg(v)\) eines Knoten \(v\) {{c1::die Anzahl inzidenter Kanten (<u>nicht</u> die Anzahl Nachbarn)}}. Es gelten\[\begin{gathered}|E| = {{c2::\tfrac{1}{2} \sum_{v \in V} \deg(v)}}, \\\mu(G) \leq {{c3::\min_{v \in V} \deg(v)}}.\end{gathered}\]
Extra
Die Schranke \(\mu(G) \leq \min_v \deg(v)\) folgt, weil das Isolieren des Knotens \(v\) mit kleinstem Grad einen gültigen Schnitt der Grösse \(\deg(v)\) liefert. Sie ist im Allgemeinen <b>nicht scharf</b>: es gibt Graphen mit \(\min \deg = 4\) und \(\mu = 3\).
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Wenn \(G\) ein bipartiter Graph ist und \(M\) ein Matching in \(G\) ist, das nicht kardinalitätsmaximal ist, dann gibt es in \(G\) einen augmentierenden Pfad bezüglich \(M\).
Modellierung Bildsegmentierung. Aus den Farben werden drei Einschätzungen extrahiert:
\(\alpha : P \to \mathbb{R}_0^{+}\): \(\alpha_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Vordergrund.
\(\beta : P \to \mathbb{R}_0^{+}\): \(\beta_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Hintergrund.
\(\gamma : E \to \mathbb{R}_0^{+}\): \(\gamma_e\) grösser \(\Rightarrow\) benachbarte Pixel eher im gleichen Teil.
Naiver Ansatz \(A := \{p : \alpha_p > \beta_p\}\), \(B := P \setminus A\) wird in vielen Fällen zu feinkörnig: deshalb braucht es die dritte Einschätzung \(\gamma\), die Nachbarschaft berücksichtigt.
Modellierung Bildsegmentierung. Aus den Farben werden drei Einschätzungen extrahiert:
\(\alpha : P \to \mathbb{R}_0^{+}\): \(\alpha_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Vordergrund.
\(\beta : P \to \mathbb{R}_0^{+}\): \(\beta_p\) grösser \(\Rightarrow\) Pixel \(p\) eher im Hintergrund.
\(\gamma : E \to \mathbb{R}_0^{+}\): \(\gamma_e\) grösser \(\Rightarrow\) benachbarte Pixel eher im gleichen Teil.
Naiver Ansatz \(A := \{p : \alpha_p > \beta_p\}\), \(B := P \setminus A\) wird in vielen Fällen zu feinkörnig: deshalb braucht es die dritte Einschätzung \(\gamma\), die Nachbarschaft berücksichtigt.
Field-by-field Comparison
Field
Before
After
Text
<b>Modellierung Bildsegmentierung.</b> Aus den Farben werden drei Einschätzungen extrahiert:<ul><li>\(\alpha : P \to \mathbb{R}_0^{+}\): {{c1::\(\alpha_p\) grösser \(\Rightarrow\)Pixel \(p\) eher im Vordergrund}}.</li><li>\(\beta : P \to \mathbb{R}_0^{+}\): {{c2::\(\beta_p\) grösser \(\Rightarrow\)Pixel \(p\) eher im Hintergrund}}.</li><li>\(\gamma : E \to \mathbb{R}_0^{+}\): {{c3::\(\gamma_e\) grösser \(\Rightarrow\)benachbarte Pixel eher im gleichen Teil}}.</li></ul>
<b>Modellierung Bildsegmentierung.</b> <br>Aus den Farben werden drei Einschätzungen extrahiert:<ul><li>\(\alpha : P \to \mathbb{R}_0^{+}\): \(\alpha_p\) grösser \(\Rightarrow\) {{c1::Pixel \(p\) eher im Vordergrund}}.</li><li>\(\beta : P \to \mathbb{R}_0^{+}\): \(\beta_p\) grösser \(\Rightarrow\) {{c1::Pixel \(p\) eher im Hintergrund}}.</li><li>\(\gamma : E \to \mathbb{R}_0^{+}\): \(\gamma_e\) grösser \(\Rightarrow\) {{c2::benachbarte Pixel eher im gleichen Teil}}.</li></ul>
Problem der kantendisjunkten Pfade. Gegeben ein Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\), bestimme eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade.
Problem der kantendisjunkten Pfade. Gegeben ein Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\), bestimme eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade.
Problem der kantendisjunkten Pfade. Gegeben ein Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\), bestimme eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade.
Problem der kantendisjunkten Pfade. Gegeben ein Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\), bestimme eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade.
Graph ist ungerichtet und ungewichtet.
Field-by-field Comparison
Field
Before
After
Text
<b>Problem der kantendisjunkten Pfade.</b> Gegeben ein {{c1::Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\)}}, bestimme {{c2::eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade}}.
<b>Problem der kantendisjunkten Pfade.</b> <br>Gegeben ein {{c1::Graph \(G\) mit zwei ausgezeichneten Knoten \(u \neq v\)}}, bestimme {{c1::eine möglichst grosse Menge kantendisjunkter \(u\)-\(v\)-Pfade}}.
Die Familie aller Stammfunktionen von \(f\) heisst unbestimmtes Integral und wird notiert als \[ \int f(x)\, dx. \] In diesem Kontext wird \(f\) der Integrand genannt.
Die Familie aller Stammfunktionen von \(f\) heisst unbestimmtes Integral und wird notiert als \[ \int f(x)\, dx. \] In diesem Kontext wird \(f\) der Integrand genannt.
Field-by-field Comparison
Field
Before
After
Text
Die Familie aller Stammfunktionen von \(f\) heisst {{c1::unbestimmtes Integral}} und wird notiert als \[ {{c2::\int f(x)\, dx}}. \] In diesem Kontext wird \(f\) der {{c3::Integrand}} genannt.
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent. Was gilt für \(\sum_{k\geq1} a_k^2\)?
konvergiert nicht notwendigerweise
konvergiert immer, aber nicht notwendigerweise absolut
konvergiert immer absolut
keine der obigen Aussagen trifft zu
(c) konvergiert immer absolut.
Da \(\sum a_k\) konvergiert, ist \((a_k)\) eine Nullfolge, also beschränkt: \(|a_k| \leq C\). Dann \(|a_k|^2 \leq C|a_k|\), und mit dem Vergleichssatz folgt aus der absoluten Konvergenz von \(\sum a_k\) die absolute Konvergenz von \(\sum a_k^2\).
Field-by-field Comparison
Field
Before
After
Front
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent. Was gilt für \(\sum_{k\geq1} a_k^2\)?<ol type="a"><li>konvergiert nicht notwendigerweise</li><li>konvergiert immer, aber nicht notwendigerweise absolut</li><li>konvergiert immer absolut</li><li>keine der obigen Aussagen trifft zu</li></ol>
Back
<b>(c)</b> konvergiert immer absolut.<br><br>Da \(\sum a_k\) konvergiert, ist \((a_k)\) eine Nullfolge, also beschränkt: \(|a_k| \leq C\). Dann \(|a_k|^2 \leq C|a_k|\), und mit dem Vergleichssatz folgt aus der absoluten Konvergenz von \(\sum a_k\) die absolute Konvergenz von \(\sum a_k^2\).
Theorie Grenzwerte IV (Nullfolge = Folge gegen \(0\)): Welche Aussagen sind wahr?<ol type="a"><li>Falls \((a_n)\) konvergiert, dann ist \((a_{n+1} - a_n)\) eine Nullfolge</li><li>Falls \((a_{n+1} - a_n)\) eine Nullfolge ist, konvergiert \((a_n)\)</li><li>Jede Nullfolge ist beschränkt</li></ol>
Back
<b>(a) und (c)</b> sind wahr.<br><br>(a): \(\lim a_{n+1} = \lim a_n\), also \(\lim(a_{n+1} - a_n) = 0\).<br>(c): Jede konvergente Folge ist beschränkt, unabhängig vom Grenzwert.<br><br>(b) ist falsch: \(a_n = \sum_{k=1}^n \tfrac{1}{k}\) erfüllt \(a_{n+1} - a_n \to 0\), divergiert aber.
Es gilt \((1+i)^2 = 1 + 2i + i^2 = 2i\), also \((1+i)^{2000} = \big((1+i)^2\big)^{1000} = (2i)^{1000}\).
Zudem \((2i)^{1000} = 2^{1000} i^{1000} = 2^{1000}(i^4)^{250} = 2^{1000}\). Der Betrag ist \(\sqrt{2}^{\,2000} = 2^{1000}\), was (a) und (e) ausschliesst.
Field-by-field Comparison
Field
Before
After
Front
Was ist \((1 + i)^{2000}\)?<ol type="a"><li>\(\sqrt{2}\,e^{500\pi i}\)</li><li>\(-2^{1000}\)</li><li>\((2i)^{1000}\)</li><li>\(2^{1000} e^{\pi i/4}\)</li><li>\(2^{2000}\)</li></ol>
Back
<b>(c)</b> \((2i)^{1000}\).<br><br>Es gilt \((1+i)^2 = 1 + 2i + i^2 = 2i\), also \((1+i)^{2000} = \big((1+i)^2\big)^{1000} = (2i)^{1000}\).<br><br>Zudem \((2i)^{1000} = 2^{1000} i^{1000} = 2^{1000}(i^4)^{250} = 2^{1000}\). Der Betrag ist \(\sqrt{2}^{\,2000} = 2^{1000}\), was (a) und (e) ausschliesst.
Sei \((f_n)_{n \in \mathbb{N}_0}\) eine Folge integrierbarer Funktionen \(f_n : [a,b] \to \mathbb{R}\), welche gleichmässig gegen \(f : [a,b] \to \mathbb{R}\) konvergiert. Dann ist auch \(f\) integrierbar und es gilt \[ \int_a^b f\, dx = {{c2::\lim_{n \to \infty} \int_a^b f_n\, dx}}. \]
Sei \((f_n)_{n \in \mathbb{N}_0}\) eine Folge integrierbarer Funktionen \(f_n : [a,b] \to \mathbb{R}\), welche gleichmässig gegen \(f : [a,b] \to \mathbb{R}\) konvergiert. Dann ist auch \(f\) integrierbar und es gilt \[ \int_a^b f\, dx = {{c2::\lim_{n \to \infty} \int_a^b f_n\, dx}}. \]
Integral und Limes dürfen vertauscht werden, sofern die Konvergenz gleichmässig ist. Bei punktweiser Konvergenz ist diese Vertauschung im Allgemeinen falsch.
Field-by-field Comparison
Field
Before
After
Text
Sei \((f_n)_{n \in \mathbb{N}_0}\) eine Folge integrierbarer Funktionen \(f_n : [a,b] \to \mathbb{R}\), welche {{c1::gleichmässig}} gegen \(f : [a,b] \to \mathbb{R}\) konvergiert. Dann ist auch \(f\) integrierbar und es gilt \[ \int_a^b f\, dx = {{c2::\lim_{n \to \infty} \int_a^b f_n\, dx}}. \]
Extra
Integral und Limes dürfen vertauscht werden, sofern die Konvergenz <i>gleichmässig</i> ist. Bei punktweiser Konvergenz ist diese Vertauschung im Allgemeinen falsch.
Sei \(I \subset \mathbb{R}\) ein Intervall und \(f : I \to \mathbb{R}\) eine Funktion. Eine differenzierbare Funktion \(F : I \to \mathbb{R}\) heisst Stammfunktion von \(f\) auf \(I\), falls \[ F'(x) = f(x) \quad \text{für alle } x \in I. \]
Sei \(I \subset \mathbb{R}\) ein Intervall und \(f : I \to \mathbb{R}\) eine Funktion. Eine differenzierbare Funktion \(F : I \to \mathbb{R}\) heisst Stammfunktion von \(f\) auf \(I\), falls \[ F'(x) = f(x) \quad \text{für alle } x \in I. \]
Das Bestimmen von \(F\) aus \(f\) nennt man (unbestimmte) Integration.
Field-by-field Comparison
Field
Before
After
Text
Sei \(I \subset \mathbb{R}\) ein Intervall und \(f : I \to \mathbb{R}\) eine Funktion. Eine differenzierbare Funktion \(F : I \to \mathbb{R}\) heisst {{c1::Stammfunktion}} von \(f\) auf \(I\), falls \[ {{c2::F'(x) = f(x)}} \quad \text{für alle } x \in I. \]
Extra
Das Bestimmen von \(F\) aus \(f\) nennt man (unbestimmte) <i>Integration</i>.
Welche Aussage ist wahr? (I) \(\forall z \in \mathbb{C} : |z|^2 = z^2\) (II) \(\forall z \in \mathbb{R} : |z|^2 = z^2\)
Beide
Nur die erste
Nur die zweite
(c) Nur die zweite.
Für \(z = u + iv\) gilt \(|z|^2 = u^2 + v^2\), aber \(z^2 = u^2 - v^2 + 2iuv\). Diese sind nur gleich, wenn \(v = 0\), also \(z\) reell ist.
Gegenbeispiel für (I): \(z = i\) liefert \(|i|^2 = 1\), aber \(i^2 = -1\).
Field-by-field Comparison
Field
Before
After
Front
Welche Aussage ist wahr?<br>(I) \(\forall z \in \mathbb{C} : |z|^2 = z^2\)<br>(II) \(\forall z \in \mathbb{R} : |z|^2 = z^2\)<ol type="a"><li>Beide</li><li>Nur die erste</li><li>Nur die zweite</li></ol>
Back
<b>(c)</b> Nur die zweite.<br><br>Für \(z = u + iv\) gilt \(|z|^2 = u^2 + v^2\), aber \(z^2 = u^2 - v^2 + 2iuv\). Diese sind nur gleich, wenn \(v = 0\), also \(z\) reell ist.<br><br>Gegenbeispiel für (I): \(z = i\) liefert \(|i|^2 = 1\), aber \(i^2 = -1\).
Sei \(S\) eine nichtleere, nach oben beschränkte Teilmenge von \(\mathbb{R}\) und \(a \in \mathbb{R}\) ihr Supremum. Welche Aussage gilt?
Für jedes \(\varepsilon > 0\) existiert eine obere Schranke \(b\) von \(S\) mit \(a - \varepsilon < b < a\)
\(a\) ist das Infimum der oberen Schranken
\(S \setminus \{a\}\) besitzt ein Maximum
(b) \(a\) ist das Infimum der oberen Schranken.
Das Supremum ist per Definition die kleinste obere Schranke, also gerade das Infimum der Menge aller oberen Schranken.
(a) ist falsch: Keine obere Schranke kann echt unterhalb von \(a\) liegen. (c) ist falsch im Allgemeinen: z.B. für \(S = \{1 - \tfrac{1}{n} : n \in \mathbb{N}\} \cup \{1\}\) hat \(S \setminus \{1\}\) kein Maximum.
Field-by-field Comparison
Field
Before
After
Front
Sei \(S\) eine nichtleere, nach oben beschränkte Teilmenge von \(\mathbb{R}\) und \(a \in \mathbb{R}\) ihr Supremum. Welche Aussage gilt?<ol type="a"><li>Für jedes \(\varepsilon > 0\) existiert eine obere Schranke \(b\) von \(S\) mit \(a - \varepsilon < b < a\)</li><li>\(a\) ist das Infimum der oberen Schranken</li><li>\(S \setminus \{a\}\) besitzt ein Maximum</li></ol>
Back
<b>(b)</b> \(a\) ist das Infimum der oberen Schranken.<br><br>Das Supremum ist per Definition die <b>kleinste obere Schranke</b>, also gerade das Infimum der Menge aller oberen Schranken.<br><br>(a) ist falsch: Keine obere Schranke kann echt unterhalb von \(a\) liegen.<br>(c) ist falsch im Allgemeinen: z.B. für \(S = \{1 - \tfrac{1}{n} : n \in \mathbb{N}\} \cup \{1\}\) hat \(S \setminus \{1\}\) kein Maximum.
Wie viele verschiedene Lösungen hat die Gleichung \(z^3 + 3z^2 - 4 = 0\)?
eine
zwei
drei
keine
(b) zwei.
Raten liefert \(z = 1\). Polynomdivision: \((z^3 + 3z^2 - 4)/(z-1) = z^2 + 4z + 4 = (z+2)^2\). Also ist \(z = -2\) eine doppelte Nullstelle. Verschiedene Lösungen: \(z = 1\) und \(z = -2\).
Field-by-field Comparison
Field
Before
After
Front
Wie viele <b>verschiedene</b> Lösungen hat die Gleichung \(z^3 + 3z^2 - 4 = 0\)?<ol type="a"><li>eine</li><li>zwei</li><li>drei</li><li>keine</li></ol>
Back
<b>(b)</b> zwei.<br><br>Raten liefert \(z = 1\). Polynomdivision: \((z^3 + 3z^2 - 4)/(z-1) = z^2 + 4z + 4 = (z+2)^2\). Also ist \(z = -2\) eine doppelte Nullstelle. Verschiedene Lösungen: \(z = 1\) und \(z = -2\).
Theorie Grenzwerte II: Seien \((a_n), (b_n), (c_n)\) Folgen mit \(c_n = a_n + b_n\). Welche Aussagen sind wahr?
Falls \(\lim c_n\) existiert, existieren auch \(\lim a_n\) und \(\lim b_n\), und \(\lim a_n + \lim b_n = \lim c_n\)
Falls \(\lim c_n\) und \(\lim b_n\) existieren, existiert auch \(\lim a_n\) und \(\lim a_n = \lim c_n - \lim b_n\)
Falls \((a_n)\) und \((b_n)\) beschränkt sind, muss auch \((c_n)\) beschränkt sein
Falls \((c_n)\) konvergiert, konvergiert mindestens eine der Folgen \((a_n), (b_n)\)
(b) und (c) sind wahr.
(b) folgt aus den Rechenregeln für Grenzwerte: \(a_n = c_n - b_n\). (c) folgt aus der Dreiecksungleichung.
(a) und (d) sind falsch: Gegenbeispiel \(a_n = -(-1)^n\), \(b_n = (-1)^n\). Dann ist \(c_n = 0\) konvergent, aber weder \((a_n)\) noch \((b_n)\) konvergiert.
Field-by-field Comparison
Field
Before
After
Front
Theorie Grenzwerte II: Seien \((a_n), (b_n), (c_n)\) Folgen mit \(c_n = a_n + b_n\). Welche Aussagen sind wahr?<ol type="a"><li>Falls \(\lim c_n\) existiert, existieren auch \(\lim a_n\) und \(\lim b_n\), und \(\lim a_n + \lim b_n = \lim c_n\)</li><li>Falls \(\lim c_n\) und \(\lim b_n\) existieren, existiert auch \(\lim a_n\) und \(\lim a_n = \lim c_n - \lim b_n\)</li><li>Falls \((a_n)\) und \((b_n)\) beschränkt sind, muss auch \((c_n)\) beschränkt sein</li><li>Falls \((c_n)\) konvergiert, konvergiert mindestens eine der Folgen \((a_n), (b_n)\)</li></ol>
Back
<b>(b) und (c)</b> sind wahr.<br><br>(b) folgt aus den Rechenregeln für Grenzwerte: \(a_n = c_n - b_n\).<br>(c) folgt aus der Dreiecksungleichung.<br><br>(a) und (d) sind falsch: Gegenbeispiel \(a_n = -(-1)^n\), \(b_n = (-1)^n\). Dann ist \(c_n = 0\) konvergent, aber weder \((a_n)\) noch \((b_n)\) konvergiert.
Geometrie von \(\mathbb{C}\): Welche Menge beschreibt die offene Kreisscheibe um \(0\) mit Radius \(2\) (die grüne Fläche in der Abbildung ohne den schwarzen Rand)?
Geometrie von \(\mathbb{C}\): Welche Menge beschreibt die offene Kreisscheibe um \(0\) mit Radius \(2\) (die grüne Fläche in der Abbildung ohne den schwarzen Rand)?
Die strikte Ungleichung \(|z| < 2\) liefert alle Punkte mit Abstand kleiner als \(2\) zum Ursprung (offene Scheibe).
(a) und (b) beschreiben Halbebenen; (d) beschreibt nur den Rand, die Kreislinie \(|z| = 2\).
Field-by-field Comparison
Field
Before
After
Front
Geometrie von \(\mathbb{C}\): <br>Welche Menge beschreibt die <b>offene</b> Kreisscheibe um \(0\) mit Radius \(2\) (die grüne Fläche in der Abbildung ohne den schwarzen Rand)?<br><br><img src="paste-c631adeeba5d5da3f6c5d0d9a53bd3dc45a9b475.jpg"><br><ol type="a"><li>\(\{z \in \mathbb{C} : \operatorname{Im}(z) < 2\}\)</li><li>\(\{z \in \mathbb{C} : \operatorname{Re}(z) > 3\}\)</li><li>\(\{z \in \mathbb{C} : |z| < 2\}\)</li><li>\(\{z \in \mathbb{C} : |z| = 2\}\)</li></ol>
Back
<b>(c)</b> \(\{z \in \mathbb{C} : |z| < 2\}\).<br><br>Die strikte Ungleichung \(|z| < 2\) liefert alle Punkte mit Abstand kleiner als \(2\) zum Ursprung (offene Scheibe).<br><br>(a) und (b) beschreiben Halbebenen; (d) beschreibt nur den Rand, die Kreislinie \(|z| = 2\).
(b) ist zu gross: enthält z.B. \(z = -7\) (dort \(\operatorname{Im} = 0 > -7\)), liegt aber nicht im Keil. (c) ist falsch: der Punkt \(z = i\) ist nicht enthalten. (d) ist zu gross: mit \(\geq\) enthielte es auch die Randgeraden.
Field-by-field Comparison
Field
Before
After
Front
Geometrie von \(\mathbb{C}\): <br>Betrachten Sie das Gebiet definiert durch den roten Teil des Bildes (ohne die blaue Linien).<br><img src="paste-daa7ae79e91ba9e8c682c6dca0ccb0de08214ebf.jpg"><br>Welche Menge ist das?<ol type="a"><li>\(\{z : \operatorname{Im}(z) > |\operatorname{Re}(z)|\}\)</li><li>\(\{z : \operatorname{Im}(z) > \operatorname{Re}(z)\}\)</li><li>\(\{z : \operatorname{Im}(z) \leq \operatorname{Re}(z)\}\)</li><li>\(\{z : \operatorname{Im}(z) \geq |\operatorname{Re}(z)|\}\)</li></ol>
Back
<b>(a)</b> \(\{z \in \mathbb{C} : \operatorname{Im}(z) > |\operatorname{Re}(z)|\}\).<br><br>(b) ist zu gross: enthält z.B. \(z = -7\) (dort \(\operatorname{Im} = 0 > -7\)), liegt aber nicht im Keil.<br>(c) ist falsch: der Punkt \(z = i\) ist nicht enthalten.<br>(d) ist zu gross: mit \(\geq\) enthielte es auch die Randgeraden.
Eulersche Formel: Was ist der Realteil von \(e^{-i}\)?
\(1\)
\(-1\)
\(\cos(1)\)
\(\sin(1)\)
(c) \(\cos(1)\).
Es gilt \(e^{-i} = \cos(-1) + i\sin(-1)\). Der Kosinus ist eine gerade Funktion, also \(\cos(-1) = \cos(1)\). Somit \(\operatorname{Re}(e^{-i}) = \cos(1)\).
Field-by-field Comparison
Field
Before
After
Front
Eulersche Formel: Was ist der Realteil von \(e^{-i}\)?<ol type="a"><li>\(1\)</li><li>\(-1\)</li><li>\(\cos(1)\)</li><li>\(\sin(1)\)</li></ol>
Back
<b>(c)</b> \(\cos(1)\).<br><br>Es gilt \(e^{-i} = \cos(-1) + i\sin(-1)\). Der Kosinus ist eine gerade Funktion, also \(\cos(-1) = \cos(1)\). Somit \(\operatorname{Re}(e^{-i}) = \cos(1)\).
Betrachte \(4z\bar{z} + (z - \bar{z})^2 = 3\). Welche Aussage trifft zu?
Diese Gleichung hat nur reelle Lösungen
Diese Gleichung hat nur Lösungen mit \(\operatorname{Re}(z) = 0\)
Diese Gleichung hat endlich viele Lösungen
Für \(z = x + iy\) lautet die Gleichung \(4x^2 - 3 = 0\)
(d) Für \(z = x + iy\) lautet die Gleichung \(4x^2 - 3 = 0\).
Einsetzen: \(4(x+iy)(x-iy) + (2iy)^2 = 4(x^2 + y^2) - 4y^2 = 4x^2\). Also \(4x^2 = 3\), unabhängig von \(y\). Das ergibt unendlich viele Lösungen (alle \(z\) mit \(\operatorname{Re}(z) = \pm\tfrac{\sqrt{3}}{2}\)), womit (a), (b), (c) falsch sind.
Field-by-field Comparison
Field
Before
After
Front
Betrachte \(4z\bar{z} + (z - \bar{z})^2 = 3\). Welche Aussage trifft zu?<ol type="a"><li>Diese Gleichung hat nur reelle Lösungen</li><li>Diese Gleichung hat nur Lösungen mit \(\operatorname{Re}(z) = 0\)</li><li>Diese Gleichung hat endlich viele Lösungen</li><li>Für \(z = x + iy\) lautet die Gleichung \(4x^2 - 3 = 0\)</li></ol>
Back
<b>(d)</b> Für \(z = x + iy\) lautet die Gleichung \(4x^2 - 3 = 0\).<br><br>Einsetzen: \(4(x+iy)(x-iy) + (2iy)^2 = 4(x^2 + y^2) - 4y^2 = 4x^2\). Also \(4x^2 = 3\), unabhängig von \(y\). Das ergibt unendlich viele Lösungen (alle \(z\) mit \(\operatorname{Re}(z) = \pm\tfrac{\sqrt{3}}{2}\)), womit (a), (b), (c) falsch sind.
Sei \(\sum_{n\geq0} c_n z^n\) eine Potenzreihe mit Konvergenzradius \(\varrho \in (0,\infty)\), und sei \(\varrho'\) der Konvergenzradius von \(\sum_{n\geq1} n c_n z^{n-1}\). Welche Aussage trifft zu?
Sei \(\sum_{n\geq0} c_n z^n\) eine Potenzreihe mit Konvergenzradius \(\varrho \in (0,\infty)\), und sei \(\varrho'\) der Konvergenzradius von \(\sum_{n\geq1} n c_n z^{n-1}\). Welche Aussage trifft zu?
\(\varrho > \varrho'\)
\(\varrho < \varrho'\)
\(\varrho = \varrho'\)
Es liegen nicht genügend Informationen vor
(c) \(\varrho = \varrho'\).
Für den Konvergenzradius macht der Faktor \(z^{n-1}\) vs. \(z^n\) keinen Unterschied. Es gilt \(\limsup_n \sqrt[n]{n|c_n|} = \lim_n \sqrt[n]{n} \cdot \limsup_n \sqrt[n]{|c_n|} = 1 \cdot \limsup_n \sqrt[n]{|c_n|}\), da \(\sqrt[n]{n} \to 1\). Also stimmen \(\varrho\) und \(\varrho'\) überein (gliedweises Ableiten ändert den Konvergenzradius nicht).
Field-by-field Comparison
Field
Before
After
Front
Sei \(\sum_{n\geq0} c_n z^n\) eine Potenzreihe mit Konvergenzradius \(\varrho \in (0,\infty)\), und sei \(\varrho'\) der Konvergenzradius von \(\sum_{n\geq1} n c_n z^{n-1}\). Welche Aussage trifft zu?<ol type="a"><li>\(\varrho > \varrho'\)</li><li>\(\varrho < \varrho'\)</li><li>\(\varrho = \varrho'\)</li><li>Es liegen nicht genügend Informationen vor</li></ol>
Back
<b>(c)</b> \(\varrho = \varrho'\).<br><br>Für den Konvergenzradius macht der Faktor \(z^{n-1}\) vs. \(z^n\) keinen Unterschied. Es gilt \(\limsup_n \sqrt[n]{n|c_n|} = \lim_n \sqrt[n]{n} \cdot \limsup_n \sqrt[n]{|c_n|} = 1 \cdot \limsup_n \sqrt[n]{|c_n|}\), da \(\sqrt[n]{n} \to 1\). Also stimmen \(\varrho\) und \(\varrho'\) überein (gliedweises Ableiten ändert den Konvergenzradius nicht).
Hauptsatz der Integral- und Differentialrechnung. Sei \(f : [a,b] \to \mathbb{R}\) stetig. Dann ist für jedes \(C \in \mathbb{R}\) die Funktion \[ F(x) := \int_a^x f(y)\, dy + C \] eine Stammfunktion von \(f\). Ausserdem ist jede Stammfunktion von dieser Form.
Hauptsatz der Integral- und Differentialrechnung. Sei \(f : [a,b] \to \mathbb{R}\) stetig. Dann ist für jedes \(C \in \mathbb{R}\) die Funktion \[ F(x) := \int_a^x f(y)\, dy + C \] eine Stammfunktion von \(f\). Ausserdem ist jede Stammfunktion von dieser Form.
Verbindet die beiden bisher getrennten Konzepte unbestimmtes Integral (Stammfunktion finden) und bestimmtes Integral (Flächenberechnung).
Field-by-field Comparison
Field
Before
After
Text
<b>Hauptsatz der Integral- und Differentialrechnung.</b><br>Sei \(f : [a,b] \to \mathbb{R}\) {{c1::stetig}}. Dann ist für jedes \(C \in \mathbb{R}\) die Funktion \[ F(x) := {{c2::\int_a^x f(y)\, dy + C}} \] eine {{c3::Stammfunktion}} von \(f\). Ausserdem ist jede Stammfunktion von dieser Form.
Extra
Verbindet die beiden bisher getrennten Konzepte <i>unbestimmtes Integral</i> (Stammfunktion finden) und <i>bestimmtes Integral</i> (Flächenberechnung).
Seien \(f, g : D \to \mathbb{R}\) monoton wachsend, \(D \subseteq \mathbb{R}\). Welche Aussage ist wahr?
\(f \cdot g\) ist monoton wachsend
Falls \(g(x) \neq 0\ \forall x\), ist \(\tfrac{f}{g}\) monoton wachsend
Falls \(f(x), g(x) \neq 0\ \forall x\), ist \(\tfrac{f}{g}\) oder \(\tfrac{g}{f}\) monoton wachsend
Alle obigen Aussagen sind falsch
(d) Alle obigen Aussagen sind falsch.
(a): Gegenbeispiel \(f(x) = g(x) = x\) auf \(D = \mathbb{R}\); dann ist \(f\cdot g = x^2\) nicht monoton. (b): \(f(x) = x,\ g(x) = x^2\) auf \((0,\infty)\) liefert \(\tfrac{f}{g} = \tfrac{1}{x}\), fallend. (c): Mit stückweise definierten \(f, g\) lassen sich \(\tfrac{f}{g}\) und \(\tfrac{g}{f}\) beide nicht-monoton machen.
Field-by-field Comparison
Field
Before
After
Front
Seien \(f, g : D \to \mathbb{R}\) monoton wachsend, \(D \subseteq \mathbb{R}\). Welche Aussage ist wahr?<ol type="a"><li>\(f \cdot g\) ist monoton wachsend</li><li>Falls \(g(x) \neq 0\ \forall x\), ist \(\tfrac{f}{g}\) monoton wachsend</li><li>Falls \(f(x), g(x) \neq 0\ \forall x\), ist \(\tfrac{f}{g}\) oder \(\tfrac{g}{f}\) monoton wachsend</li><li>Alle obigen Aussagen sind falsch</li></ol>
Back
<b>(d)</b> Alle obigen Aussagen sind falsch.<br><br>(a): Gegenbeispiel \(f(x) = g(x) = x\) auf \(D = \mathbb{R}\); dann ist \(f\cdot g = x^2\) nicht monoton.<br>(b): \(f(x) = x,\ g(x) = x^2\) auf \((0,\infty)\) liefert \(\tfrac{f}{g} = \tfrac{1}{x}\), fallend.<br>(c): Mit stückweise definierten \(f, g\) lassen sich \(\tfrac{f}{g}\) und \(\tfrac{g}{f}\) beide nicht-monoton machen.
Seien \(D \subset \mathbb{R}\), \((f_n)_{n \in \mathbb{N}_0}\) eine Folge von Funktionen \(f_n : D \to \mathbb{R}\) und \(f : D \to \mathbb{R}\).
Die Folge \((f_n)\) konvergiert punktweise gegen \(f\), falls {{c2::für jedes \(x \in D\) die reelle Folge \((f_n(x))_{n \in \mathbb{N}_0}\) gegen \(f(x)\) konvergiert}}.
Seien \(D \subset \mathbb{R}\), \((f_n)_{n \in \mathbb{N}_0}\) eine Folge von Funktionen \(f_n : D \to \mathbb{R}\) und \(f : D \to \mathbb{R}\).
Die Folge \((f_n)\) konvergiert punktweise gegen \(f\), falls {{c2::für jedes \(x \in D\) die reelle Folge \((f_n(x))_{n \in \mathbb{N}_0}\) gegen \(f(x)\) konvergiert}}.
\(f\) heisst dann punktweiser Grenzwert der Folge \((f_n)\). Quantorenreihenfolge: zuerst \(x\), dann \(N(\varepsilon, x)\).
Field-by-field Comparison
Field
Before
After
Text
Seien \(D \subset \mathbb{R}\), \((f_n)_{n \in \mathbb{N}_0}\) eine Folge von Funktionen \(f_n : D \to \mathbb{R}\) und \(f : D \to \mathbb{R}\). <br><br>Die Folge \((f_n)\) konvergiert {{c1::punktweise}} gegen \(f\), falls {{c2::für jedes \(x \in D\) die reelle Folge \((f_n(x))_{n \in \mathbb{N}_0}\) gegen \(f(x)\) konvergiert}}.
Extra
\(f\) heisst dann <i>punktweiser Grenzwert</i> der Folge \((f_n)\). Quantorenreihenfolge: zuerst \(x\), dann \(N(\varepsilon, x)\).
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent. Was gilt für \(\sum_{k\geq1} a_k b_k\)?
konvergiert nicht notwendigerweise
konvergiert immer, aber nicht notwendigerweise absolut
konvergiert immer absolut
(c) konvergiert immer absolut.
\((b_k)\) ist als Nullfolge beschränkt: \(|b_k| \leq C\). Dann \(|a_k b_k| \leq C|a_k|\), und mit dem Vergleichssatz folgt aus der absoluten Konvergenz von \(\sum a_k\) die absolute Konvergenz von \(\sum a_k b_k\).
Field-by-field Comparison
Field
Before
After
Front
Sei \(\sum_{k\geq1} a_k\) absolut konvergent und \(\sum_{k\geq1} b_k\) konvergent. Was gilt für \(\sum_{k\geq1} a_k b_k\)?<ol type="a"><li>konvergiert nicht notwendigerweise</li><li>konvergiert immer, aber nicht notwendigerweise absolut</li><li>konvergiert immer absolut</li></ol>
Back
<b>(c)</b> konvergiert immer absolut.<br><br>\((b_k)\) ist als Nullfolge beschränkt: \(|b_k| \leq C\). Dann \(|a_k b_k| \leq C|a_k|\), und mit dem Vergleichssatz folgt aus der absoluten Konvergenz von \(\sum a_k\) die absolute Konvergenz von \(\sum a_k b_k\).
Sei \(D \subset \mathbb{R}\) und \((f_n)_{n \in \mathbb{N}_0}\) eine Folge stetiger Funktionen \(f_n : D \to \mathbb{R}\), welche gleichmässig gegen \(f : D \to \mathbb{R}\) konvergiert. Dann ist auch \(f\) stetig.
Sei \(D \subset \mathbb{R}\) und \((f_n)_{n \in \mathbb{N}_0}\) eine Folge stetiger Funktionen \(f_n : D \to \mathbb{R}\), welche gleichmässig gegen \(f : D \to \mathbb{R}\) konvergiert. Dann ist auch \(f\) stetig.
Bei nur punktweiser Konvergenz gilt das im Allgemeinen nicht: z.B. \(f_n(x) = x^n\) auf \([0,1]\) konvergiert punktweise gegen eine unstetige Grenzfunktion.
Field-by-field Comparison
Field
Before
After
Text
Sei \(D \subset \mathbb{R}\) und \((f_n)_{n \in \mathbb{N}_0}\) eine Folge {{c1::stetiger}} Funktionen \(f_n : D \to \mathbb{R}\), welche {{c2::gleichmässig}} gegen \(f : D \to \mathbb{R}\) konvergiert. Dann ist auch \(f\) {{c1::stetig}}.
Extra
Bei nur punktweiser Konvergenz gilt das im Allgemeinen <b>nicht</b>: z.B. \(f_n(x) = x^n\) auf \([0,1]\) konvergiert punktweise gegen eine unstetige Grenzfunktion.
Falls der Grenzwert \[ \lim_{\substack{h \to 0 \\ h > 0}} \frac{f(a+h) - f(a)}{h} \]existiert, nennt man diesen die rechtsseitige Ableitung von \(f\) an der Stelle \(a\). Analog ist die linksseitige Ableitung definiert (mit \(h < 0\)).
Falls der Grenzwert \[ \lim_{\substack{h \to 0 \\ h > 0}} \frac{f(a+h) - f(a)}{h} \]existiert, nennt man diesen die rechtsseitige Ableitung von \(f\) an der Stelle \(a\). Analog ist die linksseitige Ableitung definiert (mit \(h < 0\)).
\(f\) ist an der Stelle \(a\) genau dann differenzierbar, wenn beide einseitigen Ableitungen existieren und übereinstimmen.
Falls der Grenzwert \[ \lim_{\substack{h \to 0 \\ h > 0}} \frac{f(a+h) - f(a)}{h} \]existiert, nennt man diesen die rechtsseitige Ableitung von \(f\) an der Stelle \(a\). Analog ist die linksseitige Ableitung definiert (mit \(h < 0\)).
Falls der Grenzwert \[ \lim_{\substack{h \to 0 \\ h > 0}} \frac{f(a+h) - f(a)}{h} \]existiert, nennt man diesen die rechtsseitige Ableitung von \(f\) an der Stelle \(a\). Analog ist die linksseitige Ableitung definiert (mit \(h < 0\)).
\(f\) ist an der Stelle \(a\) genau dann differenzierbar, wenn beide einseitigen Ableitungen existieren und übereinstimmen.
Field-by-field Comparison
Field
Before
After
Text
Falls der Grenzwert<br>\[ \lim_{\substack{h \to 0 \\ h > 0}} \frac{f(a+h) - f(a)}{h} \]existiert, nennt man diesen die {{c1::rechtsseitige Ableitung}} von \(f\) an der Stelle \(a\). Analog ist die {{c2::linksseitige Ableitung}} definiert (mit \(h < 0\)).
Falls der Grenzwert<br>\[ \lim_{\substack{h \to 0 \\ h > 0}} \frac{f(a+h) - f(a)}{h} \]existiert, nennt man diesen die {{c1::rechtsseitige Ableitung}} von \(f\) an der Stelle \(a\). Analog ist die {{c1::linksseitige Ableitung}} definiert (mit \(h < 0\)).
Es gibt konvergente Folgen, die nicht beschränkt sind
Eine divergente Folge ist nicht beschränkt
(a) Eine Folge kann höchstens einen Grenzwert haben (Eindeutigkeit des Grenzwerts).
(b) ist falsch: Jede konvergente Folge ist beschränkt. (c) ist falsch: \(a_n = (-1)^n\) ist beschränkt, aber divergent.
Field-by-field Comparison
Field
Before
After
Front
Theorie Grenzwerte I: Welche Aussage ist wahr?<ol type="a"><li>Eine Folge kann höchstens einen Grenzwert haben</li><li>Es gibt konvergente Folgen, die nicht beschränkt sind</li><li>Eine divergente Folge ist nicht beschränkt</li></ol>
Back
<b>(a)</b> Eine Folge kann höchstens einen Grenzwert haben (Eindeutigkeit des Grenzwerts).<br><br>(b) ist falsch: Jede konvergente Folge ist beschränkt.<br>(c) ist falsch: \(a_n = (-1)^n\) ist beschränkt, aber divergent.
Eine Stammfunktion ist nicht eindeutig: Ist \(F(x)\) eine Stammfunktion von \(f\), so ist auch \(F(x) + C\) für jede Konstante \(C \in \mathbb{R}\) eine Stammfunktion.
Eine Stammfunktion ist nicht eindeutig: Ist \(F(x)\) eine Stammfunktion von \(f\), so ist auch \(F(x) + C\) für jede Konstante \(C \in \mathbb{R}\) eine Stammfunktion.
Eine Funktion \(f\) besitzt also eine ganze Familie von Stammfunktionen, die sich nur um eine additive Konstante unterscheiden.
Field-by-field Comparison
Field
Before
After
Text
Eine Stammfunktion ist {{c1::nicht eindeutig}}: <br>Ist \(F(x)\) eine Stammfunktion von \(f\), so ist auch \({{c2::F(x) + C}}\) für jede Konstante \(C \in \mathbb{R}\) eine Stammfunktion.
Extra
Eine Funktion \(f\) besitzt also eine ganze <i>Familie</i> von Stammfunktionen, die sich nur um eine additive Konstante unterscheiden.
Ist \(f\) z.B. monoton fallend, so gilt \(f(1) \leq f(y) \leq f(0)\) für alle \(y \in [0,1]\), also \(f(y) \in [f(1), f(0)]\) - beschränkt.
(a) falsch: \(f(x) = |x - 1|\) ist beschränkt, nicht monoton. (b) falsch: kann einen Sprung haben. (c) falsch: \(\ln : (0,1] \to \mathbb{R}\) ist monoton, aber nicht beschränkt.
<b>(d)</b> \(f : [0,1] \to \mathbb{R}\) monoton \(\Rightarrow f\) beschränkt.<br><br>Ist \(f\) z.B. monoton fallend, so gilt \(f(1) \leq f(y) \leq f(0)\) für alle \(y \in [0,1]\), also \(f(y) \in [f(1), f(0)]\) - beschränkt.<br><br>(a) falsch: \(f(x) = |x - 1|\) ist beschränkt, nicht monoton.<br>(b) falsch: kann einen Sprung haben.<br>(c) falsch: \(\ln : (0,1] \to \mathbb{R}\) ist monoton, aber nicht beschränkt.
Integration durch Substitution. Mit \(y = g(x)\) gilt:\[ \int f'(g(x))\, g'(x)\, dx = {{c1::\int \frac{df}{dy}\, dy}} = f(g(x)) + C. \]
Herleitung: Aus der Kettenregel folgt \(\tfrac{d}{dx} f(g(x)) = f'(g(x)) \cdot g'(x)\). Beidseitiges Integrieren und formale Substitution \(dy = g'(x)\, dx\) führen auf die Formel. Substitution ist die Umkehrung der Kettenregel.
<i>Herleitung:</i> Aus der Kettenregel folgt \(\tfrac{d}{dx} f(g(x)) = f'(g(x)) \cdot g'(x)\). Beidseitiges Integrieren und formale Substitution \(dy = g'(x)\, dx\) führen auf die Formel.<br>Substitution ist die Umkehrung der Kettenregel.
Nach der Eulerschen Formel ist \(e^{i} = \cos(1) + i\sin(1)\) (Argument im Bogenmass). Auf vier Nachkommastellen: \(\cos(1) \approx 0.5403\), \(\sin(1) \approx 0.8414\).
(c) entspräche \(\cos\) und \(\sin\) von \(1°\); (d) hat Real- und Imaginärteil vertauscht.
<b>(b)</b> \(0.5403 + i\,0.8414\).<br><br>Nach der Eulerschen Formel ist \(e^{i} = \cos(1) + i\sin(1)\) (Argument im Bogenmass). Auf vier Nachkommastellen: \(\cos(1) \approx 0.5403\), \(\sin(1) \approx 0.8414\).<br><br>(c) entspräche \(\cos\) und \(\sin\) von \(1°\); (d) hat Real- und Imaginärteil vertauscht.
Sei \(f : [a,b] \to \mathbb{R}\) eine Funktion und \(\mathcal{TF}\) die Menge der Treppenfunktionen auf \([a,b]\). Die Menge der Obersummen ist \[ U(f) := \Bigl\{ \int_a^b s(x)\, dx \,\Big|\, s \in \mathcal{TF},\, s \geq f \Bigr\}, \] die Menge der Untersummen ist \[ L(f) := \Bigl\{ \int_a^b s(x)\, dx \,\Big|\, s \in \mathcal{TF},\, s \leq f \Bigr\}. \]
Sei \(f : [a,b] \to \mathbb{R}\) eine Funktion und \(\mathcal{TF}\) die Menge der Treppenfunktionen auf \([a,b]\). Die Menge der Obersummen ist \[ U(f) := \Bigl\{ \int_a^b s(x)\, dx \,\Big|\, s \in \mathcal{TF},\, s \geq f \Bigr\}, \] die Menge der Untersummen ist \[ L(f) := \Bigl\{ \int_a^b s(x)\, dx \,\Big|\, s \in \mathcal{TF},\, s \leq f \Bigr\}. \]
Obersummen approximieren die Fläche unter \(f\) von oben durch Treppenfunktionen, die \(f\) majorisieren, Untersummen von unten durch minorisierende Treppenfunktionen.
Field-by-field Comparison
Field
Before
After
Text
Sei \(f : [a,b] \to \mathbb{R}\) eine Funktion und \(\mathcal{TF}\) die Menge der Treppenfunktionen auf \([a,b]\). Die Menge der {{c1::Obersummen}} ist \[ U(f) := \Bigl\{ \int_a^b s(x)\, dx \,\Big|\, s \in \mathcal{TF},\, {{c2::s \geq f}} \Bigr\}, \] die Menge der {{c1::Untersummen}} ist \[ L(f) := \Bigl\{ \int_a^b s(x)\, dx \,\Big|\, s \in \mathcal{TF},\, {{c2::s \leq f}} \Bigr\}. \]
Extra
Obersummen approximieren die Fläche unter \(f\) <i>von oben</i> durch Treppenfunktionen, die \(f\) majorisieren, Untersummen <i>von unten</i> durch minorisierende Treppenfunktionen.
\(\sum a_n\) konvergiert, falls die Folge \((S_m)\) der Partialsummen \(S_m = \sum_{n=1}^m a_n\) konvergiert
Falls \(\sum b_n\) konvergent ist mit \(0 \leq b_n \leq a_n\), dann konvergiert \(\sum a_n\)
(b) ist richtig - das ist gerade die Definition der Konvergenz einer Reihe.
(a) ist falsch: \(\sum \tfrac{1}{n}\) (harmonische Reihe) divergiert trotz \(a_n \to 0\). (c) ist falsch: z.B. \(b_n = \tfrac{1}{2^n}\), \(a_n = 1\); dann \(0 \leq b_n \leq a_n\) und \(\sum b_n\) konvergiert, aber \(\sum a_n\) divergiert (die Abschätzung läuft in die falsche Richtung).
Field-by-field Comparison
Field
Before
After
Front
Sei \(\sum_{n=1}^{\infty} a_n\) eine Reihe. Welche Aussagen sind richtig?<ol type="a"><li>\(\sum a_n\) konvergiert, falls \(\lim_{n\to\infty} a_n = 0\)</li><li>\(\sum a_n\) konvergiert, falls die Folge \((S_m)\) der Partialsummen \(S_m = \sum_{n=1}^m a_n\) konvergiert</li><li>Falls \(\sum b_n\) konvergent ist mit \(0 \leq b_n \leq a_n\), dann konvergiert \(\sum a_n\)</li></ol>
Back
<b>(b)</b> ist richtig - das ist gerade die Definition der Konvergenz einer Reihe.<br><br>(a) ist falsch: \(\sum \tfrac{1}{n}\) (harmonische Reihe) divergiert trotz \(a_n \to 0\).<br>(c) ist falsch: z.B. \(b_n = \tfrac{1}{2^n}\), \(a_n = 1\); dann \(0 \leq b_n \leq a_n\) und \(\sum b_n\) konvergiert, aber \(\sum a_n\) divergiert (die Abschätzung läuft in die falsche Richtung).
Die Folge \((f_n)_{n \in \mathbb{N}_0}\) mit \(f_n : D \to \mathbb{R}\) konvergiert gleichmässig gegen \(f : D \to \mathbb{R}\), falls für jedes \(\varepsilon > 0\) ein Index \(N\) existiert, sodass für alle \(n \geq N\) und alle \(x \in D\) gilt \[ |f_n(x) - f(x)| < \varepsilon. \]
Die Folge \((f_n)_{n \in \mathbb{N}_0}\) mit \(f_n : D \to \mathbb{R}\) konvergiert gleichmässig gegen \(f : D \to \mathbb{R}\), falls für jedes \(\varepsilon > 0\) ein Index \(N\) existiert, sodass für alle \(n \geq N\) und alle \(x \in D\) gilt \[ |f_n(x) - f(x)| < \varepsilon. \]
Entscheidender Unterschied zur punktweisen Konvergenz: \(N\) hängt nicht von \(x\) ab, sondern gilt uniform für alle \(x \in D\) gleichzeitig.
Field-by-field Comparison
Field
Before
After
Text
Die Folge \((f_n)_{n \in \mathbb{N}_0}\) mit \(f_n : D \to \mathbb{R}\) konvergiert {{c1::gleichmässig}} gegen \(f : D \to \mathbb{R}\), falls {{c2::für jedes \(\varepsilon > 0\) ein Index \(N\) existiert, sodass für alle \(n \geq N\) und alle \(x \in D\) gilt \[ |f_n(x) - f(x)| < \varepsilon. \] }}
Extra
Entscheidender Unterschied zur punktweisen Konvergenz: \(N\) hängt <b>nicht</b> von \(x\) ab, sondern gilt <i>uniform</i> für alle \(x \in D\) gleichzeitig.
Definitionsbereich: Die Funktion \(\ln(|\cos x|)\) ist definiert für
\(0 \leq x < \tfrac{\pi}{2}\)
\(0 \leq x \leq \tfrac{\pi}{2}\)
alle reellen \(x\) ausser \(x = \tfrac{\pi}{2} + 2k\pi,\ k \in \mathbb{Z}\)
(a) \(0 \leq x < \tfrac{\pi}{2}\).
\(\ln y\) ist nur für \(y > 0\) definiert. Nun ist \(|\cos x| \geq 0\) und verschwindet genau für \(x = \tfrac{\pi}{2} + k\pi,\ k \in \mathbb{Z}\). Keine solche Zahl liegt in \([0, \tfrac{\pi}{2})\).
(b) ist falsch: bei \(x = \tfrac{\pi}{2}\) ist \(\cos x = 0\), also \(\ln(|\cos x|)\) undefiniert. (c) ist falsch: \(|\cos x|\) verschwindet bei allen \(\tfrac{\pi}{2} + k\pi\), nicht nur bei \(\tfrac{\pi}{2} + 2k\pi\).
Field-by-field Comparison
Field
Before
After
Front
Definitionsbereich: Die Funktion \(\ln(|\cos x|)\) ist definiert für<ol type="a"><li>\(0 \leq x < \tfrac{\pi}{2}\)</li><li>\(0 \leq x \leq \tfrac{\pi}{2}\)</li><li>alle reellen \(x\) ausser \(x = \tfrac{\pi}{2} + 2k\pi,\ k \in \mathbb{Z}\)</li></ol>
Back
<b>(a)</b> \(0 \leq x < \tfrac{\pi}{2}\).<br><br>\(\ln y\) ist nur für \(y > 0\) definiert. Nun ist \(|\cos x| \geq 0\) und verschwindet genau für \(x = \tfrac{\pi}{2} + k\pi,\ k \in \mathbb{Z}\). Keine solche Zahl liegt in \([0, \tfrac{\pi}{2})\).<br><br>(b) ist falsch: bei \(x = \tfrac{\pi}{2}\) ist \(\cos x = 0\), also \(\ln(|\cos x|)\) undefiniert.<br>(c) ist falsch: \(|\cos x|\) verschwindet bei allen \(\tfrac{\pi}{2} + k\pi\), nicht nur bei \(\tfrac{\pi}{2} + 2k\pi\).
Wie viele verschiedene Lösungen hat die Gleichung \(z^2 + 4z + 4 = 0\)?
eine
zwei
keine
(a) eine.
Es gilt \(z^2 + 4z + 4 = (z+2)^2 = 0\), also \(z = -2\) (doppelte Nullstelle). Die Diskriminante \(b^2 - 4ac = 16 - 16 = 0\) verschwindet, daher genau eine verschiedene Lösung.
Field-by-field Comparison
Field
Before
After
Front
Wie viele <b>verschiedene</b> Lösungen hat die Gleichung \(z^2 + 4z + 4 = 0\)?<ol type="a"><li>eine</li><li>zwei</li><li>keine</li></ol>
Back
<b>(a)</b> eine.<br><br>Es gilt \(z^2 + 4z + 4 = (z+2)^2 = 0\), also \(z = -2\) (doppelte Nullstelle). Die Diskriminante \(b^2 - 4ac = 16 - 16 = 0\) verschwindet, daher genau eine verschiedene Lösung.
Mittelwertsatz der Integralrechnung. Ist \(f : [a,b] \to \mathbb{R}\) stetig, so existiert ein \(c \in [a,b]\) mit \[ f(c) = {{c3::\frac{1}{b-a} \int_a^b f(x)\, dx}}. \]
Mittelwertsatz der Integralrechnung. Ist \(f : [a,b] \to \mathbb{R}\) stetig, so existiert ein \(c \in [a,b]\) mit \[ f(c) = {{c3::\frac{1}{b-a} \int_a^b f(x)\, dx}}. \]
Der Ausdruck \(\tfrac{1}{b-a} \int_a^b f(x)\, dx\) ist der Mittelwert von \(f\) über \([a,b]\). Beweis-Idee: Zwischenwertsatz angewandt auf \(f\) zwischen Minimum und Maximum auf \([a,b]\).
Field-by-field Comparison
Field
Before
After
Text
<b>Mittelwertsatz der Integralrechnung.</b><br>Ist \(f : [a,b] \to \mathbb{R}\) {{c1::stetig}}, so existiert ein {{c2::\(c \in [a,b]\)}} mit \[ f(c) = {{c3::\frac{1}{b-a} \int_a^b f(x)\, dx}}. \]
Extra
Der Ausdruck \(\tfrac{1}{b-a} \int_a^b f(x)\, dx\) ist der <i>Mittelwert</i> von \(f\) über \([a,b]\). <br>Beweis-Idee: Zwischenwertsatz angewandt auf \(f\) zwischen Minimum und Maximum auf \([a,b]\).
Eine Teilfolge bzw. Umordnung einer absolut konvergenten Reihe ist wieder absolut konvergent.
(a), (b), (c) sind falsch: Für nur konvergente (nicht absolut konvergente) Reihen oder bei blosser Surjektivität kann man durch Umordnung/Wiederholung von Gliedern Divergenz erzeugen.
Field-by-field Comparison
Field
Before
After
Front
Sei \(\varphi : \mathbb{N}^* \to \mathbb{N}^*\) eine Abbildung, \(\sum a_n\) eine Reihe und \(b_n = a_{\varphi(n)}\). Welche Aussage ist korrekt?<ol type="a"><li>\(\sum a_n\) konvergent und \(\varphi\) surjektiv \(\Rightarrow \sum b_n\) konvergent</li><li>\(\sum a_n\) konvergent und \(\varphi\) injektiv \(\Rightarrow \sum b_n\) konvergent</li><li>\(\sum a_n\) absolut konvergent und \(\varphi\) surjektiv \(\Rightarrow \sum b_n\) konvergent</li><li>\(\sum a_n\) absolut konvergent und \(\varphi\) injektiv \(\Rightarrow \sum b_n\) konvergent</li></ol>
Back
<b>(d)</b> \(\sum a_n\) absolut konvergent und \(\varphi\) injektiv \(\Rightarrow \sum b_n\) konvergent.<br><br>Eine Teilfolge bzw. Umordnung einer absolut konvergenten Reihe ist wieder absolut konvergent.<br><br>(a), (b), (c) sind falsch: Für nur konvergente (nicht absolut konvergente) Reihen oder bei blosser Surjektivität kann man durch Umordnung/Wiederholung von Gliedern Divergenz erzeugen.
Sei \((x_n)\) eine Cauchy-Folge in \(\mathbb{R}\). Dann
konvergiert \(\sum_{n=1}^{\infty} \sqrt{x_n}\)
kann \((x_n)\) unbeschränkt sein
gibt es zu jedem \(\varepsilon > 0\) ein \(N \in \mathbb{N}\), so dass \(|x_m - x_n| < \varepsilon\) für alle \(m, n > N\)
(c) ist richtig - das ist die Definition einer Cauchy-Folge.
(a) ist falsch: z.B. \(x_n = 1/n^2\) ist Cauchy, aber \(\sum 1/n\) divergiert. (b) ist falsch: Jede Cauchy-Folge in \(\mathbb{R}\) konvergiert, ist also beschränkt.
Field-by-field Comparison
Field
Before
After
Front
Sei \((x_n)\) eine Cauchy-Folge in \(\mathbb{R}\). Dann<ol type="a"><li>konvergiert \(\sum_{n=1}^{\infty} \sqrt{x_n}\)</li><li>kann \((x_n)\) unbeschränkt sein</li><li>gibt es zu jedem \(\varepsilon > 0\) ein \(N \in \mathbb{N}\), so dass \(|x_m - x_n| < \varepsilon\) für alle \(m, n > N\)</li></ol>
Back
<b>(c)</b> ist richtig - das ist die Definition einer Cauchy-Folge.<br><br>(a) ist falsch: z.B. \(x_n = 1/n^2\) ist Cauchy, aber \(\sum 1/n\) divergiert.<br>(b) ist falsch: Jede Cauchy-Folge in \(\mathbb{R}\) konvergiert, ist also beschränkt.
Integraldarstellung über Ableitung Sei \(F : [a,b] \to \mathbb{R}\) stetig differenzierbar. Dann gilt für alle \(x \in [a,b]\) \[ F(x) = F(a) + \int_a^x F'(t)\, dt. \]
Integraldarstellung über Ableitung Sei \(F : [a,b] \to \mathbb{R}\) stetig differenzierbar. Dann gilt für alle \(x \in [a,b]\) \[ F(x) = F(a) + \int_a^x F'(t)\, dt. \]
Jede stetig differenzierbare Funktion lässt sich als Anfangswert plus Integral über ihre Ableitung schreiben. Folgt direkt aus dem Hauptsatz angewandt auf \(f = F'\).
Field-by-field Comparison
Field
Before
After
Text
<b>Integraldarstellung über Ableitung</b><br>Sei \(F : [a,b] \to \mathbb{R}\) {{c1::stetig differenzierbar}}. Dann gilt für alle \(x \in [a,b]\) \[ F(x) = {{c2::F(a) + \int_a^x F'(t)\, dt}}. \]
Extra
Jede stetig differenzierbare Funktion lässt sich als Anfangswert plus Integral über ihre Ableitung schreiben. Folgt direkt aus dem Hauptsatz angewandt auf \(f = F'\).
Für \(n \geq 2\) sei \(a_n := \left(\tfrac{1}{n}\right)^{1/\log(n^2)}\) und \(L := \lim_n a_n\). Welche Aussage ist korrekt?
\(L\) existiert nicht
\(L\) existiert und es gilt \(0 < L < +\infty\)
\(L\) existiert und es gilt \(L = +\infty\)
\(L\) existiert und es gilt \(L = 0\)
(b) \(L\) existiert und \(0 < L < +\infty\).
Es gilt \(a_n = \exp\!\left(-\tfrac{\log n}{\log(n^2)}\right) = \exp\!\left(-\tfrac{1}{2}\right)\), denn \(\log(n^2) = 2\log n\). Die Folge ist also konstant gleich \(e^{-1/2}\).
Field-by-field Comparison
Field
Before
After
Front
Für \(n \geq 2\) sei \(a_n := \left(\tfrac{1}{n}\right)^{1/\log(n^2)}\) und \(L := \lim_n a_n\). Welche Aussage ist korrekt?<ol type="a"><li>\(L\) existiert nicht</li><li>\(L\) existiert und es gilt \(0 < L < +\infty\)</li><li>\(L\) existiert und es gilt \(L = +\infty\)</li><li>\(L\) existiert und es gilt \(L = 0\)</li></ol>
Back
<b>(b)</b> \(L\) existiert und \(0 < L < +\infty\).<br><br>Es gilt \(a_n = \exp\!\left(-\tfrac{\log n}{\log(n^2)}\right) = \exp\!\left(-\tfrac{1}{2}\right)\), denn \(\log(n^2) = 2\log n\). Die Folge ist also konstant gleich \(e^{-1/2}\).
Falls \(a_n \leq a\ \forall n\) und \(a_{n+1} \geq a_n\ \forall n\), ist \((a_n)\) konvergent
(b) und (d) sind wahr.
(b): \(b_n \to 2a\) nach Rechenregeln. (d): Monotone und beschränkte Folgen konvergieren.
(a) ist falsch: \(a = 0\), \(a_n = (-1)^n\), \(\varepsilon = 2\). (c) ist falsch: \(a_n = \sum_{k=1}^n \tfrac{1}{k}\) erfüllt \(b_n = \tfrac{1}{n+1} \to 0\), divergiert aber (harmonische Reihe).
Field-by-field Comparison
Field
Before
After
Front
Theorie Grenzwerte III: Sei \((a_n)\) eine Folge in \(\mathbb{R}\). Welche Aussagen sind wahr?<ol type="a"><li>Falls \(\varepsilon > 0\) und \(a \in \mathbb{R}\) existieren mit \(|a_n - a| < \varepsilon\ \forall n \geq 1\), dann konvergiert \((a_n)\)</li><li>Falls \((a_n)\) konvergiert, ist \(b_n := a_{n+1} + a_n\) konvergent</li><li>Falls \(b_n := a_{n+1} - a_n \to 0\), ist \((a_n)\) konvergent</li><li>Falls \(a_n \leq a\ \forall n\) und \(a_{n+1} \geq a_n\ \forall n\), ist \((a_n)\) konvergent</li></ol>
Back
<b>(b) und (d)</b> sind wahr.<br><br>(b): \(b_n \to 2a\) nach Rechenregeln.<br>(d): Monotone und beschränkte Folgen konvergieren.<br><br>(a) ist falsch: \(a = 0\), \(a_n = (-1)^n\), \(\varepsilon = 2\).<br>(c) ist falsch: \(a_n = \sum_{k=1}^n \tfrac{1}{k}\) erfüllt \(b_n = \tfrac{1}{n+1} \to 0\), divergiert aber (harmonische Reihe).
Beim Schritt \(2x = x(x-1) \Leftrightarrow 2 = x-1\) wird durch \(x\) geteilt. Das ist nur erlaubt, falls \(x \neq 0\). Das Kürzen unterschlägt die Lösung \(x = 0\), also gilt keine Äquivalenz.
Welches Äquivalenzzeichen ist falsch?<br><br>\(2x = x(x-1)\)<ol type="a"><li>\(\Leftrightarrow 2 = x - 1\)</li><li>\(\Leftrightarrow 3 = x\)</li></ol>
Back
<b>(a)</b> ist falsch.<br><br>Beim Schritt \(2x = x(x-1) \Leftrightarrow 2 = x-1\) wird durch \(x\) geteilt. Das ist nur erlaubt, falls \(x \neq 0\). Das Kürzen unterschlägt die Lösung \(x = 0\), also gilt keine Äquivalenz.<br><br>(b) \(2 = x-1 \Leftrightarrow 3 = x\) ist hingegen korrekt.
Die Aufteilungsregel erlaubt es, abschnittsweise definierte Funktionen stückweise zu integrieren. Die Umkehrungsregel macht die Definition von \(\int_a^b\) auch für \(a > b\) sinnvoll.
Die Aufteilungsregel erlaubt es, abschnittsweise definierte Funktionen stückweise zu integrieren. Die Umkehrungsregel macht die Definition von \(\int_a^b\) auch für \(a > b\) sinnvoll.
Sei \(f : [a,b] \to \mathbb{R}\) eine Treppenfunktion bezüglich der Zerlegung \(a = x_0 < \cdots < x_n = b\), wobei \(c_k\) der Funktionswert von \(f\) auf \((x_{k-1}, x_k)\) sei. Dann ist das Integral der Treppenfunktion definiert als \[ \int_a^b f(x)\, dx := {{c1::\sum_{k=1}^{n} c_k\, (x_k - x_{k-1})}}. \]
Sei \(f : [a,b] \to \mathbb{R}\) eine Treppenfunktion bezüglich der Zerlegung \(a = x_0 < \cdots < x_n = b\), wobei \(c_k\) der Funktionswert von \(f\) auf \((x_{k-1}, x_k)\) sei. Dann ist das Integral der Treppenfunktion definiert als \[ \int_a^b f(x)\, dx := {{c1::\sum_{k=1}^{n} c_k\, (x_k - x_{k-1})}}. \]
Anschaulich: Summe der vorzeichenbehafteten Rechteckflächen \(c_k \cdot \text{Breite}\) über jedem Teilintervall.
Field-by-field Comparison
Field
Before
After
Text
Sei \(f : [a,b] \to \mathbb{R}\) eine Treppenfunktion bezüglich der Zerlegung \(a = x_0 < \cdots < x_n = b\), wobei \(c_k\) der Funktionswert von \(f\) auf \((x_{k-1}, x_k)\) sei. <br>Dann ist das <i>Integral der Treppenfunktion</i> definiert als \[ \int_a^b f(x)\, dx := {{c1::\sum_{k=1}^{n} c_k\, (x_k - x_{k-1})}}. \]
Extra
Anschaulich: Summe der vorzeichenbehafteten Rechteckflächen \(c_k \cdot \text{Breite}\) über jedem Teilintervall.
Was ist das grösste Intervall, welches \(1\) enthält und auf welchem \(\sin x\) bijektiv auf das Bild ist?
\([-\pi, \pi]\)
\([0, \pi]\)
\([0, \tfrac{\pi}{2}]\)
\([-1, \tfrac{\pi}{2}]\)
\([-\tfrac{\pi}{2}, \tfrac{\pi}{2}]\)
(e) \([-\tfrac{\pi}{2}, \tfrac{\pi}{2}]\).
An der Stelle \(x = 1 < \tfrac{\pi}{2}\) ist \(\sin x\) strikt monoton steigend. Das grösste Intervall um \(x=1\), auf dem \(\sin x\) monoton (und damit injektiv) ist, ist \([-\tfrac{\pi}{2}, \tfrac{\pi}{2}]\): die Grenzen sind Minimal- bzw. Maximalstelle. Eine Funktion ist genau dann injektiv, wenn sie bijektiv auf ihr Bild abbildet.
(a), (b) sind nicht injektiv; (c), (d) sind injektiv, aber nicht das grösste solche Intervall.
Field-by-field Comparison
Field
Before
After
Front
Was ist das grösste Intervall, welches \(1\) enthält und auf welchem \(\sin x\) bijektiv auf das Bild ist?<ol type="a"><li>\([-\pi, \pi]\)</li><li>\([0, \pi]\)</li><li>\([0, \tfrac{\pi}{2}]\)</li><li>\([-1, \tfrac{\pi}{2}]\)</li><li>\([-\tfrac{\pi}{2}, \tfrac{\pi}{2}]\)</li></ol>
Back
<b>(e)</b> \([-\tfrac{\pi}{2}, \tfrac{\pi}{2}]\).<br><br>An der Stelle \(x = 1 < \tfrac{\pi}{2}\) ist \(\sin x\) strikt monoton steigend. Das grösste Intervall um \(x=1\), auf dem \(\sin x\) monoton (und damit injektiv) ist, ist \([-\tfrac{\pi}{2}, \tfrac{\pi}{2}]\): die Grenzen sind Minimal- bzw. Maximalstelle. Eine Funktion ist genau dann injektiv, wenn sie bijektiv auf ihr Bild abbildet.<br><br>(a), (b) sind nicht injektiv; (c), (d) sind injektiv, aber nicht das grösste solche Intervall.
Folgenkonvergenz II: Welche Aussagen sind richtig?
Ist \((q_n)\) eine Folge rationaler Zahlen mit \(|q_n - q_{n+1}| \to 0\), dann ist \((q_n)\) eine Cauchy-Folge
Ist \((a_n)\) konvergent und \(\sigma\) eine Permutation von \(\{1,2,3,\dots\}\), dann konvergiert auch \((b_n)\) mit \(b_n = a_{\sigma(n)}\)
(b) ist richtig.
Ist \(\alpha = \lim a_n\), so gilt für \(n \geq n_\varepsilon\) stets \(|\alpha - a_n| \leq \varepsilon\). Mit \(m = \max\{k : \sigma(k) \leq n_\varepsilon\}\) folgt \(|\alpha - b_n| \leq \varepsilon\) für \(n \geq m\). Also \(\lim b_n = \alpha\).
(a) ist falsch: \(q_n = \sum_{k=1}^n \tfrac{1}{k}\) erfüllt \(|q_n - q_{n+1}| \to 0\), ist aber keine Cauchy-Folge (denn \(q_{2n} - q_n \geq \tfrac{1}{2}\)).
Field-by-field Comparison
Field
Before
After
Front
Folgenkonvergenz II: Welche Aussagen sind richtig?<ol type="a"><li>Ist \((q_n)\) eine Folge rationaler Zahlen mit \(|q_n - q_{n+1}| \to 0\), dann ist \((q_n)\) eine Cauchy-Folge</li><li>Ist \((a_n)\) konvergent und \(\sigma\) eine Permutation von \(\{1,2,3,\dots\}\), dann konvergiert auch \((b_n)\) mit \(b_n = a_{\sigma(n)}\)</li></ol>
Back
<b>(b)</b> ist richtig.<br><br>Ist \(\alpha = \lim a_n\), so gilt für \(n \geq n_\varepsilon\) stets \(|\alpha - a_n| \leq \varepsilon\). Mit \(m = \max\{k : \sigma(k) \leq n_\varepsilon\}\) folgt \(|\alpha - b_n| \leq \varepsilon\) für \(n \geq m\). Also \(\lim b_n = \alpha\).<br><br>(a) ist falsch: \(q_n = \sum_{k=1}^n \tfrac{1}{k}\) erfüllt \(|q_n - q_{n+1}| \to 0\), ist aber keine Cauchy-Folge (denn \(q_{2n} - q_n \geq \tfrac{1}{2}\)).
Sei \([a,b] \subset \mathbb{R}\) ein kompaktes Intervall. Eine Zerlegung von \([a,b]\) ist eine endliche Menge von Punkten \[ a = x_0 < x_1 < x_2 < \cdots < x_{n-1} < x_n = b, \quad n \in \mathbb{N}. \] Die \(x_i\) heissen Unterteilungspunkte.
Sei \([a,b] \subset \mathbb{R}\) ein kompaktes Intervall. Eine Zerlegung von \([a,b]\) ist eine endliche Menge von Punkten \[ a = x_0 < x_1 < x_2 < \cdots < x_{n-1} < x_n = b, \quad n \in \mathbb{N}. \] Die \(x_i\) heissen Unterteilungspunkte.
Eine Zerlegung erzeugt automatisch eine Partition von \([a,b]\) in die einpunktigen Mengen \(\{x_k\}\) und die offenen Intervalle \((x_{k-1}, x_k)\).
Field-by-field Comparison
Field
Before
After
Text
Sei \([a,b] \subset \mathbb{R}\) ein kompaktes Intervall. Eine {{c1::Zerlegung}} von \([a,b]\) ist eine endliche Menge von Punkten \[ a = x_0 < x_1 < x_2 < \cdots < x_{n-1} < x_n = b, \quad n \in \mathbb{N}. \] Die \(x_i\) heissen {{c2::Unterteilungspunkte}}.<br><br>Eine {{c1::Zerlegung}} \(a = y_0 < y_1 < \cdots < y_m = b\) heisst {{c3::Verfeinerung}} der {{c1::Zerlegung}} \(a = x_0 < \cdots < x_n = b\), falls \(\{x_0, \ldots, x_n\} \subseteq \{y_0, \ldots, y_m\}\).
Extra
Eine Zerlegung erzeugt automatisch eine <i>Partition</i> von \([a,b]\) in die einpunktigen Mengen \(\{x_k\}\) und die offenen Intervalle \((x_{k-1}, x_k)\).
Die Folge \((a_n)_{n\geq1}\) sei definiert durch \(a_n = 1 + \sqrt{\tfrac{k}{12k+1}}\) falls \(n = 3k+1\), \(a_n = \tfrac{5k^3+k}{k^3+1}\) falls \(n = 3k+2\), und \(a_n = \tfrac{(-1)^k}{k}\) falls \(n = 3k+3\). Welche Aussage ist richtig?
\(\lim_{n\to\infty} a_n\) existiert in \(\mathbb{R}\)
\(\liminf_{n\to\infty} a_n\) existiert in \(\mathbb{R}\)
Die Folge \((a_n)_{n\geq1}\) sei definiert durch \(a_n = 1 + \sqrt{\tfrac{k}{12k+1}}\) falls \(n = 3k+1\), \(a_n = \tfrac{5k^3+k}{k^3+1}\) falls \(n = 3k+2\), und \(a_n = \tfrac{(-1)^k}{k}\) falls \(n = 3k+3\). Welche Aussage ist richtig?
\(\lim_{n\to\infty} a_n\) existiert in \(\mathbb{R}\)
\(\liminf_{n\to\infty} a_n\) existiert in \(\mathbb{R}\)
\(\limsup_{n\to\infty} a_n = 1 + \sqrt{1/12}\)
(b) \(\liminf_{n\to\infty} a_n\) existiert in \(\mathbb{R}\).
Die drei Teilfolgen konvergieren gegen \(1 + \sqrt{1/12}\), \(5\) bzw. \(0\). Die Menge der Häufungspunkte ist \(\{0,\, 1+\sqrt{1/12},\, 5\}\), die Folge hat die untere Schranke \(-1\), also existiert der Limes inferior in \(\mathbb{R}\).
(a) ist falsch (drei verschiedene Häufungspunkte). (c) ist falsch: \(\limsup = 5\) (grösster Häufungspunkt).
Field-by-field Comparison
Field
Before
After
Front
Die Folge \((a_n)_{n\geq1}\) sei definiert durch \(a_n = 1 + \sqrt{\tfrac{k}{12k+1}}\) falls \(n = 3k+1\), \(a_n = \tfrac{5k^3+k}{k^3+1}\) falls \(n = 3k+2\), und \(a_n = \tfrac{(-1)^k}{k}\) falls \(n = 3k+3\). Welche Aussage ist richtig?<ol type="a"><li>\(\lim_{n\to\infty} a_n\) existiert in \(\mathbb{R}\)</li><li>\(\liminf_{n\to\infty} a_n\) existiert in \(\mathbb{R}\)</li><li>\(\limsup_{n\to\infty} a_n = 1 + \sqrt{1/12}\)</li></ol>
Back
<b>(b)</b> \(\liminf_{n\to\infty} a_n\) existiert in \(\mathbb{R}\).<br><br>Die drei Teilfolgen konvergieren gegen \(1 + \sqrt{1/12}\), \(5\) bzw. \(0\). Die Menge der Häufungspunkte ist \(\{0,\, 1+\sqrt{1/12},\, 5\}\), die Folge hat die untere Schranke \(-1\), also existiert der Limes inferior in \(\mathbb{R}\).<br><br>(a) ist falsch (drei verschiedene Häufungspunkte).<br>(c) ist falsch: \(\limsup = 5\) (grösster Häufungspunkt).
Substitutionsregel, Version 2. Seien \(I, J \subset \mathbb{R}\) Intervalle, \(f : I \to J\) stetig differenzierbar und \(g : J \to \mathbb{R}\) stetig. Gilt zusätzlich \(f'(x) \neq 0\) für alle \(x \in [a,b]\) mit Inverser \(f^{-1} : [f(a), f(b)] \to \mathbb{R}\) von \(f\big|_{[a,b]}\), so \[ \int_a^b g(f(x))\, dx = {{c2::\int_{f(a)}^{f(b)} g(y)\, (f^{-1})'(y)\, dy}}. \]
Anders als Version 1: hier fehlt der Faktor \(f'(x)\) im Integranden, dafür braucht es Bijektivität von \(f\) (durch \(f' \neq 0\)) und es taucht die Ableitung der Umkehrfunktion auf.
Field-by-field Comparison
Field
Before
After
Text
<b>Substitutionsregel, Version 2.</b><br>Seien \(I, J \subset \mathbb{R}\) Intervalle, \(f : I \to J\) stetig differenzierbar und \(g : J \to \mathbb{R}\) stetig. Gilt zusätzlich {{c1::\(f'(x) \neq 0\) für alle \(x \in [a,b]\)}} mit Inverser \(f^{-1} : [f(a), f(b)] \to \mathbb{R}\) von \(f\big|_{[a,b]}\), so \[ \int_a^b g(f(x))\, dx = {{c2::\int_{f(a)}^{f(b)} g(y)\, (f^{-1})'(y)\, dy}}. \]
Extra
Anders als Version 1: hier fehlt der Faktor \(f'(x)\) im Integranden, dafür braucht es Bijektivität von \(f\) (durch \(f' \neq 0\)) und es taucht die Ableitung der Umkehrfunktion auf.
Wahr oder falsch? Wenn \(A \subset \mathbb{R}\) ein Maximum besitzt, dann besitzt \(A \cap \mathbb{Q}\) auch ein Maximum.
Richtig
Falsch
(b) Falsch.
Gegenbeispiel: \(A = [0, \sqrt{2}]\) hat das Maximum \(\sqrt{2}\). Die Menge \(A \cap \mathbb{Q}\) besteht aus den rationalen Zahlen in \([0, \sqrt{2}]\). Da \(\sqrt{2} \notin \mathbb{Q}\), gibt es zu jeder rationalen Zahl stets eine grössere, die näher bei \(\sqrt{2}\) liegt. Also existiert kein grösstes Element.
Field-by-field Comparison
Field
Before
After
Front
Wahr oder falsch? Wenn \(A \subset \mathbb{R}\) ein Maximum besitzt, dann besitzt \(A \cap \mathbb{Q}\) auch ein Maximum.<ol type="a"><li>Richtig</li><li>Falsch</li></ol>
Back
<b>(b)</b> Falsch.<br><br>Gegenbeispiel: \(A = [0, \sqrt{2}]\) hat das Maximum \(\sqrt{2}\). Die Menge \(A \cap \mathbb{Q}\) besteht aus den rationalen Zahlen in \([0, \sqrt{2}]\). Da \(\sqrt{2} \notin \mathbb{Q}\), gibt es zu jeder rationalen Zahl stets eine grössere, die näher bei \(\sqrt{2}\) liegt. Also existiert kein grösstes Element.
Herleitung: Aus der Produktregel folgt \((fg)' = f'g + fg'\). Beidseitiges Integrieren liefert \((fg)(x) = \int f'g\, dx + \int fg'\, dx\), und Umstellen ergibt die Formel. Partielle Integration ist die Umkehrung der Produktregel.
<i>Herleitung:</i> Aus der Produktregel folgt \((fg)' = f'g + fg'\). Beidseitiges Integrieren liefert \((fg)(x) = \int f'g\, dx + \int fg'\, dx\), und Umstellen ergibt die Formel.<br>Partielle Integration ist die Umkehrung der Produktregel.
In der offensichtlich falschen Rechnung \(-1 = i \cdot i = \sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)} = \sqrt{1} = 1\): An welcher Stelle liegt der Fehler?
In der offensichtlich falschen Rechnung \(-1 = i \cdot i = \sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)} = \sqrt{1} = 1\): An welcher Stelle liegt der Fehler?
\(-1 = i\cdot i\)
\(i\cdot i = \sqrt{-1}\cdot\sqrt{-1}\)
\(\sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)}\)
\(\sqrt{(-1)(-1)} = \sqrt{1}\)
\(\sqrt{1} = 1\)
(c) \(\sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)}\) ist der fehlerhafte Schritt.
Die Produktregel \(\sqrt{a}\cdot\sqrt{b} = \sqrt{ab}\) gilt nur für nichtnegative Radikanden. Bei \(a = b = -1\) ist sie nicht anwendbar, daher bricht die Rechnung hier zusammen.
Field-by-field Comparison
Field
Before
After
Front
In der offensichtlich falschen Rechnung \(-1 = i \cdot i = \sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)} = \sqrt{1} = 1\): <br>An welcher Stelle liegt der Fehler?<ol type="a"><li>\(-1 = i\cdot i\)</li><li>\(i\cdot i = \sqrt{-1}\cdot\sqrt{-1}\)</li><li>\(\sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)}\)</li><li>\(\sqrt{(-1)(-1)} = \sqrt{1}\)</li><li>\(\sqrt{1} = 1\)</li></ol>
Back
<b>(c)</b> \(\sqrt{-1}\cdot\sqrt{-1} = \sqrt{(-1)(-1)}\) ist der fehlerhafte Schritt.<br><br>Die Produktregel \(\sqrt{a}\cdot\sqrt{b} = \sqrt{ab}\) gilt nur für <b>nichtnegative</b> Radikanden. Bei \(a = b = -1\) ist sie nicht anwendbar, daher bricht die Rechnung hier zusammen.
Initial Michael-Scott protocol. Enqueuer: read tail into last; CAS(last.next, null, new); on success, without retry try CAS(tail, last, new). Dequeuer: read head into first, read first.next into next, read next.item, then CAS(head, first, next); on failure retry.
Initial Michael-Scott protocol. Enqueuer: read tail into last; CAS(last.next, null, new); on success, without retry try CAS(tail, last, new). Dequeuer: read head into first, read first.next into next, read next.item, then CAS(head, first, next); on failure retry.
The asymmetry, enqueuer retries on the first CAS but not the second, is intentional: a failed second CAS means some other thread already advanced tail, so the enqueue's logical effect is already established.
Initial Michael-Scott protocol. Enqueuer: read tail into last; CAS(last.next, null, new); on success, without retry try CAS(tail, last, new). Dequeuer: read head into first, read first.next into next, read next.item, then CAS(head, first, next); on failure retry.
Initial Michael-Scott protocol. Enqueuer: read tail into last; CAS(last.next, null, new); on success, without retry try CAS(tail, last, new). Dequeuer: read head into first, read first.next into next, read next.item, then CAS(head, first, next); on failure retry.
The asymmetry, enqueuer retries on the first CAS but not the second, is intentional: a failed second CAS means some other thread already advanced tail, so the enqueue's logical effect is already established.
Field-by-field Comparison
Field
Before
After
Text
Initial Michael-Scott protocol. <em>Enqueuer</em>: read <code>tail</code> into <code>last</code>; {{c1::<code>CAS(last.next, null, new)</code>}}; on success, <em>without retry</em> try {{c2::<code>CAS(tail, last, new)</code>}}. <em>Dequeuer</em>: read <code>head</code> into <code>first</code>, read <code>first.next</code> into <code>next</code>, read <code>next.item</code>, then {{c3::<code>CAS(head, first, next)</code>}}; on failure retry.
Initial Michael-Scott protocol. <br><em><br>Enqueuer</em>: read <code>tail</code> into <code>last</code>; {{c1::<code>CAS(last.next, null, new)</code>}}; on success, <em>without retry</em> try {{c1::<code>CAS(tail, last, new)</code>}}. <br><em><br>Dequeuer</em>: read <code>head</code> into <code>first</code>, read <code>first.next</code> into <code>next</code>, read <code>next.item</code>, then {{c2::<code>CAS(head, first, next)</code>}}; on failure retry.
while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key != key) return false;
Node succ = curr.next.getReference();
snip = curr.next.attemptMark(succ, true); // step 1
if (!snip) continue; // mark failed, retry
pred.next.compareAndSet(curr, succ, false, false); // step 2, ignore result
return true;
}
Two points to note: if step 1 fails, the whole operation restarts from find; if step 2 fails, the result is ignored, because some other traverser will help unlink later.
while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key != key) return false;
Node succ = curr.next.getReference();
snip = curr.next.attemptMark(succ, true); // step 1
if (!snip) continue; // mark failed, retry
pred.next.compareAndSet(curr, succ, false, false); // step 2, ignore result
return true;
}
Two points to note: if step 1 fails, the whole operation restarts from find; if step 2 fails, the result is ignored, because some other traverser will help unlink later.
Step 1 is the linearisation point: a marked node is, by convention, observably absent from the set, even before step 2 has run.
Two points to note: if marking fails, the whole operation restarts from find; if physical deletion fails, the result is ignored, because some other traverser will help unlink later.
Two points to note: if marking fails, the whole operation restarts from find; if physical deletion fails, the result is ignored, because some other traverser will help unlink later.
Step 1 is the linearisation point: a marked node is, by convention, observably absent from the set, even before step 2 has run.
Field-by-field Comparison
Field
Before
After
Text
Lock-free list-set <code>remove(item)</code> on top of <code>find</code>: <pre>while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key != key) return false;
Node succ = curr.next.getReference();
snip = curr.next.attemptMark(succ, true); // step 1
if (!snip) continue; // mark failed, retry
pred.next.compareAndSet(curr, succ, false, false); // step 2, ignore result
return true;
}</pre> Two points to note: if step 1 fails, {{c1::the whole operation restarts from <code>find</code>}}; if step 2 fails, {{c2::the result is ignored, because some other traverser will help unlink later}}.
Lock-free list-set <code>remove(item)</code> on top of <code>find</code>: <pre><img src="paste-cbc5b1aa64a34967a03c25750ff98f2e8e5b2de9.jpg"><br></pre> Two points to note: if marking fails, {{c1::the whole operation restarts from <code>find</code>}}; if physical deletion fails, {{c2::the result is ignored, because some other traverser will help unlink later}}.
public Long pop() {
Node head, next;
do {
head = top.get();
if (head == null) return null;
next = head.next;
} while (!top.compareAndSet(head, next));
return head.item;
}
The CAS commits the swing of top from the observed head to head.next; on failure the loop re-reads top and retries.
public Long pop() {
Node head, next;
do {
head = top.get();
if (head == null) return null;
next = head.next;
} while (!top.compareAndSet(head, next));
return head.item;
}
The CAS commits the swing of top from the observed head to head.next; on failure the loop re-reads top and retries.
Two threads racing pop: exactly one CAS wins, the loser retries with the new top. The stack remains consistent because head.next is read locally before the CAS attempt.
The CAS commits the swing of top from the observed head to head.next; on failure the loop re-reads top and retries.
Two threads racing pop: exactly one CAS wins, the loser retries with the new top. The stack remains consistent because head.next is read locally before the CAS attempt.
Field-by-field Comparison
Field
Before
After
Text
Lock-free stack <code>pop</code>: <pre>public Long pop() {
Node head, next;
do {
head = top.get();
if (head == null) return null;
next = head.next;
} while (!top.compareAndSet(head, next));
return head.item;
}</pre> The CAS {{c1::commits the swing of <code>top</code> from the observed <code>head</code> to <code>head.next</code>}}; on failure the loop {{c2::re-reads <code>top</code> and retries}}.
Lock-free stack <code>pop</code>:<br><br><img src="paste-a25cd915f27e377864879a5daa42bb608b82ae25.jpg"><br><br> The CAS {{c1::commits the swing of <code>top</code> from the observed <code>head</code> to <code>head.next</code>}}; on failure the loop {{c2::re-reads <code>top</code> and retries}}.
A reader/writer lock has three states: not held, held for writing by exactly one thread, and held for reading by one or more threads. The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c4::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. writers and readers exclude each other.
A reader/writer lock has three states: not held, held for writing by exactly one thread, and held for reading by one or more threads. The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c4::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. writers and readers exclude each other.
The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c2::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. writers and readers exclude each other.
The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c2::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. writers and readers exclude each other.
Field-by-field Comparison
Field
Before
After
Text
A reader/writer lock has three states: {{c1::<em>not held</em>}}, {{c2::<em>held for writing</em> by exactly one thread}}, and {{c3::<em>held for reading</em> by one or more threads}}. The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c4::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. {{c4::writers and readers exclude each other}}.
A reader/writer lock has three states: <br><ol><li>{{c1::<em>not held</em>}}, </li><li>{{c1::<em>held for writing</em> by exactly one thread}}, and </li><li>{{c1::<em>held for reading</em> by one or more threads}}. </li></ol>The associated invariants are \(0 \leq \texttt{writers} \leq 1\), \(0 \leq \texttt{readers}\), and {{c2::\(\texttt{writers} \cdot \texttt{readers} = 0\)}}, i.e. {{c2::writers and readers exclude each other}}.<br>
In the 2nd reusable-barrier trial, the release(mutex) is moved to after the release(barrier) on the entry side (and analogously on the exit side). It still fails because a single process can lap the others: while \(n-1\) processes are still in the post-barrier region, one fast process re-enters the entry section, increments count, and could even reach count == n a second time before the others have finished the first round. Violated invariant: "even when a single process has passed the barrier, barrier = 0": the lapping process leaves barrier open behind it.
In the 2nd reusable-barrier trial, the release(mutex) is moved to after the release(barrier) on the entry side (and analogously on the exit side). It still fails because a single process can lap the others: while \(n-1\) processes are still in the post-barrier region, one fast process re-enters the entry section, increments count, and could even reach count == n a second time before the others have finished the first round. Violated invariant: "even when a single process has passed the barrier, barrier = 0": the lapping process leaves barrier open behind it.
The fundamental issue: a single semaphore cannot serve as both "all have arrived" and "all have left". Two semaphores in sequence are needed.
In the 2nd reusable-barrier trial, it still fails because a single process can lap the others: while \(n-1\) processes are still in the post-barrier region, one fast process re-enters the entry section, increments count, and could even reach count == n a second time before the others have finished the first round.
Violated invariant: "even when a single process has passed the barrier, barrier = 0": the lapping process leaves barrier open behind it.
In the 2nd reusable-barrier trial, it still fails because a single process can lap the others: while \(n-1\) processes are still in the post-barrier region, one fast process re-enters the entry section, increments count, and could even reach count == n a second time before the others have finished the first round.
Violated invariant: "even when a single process has passed the barrier, barrier = 0": the lapping process leaves barrier open behind it.
The fundamental issue: a single semaphore cannot serve as both "all have arrived" and "all have left". Two semaphores in sequence are needed.
Field-by-field Comparison
Field
Before
After
Text
In the 2nd reusable-barrier trial, the <code>release(mutex)</code> is moved to <em>after</em> the <code>release(barrier)</code> on the entry side (and analogously on the exit side). It still fails because {{c1::a single process can lap the others: while \(n-1\) processes are still in the post-barrier region, one fast process re-enters the entry section, increments <code>count</code>, and could even reach <code>count == n</code> a second time before the others have finished the first round}}. Violated invariant: {{c2::"even when a single process has passed the barrier, <code>barrier = 0</code>": the lapping process leaves <code>barrier</code> open behind it}}.
<img src="paste-84f2747827f79ef9b2737ade9e5070c71f92e29d.jpg"><br><br>In the 2nd reusable-barrier trial, it still fails because {{c1::a single process can lap the others: while \(n-1\) processes are still in the post-barrier region, one fast process re-enters the entry section, increments <code>count</code>, and could even reach <code>count == n</code> a second time before the others have finished the first round}}. <br><br>Violated invariant: {{c2::"even when a single process has passed the barrier, <code>barrier = 0</code>": the lapping process leaves <code>barrier</code> open behind it}}.
Correctness argument for optimistic remove(c): given that b and c are both locked, b is still reachable from head, and c is still b's successor, neither node can currently be in the process of being deleted, so removing c is safe. For a non-existing c with neighbours b, d the same invariants additionally guarantee that no thread can insert a new node between b and d while we hold the locks, so returning false is correct.
Correctness argument for optimistic remove(c): given that b and c are both locked, b is still reachable from head, and c is still b's successor, neither node can currently be in the process of being deleted, so removing c is safe. For a non-existing c with neighbours b, d the same invariants additionally guarantee that no thread can insert a new node between b and d while we hold the locks, so returning false is correct.
Given that b and care both locked, bis still reachable from head, and cis still b's successor, neither node can currently be in the process of being deleted, so removing c is safe.
For a non-existing c with neighbours b, d the same invariants additionally guarantee that no thread can insert a new node between b and d while we hold the locks, so returning false is correct.
Given that b and care both locked, bis still reachable from head, and cis still b's successor, neither node can currently be in the process of being deleted, so removing c is safe.
For a non-existing c with neighbours b, d the same invariants additionally guarantee that no thread can insert a new node between b and d while we hold the locks, so returning false is correct.
Field-by-field Comparison
Field
Before
After
Text
Correctness argument for optimistic <code>remove(c)</code>: given that {{c1::<code>b</code> and <code>c</code>are both locked}}, {{c2::<code>b</code>is still reachable from <code>head</code>}}, and {{c3::<code>c</code>is still <code>b</code>'s successor}}, {{c4::neither node can currently be in the process of being deleted}}, so removing <code>c</code> is safe. For a non-existing <code>c</code> with neighbours <code>b, d</code> the same invariants additionally guarantee that {{c5::no thread can insert a new node between <code>b</code> and <code>d</code> while we hold the locks}}, so returning <code>false</code> is correct.
Correctness argument for optimistic <code>remove(c)</code>: <br><br>Given that <code>b</code> and <code>c</code> {{c1::are both locked}}, <code>b</code> {{c1::is still reachable from <code>head</code>}}, and <code>c</code> {{c1::is still <code>b</code>'s successor}}, {{c2::neither node can currently be in the process of being deleted}}, so removing <code>c</code> is safe. <br><br>For a non-existing <code>c</code> with neighbours <code>b, d</code> the same invariants additionally guarantee that {{c3::no thread can insert a new node between <code>b</code> and <code>d</code> while we hold the locks}}, so returning <code>false</code> is correct.
Hand-over-hand locking (also lock coupling) on a linked list: a thread always holds locks on two consecutive nodes pred and curr and only releases pred after the lock on the next node has been acquired. This way it walks through the list step by step without any concurrent thread being able to redirect a pointer underneath it.
Hand-over-hand locking (also lock coupling) on a linked list: a thread always holds locks on two consecutive nodes pred and curr and only releases pred after the lock on the next node has been acquired. This way it walks through the list step by step without any concurrent thread being able to redirect a pointer underneath it.
Skeleton of remove:
head.lock();
pred = head;
curr = pred.next;
curr.lock();
while (curr.key < key) {
pred.unlock();
pred = curr; // pred stays locked
curr = curr.next;
curr.lock(); // hand over hand
}
if (curr.key == key) { pred.next = curr.next; return true; }
return false;
Sentinel nodes at head and tail prevent curr from ever being null on entry or at the end of the list.
Hand-over-hand locking (also lock coupling) on a linked list: a thread always holds locks on two consecutive nodes pred and curr and only releases pred after the lock on the next node has been acquired.
This way it walks through the list step by step without any concurrent thread being able to redirect a pointer underneath it.
Hand-over-hand locking (also lock coupling) on a linked list: a thread always holds locks on two consecutive nodes pred and curr and only releases pred after the lock on the next node has been acquired.
This way it walks through the list step by step without any concurrent thread being able to redirect a pointer underneath it.
Sentinel nodes at head and tail prevent curr from ever being null on entry or at the end of the list.
Field-by-field Comparison
Field
Before
After
Text
Hand-over-hand locking (also <em>lock coupling</em>) on a linked list: a thread always holds {{c1::locks on two consecutive nodes <code>pred</code> and <code>curr</code>}} and only releases {{c2::<code>pred</code> after the lock on the next node has been acquired}}. This way it walks through the list step by step without {{c3::any concurrent thread being able to redirect a pointer underneath it}}.
Hand-over-hand locking (also <em>lock coupling</em>) on a linked list: a thread always holds {{c1::locks on two consecutive nodes <code>pred</code> and <code>curr</code>}} and only releases {{c1::<code>pred</code> after the lock on the next node has been acquired}}. <br><br>This way it walks through the list step by step without {{c2::any concurrent thread being able to redirect a pointer underneath it}}.
Extra
Skeleton of <code>remove</code>: <pre>head.lock();
pred = head;
curr = pred.next;
curr.lock();
while (curr.key < key) {
pred.unlock();
pred = curr; // pred stays locked
curr = curr.next;
curr.lock(); // hand over hand
}
if (curr.key == key) { pred.next = curr.next; return true; }
return false;</pre>Sentinel nodes at head and tail prevent <code>curr</code> from ever being <code>null</code> on entry or at the end of the list.
<img src="paste-6cbbbc00c4bd61103231ca85a10ecb0c093cc0cc.jpg"><br>Sentinel nodes at head and tail prevent <code>curr</code> from ever being <code>null</code> on entry or at the end of the list.
Inside the locked critical section of the lazy remove(item), the validation check is !pred.marked && !curr.marked && pred.next == curr. If it passes and curr.key == key, the thread performs the two-step delete: curr.marked = true; (logical), then pred.next = curr.next; (physical).
Inside the locked critical section of the lazy remove(item), the validation check is !pred.marked && !curr.marked && pred.next == curr. If it passes and curr.key == key, the thread performs the two-step delete: curr.marked = true; (logical), then pred.next = curr.next; (physical).
Contrast with optimistic synchronisation: there the validation walked the list from head to re-establish reachability. Here the unmarked flags imply reachability by the key invariant, so a single local check suffices.
Inside the locked critical section of the lazy remove(item), the validation check is !pred.marked && !curr.marked && pred.next == curr.
If it passes and curr.key == key, the thread performs the two-step delete: curr.marked = true; (logical), then pred.next = curr.next; (physical).
Contrast with optimistic synchronisation: there the validation walked the list from head to re-establish reachability. Here the unmarked flags imply reachability by the key invariant, so a single local check suffices.
Field-by-field Comparison
Field
Before
After
Text
Inside the locked critical section of the lazy <code>remove(item)</code>, the validation check is {{c1::<code>!pred.marked && !curr.marked && pred.next == curr</code>}}. If it passes and <code>curr.key == key</code>, the thread performs the two-step delete: {{c2::<code>curr.marked = true;</code>}} (logical), then {{c3::<code>pred.next = curr.next;</code>}} (physical).
Inside the locked critical section of the lazy <code>remove(item)</code>, the validation check is {{c1::<code>!pred.marked && !curr.marked && pred.next == curr</code>}}. <br><br>If it passes and <code>curr.key == key</code>, the thread performs the two-step delete: {{c2::<code>curr.marked = true;</code>}} (logical), then {{c2::<code>pred.next = curr.next;</code>}} (physical).
Extra
Contrast with optimistic synchronisation: there the validation walked the list from <code>head</code> to re-establish reachability. Here the unmarked flags <em>imply</em> reachability by the key invariant, so a single local check suffices.
<img src="paste-53c826a11918b8c3b42be8c6463080ddc1c14509.jpg"><br><br>Contrast with optimistic synchronisation: there the validation walked the list from <code>head</code> to re-establish reachability. Here the unmarked flags <em>imply</em> reachability by the key invariant, so a single local check suffices.
The lazy skip-list find(x, pre, succ) returns -1 if the value is not present, otherwise the level at which x was found. It also fills the output arrays pre: predecessor on each level and succ: successor on each level.
The lazy skip-list find(x, pre, succ) returns -1 if the value is not present, otherwise the level at which x was found. It also fills the output arrays pre: predecessor on each level and succ: successor on each level.
The level/pre/succ information is what add and remove need afterwards to splice or unlink the node at every level it appears in.
The lazy skip-list find(x, pre, succ) returns -1 if the value is not present, otherwise the level at which x was found.
It also fills the output arrays pre: predecessor on each level and succ: successor on each level.
The level/pre/succ information is what add and remove need afterwards to splice or unlink the node at every level it appears in.
Field-by-field Comparison
Field
Before
After
Text
The lazy skip-list <code>find(x, pre, succ)</code> returns {{c1::<code>-1</code> if the value is not present}}, otherwise {{c2::the level at which <code>x</code> was found}}. It also fills the output arrays {{c3::<code>pre</code>: predecessor on each level}} and {{c3::<code>succ</code>: successor on each level}}.
The lazy skip-list <code>find(x, pre, succ)</code> returns {{c1::<code>-1</code>}} if the value is not present, otherwise {{c1::the level at which <code>x</code> was found}}. <br><br>It also fills the output arrays {{c3::<code>pre</code>: predecessor on each level}} and {{c3::<code>succ</code>: successor on each level}}.
Idea: two semaphores act as alternating gates: the \(n\)-th arriver flips barrier1 open and barrier2 closed; the last leaver flips them back. Between phases the invariant is barrier1 = 1 and barrier2 = 0 for all processes (and after phase 2: barrier1 = 0, barrier2 = 1).
Idea: two semaphores act as alternating gates: the \(n\)-th arriver flips barrier1 open and barrier2 closed; the last leaver flips them back. Between phases the invariant is barrier1 = 1 and barrier2 = 0 for all processes (and after phase 2: barrier1 = 0, barrier2 = 1).
The barrier is now safely reusable: each iteration ends with the same initial state (count = 0, one barrier closed, one open). In practice this is very slow; specialised x86 barriers (e.g. spiral.net) can be many times faster.
Idea: two semaphores act as alternating gates: the \(n\)-th arriver flips barrier1 open and barrier2 closed; the last leaver flips them back.
Between phases the invariant is barrier1 = 1 and barrier2 = 0 for all processes (and after phase 2: barrier1 = 0, barrier2 = 1).
The barrier is now safely reusable: each iteration ends with the same initial state (count = 0, one barrier closed, one open). In practice this is very slow; specialised x86 barriers (e.g. spiral.net) can be many times faster.
Field-by-field Comparison
Field
Before
After
Text
Two-phase barrier solution: with <code>mutex=1, barrier1=0, barrier2=1, count=0</code>, <pre>acquire(mutex)
count++
if (count==n) { acquire(barrier2); release(barrier1); }
release(mutex)
acquire(barrier1); release(barrier1); // phase 1
acquire(mutex)
count--
if (count==0) { acquire(barrier1); release(barrier2); }
release(mutex)
acquire(barrier2); release(barrier2); // phase 2</pre>Idea: {{c1::two semaphores act as alternating gates: the \(n\)-th arriver flips <code>barrier1</code> open and <code>barrier2</code> closed; the last leaver flips them back}}. Between phases the invariant is {{c2::<code>barrier1 = 1</code> and <code>barrier2 = 0</code> for all processes (and after phase 2: <code>barrier1 = 0</code>, <code>barrier2 = 1</code>)}}.
Two-phase barrier solution: <br><br><img src="paste-6555cfef082b361e9fd4b99e9e1ebc4d67c9890e.jpg"><br><br>Idea: {{c1::two semaphores act as alternating gates: the \(n\)-th arriver flips <code>barrier1</code> open and <code>barrier2</code> closed; the last leaver flips them back}}. <br><br>Between phases the invariant is {{c2::<code>barrier1 = 1</code> and <code>barrier2 = 0</code> for all processes (and after phase 2: <code>barrier1 = 0</code>, <code>barrier2 = 1</code>)}}.
After locking, validate(pred, curr) in optimistic synchronisation must check two properties: pred is still reachable from head (otherwise pred has been deleted in the meantime), and pred.next == curr (otherwise some node has been inserted between pred and curr). If either check fails, the operation must be restarted.
After locking, validate(pred, curr) in optimistic synchronisation must check two properties: pred is still reachable from head (otherwise pred has been deleted in the meantime), and pred.next == curr (otherwise some node has been inserted between pred and curr). If either check fails, the operation must be restarted.
After locking, validate(pred, curr) in optimistic synchronisation must check two properties:
pred is still reachable from head (otherwise pred has been deleted in the meantime), and
pred.next == curr (otherwise some node has been inserted between pred and curr).
If either check fails, the operation must be restarted.
Field-by-field Comparison
Field
Before
After
Text
After locking, <code>validate(pred, curr)</code> in optimistic synchronisation must check two properties: {{c1::<code>pred</code> is still reachable from <code>head</code>}} (otherwise <code>pred</code> has been deleted in the meantime), and {{c2::<code>pred.next == curr</code>}} (otherwise some node has been inserted between <code>pred</code> and <code>curr</code>). If either check fails, the operation must be {{c3::restarted}}.
After locking, <code>validate(pred, curr)</code> in optimistic synchronisation must check two properties: <br><ol><li>{{c1::<code>pred</code> is still reachable from <code>head</code> (otherwise <code>pred</code> has been deleted in the meantime)}}, and </li><li>{{c2::<code>pred.next == curr</code> (otherwise some node has been inserted between <code>pred</code> and <code>curr</code>)}}. </li></ol>If either check fails, the operation must be {{c3::restarted}}.<br>
Optimistic synchronisation on a list: traverse the list without any locks to find pred and curr, then lock both nodes, and validate that the world has not changed underneath you during the traversal. If validation fails, the whole attempt is retried.
Optimistic synchronisation on a list: traverse the list without any locks to find pred and curr, then lock both nodes, and validate that the world has not changed underneath you during the traversal. If validation fails, the whole attempt is retried.
Optimistic synchronisation on a list: traverse the list without any locks to find pred and curr, then lock both nodes, and validate that the world has not changed underneath you during the traversal.
If validation fails, the whole attempt is retried.
Optimistic synchronisation on a list: traverse the list without any locks to find pred and curr, then lock both nodes, and validate that the world has not changed underneath you during the traversal.
If validation fails, the whole attempt is retried.
Field-by-field Comparison
Field
Before
After
Text
Optimistic synchronisation on a list: {{c1::traverse the list <em>without</em> any locks to find <code>pred</code> and <code>curr</code>}}, {{c2::then lock both nodes}}, and {{c3::validate that the world has not changed underneath you during the traversal}}. If validation fails, {{c4::the whole attempt is retried}}.
Optimistic synchronisation on a list: <br>{{c1::traverse the list <em>without</em> any locks to find <code>pred</code> and <code>curr</code>, then lock both nodes, and validate that the world has not changed underneath you during the traversal}}. <br><br>If validation fails, {{c3::the whole attempt is retried}}.
public void push(Long item) {
Node newi = new Node(item);
Node head;
do {
head = top.get();
newi.next = head;
} while (!top.compareAndSet(head, newi));
}
The new node is built first, its next is wired to the currently observed top, then the CAS installs the new node as top iff top has not changed in the meantime.
public void push(Long item) {
Node newi = new Node(item);
Node head;
do {
head = top.get();
newi.next = head;
} while (!top.compareAndSet(head, newi));
}
The new node is built first, its next is wired to the currently observed top, then the CAS installs the new node as top iff top has not changed in the meantime.
The new node is invisible to other threads until the CAS succeeds, so there is no need to undo anything on failure.
The new node is built first, its next is wired to the currently observed top, then the CAS installs the new node as top iff top has not changed in the meantime.
The new node is built first, its next is wired to the currently observed top, then the CAS installs the new node as top iff top has not changed in the meantime.
The new node is invisible to other threads until the CAS succeeds, so there is no need to undo anything on failure.
Field-by-field Comparison
Field
Before
After
Text
Lock-free stack <code>push</code>: <pre>public void push(Long item) {
Node newi = new Node(item);
Node head;
do {
head = top.get();
newi.next = head;
} while (!top.compareAndSet(head, newi));
}</pre> The new node is built first, its <code>next</code> is wired to the currently observed <code>top</code>, then the CAS {{c1::installs the new node as <code>top</code> iff <code>top</code> has not changed in the meantime}}.
Lock-free stack <code>push</code>:<br><br><img src="paste-3763cfb98e698ad52bad28aa948f6227aa7af476.jpg"><br><br> The new node is built first, its <code>next</code> is wired to the currently observed <code>top</code>, then the CAS {{c1::installs the new node as <code>top</code> iff <code>top</code> has not changed in the meantime}}.
FIFO fairness for reader/writer locks: when a writer leaves the CS, the \(k\) readers currently waiting are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives. An arriving writer then has to wait until the readers currently in the CS finish.
FIFO fairness for reader/writer locks: when a writer leaves the CS, the \(k\) readers currently waiting are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives. An arriving writer then has to wait until the readers currently in the CS finish.
Idea: readers that arrive after a waiting writer must not overtake that writer (analogous to the usual writer priority of common library implementations), but with an explicit quota \(k\) instead of absolute writer precedence.
FIFO fairness for reader/writer locks: when a writer leaves the CS, the \(k\) readers currently waiting are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives.
An arriving writer then has to wait until the readers currently in the CS finish.
FIFO fairness for reader/writer locks: when a writer leaves the CS, the \(k\) readers currently waiting are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives.
An arriving writer then has to wait until the readers currently in the CS finish.
Idea: readers that arrive after a waiting writer must not overtake that writer (analogous to the usual writer priority of common library implementations), but with an explicit quota \(k\) instead of absolute writer precedence.
Field-by-field Comparison
Field
Before
After
Text
FIFO fairness for reader/writer locks: {{c1::when a writer leaves the CS, the \(k\) readers <em>currently waiting</em> are allowed in}}; {{c2::once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives}}. An arriving writer then {{c3::has to wait until the readers currently in the CS finish}}.
FIFO fairness for reader/writer locks: <br>{{c1::when a writer leaves the CS, the \(k\) readers <em>currently waiting</em> are allowed in; once those \(k\) readers have finished, the next writer enters (if any), otherwise further readers may enter until a writer arrives}}. <br><br>An arriving writer then {{c2::has to wait until the readers currently in the CS finish}}.
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that the lock-free version can be slower than the blocking one, because atomic operations are expensive and the CAS retry loop wastes work under contention. Adding exponential backoff to the retry loop restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that the lock-free version can be slower than the blocking one, because atomic operations are expensive and the CAS retry loop wastes work under contention. Adding exponential backoff to the retry loop restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Moral: lock-freedom is a progress property, not an automatic performance property. Contention management (backoff, elimination, combining) is still needed to make lock-free structures fast.
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that the lock-free version can be slower than the blocking one, because atomic operations are expensive and the CAS retry loop wastes work under contention.
Adding exponential backoff to the retry loop restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that the lock-free version can be slower than the blocking one, because atomic operations are expensive and the CAS retry loop wastes work under contention.
Adding exponential backoff to the retry loop restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Moral: lock-freedom is a progress property, not an automatic performance property. Contention management (backoff, elimination, combining) is still needed to make lock-free structures fast.
Field-by-field Comparison
Field
Before
After
Text
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that {{c1::the lock-free version can be <em>slower</em> than the blocking one}}, because {{c2::atomic operations are expensive and the CAS retry loop wastes work under contention}}. Adding {{c3::exponential backoff to the retry loop}} restores good scalability and makes the lock-free + backoff variant the fastest of the three.
Empirical comparison of a synchronised stack vs. a CAS-based lock-free stack under high contention shows that {{c1::the lock-free version can be <em>slower</em> than the blocking one}}, because {{c1::atomic operations are expensive and the CAS retry loop wastes work under contention}}. <br><br>Adding {{c2::exponential backoff to the retry loop}} restores good scalability and makes the lock-free + backoff variant the fastest of the three.
A naive reusable barrier extends the one-shot barrier with a symmetric "second half"
after the turnstile, intended to reset count and barrier.
It is broken because the invariant "after all processes have passed, barrier = 0" is violated: release(barrier) can be executed multiple times across iterations before any thread reaches the resetting acquire(barrier), so barrier drifts to \(2, 3, \dots\), and the if (count == 0) acquire(barrier) check happens outside the mutex, so it cannot reliably restore the semaphore to 0 in the presence of fast re-entrants.
A naive reusable barrier extends the one-shot barrier with a symmetric "second half"
after the turnstile, intended to reset count and barrier.
It is broken because the invariant "after all processes have passed, barrier = 0" is violated: release(barrier) can be executed multiple times across iterations before any thread reaches the resetting acquire(barrier), so barrier drifts to \(2, 3, \dots\), and the if (count == 0) acquire(barrier) check happens outside the mutex, so it cannot reliably restore the semaphore to 0 in the presence of fast re-entrants.
Concrete scheduling: thread A finishes phase 1 with count = 1; meanwhile B and C race into the next iteration, both increment count back up, hit count == n, and each calls release(barrier). The semaphore is no longer a clean 0/1 toggle. The fix is a proper two-phase split with separate semaphores for the two halves.
A naive reusable barrier extends the one-shot barrier with a symmetric "second half" after the turnstile, intended to reset count and barrier.
It is broken because the invariant "after all processes have passed, barrier = 0" is violated: release(barrier) can be executed multiple times across iterations before any thread reaches the resetting acquire(barrier), so barrier drifts to \(2, 3, \dots\), and the if (count == 0) acquire(barrier) check happens outside the mutex, so it cannot reliably restore the semaphore to 0 in the presence of fast re-entrants.
A naive reusable barrier extends the one-shot barrier with a symmetric "second half" after the turnstile, intended to reset count and barrier.
It is broken because the invariant "after all processes have passed, barrier = 0" is violated: release(barrier) can be executed multiple times across iterations before any thread reaches the resetting acquire(barrier), so barrier drifts to \(2, 3, \dots\), and the if (count == 0) acquire(barrier) check happens outside the mutex, so it cannot reliably restore the semaphore to 0 in the presence of fast re-entrants.
Concrete scheduling: thread A finishes phase 1 with count = 1; meanwhile B and C race into the next iteration, both increment count back up, hit count == n, and each calls release(barrier). The semaphore is no longer a clean 0/1 toggle. The fix is a proper two-phase split with separate semaphores for the two halves.
Field-by-field Comparison
Field
Before
After
Text
A naive reusable barrier extends the one-shot barrier with a symmetric "second half" <pre><img src="paste-ffd6359913f85c1da896aba5205bc4cf259dbbc3.jpg"><br></pre>after the turnstile, intended to reset<code>count</code> and <code>barrier</code>.<br><br>It is broken because the invariant {{c1::"after all processes have passed, <code>barrier = 0</code>" is violated: <code>release(barrier)</code> can be executed multiple times across iterations before any thread reaches the resetting <code>acquire(barrier)</code>, so <code>barrier</code> drifts to \(2, 3, \dots\)}}, and the <code>if (count == 0) acquire(barrier)</code> check {{c2::happens outside the mutex, so it cannot reliably restore the semaphore to 0 in the presence of fast re-entrants}}.
A naive reusable barrier extends the one-shot barrier with a symmetric "second half" after the turnstile, intended to reset <code>count</code> and <code>barrier</code>.<pre><img src="paste-ffd6359913f85c1da896aba5205bc4cf259dbbc3.jpg"><br></pre>It is broken because the invariant {{c1::"after all processes have passed, <code>barrier = 0</code>" is violated: <code>release(barrier)</code> can be executed multiple times across iterations before any thread reaches the resetting <code>acquire(barrier)</code>, so <code>barrier</code> drifts to \(2, 3, \dots\)}}, and the <code>if (count == 0) acquire(barrier)</code> check {{c2::happens outside the mutex, so it cannot reliably restore the semaphore to 0 in the presence of fast re-entrants}}.
Lazy synchronisation improves the optimistic list in two respects: the list is traversed only once (instead of twice for the validation pass), and contains() never acquires any locks. The trick is to give every node a deleted flag (marker) with the semantics every unmarked node is reachable from head; nodes are first marked and only afterwards "lazily" unlinked from the list.
Lazy synchronisation improves the optimistic list in two respects: the list is traversed only once (instead of twice for the validation pass), and contains() never acquires any locks. The trick is to give every node a deleted flag (marker) with the semantics every unmarked node is reachable from head; nodes are first marked and only afterwards "lazily" unlinked from the list.
The marker replaces the validation step: a thread that locks a node and observes marked == false knows without rescanning that this node is still reachable and valid.
Lazy synchronisation improves the optimistic list in two respects:
the list is traversed only once (instead of twice for the validation pass), and
contains() never acquires any locks.
The trick is to give every node a deleted flag (marker) with the semantics every unmarked node is reachable from head; nodes are first marked and only afterwards "lazily" unlinked from the list.
Lazy synchronisation improves the optimistic list in two respects:
the list is traversed only once (instead of twice for the validation pass), and
contains() never acquires any locks.
The trick is to give every node a deleted flag (marker) with the semantics every unmarked node is reachable from head; nodes are first marked and only afterwards "lazily" unlinked from the list.
The marker replaces the validation step: a thread that locks a node and observes marked == false knows without rescanning that this node is still reachable and valid.
Field-by-field Comparison
Field
Before
After
Text
Lazy synchronisation improves the optimistic list in two respects: {{c1::the list is traversed only once}} (instead of twice for the validation pass), and {{c2::<code>contains()</code> never acquires any locks}}. The trick is to give every node a {{c3::<em>deleted</em> flag (marker)}} with the semantics {{c4::every unmarked node is reachable from <code>head</code>}}; nodes are first marked and {{c5::only afterwards "lazily" unlinked from the list}}.
Lazy synchronisation improves the optimistic list in two respects: <br><ol><li>{{c1::the list is traversed only once (instead of twice for the validation pass)}}, and </li><li>{{c2::<code>contains()</code> never acquires any locks}}. </li></ol>The trick is to give every node a {{c3::<em>deleted</em> flag (marker) with the semantics every unmarked node is reachable from <code>head</code>; nodes are first marked and only afterwards "lazily" unlinked from the list}}.<br>
Disadvantage of the plain producer-consumer with Lock + Condition: signal() is called on every enqueue and dequeue, even when no thread is currently waiting on that condition (a wasted call into the runtime). Dijkstra's Sleeping Barber variant adds two counters \(m\) and \(n\) with the semantics \(m \leq 0 \Leftrightarrow\) buffer full and \(-m\) producers are waiting and \(n \leq 0 \Leftrightarrow\) buffer empty and \(-n\) consumers are waiting, so signals are issued only when someone is actually waiting.
Disadvantage of the plain producer-consumer with Lock + Condition: signal() is called on every enqueue and dequeue, even when no thread is currently waiting on that condition (a wasted call into the runtime). Dijkstra's Sleeping Barber variant adds two counters \(m\) and \(n\) with the semantics \(m \leq 0 \Leftrightarrow\) buffer full and \(-m\) producers are waiting and \(n \leq 0 \Leftrightarrow\) buffer empty and \(-n\) consumers are waiting, so signals are issued only when someone is actually waiting.
Initial values: \(n = 0\) (buffer empty, no waiters), \(m = \text{size} - 1\) (one fewer free slot than capacity, matching the unused-slot trick of the underlying ring buffer). The barber metaphor: the customer (consumer) waits if no client is in the chair; the barber (producer) sleeps if no chair is free.
Disadvantage of the plain producer-consumer with Lock + Condition: signal() is called on every enqueue and dequeue, even when no thread is currently waiting on that condition (a wasted call into the runtime).
Dijkstra's Sleeping Barber variant adds two counters \(m\) and \(n\) with the semantics \(m \leq 0 \Leftrightarrow\) buffer full and \(-m\) producers are waiting and \(n \leq 0 \Leftrightarrow\) buffer empty and \(-n\) consumers are waiting, so signals are issued only when someone is actually waiting.
Disadvantage of the plain producer-consumer with Lock + Condition: signal() is called on every enqueue and dequeue, even when no thread is currently waiting on that condition (a wasted call into the runtime).
Dijkstra's Sleeping Barber variant adds two counters \(m\) and \(n\) with the semantics \(m \leq 0 \Leftrightarrow\) buffer full and \(-m\) producers are waiting and \(n \leq 0 \Leftrightarrow\) buffer empty and \(-n\) consumers are waiting, so signals are issued only when someone is actually waiting.
Initial values: \(n = 0\) (buffer empty, no waiters), \(m = \text{size} - 1\) (one fewer free slot than capacity, matching the unused-slot trick of the underlying ring buffer). The barber metaphor: the customer (consumer) waits if no client is in the chair; the barber (producer) sleeps if no chair is free.
Field-by-field Comparison
Field
Before
After
Text
Disadvantage of the plain producer-consumer with <code>Lock</code> + <code>Condition</code>: {{c1::<code>signal()</code> is called on every <code>enqueue</code> and <code>dequeue</code>, even when no thread is currently waiting on that condition (a wasted call into the runtime)}}. Dijkstra's <em>Sleeping Barber</em> variant adds {{c2::two counters \(m\) and \(n\)}} with the semantics {{c3::\(m \leq 0 \Leftrightarrow\) buffer full and \(-m\) producers are waiting}} and {{c3::\(n \leq 0 \Leftrightarrow\) buffer empty and \(-n\) consumers are waiting}}, so signals are issued only when someone is actually waiting.
Disadvantage of the plain producer-consumer with <code>Lock</code> + <code>Condition</code>: {{c1::<code>signal()</code> is called on every <code>enqueue</code> and <code>dequeue</code>, even when no thread is currently waiting on that condition (a wasted call into the runtime)}}. <br><br>Dijkstra's <em>Sleeping Barber</em> variant adds two counters \(m\) and \(n\) with the semantics {{c2::\(m \leq 0 \Leftrightarrow\) buffer full and \(-m\) producers are waiting}} and {{c2::\(n \leq 0 \Leftrightarrow\) buffer empty and \(-n\) consumers are waiting}}, so signals are issued only when someone is actually waiting.
Waiting (scheduled) locks suspend a blocked thread instead of spinning. Typical building blocks: semaphores, mutexes, and monitors. A monitor has two queues: a waiting entry queue for threads trying to enter the monitor, and a waiting condition queue for threads that have called wait inside it. These queues themselves must be protected against concurrent access, typically with a spinlock (unless implemented lock-free).
Waiting (scheduled) locks suspend a blocked thread instead of spinning. Typical building blocks: semaphores, mutexes, and monitors. A monitor has two queues: a waiting entry queue for threads trying to enter the monitor, and a waiting condition queue for threads that have called wait inside it. These queues themselves must be protected against concurrent access, typically with a spinlock (unless implemented lock-free).
So spinlocks do not disappear when one moves to scheduled locks: they are reused at a lower level to protect the scheduler's data structures.
Waiting (scheduled) locks suspend a blocked thread instead of spinning.
Typical building blocks: semaphores, mutexes, and monitors.
A monitor has two queues: waiting entry queue for threads trying to enter the monitor, and a waiting condition queue for threads that have called wait inside it. These queues themselves must be protected against concurrent access, typically with a spinlock (unless implemented lock-free).
Waiting (scheduled) locks suspend a blocked thread instead of spinning.
Typical building blocks: semaphores, mutexes, and monitors.
A monitor has two queues: waiting entry queue for threads trying to enter the monitor, and a waiting condition queue for threads that have called wait inside it. These queues themselves must be protected against concurrent access, typically with a spinlock (unless implemented lock-free).
So spinlocks do not disappear when one moves to scheduled locks: they are reused at a lower level to protect the scheduler's data structures.
Field-by-field Comparison
Field
Before
After
Text
Waiting (scheduled) locks suspend a blocked thread instead of spinning. Typical building blocks: {{c1::semaphores, mutexes, and monitors}}. A monitor has two queues: {{c2::a <em>waiting entry</em> queue for threads trying to enter the monitor}}, and {{c2::a <em>waiting condition</em> queue for threads that have called <code>wait</code> inside it}}. These queues themselves must be protected against concurrent access, typically {{c3::with a spinlock}} (unless implemented lock-free).
Waiting (scheduled) locks suspend a blocked thread instead of spinning. <br><br>Typical building blocks: {{c1::semaphores, mutexes, and monitors}}. <br><br>A monitor has two queues: <em>waiting entry</em> queue for threads trying to enter the monitor, and a <em>waiting condition</em> queue for threads that have called <code>wait</code> inside it. These queues themselves must be protected against concurrent access, typically {{c2::with a spinlock (unless implemented lock-free)}}.
Accesses to volatile fields in Java do not count as a data race.
In terms of performance, volatile is slower than ordinary fields, but faster than locks.
Recommendation: only for experts; otherwise use the standard library (java.util.concurrent, AtomicInteger, …).
Caveat: volatile guarantees visibility, but not atomicity of compound operations like i++.
Field-by-field Comparison
Field
Before
After
Text
Accesses to <code>volatile</code> fields in Java do not count as {{c1::a data race}}. <br><br>In terms of performance, <code>volatile</code> is {{c2::slower than ordinary fields, but faster than locks}}.
Accesses to <code>volatile</code> fields in Java do not count as {{c1::a data race}}. <br><br>In terms of performance, <code>volatile</code> is slower than {{c2::ordinary fields}}, but faster than {{c2::locks}}.
Practical reader/writer lock implementations usually give priority to writers: once a writer blocks, readers arriving later no longer get the lock before that writer. Otherwise an insert could starve under a steady stream of readers.
Practical reader/writer lock implementations usually give priority to writers: once a writer blocks, readers arriving later no longer get the lock before that writer. Otherwise an insert could starve under a steady stream of readers.
Practical reader/writer lock implementations usually give priority to writers: once a writer blocks, readers arriving later no longer get the lock before that writer.
Otherwise an insert could starve under a steady stream of readers.
Practical reader/writer lock implementations usually give priority to writers: once a writer blocks, readers arriving later no longer get the lock before that writer.
Otherwise an insert could starve under a steady stream of readers.
Field-by-field Comparison
Field
Before
After
Text
Practical reader/writer lock implementations usually give priority to {{c1::writers}}: once a writer blocks, {{c2::readers arriving later}} no longer get the lock {{c3::before that writer}}. Otherwise an <code>insert</code> could {{c4::starve}} under a steady stream of readers.
Practical reader/writer lock implementations usually give priority to {{c1::writers: once a writer blocks, readers arriving later no longer get the lock before that writer}}. <br><br>Otherwise an <code>insert</code> could {{c2::starve under a steady stream of readers}}.
while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key == key) return false;
Node node = new Node(item);
node.next = new AtomicMarkableReference(curr, false);
if (pred.next.compareAndSet(curr, node, false, false))
return true;
// else retry
}
The single CAS commits both that pred still points to curr and that pred is itself still unmarked. If it fails, another thread changed pred.next or marked pred for deletion in the meantime, so the operation restarts.
while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key == key) return false;
Node node = new Node(item);
node.next = new AtomicMarkableReference(curr, false);
if (pred.next.compareAndSet(curr, node, false, false))
return true;
// else retry
}
The single CAS commits both that pred still points to curr and that pred is itself still unmarked. If it fails, another thread changed pred.next or marked pred for deletion in the meantime, so the operation restarts.
Because find already snips away every marked node it encounters, by the time add tries its CAS the window (pred, curr) is "clean": any failure of this CAS is due to a concurrent operation, not stale state from a half-done remove.
The single CAS commits both that pred still points to curr and that pred is itself still unmarked.
If it fails, another thread changed pred.next or marked pred for deletion in the meantime, so the operation restarts.
Because find already snips away every marked node it encounters, by the time add tries its CAS the window (pred, curr) is "clean": any failure of this CAS is due to a concurrent operation, not stale state from a half-done remove.
Field-by-field Comparison
Field
Before
After
Text
Lock-free list-set <code>add(item)</code> on top of <code>find</code>: <pre>while (true) {
Window w = find(head, key);
Node pred = w.pred, curr = w.curr;
if (curr.key == key) return false;
Node node = new Node(item);
node.next = new AtomicMarkableReference(curr, false);
if (pred.next.compareAndSet(curr, node, false, false))
return true;
// else retry
}</pre> The single CAS commits both that {{c1::<code>pred</code> still points to <code>curr</code>}} and that {{c2::<code>pred</code> is itself still unmarked}}. If it fails, {{c3::another thread changed <code>pred.next</code> or marked <code>pred</code> for deletion in the meantime, so the operation restarts}}.
Lock-free list-set <code>add(item)</code> on top of <code>find</code>: <pre><img src="paste-a858ec2e27ee295fb00d074b5fc704551dcffafb.jpg"><br></pre> The single CAS commits both that {{c1::<code>pred</code> still points to <code>curr</code>}} and that {{c1::<code>pred</code> is itself still unmarked}}. <br><br>If it fails, {{c2::another thread changed <code>pred.next</code> or marked <code>pred</code> for deletion in the meantime, so the operation restarts}}.
Reader/writer lock API. new creates the lock in state not held. acquire_write: block if currently held for reading or held for writing; otherwise transition to held for writing. release_write: make not held. acquire_read: block if currently held for writing; otherwise transition to / stay in held for reading and increment the readers count. release_read: decrement the readers count; if it reaches \(0\), make not held.
Reader/writer lock API. new creates the lock in state not held. acquire_write: block if currently held for reading or held for writing; otherwise transition to held for writing. release_write: make not held. acquire_read: block if currently held for writing; otherwise transition to / stay in held for reading and increment the readers count. release_read: decrement the readers count; if it reaches \(0\), make not held.
Reader/writer lock API. new creates the lock in state not held.
acquire_write: block if currently held for reading or held for writing; otherwise transition to held for writing.
release_write: make not held.
acquire_read: block if currently held for writing; otherwise transition to / stay in held for reading and increment the readers count.
release_read: decrement the readers count; if it reaches \(0\), make not held.
Field-by-field Comparison
Field
Before
After
Text
Reader/writer lock API. <code>new</code> creates the lock in state <em>not held</em>. {{c1::<code>acquire_write</code>}}: {{c2::block if currently <em>held for reading</em> or <em>held for writing</em>; otherwise transition to <em>held for writing</em>}}. {{c3::<code>release_write</code>}}: {{c4::make <em>not held</em>}}. {{c5::<code>acquire_read</code>}}: {{c6::block if currently <em>held for writing</em>; otherwise transition to / stay in <em>held for reading</em> and increment the readers count}}. {{c7::<code>release_read</code>}}: {{c8::decrement the readers count; if it reaches \(0\), make <em>not held</em>}}.
Reader/writer lock API. <code>new</code> creates the lock in state <em>not held</em>. <br><ul><li><code>acquire_write</code>: {{c1::block if currently <em>held for reading</em> or <em>held for writing</em>; otherwise transition to <em>held for writing</em>}}. </li><li><code>release_write</code>: {{c2::make <em>not held</em>}}. </li><li><code>acquire_read</code>: {{c3::block if currently <em>held for writing</em>; otherwise transition to / stay in <em>held for reading</em> and increment the readers count}}. </li><li><code>release_read</code>: {{c4::decrement the readers count; if it reaches \(0\), make <em>not held</em>}}.</li></ul>
A monitor is an abstract data structure equipped with a set of operations that run in mutual exclusion, plus a mechanism to wait on conditions inside the monitor. Invented by Tony Hoare and Per Brinch Hansen (1974).
A monitor is an abstract data structure equipped with a set of operations that run in mutual exclusion, plus a mechanism to wait on conditions inside the monitor. Invented by Tony Hoare and Per Brinch Hansen (1974).
Beyond mutual exclusion, a monitor must let a thread that finds a condition unsatisfied release the monitor lock, wait for the condition, and be signalled when it becomes true, all without busy-waiting.
A monitor is an abstract data structure equipped with a set of operations that run in mutual exclusion, plus a mechanism to wait on conditions inside the monitor.
Invented by Tony Hoare and Per Brinch Hansen (1974).
A monitor is an abstract data structure equipped with a set of operations that run in mutual exclusion, plus a mechanism to wait on conditions inside the monitor.
Invented by Tony Hoare and Per Brinch Hansen (1974).
Beyond mutual exclusion, a monitor must let a thread that finds a condition unsatisfied release the monitor lock, wait for the condition, and be signalled when it becomes true, all without busy-waiting.
Field-by-field Comparison
Field
Before
After
Text
A {{c1::monitor}} is {{c2::an abstract data structure equipped with a set of operations that run in mutual exclusion}}, plus a mechanism to wait on conditions inside the monitor. Invented by {{c3::Tony Hoare and Per Brinch Hansen (1974)}}.
A {{c1::monitor}} is {{c2::an abstract data structure equipped with a set of operations that run in mutual exclusion}}, plus a mechanism to wait on conditions inside the {{c1::monitor}}. <br><br>Invented by {{c3::Tony Hoare and Per Brinch Hansen (1974)}}.
Sublist property of a skip list: a higher-level list is always contained in every lower-level list; in particular the lowest level contains the entire list.
Sublist property of a skip list: a higher-level list is always contained in every lower-level list; in particular the lowest level contains the entire list.
Equivalently: if a node has height \(h\), it appears in levels \(0, 1, \dots, h-1\). Sentinel nodes \(-\infty\) and \(+\infty\) are present at every level.
Sublist property of a skip list: a higher-level list is always contained in every lower-level list; in particular the lowest level contains the entire list.
Sublist property of a skip list: a higher-level list is always contained in every lower-level list; in particular the lowest level contains the entire list.
Equivalently: if a node has height \(h\), it appears in levels \(0, 1, \dots, h-1\). Sentinel nodes \(-\infty\) and \(+\infty\) are present at every level.
Field-by-field Comparison
Field
Before
After
Text
<em>Sublist property</em> of a skip list: {{c1::a higher-level list is always contained in every lower-level list}}; in particular {{c2::the lowest level contains the entire list}}.
<em>Sublist property</em> of a skip list: {{c1::a higher-level list is always contained in every lower-level list}}; in particular {{c1::the lowest level contains the entire list}}.
Extra
Equivalently: if a node has height \(h\), it appears in levels \(0, 1, \dots, h-1\). Sentinel nodes \(-\infty\) and \(+\infty\) are present at every level.
<img src="paste-98990994b90175c89aa3c810cad2f5a7aa50fec5.jpg"><br><br>Equivalently: if a node has height \(h\), it appears in levels \(0, 1, \dots, h-1\). Sentinel nodes \(-\infty\) and \(+\infty\) are present at every level.
Defining property of a non-blocking algorithm: the failure or suspension of one thread cannot cause the failure or suspension of another thread. Contrast with locks/blocking, where one thread can indefinitely delay another (e.g. by dying inside the critical section).
Defining property of a non-blocking algorithm: the failure or suspension of one thread cannot cause the failure or suspension of another thread. Contrast with locks/blocking, where one thread can indefinitely delay another (e.g. by dying inside the critical section).
This is precisely what makes non-blocking algorithms suitable for environments where threads may be preempted, killed, or run at very different speeds (real-time systems, interrupt handlers, GC pauses).
Defining property of a non-blocking algorithm: the failure or suspension of one thread cannot cause the failure or suspension of another thread.
Contrast with locks/blocking, where one thread can indefinitely delay another (e.g. by dying inside the critical section).
This is precisely what makes non-blocking algorithms suitable for environments where threads may be preempted, killed, or run at very different speeds (real-time systems, interrupt handlers, GC pauses).
Field-by-field Comparison
Field
Before
After
Text
Defining property of a non-blocking algorithm: {{c1::the failure or suspension of one thread cannot cause the failure or suspension of another thread}}. Contrast with locks/blocking, where {{c2::one thread can indefinitely delay another (e.g. by dying inside the critical section)}}.
Defining property of a non-blocking algorithm: {{c1::the failure or suspension of one thread cannot cause the failure or suspension of another thread}}. <br><br>Contrast with locks/blocking, where {{c1::one thread can indefinitely delay another (e.g. by dying inside the critical section)}}.
is broken because the busy-wait holds the monitor lock the entire time, so no other thread (including the consumer that would make space) can enter the object: the producer spins forever and the consumer blocks at the entry. Effectively a deadlock between the spinning producer and any thread that would change the condition.
is broken because the busy-wait holds the monitor lock the entire time, so no other thread (including the consumer that would make space) can enter the object: the producer spins forever and the consumer blocks at the entry. Effectively a deadlock between the spinning producer and any thread that would change the condition.
Lesson: any "wait until condition" pattern under a held lock must release the lock while waiting and reacquire it before re-checking. That is exactly what wait() / await() do.
is broken because the busy-wait holds the monitor lock the entire time, so no other thread (including the consumer that would make space) can enter the object: the producer spins forever and the consumer blocks at the entry.
is broken because the busy-wait holds the monitor lock the entire time, so no other thread (including the consumer that would make space) can enter the object: the producer spins forever and the consumer blocks at the entry.
Effectively a deadlock between the spinning producer and any thread that would change the condition.
Lesson: any "wait until condition" pattern under a held lock must release the lock while waiting and reacquire it before re-checking. That is exactly what wait() / await() do.
Field-by-field Comparison
Field
Before
After
Text
Naive synchronised producer-consumer queue <pre>synchronized void enqueue(long item) {
while (isFull()) ; // wait
doEnqueue(item);
}</pre>is broken because {{c1::the busy-wait holds the monitor lock the entire time, so no other thread (including the consumer that would make space) can enter the object}}: the producer spins forever and the consumer blocks at the entry. Effectively a {{c2::deadlock between the spinning producer and any thread that would change the condition}}.
Naive synchronised producer-consumer queue <pre><img src="paste-eea7872cc5db3b20396a45f6da628e9737336653.jpg"><br></pre>is broken because {{c1::the busy-wait holds the monitor lock the entire time, so no other thread (including the consumer that would make space) can enter the object: the producer spins forever and the consumer blocks at the entry}}.<br>
Extra
Lesson: any "wait until condition" pattern under a held lock must <em>release</em> the lock while waiting and reacquire it before re-checking. That is exactly what <code>wait()</code> / <code>await()</code> do.
Effectively a deadlock between the spinning producer and any thread that would change the condition.<br><br>Lesson: any "wait until condition" pattern under a held lock must <em>release</em> the lock while waiting and reacquire it before re-checking. That is exactly what <code>wait()</code> / <code>await()</code> do.
Replacing the busy-wait with Thread.sleep(timeout) outside the synchronized block (while(true){ synchronized(this){ if (!isFull()){ doEnqueue(...); return; }} sleep(t); }) fixes the deadlock but has no good value for timeout: too short wastes CPU on repeated re-acquisition, too long adds latency between the queue freeing up and the producer noticing. The real wish is to be notified exactly when the condition becomes true (i.e. when a consumer dequeues), not to poll.
Replacing the busy-wait with Thread.sleep(timeout) outside the synchronized block (while(true){ synchronized(this){ if (!isFull()){ doEnqueue(...); return; }} sleep(t); }) fixes the deadlock but has no good value for timeout: too short wastes CPU on repeated re-acquisition, too long adds latency between the queue freeing up and the producer noticing. The real wish is to be notified exactly when the condition becomes true (i.e. when a consumer dequeues), not to poll.
This motivates monitors / wait-notify: instead of polling, the producer waits on a condition and the consumer signals it after dequeuing.
Replacing the busy-wait with Thread.sleep(timeout) fixes the deadlock but has no good value for timeout: too short wastes CPU on repeated re-acquisition, too long adds latency between the queue freeing up and the producer noticing.
The real wish is to be notified exactly when the condition becomes true (i.e. when a consumer dequeues), not to poll.
Replacing the busy-wait with Thread.sleep(timeout) fixes the deadlock but has no good value for timeout: too short wastes CPU on repeated re-acquisition, too long adds latency between the queue freeing up and the producer noticing.
The real wish is to be notified exactly when the condition becomes true (i.e. when a consumer dequeues), not to poll.
This motivates monitors / wait-notify: instead of polling, the producer waits on a condition and the consumer signals it after dequeuing.
Field-by-field Comparison
Field
Before
After
Text
Replacing the busy-wait with <code>Thread.sleep(timeout)</code> outside the synchronized block (<code>while(true){ synchronized(this){ if (!isFull()){ doEnqueue(...); return; }} sleep(t); }</code>) fixes the deadlock but {{c1::has no good value for <code>timeout</code>}}: too short wastes CPU on repeated re-acquisition, too long adds latency between the queue freeing up and the producer noticing. The real wish is {{c2::to be notified exactly when the condition becomes true (i.e. when a consumer dequeues), not to poll}}.
<img src="paste-f0edd97657a8cdf0cd5fe2d3b45372990734473e.jpg"><br><br>Replacing the busy-wait with <code>Thread.sleep(timeout)</code> fixes the deadlock but {{c1::has no good value for <code>timeout</code>: too short wastes CPU on repeated re-acquisition, too long adds latency between the queue freeing up and the producer noticing}}. <br><br>The real wish is {{c2::to be notified exactly when the condition becomes true (i.e. when a consumer dequeues), not to poll}}.
Concrete two-step lock-free remove(c), where each node's next field is an AtomicMarkableReference:
1. try to set the mark on c.next (c.next.attemptMark(d, true))
2. try CAS on b.next:
expected: [reference=c, mark=unmarked]
new: [reference=d, mark=unmarked]
Both steps are "try to" because either CAS may fail if a concurrent thread has changed the relevant field in the meantime. On failure of step 1, another thread already marked or modified c; restart the operation; on failure of step 2, b is no longer c's predecessor; the physical unlinking can be left to a later traversal that encounters the marked node.
Concrete two-step lock-free remove(c), where each node's next field is an AtomicMarkableReference:
1. try to set the mark on c.next (c.next.attemptMark(d, true))
2. try CAS on b.next:
expected: [reference=c, mark=unmarked]
new: [reference=d, mark=unmarked]
Both steps are "try to" because either CAS may fail if a concurrent thread has changed the relevant field in the meantime. On failure of step 1, another thread already marked or modified c; restart the operation; on failure of step 2, b is no longer c's predecessor; the physical unlinking can be left to a later traversal that encounters the marked node.
This is the core lock-free pattern: each thread that walks the list and stumbles over a marked node helps unlink it ("helping"). That property is what gives the algorithm its lock-freedom guarantee.
Both steps are "try to" because either CAS may fail if a concurrent thread has changed the relevant field in the meantime.
On failure of step 1, another thread already marked or modified c; restart the operation; on failure of step 2, b is no longer c's predecessor; the physical unlinking can be left to a later traversal that encounters the marked node.
Both steps are "try to" because either CAS may fail if a concurrent thread has changed the relevant field in the meantime.
On failure of step 1, another thread already marked or modified c; restart the operation; on failure of step 2, b is no longer c's predecessor; the physical unlinking can be left to a later traversal that encounters the marked node.
This is the core lock-free pattern: each thread that walks the list and stumbles over a marked node helps unlink it ("helping"). That property is what gives the algorithm its lock-freedom guarantee.
Field-by-field Comparison
Field
Before
After
Text
Concrete two-step lock-free <code>remove(c)</code>, where each node's <code>next</code> field is an <code>AtomicMarkableReference</code>: <pre>1. try to set the mark on c.next (c.next.attemptMark(d, true))
2. try CAS on b.next:
expected: [reference=c, mark=unmarked]
new: [reference=d, mark=unmarked]</pre> Both steps are "try to" because {{c1::either CAS may fail if a concurrent thread has changed the relevant field in the meantime}}. On failure of step 1, {{c2::another thread already marked or modified <code>c</code>; restart the operation}}; on failure of step 2, {{c3::<code>b</code> is no longer <code>c</code>'s predecessor; the physical unlinking can be left to a later traversal that encounters the marked node}}.
<img src="paste-4a4e8c4e35658cf973aec295541d4a04144b1925.jpg"><br><br>Both steps are "try to" because {{c1::either CAS may fail if a concurrent thread has changed the relevant field in the meantime}}. <br><br>On failure of step 1, {{c2::another thread already marked or modified <code>c</code>; restart the operation}}; <br>on failure of step 2, {{c3::<code>b</code> is no longer <code>c</code>'s predecessor; the physical unlinking can be left to a later traversal that encounters the marked node}}.
The FIFO-fair RW lock keeps five counters: writers: number of writers in the CS (\(\leq 1\)); readers: number of readers in the CS; writersWaiting: number of writers trying to enter the CS; readersWaiting: number of readers trying to enter the CS; writersWait: number of readers the writers still have to wait for (the remaining quota \(k\)).
The FIFO-fair RW lock keeps five counters: writers: number of writers in the CS (\(\leq 1\)); readers: number of readers in the CS; writersWaiting: number of writers trying to enter the CS; readersWaiting: number of readers trying to enter the CS; writersWait: number of readers the writers still have to wait for (the remaining quota \(k\)).
writers: number of writers in the CS (\(\leq 1\));
readers: number of readers in the CS;
writersWaiting: number of writers trying to enter the CS;
readersWaiting: number of readers trying to enter the CS;
writersWait: number of readers the writers still have to wait for (the remaining quota \(k\)).
Field-by-field Comparison
Field
Before
After
Text
The FIFO-fair RW lock keeps five counters:{{c1::<code>writers</code>}}: {{c2::number of writers in the CS (\(\leq 1\))}}; {{c1::<code>readers</code>}}: {{c2::number of readers in the CS}}; {{c3::<code>writersWaiting</code>}}: {{c4::number of writers trying to enter the CS}}; {{c3::<code>readersWaiting</code>}}: {{c4::number of readers trying to enter the CS}}; {{c5::<code>writersWait</code>}}: {{c6::number of readers the writers still have to wait for (the remaining quota \(k\))}}.
The FIFO-fair RW lock keeps five counters:<br><ol><li>{{c1::<code>writers</code>: number of writers in the CS (\(\leq 1\))}}; </li><li>{{c1::<code>readers</code>: number of readers in the CS}}; </li><li>{{c2::<code>writersWaiting</code>: number of writers trying to enter the CS}}; </li><li>{{c2::<code>readersWaiting</code>: number of readers trying to enter the CS}}; </li><li>{{c3::<code>writersWait</code>: number of readers the writers still have to wait for (the remaining quota \(k\))}}.</li></ol>
Plain mutual exclusion is unnecessarily conservative when reads dominate: concurrent read/read on the same memory is harmless but still gets serialised. Real conflicts only arise on write/write or read/write. A reader/writer lock therefore allows multiple concurrent readers, but at most one writer and no readers in parallel with that writer.
Plain mutual exclusion is unnecessarily conservative when reads dominate: concurrent read/read on the same memory is harmless but still gets serialised. Real conflicts only arise on write/write or read/write. A reader/writer lock therefore allows multiple concurrent readers, but at most one writer and no readers in parallel with that writer.
Example: a hashtable that almost only sees lookup and rarely insert (Wikipedia: ~0.12% write rate) wastes essentially all parallelism under a coarse-grained mutex. Crucially, lookup must really be read-only (no move-to-front or similar mutation).
Plain mutual exclusion is unnecessarily conservative when reads dominate: concurrent read/read on the same memory is harmless but still gets serialised.
Real conflicts only arise on write/write or read/write. A reader/writer lock therefore allows multiple concurrent readers, but at most one writer and no readers in parallel with that writer.
Plain mutual exclusion is unnecessarily conservative when reads dominate: concurrent read/read on the same memory is harmless but still gets serialised.
Real conflicts only arise on write/write or read/write. A reader/writer lock therefore allows multiple concurrent readers, but at most one writer and no readers in parallel with that writer.
Example: a hashtable that almost only sees lookup and rarely insert (Wikipedia: ~0.12% write rate) wastes essentially all parallelism under a coarse-grained mutex. Crucially, lookup must really be read-only (no move-to-front or similar mutation).
Field-by-field Comparison
Field
Before
After
Text
Plain mutual exclusion is unnecessarily conservative when reads dominate: {{c1::concurrent <em>read/read</em> on the same memory is harmless}} but still gets serialised. Real conflicts only arise on {{c2::write/write or read/write}}. A <em>reader/writer lock</em> therefore allows {{c3::multiple concurrent readers, but at most one writer and no readers in parallel with that writer}}.
Plain mutual exclusion is unnecessarily conservative when reads dominate: {{c1::concurrent <em>read/read</em> on the same memory is harmless but still gets serialised}}. <br><br>Real conflicts only arise on write/write or read/write. A <em>reader/writer lock</em> therefore allows {{c2::multiple concurrent readers, but at most one writer and no readers in parallel with that writer}}.
enqueue(x): m--; // claim a slot in advance
if (m < 0) while (isFull()) notFull.await();
doEnqueue(x);
n++;
if (n <= 0) notEmpty.signal();
dequeue(): n--;
if (n < 0) while (isEmpty()) notEmpty.await();
doDequeue();
m++;
if (m <= 0) notFull.signal();
The decrement-first / check-negative pattern: m-- followed by if (m < 0) reserves a slot and detects "buffer was full" before waiting; n++ followed by if (n <= 0) means "after my insert there is at least one consumer still waiting", so signal exactly then, saving the call when n > 0 (no one is waiting).
enqueue(x): m--; // claim a slot in advance
if (m < 0) while (isFull()) notFull.await();
doEnqueue(x);
n++;
if (n <= 0) notEmpty.signal();
dequeue(): n--;
if (n < 0) while (isEmpty()) notEmpty.await();
doDequeue();
m++;
if (m <= 0) notFull.signal();
The decrement-first / check-negative pattern: m-- followed by if (m < 0) reserves a slot and detects "buffer was full" before waiting; n++ followed by if (n <= 0) means "after my insert there is at least one consumer still waiting", so signal exactly then, saving the call when n > 0 (no one is waiting).
The asymmetry < 0 vs <= 0 on the wait side vs the signal side is intentional: at the moment of my own increment, my counter has just become +1 if I was the only waiter, so the condition for "someone else is still waiting" is <= 0.
The decrement-first / check-negative pattern: m-- followed by if (m < 0) reserves a slot and detects "buffer was full" before waiting; n++ followed by if (n <= 0) means "after my insert there is at least one consumer still waiting", so signal exactly then, saving the call when n > 0 (no one is waiting).
The decrement-first / check-negative pattern: m-- followed by if (m < 0) reserves a slot and detects "buffer was full" before waiting; n++ followed by if (n <= 0) means "after my insert there is at least one consumer still waiting", so signal exactly then, saving the call when n > 0 (no one is waiting).
The asymmetry < 0 vs <= 0 on the wait side vs the signal side is intentional: at the moment of my own increment, my counter has just become +1 if I was the only waiter, so the condition for "someone else is still waiting" is <= 0.
Field-by-field Comparison
Field
Before
After
Text
Sleeping-Barber producer-consumer signalling logic: <pre>enqueue(x): m--; // claim a slot in advance
if (m < 0) while (isFull()) notFull.await();
doEnqueue(x);
n++;
if (n <= 0) notEmpty.signal();
dequeue(): n--;
if (n < 0) while (isEmpty()) notEmpty.await();
doDequeue();
m++;
if (m <= 0) notFull.signal();</pre>The decrement-first / check-negative pattern: {{c1::<code>m--</code> followed by <code>if (m < 0)</code> reserves a slot and detects "buffer was full" before waiting}}; {{c2::<code>n++</code> followed by <code>if (n <= 0)</code> means "after my insert there is at least one consumer still waiting", so signal exactly then, saving the call when <code>n > 0</code> (no one is waiting)}}.
Sleeping-Barber producer-consumer signalling logic: <pre><img src="paste-65cd4bf85fa2ddd5b48c98879968a44accaa46ef.jpg"><br></pre>The decrement-first / check-negative pattern: {{c1::<code>m--</code> followed by <code>if (m < 0)</code> reserves a slot and detects "buffer was full" before waiting}}; {{c2::<code>n++</code> followed by <code>if (n <= 0)</code> means "after my insert there is at least one consumer still waiting", so signal exactly then, saving the call when <code>n > 0</code> (no one is waiting)}}.
Fine-grained locking: the object is split into pieces with one lock per piece, so that operations on disjoint pieces no longer exclude each other. On a linked list this means one lock per node. In practice it tends to be more intricate than it looks and requires careful handling of special cases.
Fine-grained locking: the object is split into pieces with one lock per piece, so that operations on disjoint pieces no longer exclude each other. On a linked list this means one lock per node. In practice it tends to be more intricate than it looks and requires careful handling of special cases.
Fine-grained locking: The object is split into pieces with one lock per piece, so that operations on disjoint pieces no longer exclude each other.
On a linked list this means one lock per node. In practice it tends to be more intricate than it looks and requires careful handling of special cases.
Field-by-field Comparison
Field
Before
After
Text
Fine-grained locking: {{c1::the object is split into pieces with one lock per piece}}, so that {{c2::operations on disjoint pieces no longer exclude each other}}. On a linked list this means one lock per node. In practice it tends to be {{c3::more intricate than it looks and requires careful handling of special cases}}.
Fine-grained locking: <br>{{c1::The object is split into pieces with one lock per piece}}, so that {{c1::operations on disjoint pieces no longer exclude each other}}.
Extra
On a linked list this means one lock per node. In practice it tends to be more intricate than it looks and requires careful handling of special cases.
In the producer-consumer pattern, thread \(T_0\) computes a value \(X\) and passes it to \(T_1\) which uses \(X\). Synchronisation on \(X\) itself is not needed, because at any point in time only one thread accesses \(X\); what is needed is a synchronised mechanism to pass \(X\) from \(T_0\) to \(T_1\) (typically a queue).
In the producer-consumer pattern, thread \(T_0\) computes a value \(X\) and passes it to \(T_1\) which uses \(X\). Synchronisation on \(X\) itself is not needed, because at any point in time only one thread accesses \(X\); what is needed is a synchronised mechanism to pass \(X\) from \(T_0\) to \(T_1\) (typically a queue).
Producer-consumer is a fundamental parallel-programming pattern. Pipelines \(T_0 \to T_1 \to T_2\) generalise it: middle stages are both producer and consumer. Programmable hardware like Intel Stratix 10 (30 billion transistors) is built around exactly this dataflow style.
In the producer-consumer pattern, thread \(T_0\) computes a value \(X\) and passes it to \(T_1\) which uses \(X\). Synchronisation on \(X\) itself is not needed, because at any point in time only one thread accesses \(X\); what is needed is a synchronised mechanism to pass \(X\) from \(T_0\) to \(T_1\) (typically a queue).
In the producer-consumer pattern, thread \(T_0\) computes a value \(X\) and passes it to \(T_1\) which uses \(X\). Synchronisation on \(X\) itself is not needed, because at any point in time only one thread accesses \(X\); what is needed is a synchronised mechanism to pass \(X\) from \(T_0\) to \(T_1\) (typically a queue).
Producer-consumer is a fundamental parallel-programming pattern. Pipelines \(T_0 \to T_1 \to T_2\) generalise it: middle stages are both producer and consumer. Programmable hardware like Intel Stratix 10 (30 billion transistors) is built around exactly this dataflow style.
Field-by-field Comparison
Field
Before
After
Text
In the producer-consumer pattern, thread \(T_0\) computes a value \(X\) and passes it to \(T_1\) which uses \(X\). Synchronisation on \(X\) itself is {{c1::not needed, because at any point in time only one thread accesses \(X\)}}; what is needed is {{c2::a synchronised mechanism to pass \(X\) from \(T_0\) to \(T_1\) (typically a queue)}}.
In the producer-consumer pattern, thread \(T_0\) computes a value \(X\) and passes it to \(T_1\) which uses \(X\). Synchronisation on \(X\) itself is {{c1::not needed, because at any point in time only one thread accesses \(X\)}}; what is needed is {{c1::a synchronised mechanism to pass \(X\) from \(T_0\) to \(T_1\) (typically a queue)}}.
Extra
Producer-consumer is a fundamental parallel-programming pattern. Pipelines \(T_0 \to T_1 \to T_2\) generalise it: middle stages are both producer and consumer. Programmable hardware like Intel Stratix 10 (30 billion transistors) is built around exactly this dataflow style.
<img src="paste-040519606e77ba406b90a84a2cb9f8ad340e7614.jpg"><br><br>Producer-consumer is a fundamental parallel-programming pattern. Pipelines \(T_0 \to T_1 \to T_2\) generalise it: middle stages are both producer and consumer. Programmable hardware like Intel Stratix 10 (30 billion transistors) is built around exactly this dataflow style.
Concurrent remove(c) by A and remove(b) by B on a lock-free list with AtomicMarkableReference: both threads first mark their victim's next. When B then tries the DCAS a.next.CAS([b, unmarked], [c, unmarked]), it fails, because b.next is now marked (no longer matches the expected unmarked). The outcome: c remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries.
Concurrent remove(c) by A and remove(b) by B on a lock-free list with AtomicMarkableReference: both threads first mark their victim's next. When B then tries the DCAS a.next.CAS([b, unmarked], [c, unmarked]), it fails, because b.next is now marked (no longer matches the expected unmarked). The outcome: c remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries.
This is the core observation: the mark bit on b.next is what protects c from being silently "un-deleted" by a concurrent operation on the predecessor. The DCAS over (reference, mark) ties the two together.
When B then tries the DCAS a.next.CAS([b, unmarked], [c, unmarked]), it fails, because b.next is now marked (no longer matches the expected unmarked).
The outcome: c remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries.
This is the core observation: the mark bit on b.next is what protects c from being silently "un-deleted" by a concurrent operation on the predecessor. The DCAS over (reference, mark) ties the two together.
Field-by-field Comparison
Field
Before
After
Text
Concurrent <code>remove(c)</code> by A and <code>remove(b)</code> by B on a lock-free list with <code>AtomicMarkableReference</code>: both threads first mark their victim's <code>next</code>. When B then tries the DCAS <code>a.next.CAS([b, unmarked], [c, unmarked])</code>, it {{c1::fails, because <code>b.next</code> is now <em>marked</em> (no longer matches the expected <code>unmarked</code>)}}. The outcome: {{c2::<code>c</code> remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries}}.
<img src="paste-523b2fefcec325a0f186866b45559ed7c9bc2623.jpg"><br><br>When B then tries the DCAS <code>a.next.CAS([b, unmarked], [c, unmarked])</code>, it {{c1::fails, because <code>b.next</code> is now <em>marked</em> (no longer matches the expected <code>unmarked</code>)}}. <br><br>The outcome: {{c2::<code>c</code> remains logically deleted (marked) and will be physically unlinked by some later traverser, while B retries}}.
A Java Condition (obtained via lock.newCondition()) offers await(): must be called with the lock held; atomically releases the lock and waits until the thread is signalled; on return, the lock is guaranteed to be held again; the thread always needs to re-check the condition (use while, not if). Plus signal() / signalAll(): also called with the lock held, wakes one or all threads waiting on this specific condition.
A Java Condition (obtained via lock.newCondition()) offers await(): must be called with the lock held; atomically releases the lock and waits until the thread is signalled; on return, the lock is guaranteed to be held again; the thread always needs to re-check the condition (use while, not if). Plus signal() / signalAll(): also called with the lock held, wakes one or all threads waiting on this specific condition.
Crucial difference from wait/notify on intrinsic locks: a single lock can have multiple conditions, so producers and consumers can wait on different ones (notFull, notEmpty) and the right kind of waiter can be woken directly without notifying all.
A Java Condition (obtained via lock.newCondition()) offers await():
must be called with the lock held;
atomically releases the lock and waits until the thread is signalled;
on return, the lock is guaranteed to be held again;
the thread always needs to re-check the condition (use while, not if).
Plus signal() / signalAll(): also called with the lock held, wakes one or all threads waiting on this specific condition.
Crucial difference from wait/notify on intrinsic locks: a single lock can have multiple conditions, so producers and consumers can wait on different ones (notFull, notEmpty) and the right kind of waiter can be woken directly without notifying all.
Field-by-field Comparison
Field
Before
After
Text
A Java <code>Condition</code> (obtained via <code>lock.newCondition()</code>) offers {{c1::<code>await()</code>}}: must be called with the lock held;{{c2::atomically releases the lock and waits until the thread is signalled}};on return, the lock is {{c3::guaranteed to be held again}};the thread {{c4::always needs to re-check the condition (use <code>while</code>, not <code>if</code>)}}.Plus <code>signal()</code> / <code>signalAll()</code>: also called with the lock held, wakes one or all threads waiting on this specific condition.
A Java <code>Condition</code> (obtained via <code>lock.newCondition()</code>) offers {{c1::<code>await()</code>}}: <br><ol><li>must be called with the lock held; </li><li>{{c2::atomically releases the lock and waits until the thread is signalled}}; </li><li>on return, the lock is {{c3::guaranteed to be held again}}; </li><li>the thread {{c4::always needs to re-check the condition (use <code>while</code>, not <code>if</code>)}}.</li></ol>Plus <code>signal()</code> / <code>signalAll()</code>: also called with the lock held, wakes one or all threads waiting on this specific condition.<br>
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via synchronized methods. Pro: simple and obviously correct. Con: a single bottleneck for all threads, no parallelism even between disjoint operations.
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via synchronized methods. Pro: simple and obviously correct. Con: a single bottleneck for all threads, no parallelism even between disjoint operations.
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via synchronized methods.
Pro: simple and obviously correct. Con: a single bottleneck for all threads, no parallelism even between disjoint operations.
Field-by-field Comparison
Field
Before
After
Text
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via <code>synchronized</code> methods. Pro: {{c1::simple and obviously correct}}. Con: {{c2::a single bottleneck for all threads, no parallelism even between disjoint operations}}.
Coarse-grained locking on a list-based set: every operation is guarded by a single lock, e.g. via <code>synchronized</code> methods. <br><br>Pro: {{c1::simple and obviously correct}}. <br>Con: {{c1::a single bottleneck for all threads, no parallelism even between disjoint operations}}.
The standard CAS update pattern (here for an AtomicInteger counter):
int v;
do {
v = value.get(); // (a) read current
} while (!value.compareAndSet(v, v+1)); // (b) compute v'; (c) CAS; (d) return on success
return v+1;
A successful CAS suggests (not guarantees) that no other thread has written between (a) and (c). If a thread dies inside the loop, other threads are unaffected and continue to make progress, and if two threads see the same v, exactly one CAS succeeds, the other one retries.
The standard CAS update pattern (here for an AtomicInteger counter):
int v;
do {
v = value.get(); // (a) read current
} while (!value.compareAndSet(v, v+1)); // (b) compute v'; (c) CAS; (d) return on success
return v+1;
A successful CAS suggests (not guarantees) that no other thread has written between (a) and (c). If a thread dies inside the loop, other threads are unaffected and continue to make progress, and if two threads see the same v, exactly one CAS succeeds, the other one retries.
This is the canonical lock-free read-modify-write pattern. The reason for "suggests, not guarantees" is the ABA problem: a value can be changed and changed back between (a) and (c), and CAS cannot tell the difference.
The standard CAS update pattern (here for an AtomicInteger counter):
A successful CAS suggests (not guarantees) that no other thread has written between (a) and (c).
If a thread dies inside the loop, other threads are unaffected and continue to make progress, and if two threads see the same v, exactly one CAS succeeds, the other one retries.
The standard CAS update pattern (here for an AtomicInteger counter):
A successful CAS suggests (not guarantees) that no other thread has written between (a) and (c).
If a thread dies inside the loop, other threads are unaffected and continue to make progress, and if two threads see the same v, exactly one CAS succeeds, the other one retries.
This is the canonical lock-free read-modify-write pattern. The reason for "suggests, not guarantees" is the ABA problem: a value can be changed and changed back between (a) and (c), and CAS cannot tell the difference.
Field-by-field Comparison
Field
Before
After
Text
The standard CAS update pattern (here for an <code>AtomicInteger</code> counter): <pre>int v;
do {
v = value.get(); // (a) read current
} while (!value.compareAndSet(v, v+1)); // (b) compute v'; (c) CAS; (d) return on success
return v+1;</pre> A successful CAS {{c1::<em>suggests</em> (not guarantees) that no other thread has written between (a) and (c)}}. If a thread dies inside the loop, other threads {{c2::are unaffected and continue to make progress}}, and if two threads see the same <code>v</code>, {{c3::exactly one CAS succeeds, the other one retries}}.
The standard CAS update pattern (here for an <code>AtomicInteger</code> counter):<br><br><img src="paste-81d2825fd792ee1f9c50149407103c6e04398658.jpg"><br><br>A successful CAS {{c1::<em>suggests</em> (not guarantees) that no other thread has written between (a) and (c)}}. <br><br>If a thread dies inside the loop, other threads {{c2::are unaffected and continue to make progress}}, and if two threads see the same <code>v</code>, {{c2::exactly one CAS succeeds, the other one retries}}.
Why this is cleaner than synchronized + wait / notifyAll: with two conditions, the producer signals only consumers on notEmpty, not all waiters on the object's single intrinsic queue, so signal() instead of signalAll() suffices in this pattern (every waiter on notEmpty is a consumer, every waiter on notFull is a producer, no risk of waking the wrong kind of thread).
Why this is cleaner than synchronized + wait / notifyAll: with two conditions, the producer signals only consumers on notEmpty, not all waiters on the object's single intrinsic queue, so signal() instead of signalAll() suffices in this pattern (every waiter on notEmpty is a consumer, every waiter on notFull is a producer, no risk of waking the wrong kind of thread).
With a single intrinsic monitor and one queue (mixing producers and consumers), notify() could wake a producer when the queue is full, which would just go back to wait: hence notifyAll is required there.
Producer-consumer with ReentrantLock + two conditions notFull and notEmpty:
Why this is cleaner than synchronized + wait / notifyAll: with two conditions, the producer signals only consumers on notEmpty, not all waiters on the object's single intrinsic queue, so signal() instead of signalAll() suffices in this pattern (every waiter on notEmpty is a consumer, every waiter on notFull is a producer, no risk of waking the wrong kind of thread).
Producer-consumer with ReentrantLock + two conditions notFull and notEmpty:
Why this is cleaner than synchronized + wait / notifyAll: with two conditions, the producer signals only consumers on notEmpty, not all waiters on the object's single intrinsic queue, so signal() instead of signalAll() suffices in this pattern (every waiter on notEmpty is a consumer, every waiter on notFull is a producer, no risk of waking the wrong kind of thread).
With a single intrinsic monitor and one queue (mixing producers and consumers), notify() could wake a producer when the queue is full, which would just go back to wait: hence notifyAll is required there.
Field-by-field Comparison
Field
Before
After
Text
Producer-consumer with <code>ReentrantLock</code> + two conditions <code>notFull</code> and <code>notEmpty</code>: <pre>void enqueue(long x) {
lock.lock();
while (isFull()) notFull.await();
doEnqueue(x);
notEmpty.signal();
lock.unlock();
}</pre>Why this is cleaner than <code>synchronized</code> + <code>wait</code> / <code>notifyAll</code>: {{c1::with two conditions, the producer signals only consumers on <code>notEmpty</code>, not all waiters on the object's single intrinsic queue}}, so {{c2::<code>signal()</code> instead of <code>signalAll()</code> suffices in this pattern (every waiter on <code>notEmpty</code> is a consumer, every waiter on <code>notFull</code> is a producer, no risk of waking the wrong kind of thread)}}.
Producer-consumer with <code>ReentrantLock</code> + two conditions <code>notFull</code> and <code>notEmpty</code>: <pre><img src="paste-323a806c2678409c830c5e88e60b4446fa26f64d.jpg"><br></pre>Why this is cleaner than <code>synchronized</code> + <code>wait</code> / <code>notifyAll</code>: {{c1::with two conditions, the producer signals only consumers on <code>notEmpty</code>, not all waiters on the object's single intrinsic queue}}, so {{c2::<code>signal()</code> instead of <code>signalAll()</code> suffices in this pattern (every waiter on <code>notEmpty</code> is a consumer, every waiter on <code>notFull</code> is a producer, no risk of waking the wrong kind of thread)}}.
Why the first CAS of the lock-free enqueue (CAS(last.next, null, new)) can fail: another thread wrote last.next just before me, or I read a stale tail -- either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing tail. Conclusion: if my CAS fails, I should not blindly retry on the same last; I must re-read tail first.
Why the first CAS of the lock-free enqueue (CAS(last.next, null, new)) can fail: another thread wrote last.next just before me, or I read a stale tail -- either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing tail. Conclusion: if my CAS fails, I should not blindly retry on the same last; I must re-read tail first.
Case (c3) is exactly the scenario that forces helping in the final version: a future dequeuer or enqueuer must be willing to advance tail on behalf of a thread that may never return.
Why the first CAS of the lock-free enqueue (CAS(last.next, null, new)) can fail: Another thread wrote last.next just before me, or I read a stale tail - either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing tail.
Conclusion: if my CAS fails, I should not blindly retry on the same last; I must re-read tail first.
Why the first CAS of the lock-free enqueue (CAS(last.next, null, new)) can fail: Another thread wrote last.next just before me, or I read a stale tail - either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing tail.
Conclusion: if my CAS fails, I should not blindly retry on the same last; I must re-read tail first.
Case 3 is exactly the scenario that forces helping in the final version: a future dequeuer or enqueuer must be willing to advance tail on behalf of a thread that may never return.
Field-by-field Comparison
Field
Before
After
Text
Why the first CAS of the lock-free enqueue (<code>CAS(last.next, null, new)</code>) can fail: {{c1::another thread wrote <code>last.next</code> just before me}}, or {{c2::I read a stale <code>tail</code>}} -- either because I missed an update or {{c3::because some earlier enqueuer failed (e.g. died) before advancing <code>tail</code>}}. Conclusion: if my CAS fails, {{c4::I should not blindly retry on the same <code>last</code>; I must re-read <code>tail</code> first}}.
Why the first CAS of the lock-free enqueue (<code>CAS(last.next, null, new)</code>) can fail: <br>{{c1::Another thread wrote <code>last.next</code> just before me}}, or {{c2::I read a stale <code>tail</code> - either because I missed an update or because some earlier enqueuer failed (e.g. died) before advancing <code>tail</code>}}. <br><br>Conclusion: if my CAS fails, {{c3::I should not blindly retry on the same <code>last</code>; I must re-read <code>tail</code> first}}.
Extra
Case (c3) is exactly the scenario that forces helping in the final version: a future dequeuer or enqueuer must be willing to advance <code>tail</code> on behalf of a thread that may never return.
Case 3 is exactly the scenario that forces helping in the final version: a future dequeuer or enqueuer must be willing to advance <code>tail</code> on behalf of a thread that may never return.
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: finish the job, i.e. CAS the predecessor's next field past the marked node and continue (repeating as needed if more marked nodes follow).
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: finish the job, i.e. CAS the predecessor's next field past the marked node and continue (repeating as needed if more marked nodes follow).
This is the canonical helping pattern: every traverser shares responsibility for completing the physical-delete step that another thread left half-done. Without it, a thread that died right after step 1 of remove would leave a marked node in the list forever, which would not violate correctness, but would degrade performance and is incompatible with practical use.
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: finish the job, i.e. CAS the predecessor's next field past the marked node and continue (repeating as needed if more marked nodes follow).
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: finish the job, i.e. CAS the predecessor's next field past the marked node and continue (repeating as needed if more marked nodes follow).
This is the canonical helping pattern: every traverser shares responsibility for completing the physical-delete step that another thread left half-done. Without it, a thread that died right after step 1 of remove would leave a marked node in the list forever, which would not violate correctness, but would degrade performance and is incompatible with practical use.
Field-by-field Comparison
Field
Before
After
Text
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: {{c1::finish the job}}, i.e. {{c2::<code>CAS</code> the predecessor's <code>next</code> field past the marked node}} and {{c3::continue (repeating as needed if more marked nodes follow)}}.
Lock-free list-set traversal policy when stumbling over a logically deleted (marked) node: <br>{{c1::finish the job}}, i.e. {{c1::<code>CAS</code> the predecessor's <code>next</code> field past the marked node and continue (repeating as needed if more marked nodes follow)}}.
Two progress conditions for non-blocking algorithms: lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation); wait-freedom: every thread eventually makes progress (implies freedom from starvation). Wait-freedom is strictly stronger than lock-freedom.
Two progress conditions for non-blocking algorithms: lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation); wait-freedom: every thread eventually makes progress (implies freedom from starvation). Wait-freedom is strictly stronger than lock-freedom.
"Implies" here is the standard arrow: every wait-free algorithm is automatically lock-free, but not vice versa.
Two progress conditions for non-blocking algorithms:
lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation);
wait-freedom: every thread eventually makes progress (implies freedom from starvation).
Wait-freedom is strictly stronger than lock-freedom.
Two progress conditions for non-blocking algorithms:
lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation);
wait-freedom: every thread eventually makes progress (implies freedom from starvation).
Wait-freedom is strictly stronger than lock-freedom.
"Implies" here is the standard arrow: every wait-free algorithm is automatically lock-free, but not vice versa.
Field-by-field Comparison
Field
Before
After
Text
Two progress conditions for non-blocking algorithms: {{c1::lock-freedom}}: {{c2::at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation)}}; {{c3::wait-freedom}}: {{c4::every thread eventually makes progress (implies freedom from starvation)}}. Wait-freedom is strictly stronger than lock-freedom.
Two progress conditions for non-blocking algorithms: <br><ol><li>{{c1::lock-freedom: at least one thread always makes progress, even if other threads run concurrently (implies system-wide progress, but not freedom from starvation)}}; </li><li>{{c1::wait-freedom: every thread eventually makes progress (implies freedom from starvation)}}. </li></ol>{{c1::Wait-freedom}} is strictly stronger than {{c1::lock-freedom}}.<br>
Node node = new Node(item);
while (true) {
Node last = tail.get();
Node next = last.next.get();
if (next == null) {
if (last.next.compareAndSet(null, node)) {
tail.compareAndSet(last, node); // try to swing tail
return;
}
} else {
tail.compareAndSet(last, next); // help advance tail
}
}
The else branch is the helping step: if tail.next != null, some other enqueuer is mid-operation, so this thread advances tail on its behalf before retrying.
Node node = new Node(item);
while (true) {
Node last = tail.get();
Node next = last.next.get();
if (next == null) {
if (last.next.compareAndSet(null, node)) {
tail.compareAndSet(last, node); // try to swing tail
return;
}
} else {
tail.compareAndSet(last, next); // help advance tail
}
}
The else branch is the helping step: if tail.next != null, some other enqueuer is mid-operation, so this thread advances tail on its behalf before retrying.
The two compareAndSet calls on tail (in the success branch and in the helping branch) both deliberately ignore their return value: if some other thread has already done the swing, that's fine.
The else branch is the helping step: if tail.next != null, some other enqueuer is mid-operation, so this thread advances tail on its behalf before retrying.
The else branch is the helping step: if tail.next != null, some other enqueuer is mid-operation, so this thread advances tail on its behalf before retrying.
The two compareAndSet calls on tail (in the success branch and in the helping branch) both deliberately ignore their return value: if some other thread has already done the swing, that's fine.
Field-by-field Comparison
Field
Before
After
Text
Final Michael-Scott <code>enqueue</code>: <pre>Node node = new Node(item);
while (true) {
Node last = tail.get();
Node next = last.next.get();
if (next == null) {
if (last.next.compareAndSet(null, node)) {
tail.compareAndSet(last, node); // try to swing tail
return;
}
} else {
tail.compareAndSet(last, next); // help advance tail
}
}</pre> The <code>else</code> branch is the {{c1::helping step}}: if <code>tail.next != null</code>, some other enqueuer is mid-operation, so this thread {{c2::advances <code>tail</code> on its behalf before retrying}}.
Final Michael-Scott <code>enqueue</code>: <pre><img src="paste-da7a49e86c86f22eae56978b8427ea0242296e09.jpg"><br></pre> The <code>else</code> branch is the {{c1::helping step: if <code>tail.next != null</code>, some other enqueuer is mid-operation, so this thread advances <code>tail</code> on its behalf before retrying}}.
synchronized acquire() { if (number <= 0) wait(); number--; }
synchronized release() { number++; if (number > 0) notify(); }
is broken under signal-and-continue semantics (which is what Java uses). Concrete scenario with threads P, Q, R: (1) P entered earlier and decremented number to 0; (2) Q sees 0 and goes to the condition queue; (3) P calls release(): increments number to 1, calls notify() which moves Q to the entry queue, then P exits the monitor; (4) R now calls acquire(), finds number = 1 > 0, decrements to 0 and proceeds; (5) Q, when it finally acquires the lock, decrements number to \(-1\), an inconsistency. The cure: replace if with while (re-check the condition after waking).
synchronized acquire() { if (number <= 0) wait(); number--; }
synchronized release() { number++; if (number > 0) notify(); }
is broken under signal-and-continue semantics (which is what Java uses). Concrete scenario with threads P, Q, R: (1) P entered earlier and decremented number to 0; (2) Q sees 0 and goes to the condition queue; (3) P calls release(): increments number to 1, calls notify() which moves Q to the entry queue, then P exits the monitor; (4) R now calls acquire(), finds number = 1 > 0, decrements to 0 and proceeds; (5) Q, when it finally acquires the lock, decrements number to \(-1\), an inconsistency. The cure: replace if with while (re-check the condition after waking).
Under signal-and-wait the lock would have been handed straight to Q, blocking R, and if would have sufficed. Java's signal-and-continue is what forces the while idiom, together with the possibility of spurious wakeups.
is broken under signal-and-continue semantics (which is what Java uses).
Concrete scenario with threads P, Q, R:
P entered earlier and decremented number to 0;
Q sees 0 and goes to the condition queue;
P calls release(): increments number to 1, calls notify() which moves Q to the entry queue, then P exits the monitor;
R now calls acquire(), finds number = 1 > 0, decrements to 0 and proceeds;
Q, when it finally acquires the lock, decrements number to \(-1\), an inconsistency.
The cure: replace if with while (re-check the condition after waking).
Under signal-and-wait the lock would have been handed straight to Q, blocking R, and if would have sufficed. Java's signal-and-continue is what forces the while idiom, together with the possibility of spurious wakeups.
Field-by-field Comparison
Field
Before
After
Text
A monitor-based semaphore with <pre>synchronized acquire() { if (number <= 0) wait(); number--; }
synchronized release() { number++; if (number > 0) notify(); }</pre>is {{c1::broken under signal-and-continue semantics (which is what Java uses)}}. Concrete scenario with threads P, Q, R: {{c2::(1) P entered earlier and decremented <code>number</code> to 0; (2) Q sees 0 and goes to the condition queue; (3) P calls <code>release()</code>: increments <code>number</code> to 1, calls <code>notify()</code> which moves Q to the entry queue, then P exits the monitor; (4) R now calls <code>acquire()</code>, finds <code>number = 1 > 0</code>, decrements to 0 and proceeds; (5) Q, when it finally acquires the lock, decrements <code>number</code> to \(-1\), an inconsistency}}. The cure: {{c3::replace <code>if</code> with <code>while</code> (re-check the condition after waking)}}.
A monitor-based semaphore with<br><br><img src="paste-52df91ec886813998f65a5822ce80d517f48df1b.jpg"><br><br>is {{c1::broken under signal-and-continue semantics (which is what Java uses)}}. <br><br>Concrete scenario with threads P, Q, R: <br><ol><li>{{c2::P entered earlier and decremented <code>number</code> to 0;}}</li><li>{{c2::Q sees 0 and goes to the condition queue;}} </li><li>{{c2::P calls <code>release()</code>: increments <code>number</code> to 1, calls <code>notify()</code> which moves Q to the entry queue, then P exits the monitor;}}<br></li><li>{{c2::R now calls <code>acquire()</code>, finds <code>number = 1 > 0</code>, decrements to 0 and proceeds; }}<br></li><li>{{c2::Q, when it finally acquires the lock, decrements <code>number</code> to \(-1\), an inconsistency.}}<br></li></ol>The cure: {{c3::replace <code>if</code> with <code>while</code> (re-check the condition after waking)}}.<br>
This naive variant gives priority to readers: while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can starve.
This naive variant gives priority to readers: while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can starve.
Correctness: acquire_write waits until neither writer nor reader is in the CS; acquire_read only waits on writers.
Simple monitor implementation of a reader/writer lock:
This naive variant gives priority to readers: while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can starve.
Simple monitor implementation of a reader/writer lock:
This naive variant gives priority to readers: while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can starve.
Correctness: acquire_write waits until neither writer nor reader is in the CS; acquire_read only waits on writers.
Field-by-field Comparison
Field
Before
After
Text
Simple monitor implementation of a reader/writer lock: <pre>class RWLock {
int writers = 0, readers = 0;
synchronized void acquire_read() {
while (writers > 0) wait();
readers++;
}
synchronized void release_read() { readers--; notifyAll(); }
synchronized void acquire_write() {
while (writers > 0 || readers > 0) wait();
writers++;
}
synchronized void release_write() { writers--; notifyAll(); }
}</pre>This naive variant {{c1::gives priority to readers}}: {{c2::while a reader is active, further readers may enter and the writer stays blocked}}, so under a constant stream of readers a writer can {{c3::starve}}.
Simple monitor implementation of a reader/writer lock: <pre><img src="paste-aedca14a4590ff965ebd9fbc73fb4ca0d23b07f3.jpg"><br></pre>This naive variant gives priority to {{c1::readers: while a reader is active, further readers may enter and the writer stays blocked, so under a constant stream of readers a writer can starve}}.
Three lessons from the lock-free list-set construction. DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once. Lazy + open repair: leaving the physical delete "half-done" is fine as long as any thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise. Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes.
Three lessons from the lock-free list-set construction. DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once. Lazy + open repair: leaving the physical delete "half-done" is fine as long as any thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise. Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes.
The third point distinguishes lock-free from wait-free: lock-freedom only requires that some thread makes progress; wait-freedom requires every thread to finish in a bounded number of steps, which in practice means other threads must complete its half-done operations.
Three lessons from the lock-free list-set construction.
DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once.
Lazy + open repair: leaving the physical delete "half-done" is fine as long as any thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise.
Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes.
Three lessons from the lock-free list-set construction.
DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once.
Lazy + open repair: leaving the physical delete "half-done" is fine as long as any thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise.
Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes.
The third point distinguishes lock-free from wait-free: lock-freedom only requires that some thread makes progress; wait-freedom requires every thread to finish in a bounded number of steps, which in practice means other threads must complete its half-done operations.
Field-by-field Comparison
Field
Before
After
Text
Three lessons from the lock-free list-set construction. {{c1::DCAS via bit-stealing: packing a reference and a flag into one word lets one CAS check two conditions at once}}. {{c2::Lazy + open repair: leaving the physical delete "half-done" is fine as long as <em>any</em> thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise}}. {{c3::Helping is recurring: in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes}}.
Three lessons from the lock-free list-set construction. <br><ol><li>DCAS via bit-stealing: {{c1::packing a reference and a flag into one word lets one CAS check two conditions at once}}. </li><li>Lazy + open repair: {{c2::leaving the physical delete "half-done" is fine as long as <em>any</em> thread is allowed to complete it; requiring a specific thread to finish would be locking in disguise}}. </li><li>Helping is recurring: {{c3::in wait-free algorithms in particular, threads must actively make progress on others' operations ("they may be off in the mountains") in order to guarantee that everyone eventually finishes}}.</li></ol>
Lock performance has two very different regimes. Uncontended: threads do not compete; a good implementation costs roughly one atomic operation. Contended: threads compete; the result is significant performance degradation and possible starvation.
Lock performance has two very different regimes. Uncontended: threads do not compete; a good implementation costs roughly one atomic operation. Contended: threads compete; the result is significant performance degradation and possible starvation.
Specialised lock implementations (queue locks, backoff locks, MCS, etc.) primarily target the contended regime, while keeping the uncontended cost close to a single CAS.
Uncontended: threads do not compete; a good implementation costs roughly one atomic operation.
Contended: threads compete; the result is significant performance degradation and possible starvation.
Specialised lock implementations (queue locks, backoff locks, MCS, etc.) primarily target the contended regime, while keeping the uncontended cost close to a single CAS.
Field-by-field Comparison
Field
Before
After
Text
Lock performance has two very different regimes. {{c1::Uncontended}}: threads do not compete; a good implementation costs {{c2::roughly one atomic operation}}. {{c1::Contended}}: threads compete; the result is {{c3::significant performance degradation and possible starvation}}.
Lock performance has two very different regimes. <br><ol><li>{{c1::Uncontended: threads do not compete; a good implementation costs roughly one atomic operation}}. </li><li>{{c1::Contended: threads compete; the result is significant performance degradation and possible starvation}}.</li></ol>
Two main monitor signalling semantics: signal and wait: the signalling process exits the monitor (goes to the waiting-entry queue) and passes the monitor lock directly to the signalled process. signal and continue: the signalling process continues running and merely moves the signalled process to the waiting-entry queue, where it must reacquire the lock like anyone else.
Two main monitor signalling semantics: signal and wait: the signalling process exits the monitor (goes to the waiting-entry queue) and passes the monitor lock directly to the signalled process. signal and continue: the signalling process continues running and merely moves the signalled process to the waiting-entry queue, where it must reacquire the lock like anyone else.
Other variants exist (signal-and-exit, signal-and-urgent-wait, ...). Java uses signal-and-continue, which has important consequences for how condition checks must be coded (always while, never if).
signal and wait: the signalling process exits the monitor (goes to the waiting-entry queue) and passes the monitor lock directly to the signalled process.
signal and continue: the signalling process continues running and merely moves the signalled process to the waiting-entry queue, where it must reacquire the lock like anyone else.
signal and wait: the signalling process exits the monitor (goes to the waiting-entry queue) and passes the monitor lock directly to the signalled process.
signal and continue: the signalling process continues running and merely moves the signalled process to the waiting-entry queue, where it must reacquire the lock like anyone else.
Other variants exist (signal-and-exit, signal-and-urgent-wait, ...). Java uses signal-and-continue, which has important consequences for how condition checks must be coded (always while, never if).
Field-by-field Comparison
Field
Before
After
Text
Two main monitor signalling semantics: {{c1::<em>signal and wait</em>}}: {{c2::the signalling process exits the monitor (goes to the waiting-entry queue) and passes the monitor lock directly to the signalled process}}. {{c3::<em>signal and continue</em>}}: {{c4::the signalling process continues running and merely moves the signalled process to the waiting-entry queue, where it must reacquire the lock like anyone else}}.
Two main monitor signalling semantics: <br><ol><li>{{c1::<em>signal and wait</em>: the signalling process exits the monitor (goes to the waiting-entry queue) and passes the monitor lock directly to the signalled process}}. </li><li>{{c2::<em>signal and continue</em>: the signalling process continues running and merely moves the signalled process to the waiting-entry queue, where it must reacquire the lock like anyone else}}.</li></ol>
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. Scenario: thread A runs remove(c) as CAS(c.mark, false, true) then CAS(b.next, c, d), while thread B runs add(c') after c as CAS(c.next, d, c'). The result: c' is appended to c, but c is then unlinked, so c' is silently lost.
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. Scenario: thread A runs remove(c) as CAS(c.mark, false, true) then CAS(b.next, c, d), while thread B runs add(c') after c as CAS(c.next, d, c'). The result: c' is appended to c, but c is then unlinked, so c' is silently lost.
The lesson: the mark bit and the next-pointer must be updated together, atomically, otherwise an inserter can splice onto a node that is about to be unlinked.
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken.
The result: c' is appended to c, but c is then unlinked, so c' is silently lost.
The lesson: the mark bit and the next-pointer must be updated together, atomically, otherwise an inserter can splice onto a node that is about to be unlinked.
Field-by-field Comparison
Field
Before
After
Text
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. Scenario: thread A runs <code>remove(c)</code> as {{c1::<code>CAS(c.mark, false, true)</code> then <code>CAS(b.next, c, d)</code>}}, while thread B runs <code>add(c')</code> after <code>c</code> as {{c2::<code>CAS(c.next, d, c')</code>}}. The result: {{c3::<code>c'</code> is appended to <code>c</code>, but <code>c</code> is then unlinked, so <code>c'</code> is silently lost}}.
Adding a mark bit to each node (without coupling it to the next-pointer) is still broken. <br><br><img src="paste-2f3b23f8039cf29b52e666d66c307c8372ede18f.jpg"><br><br>The result: {{c1::<code>c'</code> is appended to <code>c</code>, but <code>c</code> is then unlinked, so <code>c'</code> is silently lost}}.
A second transient inconsistency in the lock-free queue. Thread A enqueues into an empty queue: it writes sentinel.next = new but has not yet updated tail. Thread B then dequeues, advancing head past the sentinel onto new. Now tail still points to the original sentinel, which has just been removed from the queue. Without helping this is unrecoverable; the final algorithm fixes it by having any thread that observes tail.next != null attempt CAS(tail, tail, tail.next) to drag tail forward.
A second transient inconsistency in the lock-free queue. Thread A enqueues into an empty queue: it writes sentinel.next = new but has not yet updated tail. Thread B then dequeues, advancing head past the sentinel onto new. Now tail still points to the original sentinel, which has just been removed from the queue. Without helping this is unrecoverable; the final algorithm fixes it by having any thread that observes tail.next != null attempt CAS(tail, tail, tail.next) to drag tail forward.
This is why the final dequeue code, before doing the actual dequeue, checks if (first == last) and, if so, helps advance tail.
A second transient inconsistency in the lock-free queue.
Now tail still points to the original sentinel, which has just been removed from the queue.
Without helping this is unrecoverable; the final algorithm fixes it by having any thread that observes tail.next != null attempt CAS(tail, tail, tail.next) to drag tail forward.
A second transient inconsistency in the lock-free queue.
Now tail still points to the original sentinel, which has just been removed from the queue.
Without helping this is unrecoverable; the final algorithm fixes it by having any thread that observes tail.next != null attempt CAS(tail, tail, tail.next) to drag tail forward.
This is why the final dequeue code, before doing the actual dequeue, checks if (first == last) and, if so, helps advance tail.
Field-by-field Comparison
Field
Before
After
Text
A second transient inconsistency in the lock-free queue. Thread A enqueues into an empty queue: it writes <code>sentinel.next = new</code> but has not yet updated <code>tail</code>. Thread B then dequeues, advancing <code>head</code> past the sentinel onto <code>new</code>. Now {{c1::<code>tail</code> still points to the original sentinel, which has just been removed from the queue}}. Without helping this is unrecoverable; the final algorithm fixes it by {{c2::having any thread that observes <code>tail.next != null</code> attempt <code>CAS(tail, tail, tail.next)</code> to drag <code>tail</code> forward}}.
A second transient inconsistency in the lock-free queue. <br><br><img src="paste-f93794d8374bf33c5804a69f8ebc99f535d730b6.jpg"><br><br>Now {{c1::<code>tail</code> still points to the original sentinel, which has just been removed from the queue}}. <br><br>Without helping this is unrecoverable; the final algorithm fixes it by {{c2::having any thread that observes <code>tail.next != null</code> attempt <code>CAS(tail, tail, tail.next)</code> to drag <code>tail</code> forward}}.
java.util.concurrent.atomic.AtomicMarkableReference<V> packages a reference and a boolean mark into one atomic cell. Key methods: compareAndSet(expRef, newRef, expMark, newMark): atomic CAS over the (reference, mark) pair; attemptMark(expRef, newMark): CAS the mark only, leaving the reference; get(boolean[] markHolder): read both at once. Implementation trick: steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word.
java.util.concurrent.atomic.AtomicMarkableReference<V> packages a reference and a boolean mark into one atomic cell. Key methods: compareAndSet(expRef, newRef, expMark, newMark): atomic CAS over the (reference, mark) pair; attemptMark(expRef, newMark): CAS the mark only, leaving the reference; get(boolean[] markHolder): read both at once. Implementation trick: steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word.
The bit-stealing trick relies on object addresses being 8-byte aligned, so the bottom three bits are always zero in a real pointer. Using one of them as a mark costs nothing - the slide jokes that a fully addressable 64-bit space is \(2^{64}\,\text{B} = 5.6 \cdot 10^{14}\,\text{PB}\), so the lost bit is not missed.
java.util.concurrent.atomic.AtomicMarkableReference<V> packages a reference and a boolean mark into one atomic cell.
Key methods:
compareAndSet(expRef, newRef, expMark, newMark): atomic CAS over the (reference, mark) pair;
attemptMark(expRef, newMark): CAS the mark only, leaving the reference;
get(boolean[] markHolder): read both at once.
Implementation trick: steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word.
The bit-stealing trick relies on object addresses being 8-byte aligned, so the bottom three bits are always zero in a real pointer. Using one of them as a mark costs nothing - the slide jokes that a fully addressable 64-bit space is \(2^{64}\,\text{B} = 5.6 \cdot 10^{14}\,\text{PB}\), so the lost bit is not missed.
Field-by-field Comparison
Field
Before
After
Text
<code>java.util.concurrent.atomic.AtomicMarkableReference<V></code> packages a reference and a boolean mark into one atomic cell. Key methods: {{c1::<code>compareAndSet(expRef, newRef, expMark, newMark)</code>}}: atomic CAS over the (reference, mark) pair; {{c2::<code>attemptMark(expRef, newMark)</code>}}: CAS the mark only, leaving the reference; {{c2::<code>get(boolean[] markHolder)</code>}}: read both at once. Implementation trick: {{c3::steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word}}.
<code>java.util.concurrent.atomic.AtomicMarkableReference<V></code> packages a reference and a boolean mark into one atomic cell. <br><br>Key methods: <br><ol><li><code>compareAndSet(expRef, newRef, expMark, newMark)</code>: {{c1::atomic CAS over the (reference, mark) pair}}; </li><li><code>attemptMark(expRef, newMark)</code>: {{c2::CAS the mark only, leaving the reference}}; </li><li><code>get(boolean[] markHolder)</code>: {{c3::read both at once}}. </li></ol>Implementation trick: {{c4::steal the low bit of the 8-byte aligned pointer for the mark, so the pair still fits in one 64-bit word}}.<br>
Extra
The bit-stealing trick relies on object addresses being 8-byte aligned, so the bottom three bits are always zero in a real pointer. Using one of them as a mark costs nothing - the slide jokes that a fully addressable 64-bit space is \(2^{64}\,\text{B} = 5.6 \cdot 10^{14}\,\text{PB}\), so the lost bit is not missed.
The bit-stealing trick relies on object addresses being 8-byte aligned, so the bottom three bits are always zero in a real pointer. Using one of them as a mark costs nothing - the slide jokes that a fully addressable 64-bit space is \(2^{64}\,\text{B} = 5.6 \cdot 10^{14}\,\text{PB}\), so the lost bit is not missed.<br><br><img src="paste-a152949cdf51a708905f95e863d16b470f3f110c.jpg">
Core logic of the FIFO-fair RW lock. release_write sets writersWait = readersWaiting, i.e. exactly the readers waiting now are allowed through before the next writer. acquire_read blocks while writers > 0 or (writersWaiting > 0 and writersWait <= 0), and on entry decrements writersWait. acquire_write blocks while writers > 0 or readers > 0 or writersWait > 0.
Core logic of the FIFO-fair RW lock. release_write sets writersWait = readersWaiting, i.e. exactly the readers waiting now are allowed through before the next writer. acquire_read blocks while writers > 0 or (writersWaiting > 0 and writersWait <= 0), and on entry decrements writersWait. acquire_write blocks while writers > 0 or readers > 0 or writersWait > 0.
The clause writersWait <= 0 reads as: "the quota of preferred readers is used up, newly arriving readers must wait". When the next writer finishes, the quota is freshly set from the readers that happen to be waiting then.
release_write sets writersWait = readersWaiting, i.e. exactly the readers waiting now are allowed through before the next writer.
acquire_read blocks while writers > 0 or (writersWaiting > 0 and writersWait <= 0), and on entry decrements writersWait.
acquire_write blocks while writers > 0 or readers > 0 or writersWait > 0.
The clause writersWait <= 0 reads as: "the quota of preferred readers is used up, newly arriving readers must wait". When the next writer finishes, the quota is freshly set from the readers that happen to be waiting then.
Field-by-field Comparison
Field
Before
After
Text
Core logic of the FIFO-fair RW lock. {{c1::<code>release_write</code>}} sets {{c2::<code>writersWait = readersWaiting</code>}}, i.e. {{c2::exactly the readers waiting <em>now</em> are allowed through before the next writer}}. {{c3::<code>acquire_read</code>}} blocks while {{c4::<code>writers > 0</code> or (<code>writersWaiting > 0</code> and <code>writersWait <= 0</code>)}}, and on entry decrements {{c5::<code>writersWait</code>}}. {{c6::<code>acquire_write</code>}} blocks while {{c7::<code>writers > 0</code> or <code>readers > 0</code> or <code>writersWait > 0</code>}}.
Core logic of the FIFO-fair RW lock.<br><ol><li><code>release_write</code> sets <code>writersWait = readersWaiting</code>, i.e. {{c1::exactly the readers waiting <em>now</em> are allowed through before the next writer}}. </li><li><code>acquire_read</code> blocks while {{c2::<code>writers > 0</code> or (<code>writersWaiting > 0</code> and <code>writersWait <= 0</code>)}}, and on entry decrements {{c2::<code>writersWait</code>}}. </li><li><code>acquire_write</code> blocks while {{c3::<code>writers > 0</code> or <code>readers > 0</code> or <code>writersWait > 0</code>}}.</li></ol>
Extra
The clause <code>writersWait <= 0</code> reads as: "the quota of preferred readers is used up, newly arriving readers must wait". When the next writer finishes, the quota is freshly set from the readers that happen to be waiting then.
<img src="paste-629ebfaa950a6d89e3c68018c81cbad68b49e6a3.jpg"><br><br>The clause <code>writersWait <= 0</code> reads as: "the quota of preferred readers is used up, newly arriving readers must wait". When the next writer finishes, the quota is freshly set from the readers that happen to be waiting then.
Java's synchronized statement does not support reader/writer semantics. The library provides java.util.concurrent.locks.ReentrantReadWriteLock instead. Its methods readLock() and writeLock() each return a lock object with its own lock()/unlock() methods. This implementation has neither writer priority nor reader-to-writer upgrading.
Java's synchronized statement does not support reader/writer semantics. The library provides java.util.concurrent.locks.ReentrantReadWriteLock instead. Its methods readLock() and writeLock() each return a lock object with its own lock()/unlock() methods. This implementation has neither writer priority nor reader-to-writer upgrading.
Re-entrancy is orthogonal to the reader/writer distinction; some libraries do support upgrading a held read lock to a write lock in the same thread.
Java's synchronized statement does not support reader/writer semantics. The library provides java.util.concurrent.locks.ReentrantReadWriteLock instead.
Its methods readLock() and writeLock() each return a lock object with its own lock()/unlock() methods. This implementation has neither writer priority nor reader-to-writer upgrading.
Java's synchronized statement does not support reader/writer semantics. The library provides java.util.concurrent.locks.ReentrantReadWriteLock instead.
Its methods readLock() and writeLock() each return a lock object with its own lock()/unlock() methods. This implementation has neither writer priority nor reader-to-writer upgrading.
Re-entrancy is orthogonal to the reader/writer distinction; some libraries do support upgrading a held read lock to a write lock in the same thread.
Field-by-field Comparison
Field
Before
After
Text
Java's <code>synchronized</code> statement does not support reader/writer semantics. The library provides {{c1::<code>java.util.concurrent.locks.ReentrantReadWriteLock</code>}} instead. Its methods {{c2::<code>readLock()</code> and <code>writeLock()</code>}} each return {{c3::a lock object with its own <code>lock()</code>/<code>unlock()</code> methods}}. This implementation has {{c4::neither writer priority nor reader-to-writer upgrading}}.
Java's <code>synchronized</code> statement does not support reader/writer semantics. The library provides <code>java.util.concurrent.locks.ReentrantReadWriteLock</code> instead. <br><br>Its methods <code>readLock()</code> and <code>writeLock()</code> each return {{c1::a lock object with its own <code>lock()</code>/<code>unlock()</code> methods}}. This implementation has {{c2::neither writer priority nor reader-to-writer upgrading}}.
Producer-consumer with three semaphores nonEmpty = Semaphore(0), nonFull = Semaphore(size), manipulation = Semaphore(1): the order manipulation.acquire(); nonFull.acquire(); in enqueue (and analogously manipulation before nonEmpty in dequeue) deadlocks: a producer holding manipulation on a full queue waits on nonFull, while the consumer needs manipulation to remove an item: a circular wait between manipulation and nonFull / nonEmpty. Fix: acquire the resource semaphore before the manipulation mutex (nonFull.acquire(); manipulation.acquire();), so the resource wait happens outside the critical section.
Producer-consumer with three semaphores nonEmpty = Semaphore(0), nonFull = Semaphore(size), manipulation = Semaphore(1): the order manipulation.acquire(); nonFull.acquire(); in enqueue (and analogously manipulation before nonEmpty in dequeue) deadlocks: a producer holding manipulation on a full queue waits on nonFull, while the consumer needs manipulation to remove an item: a circular wait between manipulation and nonFull / nonEmpty. Fix: acquire the resource semaphore before the manipulation mutex (nonFull.acquire(); manipulation.acquire();), so the resource wait happens outside the critical section.
General rule when nesting semaphores: acquire the one you might block on first, the one you merely need for exclusion second. This breaks the hold-and-wait cycle.
The order manipulation.acquire(); nonFull.acquire(); in enqueue (and analogously manipulation before nonEmpty in dequeue) deadlocks: a producer holding manipulation on a full queue waits on nonFull, while the consumer needs manipulation to remove an item: a circular wait between manipulation and nonFull / nonEmpty.
Fix: acquire the resource semaphore before the manipulation mutex (nonFull.acquire(); manipulation.acquire();), so the resource wait happens outside the critical section.
The order manipulation.acquire(); nonFull.acquire(); in enqueue (and analogously manipulation before nonEmpty in dequeue) deadlocks: a producer holding manipulation on a full queue waits on nonFull, while the consumer needs manipulation to remove an item: a circular wait between manipulation and nonFull / nonEmpty.
Fix: acquire the resource semaphore before the manipulation mutex (nonFull.acquire(); manipulation.acquire();), so the resource wait happens outside the critical section.
General rule when nesting semaphores: acquire the one you might block on first, the one you merely need for exclusion second. This breaks the hold-and-wait cycle.
Field-by-field Comparison
Field
Before
After
Text
Producer-consumer with three semaphores <code>nonEmpty = Semaphore(0)</code>, <code>nonFull = Semaphore(size)</code>, <code>manipulation = Semaphore(1)</code>: the order <code>manipulation.acquire(); nonFull.acquire();</code> in <code>enqueue</code> (and analogously <code>manipulation</code> before <code>nonEmpty</code> in <code>dequeue</code>) {{c1::deadlocks}}: a producer holding <code>manipulation</code> on a full queue waits on <code>nonFull</code>, while the consumer needs <code>manipulation</code> to remove an item: {{c2::a circular wait between <code>manipulation</code> and <code>nonFull</code> / <code>nonEmpty</code>}}. Fix: {{c3::acquire the resource semaphore <em>before</em> the <code>manipulation</code> mutex (<code>nonFull.acquire(); manipulation.acquire();</code>)}}, so the resource wait happens outside the critical section.
Producer-consumer with three semaphores <font face="monospace"><br><br></font><img src="paste-62e850b7aba10450be51dbcac1edd8786380c981.jpg"><font face="monospace"><br><br></font>The order <code>manipulation.acquire(); nonFull.acquire();</code> in <code>enqueue</code> (and analogously <code>manipulation</code> before <code>nonEmpty</code> in <code>dequeue</code>) {{c1::deadlocks: a producer holding <code>manipulation</code> on a full queue waits on <code>nonFull</code>, while the consumer needs <code>manipulation</code> to remove an item: a circular wait between <code>manipulation</code> and <code>nonFull</code> / <code>nonEmpty</code>}}. <br><br>Fix: {{c3::acquire the resource semaphore <em>before</em> the <code>manipulation</code> mutex (<code>nonFull.acquire(); manipulation.acquire();</code>), so the resource wait happens outside the critical section}}.
A skip list is a sorted multi-level linked list. Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\)}} (geometric distribution), and no rebalancing is ever performed.
A skip list is a sorted multi-level linked list. Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\)}} (geometric distribution), and no rebalancing is ever performed.
The geometric height distribution makes the expected number of nodes at level \(k\) decrease by a factor of two with each level, which is what gives the logarithmic search.
Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\) (geometric distribution)}}, and no rebalancing is ever performed.
Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\) (geometric distribution)}}, and no rebalancing is ever performed.
The geometric height distribution makes the expected number of nodes at level \(k\) decrease by a factor of two with each level, which is what gives the logarithmic search.
Field-by-field Comparison
Field
Before
After
Text
A skip list is a {{c1::sorted multi-level linked list}}. Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\)}} (geometric distribution), and {{c3::no rebalancing is ever performed}}.
A skip list is a {{c1::sorted multi-level linked list}}. <br><br>Each node has a probabilistic height with {{c2::\(\mathbb{P}(\text{height} = n) = 0.5^n\) (geometric distribution)}}, and {{c3::no rebalancing is ever performed}}.
Design trick for the lock-free queue: introduce a persistent sentinel node at the front. Then enqueuers only ever touch tail and tail.next, and dequeuers only ever touch head and read head.next; the two sides do not directly contend on the same pointer. Dequeue returns the item carried by head.next (not the sentinel itself), then advances head to that node, which becomes the new sentinel.
Design trick for the lock-free queue: introduce a persistent sentinel node at the front. Then enqueuers only ever touch tail and tail.next, and dequeuers only ever touch head and read head.next; the two sides do not directly contend on the same pointer. Dequeue returns the item carried by head.next (not the sentinel itself), then advances head to that node, which becomes the new sentinel.
The sentinel makes the empty-queue case uniform: an empty queue has head == tail and head.next == null, with no aliasing pathology.
Design trick for the lock-free queue: introduce a persistent sentinel node at the front.
Then enqueuers only ever touch tail and tail.next, and dequeuers only ever touch head and read head.next; the two sides do not directly contend on the same pointer.
Dequeue returns the item carried by head.next (not the sentinel itself), then advances head to that node, which becomes the new sentinel.
Design trick for the lock-free queue: introduce a persistent sentinel node at the front.
Then enqueuers only ever touch tail and tail.next, and dequeuers only ever touch head and read head.next; the two sides do not directly contend on the same pointer.
Dequeue returns the item carried by head.next (not the sentinel itself), then advances head to that node, which becomes the new sentinel.
The sentinel makes the empty-queue case uniform: an empty queue has head == tail and head.next == null, with no aliasing pathology.
Field-by-field Comparison
Field
Before
After
Text
Design trick for the lock-free queue: introduce a {{c1::persistent sentinel node at the front}}. Then enqueuers only ever touch {{c2::<code>tail</code> and <code>tail.next</code>}}, and dequeuers only ever touch {{c3::<code>head</code> and read <code>head.next</code>}}; the two sides do not directly contend on the same pointer. Dequeue returns the item carried by <code>head.next</code> (not the sentinel itself), then {{c4::advances <code>head</code> to that node, which becomes the new sentinel}}.
Design trick for the lock-free queue: introduce a {{c1::persistent sentinel node at the front}}. <br><br>Then enqueuers only ever touch {{c2::<code>tail</code> and <code>tail.next</code>}}, and dequeuers only ever touch {{c2::<code>head</code> and read <code>head.next</code>}}; the two sides do not directly contend on the same pointer. <br><br>Dequeue returns the item carried by <code>head.next</code> (not the sentinel itself), then {{c3::advances <code>head</code> to that node, which becomes the new sentinel}}.
What are the four necessary conditions for deadlock (Coffman conditions)?
Mutual exclusion: at least one resource is held in non-shareable mode
Hold and wait: a thread holds at least one resource while waiting for another
No preemption: resources cannot be forcibly taken away
Circular wait: a cycle of threads each waiting for a resource held by the next
All four must hold simultaneously. Breaking any one prevents deadlock.
Field-by-field Comparison
Field
Before
After
Text
What are the four necessary conditions for deadlock (Coffman conditions)?
What are the four necessary conditions for deadlock (Coffman conditions)?<br><ol><li>{{c1::<b>Mutual exclusion: </b>at least one resource is held in non-shareable mode}}<br></li><li>{{c2::<b>Hold and wait:</b> a thread holds at least one resource while waiting for another}}<br></li><li>{{c3::<b>No preemption:</b> resources cannot be forcibly taken away}}<br></li><li>{{c4::<b>Circular wait:</b> a cycle of threads each waiting for a resource held by the next}}<br></li></ol>All four must hold simultaneously. Breaking any one prevents deadlock.<br>
Extra
<ol><li><b>Mutual exclusion</b> — at least one resource is held in non-shareable mode</li><li><b>Hold and wait</b> — a thread holds at least one resource while waiting for another</li><li><b>No preemption</b> — resources cannot be forcibly taken away</li><li><b>Circular wait</b> — a cycle of threads each waiting for a resource held by the next</li></ol>All four must hold simultaneously. Breaking any one prevents deadlock.
A successful CAS only suggests that no other thread has written between the read and the swap, it does not guarantee it. The counterexample is the ABA problem: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A. Stronger alternatives that avoid ABA are LL/SC (and its variants).
A successful CAS only suggests that no other thread has written between the read and the swap, it does not guarantee it. The counterexample is the ABA problem: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A. Stronger alternatives that avoid ABA are LL/SC (and its variants).
Transactional memory has been proposed as a more compositional alternative, but is not yet broadly competitive in practice.
A successful CAS only suggests that no other thread has written between the read and the swap, it does not guarantee it.
The counterexample is the ABA problem: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A.
Stronger alternatives that avoid ABA are LL/SC (and its variants).
Transactional memory has been proposed as a more compositional alternative, but is not yet broadly competitive in practice.
Field-by-field Comparison
Field
Before
After
Text
A successful CAS only {{c1::<em>suggests</em>}} that no other thread has written between the read and the swap, it does not {{c2::guarantee}} it. The counterexample is the {{c3::ABA problem}}: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A. Stronger alternatives that avoid ABA are {{c4::LL/SC (and its variants)}}.
A successful CAS only <em>suggests</em> that no other thread has written between the read and the swap, it does not guarantee it. <br><br>The counterexample is {{c1::the ABA problem: the value can be changed from A to B and back to A between the two operations, and CAS sees an unchanged A}}. <br><br>Stronger alternatives that avoid {{c1::ABA}} are {{c2::LL/SC (and its variants)}}.